
O que é o TidalScale?
O TidalScale é, para simplificar, um hipervisor “vice-versa”. Em vez da separação usual de uma máquina física em vários sistemas virtualizados, o TidalScale, pelo contrário, permite combinar vários nós físicos em um único servidor definido por software. Bem, ou em vários servidores. Em outras palavras, permite substituir de forma transparente a escala vertical pela horizontal, para que os sistemas e aplicativos convidados não notem nada.
Este não é o único sistema desse tipo, mas o TidalScale se concentra no dimensionamento em termos de RAM e não nos recursos de computação. Enfim, agora. O desenvolvedor, é claro, fala sobre as delícias de consolidar os recursos disponíveis para o usuário para aumentar a eficiência do uso de equipamentos: combinando todas as máquinas sob a asa de um hipervisor e “cortando” elas em servidores virtuais, você pode carregar melhor o hardware. É verdade que, ao mesmo tempo, a falha de um único nó destruirá todo o sistema de uma só vez.
Na prática, ainda existem algumas limitações. Até 8 nós de quatro soquetes podem ser combinados em um pool, cada um dos quais pode conter até 128 núcleos físicos e até 3 TB de RAM. Para uma máquina virtual (VM / instância ou SDS neste caso), até 254 vCPUs e até 16 TB de RAM podem ser alocados. Versões futuras prometem suporte a VM com 1024 vCPUs e 64 TB de RAM. Até o momento, o próprio fornecedor recomenda não mais que 64 vCPU por instância e, por padrão, fornece não mais que 70% da memória total do pool, mas, se desejado, esse limite pode ser aumentado para 90%.
Existe transparência em geral, mas existem algumas nuances. Sim, a VM “vê” todos os recursos alocados a ela e o hipervisor “inteligentemente” distribui todo o trabalho entre os nós físicos subjacentes, tentando evitar “saltos” desnecessários entre eles – a fila de comandos é executada em uma CPU, o sistema evita acessos desnecessários à memória do nó vizinho, e os dados devem ser armazenados no armazenamento mais próximo. Ao mesmo tempo, o hypervisor usa o aprendizado de máquina para se adaptar melhor à carga atual ao longo do tempo.
Ao mesmo tempo, as instruções do AVX512 não são mostradas para as VMs convidadas, elas não têm conhecimento do SMT, devem ter o Transparent Huge Pages (THP) desativado, devem usar uma fonte de entropia adicional para o PRNG, os drivers virtio são um pouco mais lentos que os padrão e alguns parâmetros e valores / proc e / sys não estão disponíveis ou podem exibir informações incorretas. Existem outras sutilezas, inclusive com o próprio hypervisor. Por exemplo, em nosso sistema de teste, as CPUs funcionavam a uma frequência constante e abaixo da base.
Por que isso é necessário?
A resposta óbvia é para cargas escalonáveis verticalmente, que em princípio não conseguem paralelizar vários nós. As tarefas “verticais” típicas incluem vários tipos de análise, modelagem e visualização. Eles geralmente são críticos precisamente para a quantidade de RAM, onde todos os dados necessários para o trabalho são armazenados. Mas o custo total de RAM no sistema está crescendo de forma não linear e depende de vários fatores. Portanto, a resposta correta é: economizar dinheiro! Infelizmente, a coisa mais importante – o custo das licenças e o princípio de sua formação – a TidalScale não divulga.
Em geral, há muito tempo há um desequilíbrio entre o aumento do número de núcleos e o número de canais de memória – o primeiro é muito mais rápido. Ao mesmo tempo, o volume de módulos suportados por canal também cresce relativamente lentamente, mas o custo dos módulos com um aumento em sua capacidade é, pelo contrário, rápido. Tudo o que vai além da plataforma típica de dois soquetes começa imediatamente a custar muito dinheiro. E não se trata apenas do chassi.
A única opção para servidores físicos 4s / 8s é Intel. Além disso, para plataformas 8s, são necessários modelos de CPU mais antigos e caros, que suportam uma grande quantidade de memória e têm 3 linhas UPI. E, no caso extremo, a velocidade de acesso será limitada a uma linha, ou seja, 20,8 GB / s, que, no entanto, ainda é cerca de três ordens de magnitude mais rápidas que a atual interconexão TidalScale. Escalar acima de 8s se torna não trivial e geralmente envolve sistemas com vários nós, enquanto o TidalScale oferece capacidade de RAM com pelo menos máquinas de soquete duplo baratas.
Uma maneira alternativa de reduzir os custos de RAM é usar a Memória de Classe de Armazenamento e, no caso geral, revisar a hierarquia de memória. Com o advento do IMDT e, em seguida, do Intel Optane DCPMM, tornou-se possível expandir a RAM do nó com uma memória de estado sólido mais barata. Como bônus, obtemos segurança de dados, por exemplo, durante uma reinicialização devido a uma falha. Um exemplo típico de uso do modo App Direct para DCPMM é o SAP HANA “vertical”.
Essas soluções estão na nuvem – o Azure oferece instâncias com 9 TB de memória compartilhada. Mas não esqueça que o modo App Direct requer modificação de software e o desempenho do modo de memória, ou seja, uma expansão transparente da RAM, depende do tipo de carga. No entanto, sobre Optane ainda nos lembramos um pouco mais baixo.
Como o TidalScale funciona?
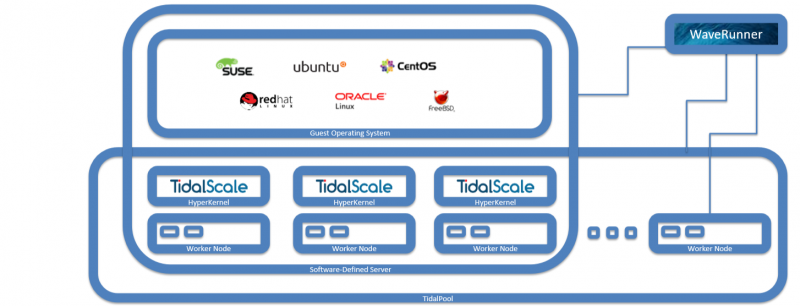
Todo o sistema é controlado por um servidor WaveRunner em execução em uma máquina física ou virtual. Ele fornece ao usuário uma interface da Web e uma API RESTful. O WaveRunner permite combinar vários hosts físicos (Nós do Trabalhador), onde a camada de virtualização do HyperKernel funcionará, no pool do TidalPool, onde as máquinas virtuais (SDS) são iniciadas.
Os hosts devem ser aproximadamente os mesmos na CPU e na RAM. Os requisitos mínimos são pequenos: CPUs Intel Xeon E5 v3 ou mais recentes, 32 GB de RAM, várias interfaces de rede e BMC com suporte a IPMI 2.0. Parte dos núcleos será necessária para a duração do hypervisor e do serviço de E / S.
Para o WaveRunner, os requisitos são os mesmos, mas 16 GB serão memória suficiente. Mas com discos um pouco mais complicados. Um volume de inicialização com capacidade de 50 GB ou mais (recomenda-se 300) deve ser espelhado. Se HDDs forem usados, o armazenamento em cache requer um SSD do mesmo tamanho recomendado. Para logs, você precisará de outro disco de 100 GB.
O WaveRunner gerencia o estado dos hosts via IPMI, ativando / desativando-os e fazendo o download via PXE HyperKernel em cada um deles. Portanto, supõe-se que várias redes separadas estejam disponíveis ao mesmo tempo. Um para BMC e PXE. O acesso ao restante da rede corporativa e SAN também requer pelo menos uma interface. Por fim, a interconexão entre nós requer uma conexão rápida e isolada. Velocidades de até 25GbE são suportadas e é recomendável usar quadros Jumbo. Interfaces de até 25 GbE também estão disponíveis para os hóspedes e, no total, até 32 dispositivos virtio podem ser alocados a eles.
Quanto ao subsistema de armazenamento, existem várias opções de implementação. Nenhum requisito de armazenamento é mencionado nos requisitos do host, pois supõe-se que os volumes se conectem pela rede. No entanto, nos próprios hosts, o encaminhamento de dispositivos locais está disponível, para que você possa organizar o armazenamento neles. Embora os próprios desenvolvedores recomendem o uso de DAS para hosts, e o melhor de tudo, uma SAN ou NAS iSCSI / FC separada com conectividade de pelo menos 10 GbE. Uma alternativa é a função de armazenamento WaveRunner. Para isso, é recomendável que você tenha pelo menos algumas unidades de terabyte no “espelho” no qual os pools do ZFS serão implantados. Você pode conectar prateleiras JBOD externas.
A lista de sistemas convidados oficialmente suportados é assim:
CentOS 7.1, 7.2, 7.3, 7.4;
Red Hat Enterprise Linux 7.1, 7.2, 7.3, 7.4;
Ubuntu 16.04;
SUSE Linux Enterprise Server 12 SP3, 15;
Oracle Linux 6.5, 6.6, 6.7, 7.6;
FreeBSD 11.1, 11.2, 12.0.
Não deve haver nenhum problema com o lançamento de “convidados” com UEFI. De fato, o Ubuntu 19.10 foi implantado no sistema de teste. Temos uma máquina virtual com 64 vCPU e 8 TB de RAM. Nenhuma configuração especial, exceto o encerramento forçado do THP, foi feita. Demora de 15 a 20 minutos para iniciar uma VM. Não havia outros SDSs em execução no mesmo cluster.
Configuração Selectel HyperServer
A Selectel oferece o serviço HyperServer, baseado no TidalScale. No nosso caso, o cluster consistia em quatro chassis Supermicro 218UTS-R1K62P com placas X11QPH + de quatro soquetes. Cada um deles carregava processadores Intel Xeon Gold 6240 (18/36, 2,6 / 3,9 GHz, L3 24,75 MB) e 3 TB de memória: 48 módulos de 64 GB de DDR4 ECC Reg. Para a interconexão de 10 GbE, foram utilizados adaptadores Intel X520-DA2, conectados via DAC ao comutador Huawei CloudEngine 6850. O WaveRunner também trabalhou em um dos nós. O armazenamento principal foi implementado por seus próprios esforços: uma matriz de software baseada em HBA com quatro Intel S4510 de 2 TB.
Nós HyperServer
Teste
Polymem é um utilitário que calcula polinômios de enésima ordem, adicionando-os a uma matriz de um determinado tamanho na RAM. Tais cálculos fazem parte de muitas tarefas científicas. Polymem é essencialmente uma referência do tipo STREAM, mas com uma taxa de cálculo ajustável, que permite determinar o equilíbrio entre a velocidade de cálculo e a velocidade da memória. Ele, em particular, foi usado na avaliação de desempenho do Intel Optane DCPMM e IMDT. A versão completa do trabalho está disponível publicamente.
O IMDT para expandir a RAM visível e o TidalScale, em certa medida, está relacionado ao fato de que, com o aumento da quantidade de dados na memória, mais cedo ou mais tarde chegará um momento em que a própria RAM local não será suficiente – e o hipervisor terá que acessar a memória de outra pessoa no nó vizinho no caso do TidalScale ou Optano no caso do IMDT. Para o teste de Polymem, o GCC foi compilado com parâmetros do Makefile completo. Em cada estágio, foi lançado três vezes, com ligação de thread aos kernels (vCPU) através do OpenMP.
A primeira execução foi realizada com uma pequena quantidade de RAM e uma ordem variável para uma estimativa aproximada do nível requerido de intensidade de computação. Em geral, próximo de n = 512, a velocidade máxima de cálculo se estabelece na região de 800 Gflop / s e não aumenta mais rapidamente com o aumento da ordem polinomial. O máximo teórico para nossos 64 núcleos, com acesso apenas ao AVX2 / FMA (2 × 16 flops / ciclo) e com uma frequência de clock estabelecida de cerca de 2,15 GHz, é de aproximadamente 2,2 TFl / s. No entanto, sem nenhuma virtualização no hardware usual, o Polymem geralmente fornece cerca da metade do máximo possível.
De fato, mesmo na estrutura de um teste tão pequeno, os indicadores de desempenho reais às vezes apresentavam fortes falhas: em algum lugar entre duas a três vezes o máximo e em algum lugar na ordem de magnitude. Não deveria surpreender ninguém. Primeiro, a carga ainda é dinamicamente distribuída entre os hosts físicos subjacentes. Em segundo lugar, mesmo dentro do host, toda a sua RAM não pode ser fornecida exclusivamente para as necessidades da VM – a parte sempre é usada para armazenar em cache as páginas de memória dos hosts vizinhos.
A segunda execução foi feita para volumes de RAM de até 4 TB, para que, mesmo no caso extremo, tenha certeza de que a memória da VM está “espalhada” por vários hosts e a interconexão será o fator limitante. O gráfico mostra uma fratura a partir de 3 TB, o que é esperado. E aqui, é claro, eu gostaria de escolher a ordem polinomial para completar o quadro, mas … trabalhar com esses volumes se torna dolorosamente longo, e o tempo alocado para se familiarizar com o sistema é razoavelmente limitado.
E o assunto diz respeito não apenas ao preenchimento da RAM, mas também ao seu lançamento. Por exemplo, em Tachyon, demorou mais de uma hora para limpar 7 TB de RAM, mas esse tempo também é levado em consideração no resultado final. Por outro lado, há quanto tempo você teve a oportunidade de obter tanta memória para uma visualização tão grande? Como você gosta, por exemplo, da chaleira 640 Gpix da Newell? Brincar como brincadeira, mas nem sempre é possível renderizar com eficiência, pelo menos, alguns nós.
Na verdade, o Tachyon é um mecanismo de renderização clássico usando o traçado de raios, muito popular como uma ferramenta para visualizar vários modelos na comunidade científica. Para o teste, a versão atual 0.99b6 foi feita, montada na versão linux-64-thr do Makefile completo. Foi usado para a renderização mais simples do modelo de demonstração teapot.dat com uma resolução de n00000 × n00000 pixels, em que n era 1, 2, 4 e 8. O resultado não foi salvo no disco, portanto, a carga principal estava precisamente na RAM.
Mas qual é a velocidade geral de trabalhar com RAM? Um teste simples com blocos de 4 KB de / dev / zero a ramfs e de ramfs a / dev / null, realizado três vezes para cada direção, mostrou o seguinte. Em primeiro lugar, até 32 GB, as velocidades de leitura e gravação permanecem aproximadamente as mesmas: cerca de 315 MB / se 260 MB / s, respectivamente, o que é bastante modesto. Após 32 GB, a velocidade não diminui gradualmente – a primeira passagem é muito mais lenta que as subsequentes, que se parecem com o prometido “aprendizado” do hipervisor em tempo real. Infelizmente, 512 GB conseguiram gravar dados apenas uma vez, após o que a VM caiu por um motivo desconhecido. E nisso nosso tempo de acesso ao HyperServer expirou.
Conclusão
Talvez não tiremos conclusões finais e peremptórias agora. Em primeiro lugar, a tecnologia está longe de ser massa e os testes estão longe de serem concluídos devido a restrições de tempo. Isso também levou à falta de possíveis otimizações, enquanto os próprios desenvolvedores recomendam o ajuste das configurações de software e hardware para uma tarefa específica e conjunto de dados / volume. Em segundo lugar, o próprio HyperServer é classificado pela Selectel como soluções individuais.
Preços do HyperServer …
Portanto, a conclusão mais geral pode parecer estranha à primeira vista: ela realmente existe e funciona! Na verdade, o HyperServer, sendo um serviço exclusivo para o mercado russo, está intimamente ligado a outra possibilidade igualmente infreqüente de alugar servidores de quatro soquetes. No momento, é reivindicada a possibilidade de escalar até 512 núcleos e 48 TB de RAM com a união de 4 a 16 nós físicos.
… e o preço aproximado do aluguel de um nó de configuração júnior
A própria possibilidade de alugar torna essas tecnologias mais acessíveis. Se você acredita nas palavras do representante da SAP, quando no âmbito de um projeto era necessário um sistema de teste com “apenas” 6 TB de RAM, descobriu-se que na Rússia, em princípio, não existem sistemas para uso temporário – todas essas máquinas são montadas para clientes específicos individualmente .
.