
A AMD respondeu à recente declaração da NVIDIA de que os aceleradores de computação NVIDIA H100, usando bibliotecas TensorRT-LLM otimizadas para cálculos de IA, são mais rápidos na conclusão de tarefas do que os novos aceleradores AMD Instinct MI300X. Segundo a AMD, seus aceleradores ainda ganham.

Fonte da imagem: WCCFTech
Dois dias antes, a NVIDIA divulgou seus resultados de benchmark para seus aceleradores de computação dedicados Hopper H100 e disse que eles eram significativamente mais rápidos do que os mais recentes aceleradores MI300X AI da AMD, que foram revelados no evento Advancing AI da semana passada. Segundo a NVIDIA, a AMD, ao comparar seu MI300X com o H100, não utilizou bibliotecas de software TensorRT-LLM otimizadas especiais para este último, que aumentam a eficiência dos chips NIVDIA AI.
A NVIDIA publicou dados de seus testes usando as bibliotecas TensorRT-LLM, que mostraram uma vantagem de quase 50% sobre os aceleradores AMD MI300X. A AMD decidiu responder a esta afirmação mostrando em novos gráficos como o MI300X ainda é mais rápido que os aceleradores H100, mesmo que este último utilize uma pilha de software otimizada para eles. Segundo a AMD, a NVIDIA fornece seus dados:
- Baseado em testes H100 com bibliotecas TensorRT-LLM em vez de bibliotecas vLLM que foram usadas para testes de aceleradores AMD;
- Compara o desempenho dos aceleradores AMD Instinct MI300X em cálculos em números FP16 e usa dados FP8 para testar seu H100;
- Nos gráficos, inverti os dados de latência relativa da AMD em taxa de transferência absoluta.
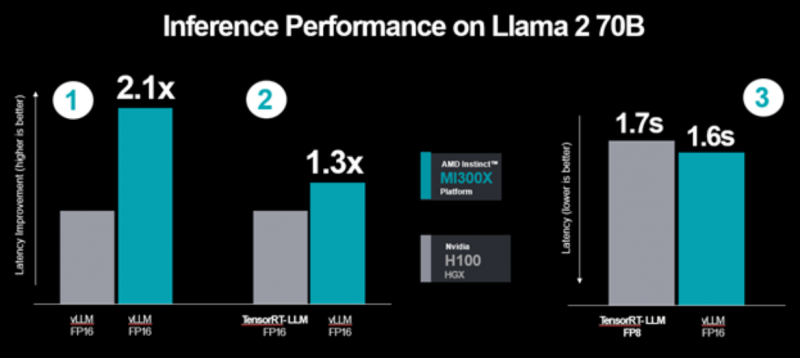
De acordo com novos testes da AMD, seus aceleradores MI300X executando bibliotecas vLLM são 30% mais produtivos do que os aceleradores NVIDIA H100, mesmo quando estes últimos executam bibliotecas TensorRT-LLM. Abaixo está um novo gráfico de resultados de testes para os aceleradores H100 e MI300X fornecidos pela AMD.
Fonte da imagem: Wccftech/AMD
Abaixo está a declaração da AMD.
- «Testes MI300X e H100 com bibliotecas vLLM
- Como parte do anúncio do MI300X no início de dezembro, informamos que nossa solução era 1,4 vezes mais rápida que o H100 em tipos de dados e software de cálculo equivalentes. Com nossas otimizações mais recentes, o MI300X tem desempenho 2,1 vezes mais rápido que seu concorrente;
- Escolhemos o vLLM com base em sua ampla adoção entre usuários e desenvolvedores e porque é compatível com GPUs AMD e NVIDIA.
- MI300X com vLLM vs H100 com bibliotecas TensorRT-LLM otimizadas
- Comparar o H100 otimizado para TensorRT-LLM com MI300X com vLLM mostra que MI300X com vLLM oferece desempenho 1,3 vezes melhor em operações FP16.
- Medições de latência para MI300X com tipo de dados FP16 versus H100 com tipo de dados TensorRT-LLM e FP8
- Os aceleradores MI300X continuam a demonstrar uma vantagem de desempenho ao medir a latência absoluta, mesmo quando o H100 com TensorRT-LLM é executado em tipos de dados FP8 e é comparado ao MI300X, que é executado em tipos de dados FP16 mais precisos. Nós (AMD) usamos o FP16 devido à sua popularidade, e os vLLMs também não suportam operações do FP8.
- “Os novos resultados mostram novamente que o MI300X tem desempenho comparável ao H100 em dados FP16 usando as configurações recomendadas pela NVIDIA que levam em consideração os tipos de dados FP8 e a estrutura de software TensorRT-LLM.”
A disputa pública entre AMD e NVIDIA demonstra mais uma vez que no segmento de computação de IA existe uma competição muito alta entre fabricantes de hardware que estão prontos para lutar por cada cliente.