
Hoje o Google anunciou o lançamento de um novo modelo de linguagem grande, Gemini. Junto com ele, a empresa apresentou seu novo acelerador AI Cloud TPU v5e (unidade de processamento Tensor – processador tensor). O cluster baseado na nova TPU consiste em 8.960 chips v5p e está equipado com a interconexão mais rápida do Google – as velocidades de transferência de dados podem chegar a 4.800 Gbps por chip.

Fonte da imagem: Google
O Cloud TPU v5e está equipado com 95 GB de memória HBM3 com largura de banda de 2765 GB/s. O desempenho de número inteiro INT8 é de 918 TOPS (trilhões de operações por segundo), enquanto o desempenho de ponto flutuante BF16 é de 459 teraflops.
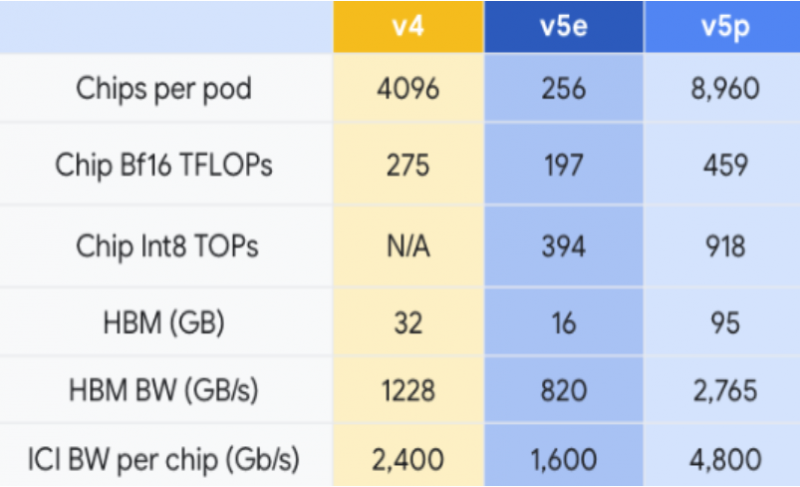
O Google afirma que os novos chips são significativamente mais rápidos do que a geração anterior TPU v4. O novo Cloud TPU v5p oferecerá 2x o desempenho de ponto flutuante (FLOPS) e 3x a memória de alta largura de banda.
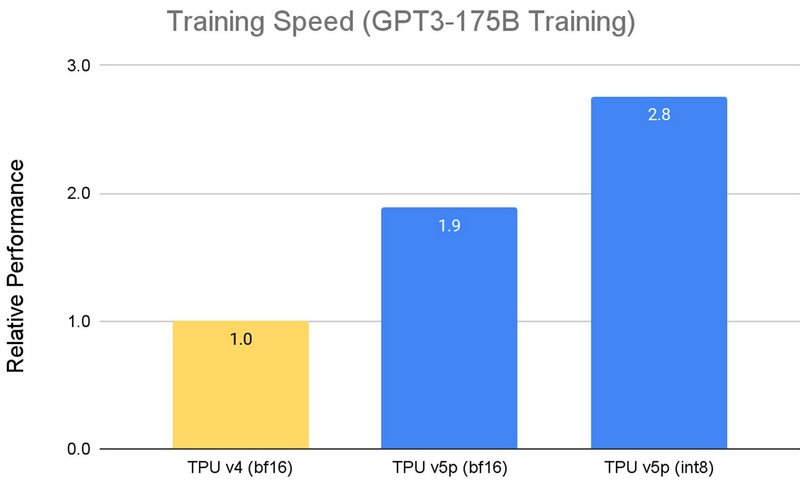
Segundo o Google, os novos aceleradores TPU v5p são capazes de treinar grandes modelos de linguagem, como GPT-3 com 175 bilhões de parâmetros, 2,8 vezes mais rápido que o TPU v4, usando menos energia. Além disso, graças à segunda geração do SparseCore, o TPU v5p pode treinar modelos densos de incorporação 1,9 vezes mais rápido que o TPU v4. Além do desempenho aprimorado, o TPU v5p oferece o dobro da escalabilidade do TPU v4, que combinado com a duplicação do desempenho fornece quatro vezes mais FLOPS por cluster.
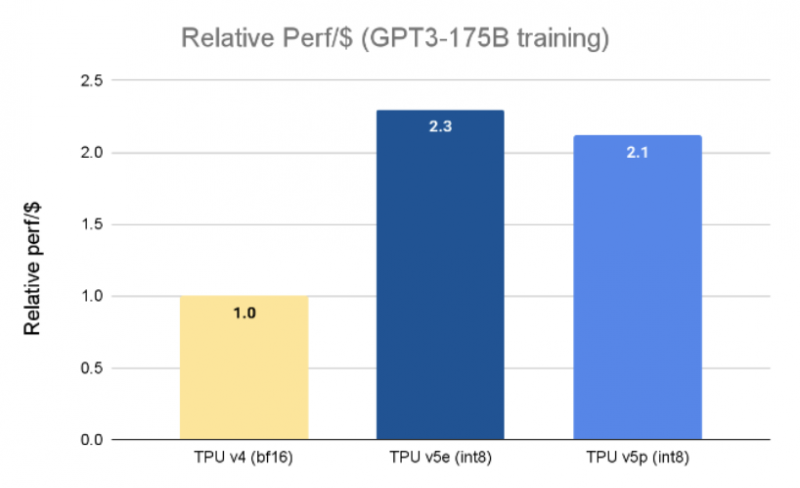
Curiosamente, em termos de desempenho por dólar, o v5p é ligeiramente inferior aos aceleradores TPU v5e recentemente introduzidos. No entanto, este último pode ser montado em clusters de apenas 256 chips, e um chip fornecerá apenas 197 teraflops no BF16 contra 275 teraflops para TPU v4 e 459 teraflops para TPU v5p.
«No uso inicial, o Google DeepMind e o Google Research demonstraram aceleração de até 2x nas cargas de trabalho de treinamento LLM baseadas em chips TPU v5p em comparação com o desempenho capturado dos chips TPU v4 da geração atual, escreve Jeff Dean, cientista-chefe do Google DeepMind e Google Research. “O amplo suporte para estruturas de ML como JAX, PyTorch, TensorFlow e ferramentas de orquestração nos permitirá escalar de forma ainda mais eficiente usando chips v5p. Com a segunda geração do SparseCore, também estamos vendo melhorias significativas no desempenho da incorporação de cargas de trabalho. As TPUs são vitais para impulsionar nossos mais extensos esforços de pesquisa e engenharia em modelos de ponta como o Gemini.”