
A startup americana Cerebras Systems introduziu um processador WSE-3 gigante para aprendizado de máquina e outras tarefas que exigem uso intensivo de recursos, que afirma um aumento duas vezes no desempenho por watt de consumo de energia em comparação com seu antecessor.

Cérebras WSE-3. Fonte da imagem: Cerebras
A área do novo processador é de 46.225 mm2. É produzido usando a tecnologia de processo de 5 nm da TSMC, contém 4 trilhões de transistores, 900.000 núcleos e é combinado com 44 GB de memória SRAM integrada. Seu desempenho em operações FP16 é declarado em 125 Pflops.
Um WSE-3 forma a base para a nova plataforma de computação Cerebras CS-3, que a empresa afirma oferecer o dobro do desempenho da plataforma CS-2 anterior, mantendo o mesmo consumo de energia de 23 kW. Comparada ao acelerador Nvidia H100, a plataforma Cerebras CS-3 baseada em WSE-3 é fisicamente 57 vezes maior e aproximadamente 62 vezes mais rápida em operações FP16. Mas dado o tamanho e consumo de energia do Cerebras CS-3, seria mais justo compará-lo com a plataforma Nvidia DGX com 16 aceleradores H100. É verdade que mesmo neste caso, o CS-3 é cerca de 4 vezes mais rápido que o seu concorrente, se estivermos falando especificamente das operações do FP16.

Cérebras CS-3
Uma das principais vantagens dos sistemas Cerebras é o seu rendimento. Com 44 GB de SRAM integrado em cada WSE-3, o mais recente sistema Cerebras CS-3 oferece 21 PB/s de largura de banda. Para efeito de comparação, a Nvidia H100 com memória HBM3 tem uma taxa de transferência de 3,9 TB/s. No entanto, isso não significa que os sistemas Cerebras sejam mais rápidos em todos os casos de uso do que as soluções concorrentes. Seu desempenho depende do coeficiente de “escassez” das operações. A mesma Nvidia conseguiu com suas soluções dobrar o número de operações de ponto flutuante usando “esparsidade”. Por sua vez, a Cerebras afirma ter conseguido uma melhoria de até aproximadamente 8 vezes. Isso significa que o novo sistema Cerebras CS-3 será um pouco mais lento em operações FP16 mais densas do que um par de servidores Nvidia DGX H100 com o mesmo consumo de energia e área ocupada, e fornecerá cerca de 15 Pflops de desempenho contra 15,8 Pflops da Nvidia (16 aceleradores H100 produzir 986 teraflops de desempenho).

Uma das instalações do Condor Galaxy AI
A Cerebras já está trabalhando na implementação do CS-3 como parte de seu superaglomerado Condor Galaxy AI, projetado para resolver problemas de uso intensivo de recursos usando IA. Este projeto foi iniciado no ano passado com o apoio do G42. No seu âmbito, está prevista a criação de nove supercomputadores em diferentes partes do mundo. Os dois primeiros sistemas, CG-1 e CG-2, foram montados no ano passado. Cada um deles conterá 64 plataformas Cerebras CS-2 com desempenho combinado de IA de 4 exaflops.
A Cerebras anunciou nesta quarta-feira que construirá o sistema CG-3 em Dallas, no Texas. Ele usará vários CS-3s com um desempenho total de IA de 8 exaflops. Se assumirmos que os seis locais restantes também usarão 64 sistemas CS-3, então o desempenho total do superaglomerado Condor Galaxy AI será de 64 exaflops. Cerebras observa que a plataforma CS-3 pode escalar até 2.048 aceleradores com desempenho total de até 256 exaflops. Segundo especialistas, tal supercomputador será capaz de treinar o modelo Llama 70B da Meta✴ em apenas 24 horas.
Além de anunciar novos aceleradores de IA, a Cerebras também anunciou uma colaboração com a Qualcomm para criar modelos otimizados para aceleradores de IA da Qualcomm com arquitetura Arm. Ambas as empresas têm sugerido uma possível colaboração desde novembro do ano passado. Ao mesmo tempo, a Qualcomm lançou seus próprios aceleradores de IA Cloud AI100 Ultra no formato PCIe. Possui 64 núcleos AI, 128 GB de memória LPDDR4X com largura de banda de 548 GB/s, desempenho de 870 TOPS INT8 e um TDP de 150 W.

Fonte da imagem: Qualcomm
A Cerebras observa que trabalhará com a Qualcomm para otimizar modelos para Cloud AI100 Ultra que aproveitarão técnicas como dispersão, decodificação especulativa, MX6 e descoberta de arquitetura de rede.
«Como já mostramos, a dispersão, quando implementada corretamente, pode melhorar significativamente o desempenho dos aceleradores. A decodificação especulativa foi projetada para melhorar a eficiência da implantação do modelo usando um modelo pequeno e leve para gerar uma resposta inicial e, em seguida, usando um modelo maior para testar a precisão dessa resposta”, disse Andrew Feldman, CEO da Cerebras.
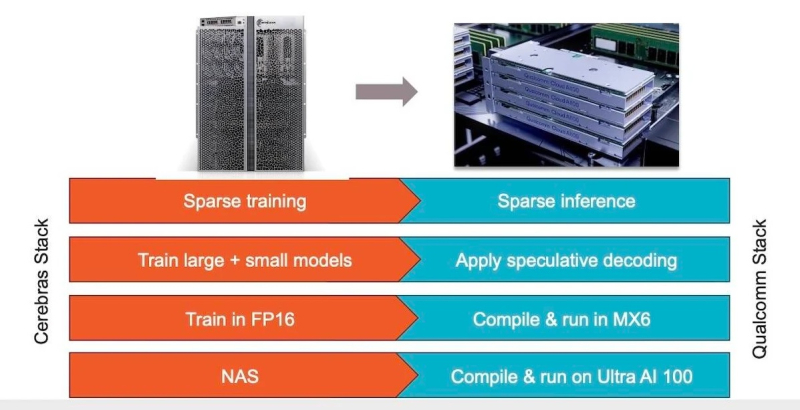
Ambas as empresas também consideram usar o método MX6, que é uma forma de comprimir o tamanho do modelo reduzindo sua precisão. Por sua vez, a busca pela arquitetura de redes é o processo de automatização do projeto de redes neurais para tarefas específicas, a fim de melhorar seu desempenho. A combinação dessas técnicas resulta em um aumento de dez vezes na produtividade por dólar, segundo a Cerebras.