
A NVIDIA publicou resultados novos e ainda mais impressionantes na área de trabalho com modelos de linguagem grandes (LLM) no benchmark MLPerf Inference 4.0. Nos últimos seis meses, os já elevados resultados demonstrados pela arquitetura Hopper em cenários de inferência foram quase triplicados. Um resultado tão impressionante foi alcançado graças às melhorias de hardware nos aceleradores H200 e às otimizações de software.
A IA generativa literalmente explodiu a indústria: nos últimos dez anos, o poder computacional gasto no treinamento de redes neurais cresceu seis ordens de magnitude, e LLMs com um trilhão de parâmetros não são mais incomuns. No entanto, a inferência de tais modelos também é uma tarefa difícil, que a NVIDIA aborda de forma abrangente, utilizando, em suas próprias palavras, “otimização multidimensional”.

Fonte da imagem: NVIDIA
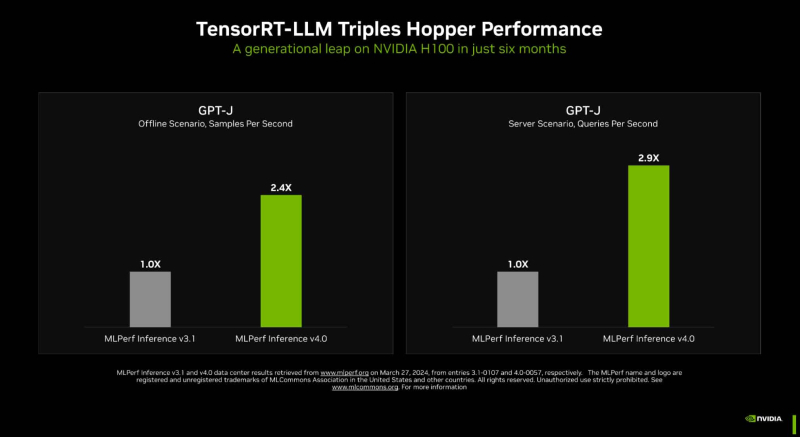
Uma das principais ferramentas é o TensorRT-LLM, que inclui um compilador e outras ferramentas de desenvolvimento que levam em consideração a arquitetura dos aceleradores da empresa. Graças a ele foi possível quase triplicar o desempenho da inferência GPT-J nos aceleradores H100 em apenas seis meses. Esse aumento foi alcançado graças à otimização de filas em tempo real (lote de sequência em voo), ao uso de cache KV paginado, paralelismo de tensor (distribuição de pesos entre aceleradores), quantização FP8 e ao uso do novo kernel XQA.
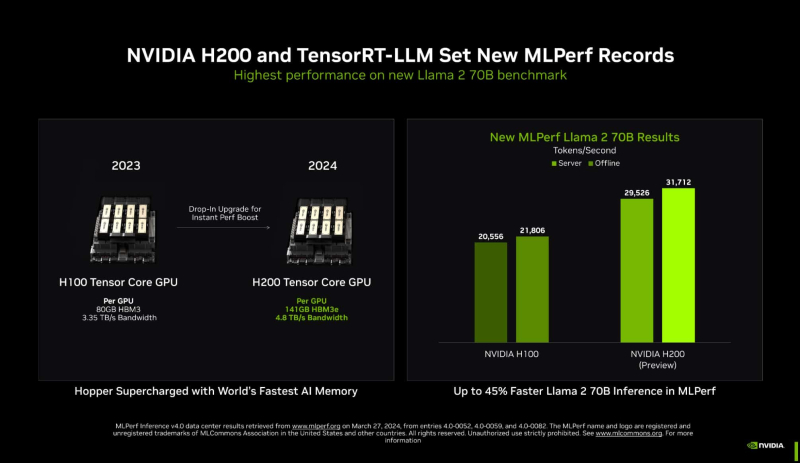
No caso dos aceleradores H200, que utilizam a mesma arquitetura Hopper do H100, a memória desempenha um papel importante: 141 GB HBM3e (4,8 TB/s) versus 80 GB HBM3 (3,35 TB/s). Este volume permite colocar o modelo de nível Llama 2 70B inteiramente na memória local. No teste MLPerf Llama 2 70B, os aceleradores H200 são 28% mais produtivos que o H100 com o mesmo pacote térmico de 700 W, e aumentar o pacote térmico para 1000 W (como alguns fornecedores fazem em suas plataformas MGX) dá outros 11– Aumento de 14%, e a diferença final com o H100 neste teste pode chegar até 45%.
Em uma seção especial da nova versão do MLPerf, a NVIDIA demonstrou várias técnicas interessantes para maior otimização: “escassez estruturada”, que permite aumentar o desempenho no teste Llama 2 em 33%, “poda”, que simplifica a IA modelo e permite aumentar a velocidade de inferência em mais 40%, bem como DeepCache, que simplifica os cálculos para Stable Diffusion XL e proporciona um aumento de desempenho de até 74%.
Hoje, a plataforma baseada em módulos H200, segundo a NVIDIA, é a plataforma de inferência mais rápida disponível. A empresa se vangloriou dos resultados do GH200 na última rodada, mas não divulgou os resultados dos aceleradores Blackwell. No entanto, nem todos consideram os resultados do MLPerf indicativos. Por exemplo, a Groq não participa neste benchmark por uma questão de princípio.