
Em 2024, não se pode reclamar da falta de uma interconexão adequada se o objetivo é “unir” centenas, milhares ou mesmo dezenas de milhares de aceleradores num único sistema. Existem NVIDIA NVLink e InfiniBand. O Google usa switches ópticos OCS, a AMD em breve levará o Infinity Fabric ao nível dos entrenós, e a boa e velha Ethernet não vai perder terreno de forma alguma e está encontrando uma nova vida na forma de Ultra Ethernet.
O problema não é a disponibilidade e seleção de uma interconexão adequada, mas a perda acentuada de largura de banda fora da embalagem do chip (a chamada Parede de Memória). Sim, a memória HBM é rápida, mas está fortemente ligada aos recursos de computação e, como resultado, como observou o chefe da Celestial AI em um comentário ao The Next Platform, a indústria de IA usa aceleradores NVIDIA como os controladores de memória mais caros no mundo.
A Celestial AI anunciou no ano passado que pretende criar uma interconexão “inteligente” universal baseada em fotônica, que poderia ser usada em todos os nichos que exigem troca ativa de grandes fluxos de dados, desde inter-chip (chip-to-chip) até inter-chip. nó (nó) -para nó). Recentemente, recebeu um pacote de investimento adicional no valor de US$ 175 milhões.

Fonte das imagens aqui e abaixo: Celestial AI
A tecnologia, chamada Photonic Fabric, de acordo com a Celestial AI, pode aumentar a largura de banda e a memória disponível em 25 vezes, ao mesmo tempo que consome uma ordem de magnitude menos energia do que os sistemas de interconexão existentes. Está se desenvolvendo em três direções: chips, interposers e um análogo óptico da tecnologia Intel EMIB chamado OMIB.
A Celestial AI considera, com razão, os chips como a maneira mais fácil de integrar sua tecnologia. O módulo da empresa oferece atualmente 14,4 Tbps (1,8 TB/s) de taxa de transferência fora do chip e é um pouco menor em tamanho do que a construção padrão da HBM. Mas esta é apenas a primeira geração: na segunda geração do Photonic Fabric, os blocos SerDes de 56 Gbit/s serão substituídos por blocos de classe de 112 Gbit/s (PAM4).
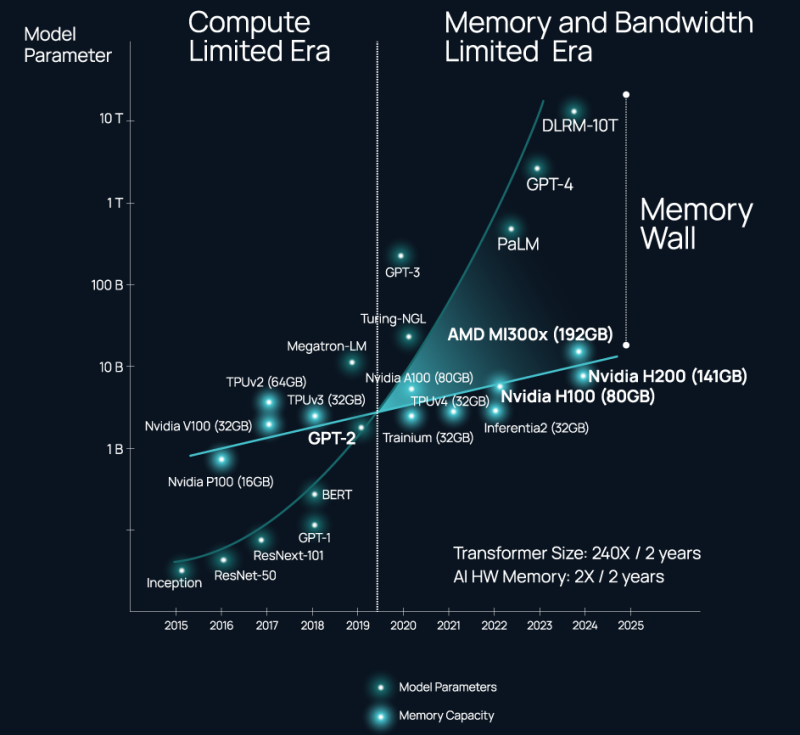
O notório “Muro da Memória”
Por se tratar de sistemas com desagregação de recursos, a Celestial AI se propõe a resolver o problema de acesso rápido a uma grande quantidade de memória da seguinte forma: o novo chiplet, que além da interconexão contém dois conjuntos HBM com volume total de 72 GB, também receberá suporte para quatro DIMMs DDR5 com volume total de até 2 TB. Usando uma tecnologia de processo de 5 nm, esse chip pode facilmente transformar o HBM em um cache de gravação rápida para DDR5.
Na verdade, estamos falando de uma maneira relativamente simples e relativamente acessível de transformar qualquer processador com layout de chiplet em um análogo desagregado do Intel Xeon Max ou NVIDIA Grace Hopper. Ao mesmo tempo, a latência para acesso remoto à memória não excederá 120 ns, e o consumo de energia neste caso será uma ordem de grandeza menor do que no caso do NVLink – apenas 6,2 pJ/bit versus 62,5 pJ/bit para NVIDIA .

O novo chip Celestial tornará a HBM mais relacionada ao DDR5 do que a NVIDIA
Assim, com o uso de novos controladores de memória chiplet, tornam-se reais sistemas onde todos os chips, desde a CPU até os processadores e aceleradores de rede, serão unidos por uma única interconexão fotônica e ao mesmo tempo terão um pool de memória DDR5 comum de grande capacidade. com cache HBM eficaz. A Celestial AI diz que já está trabalhando com alguns hiperescaladores e um “grande fabricante de processadores”.
Segundo o chefe da Celestial AI, amostras de chips com suporte Photonic Fabric aparecerão no segundo semestre de 2025, e a implementação em massa começará em 2027. No entanto, isso pode acabar sendo uma corrida para o fundo do poço: Ayar Labs, outro desenvolvedor de fotônica apoiado pela Intel, já mostrou um protótipo de processador com interconexão fotônica integrada.
E a Lightmatter recebeu financiamento de US$ 155 milhões em dezembro para desenvolver o interposer fotônico Passage e já estaria colaborando com clientes interessados na criação de um supercomputador com 300 mil nós. Eliyan não pode ser descartado, pois propõe abandonar completamente a tecnologia interposer e substituí-la por controladores de camada física NuLink.