
Material preparado pela equipe Catalyst. A opinião dos autores pode não coincidir com a opinião do editor
Hoje, as GPUs de alto desempenho são procuradas em todas as áreas do setor de TI, em projetos científicos, em sistemas de segurança e outras áreas. Engenheiros, arquitetos e designers precisam de computadores poderosos para renderização e animação 3D, treinamento de redes neurais e análise de dados, análise em tempo real e outras tarefas que envolvam uma grande quantidade de computação. Em geral, os servidores GPU de alto desempenho são uma solução muito popular no mercado.
Todos os anos, em todas as áreas, estão se tornando métodos cada vez mais comuns de inteligência artificial (IA) e aprendizado de máquina (ML). Essas tecnologias já estão revolucionando o campo do diagnóstico médico, ajudando a desenvolver instrumentos financeiros, criando novos serviços de processamento de dados, permitindo a implementação de vários projetos nos campos da ciência básica, robótica, gestão de recursos humanos, transporte, indústria pesada, economia urbana, reconhecimento de fala, pessoas e instalações de entrega de conteúdo. Por exemplo, a NVIDIA incentivou os proprietários de poderosos computadores GPU a usá-los para ajudar a combater o surto da pandemia de coronavírus COVID-19.
GPU como um serviço
Como muitas tarefas modernas de aprendizado de máquina usam GPUs, as pessoas estão cada vez mais confrontadas com a pergunta: o que escolher para esses fins? Para responder, é muito importante entender os indicadores de custo e desempenho de diferentes GPUs. Atualmente, vários provedores oferecem servidores virtuais, em nuvem (GPUaaS) e dedicados com GPUs para aprendizado de máquina.
Servidores dedicados são a melhor opção quando a capacidade de computação é necessária continuamente, e a manutenção de sua própria máquina é inútil ou simplesmente impossível. Alguns provedores alugam esses servidores mensalmente e, se você tiver o número necessário de tarefas que podem carregar esse servidor, em termos de horas e minutos, os preços podem ser muito atraentes. No entanto, na maioria dos casos, os servidores virtuais (VDS / VPS) com cobrança por horas ou minutos ou serviços em nuvem ainda são preferíveis, o que geralmente é mais barato e mais flexível.
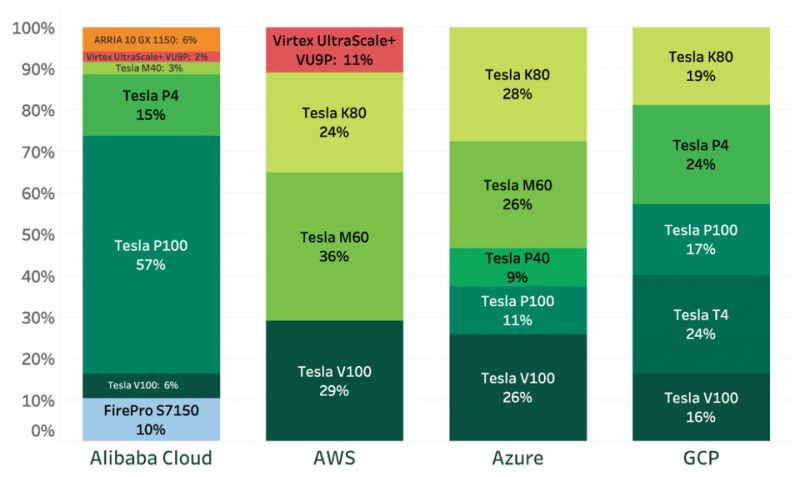
Ações de instâncias de GPU dedicadas de diferentes tipos de quatro principais fornecedores (de acordo com o Lliftr Cloud Insight, maio de 2019)
De acordo com o último relatório do Global Market Insights, o mercado global de GPUaaS excederá US $ 7 bilhões até 2025. Os participantes do mercado estão desenvolvendo soluções de GPU especificamente para aprendizagem profunda (DL) e IA. Por exemplo, o NVIDIA Deep Learning SDK fornece aceleração de GPU de alto desempenho para algoritmos de aprendizado profundo e foi projetado para criar estruturas DL prontas para uso.
As empresas GPUaaS se concentram em inovação tecnológica, aquisições estratégicas e fusões para fortalecer sua posição no mercado e adquirir novos clientes. Os principais players do mercado de GPUaaS incluem AMD, Autodesk, Amazon Web Services (AWS), Cogeco Communications, Dassault Systems, IBM, Intel, Microsoft, Nimbix, NVIDIA, Penguin Computing, Qualcomm, Siemens, HTC. Para aprendizado de máquina, as GPUs mais populares são AWS, Google Cloud Engine, IBM Cloud e Microsoft Azure.
Você também pode tirar proveito do poder dos aceleradores gráficos de fornecedores menos conhecidos – seus servidores GPU também são adequados para uma variedade de projetos. Cada plataforma tem seus prós e contras. Acredita-se que servidores de alto desempenho com GPUs poderosas permitem que você atinja rapidamente seus objetivos e obtenha resultados significativos, mas as instâncias caras valem o seu dinheiro e em que casos?
Aprenda e estude novamente
O processo de treinamento de um modelo é mais caro em termos de computação e requer muito mais recursos do que o necessário para executar um modelo já treinado. Se a tarefa não implicar algum tipo de carga ultra alta, como o reconhecimento facial de um grande número de câmeras, uma ou duas placas de nível GeForce GTX 1080 Ti são suficientes para funcionar, o que é muito importante para economizar o orçamento do projeto. As mais poderosas GPUs Tesla V100 modernas são geralmente usadas apenas para treinamento.
Além disso, a versão de trabalho do modelo pode funcionar mesmo com parte dos recursos da GPU – bem, ou uma placa pode ser usada para executar vários modelos. No entanto, essa abordagem não é adequada para treinamento devido aos recursos do dispositivo de barramento de memória e, para o treinamento de cada modelo, é usado um número inteiro de aceleradores gráficos. Além disso, o processo de aprendizado geralmente é um conjunto de experimentos para testar hipóteses, quando um modelo é treinado repetidamente do zero, usando vários parâmetros. Essas experiências são convenientemente executadas em paralelo em placas gráficas adjacentes.
O modelo é considerado treinado quando a precisão esperada é alcançada ou quando a precisão não aumenta mais com o treinamento adicional. Às vezes, no processo de treinamento do modelo, surgem gargalos. Operações auxiliares como pré-processamento e download de imagens podem exigir muito tempo do processador – isso significa que a configuração do servidor não foi balanceada para esta tarefa específica: a CPU não é capaz de “alimentar” a GPU.
Isso se aplica igualmente a servidores dedicados e virtuais. Em um servidor virtual, esse problema também pode ser causado pelo fato de uma CPU atender a várias instâncias. O processador dedicado está à disposição total, mas seus recursos ainda podem ser insuficientes. Simplificando, em muitas tarefas, o poder do processador central é importante para que seu desempenho seja suficiente para o processamento de dados no estágio inicial.
Esquema de treinamento de modelo simplificado
O treinamento em várias (N) GPUs é o seguinte:
Um conjunto de fotos é tirado, dividido em N partes e “decomposto” em aceleradores;
Para cada acelerador, o erro é calculado em seu próprio conjunto de imagens e no gradiente futuro (a direção na qual os coeficientes devem ser alterados para que o erro se torne menor);
Os gradientes de todos os aceleradores são coletados em um deles e adicionados;
O modelo dá um passo nessa direção média em um acelerador e aprende;
Um modelo novo e aprimorado é enviado para o restante das GPUs e a etapa 1 é repetida.
Se o modelo for muito leve, a execução de N desses ciclos em uma GPU será mais rápida que a distribuição em N GPUs com a combinação subsequente dos resultados. Além disso, com experimentos ativos com o modelo, os custos financeiros podem ser muito significativos. Ao testar muitas hipóteses, o tempo de cálculo às vezes se estende por muitos dias, e as empresas às vezes gastam, por exemplo, dezenas de milhares de dólares por mês na locação de servidores do Google.
Catalisador para o resgate
O Catalyst é uma biblioteca de alto nível que permite realizar pesquisas de aprendizado profundo e desenvolver modelos de maneira mais rápida e eficiente, reduzindo a quantidade de código padrão. O Catalyst assume o dimensionamento dos pipelines e permite o treinamento rápido e reproduzível de um grande número de modelos. Assim, você pode fazer menos programação e se concentrar mais no teste de hipóteses. A biblioteca inclui várias das melhores soluções do setor, além de pipelines prontos para classificação, detecção e segmentação.
Recentemente, a equipe do Catalyst fez uma parceria com a Georgia State University, o Georgia Institute of Technology e o centro conjunto de Pesquisa Translacional em Neuroimagem e Ciência de Dados da Universidade Emory (TReNDS) para simplificar o treinamento de modelos para aplicativos de neuroimagem e fornecer estudos de Aprendizagem Profunda reproduzíveis em imagens cerebrais. Trabalhar juntos nessas questões importantes ajudará você a entender melhor como o cérebro funciona e melhorar a qualidade de vida das pessoas com transtornos mentais.
Voltando ao assunto do artigo, o Catalyst foi usado nos três casos para verificar a velocidade dos servidores: nos servidores HOSTKEY, Amazon e Google. Então compare como foi.
Usabilidade
Um indicador importante é a usabilidade da solução. Apenas alguns serviços oferecem um conveniente sistema de gerenciamento de servidor virtual com as bibliotecas e instruções necessárias sobre como usá-los. Ao usar o Google Cloud, por exemplo, você precisa instalar as bibliotecas. Aqui está uma avaliação subjetiva das interfaces da web:
Serviço
Interface da web
Aws
Anti-leader: todas as configurações são codificadas com nomes no estilo p2.xlarge – para entender qual hardware está oculto sob cada nome, você precisa ir para uma página separada e existem cerca de cem nomes
Google
Classificação média, configuração não muito intuitiva de instâncias
Colab do Google
Caderno analógico Jupyter
Hostkey
Serviço da Web não usado
De fato, para começar a usar essas ferramentas, leva de 20 a 60 minutos (dependendo das qualificações) para preparar – instalar o software e fazer o download dos dados. Quanto à conveniência de usar instâncias já emitidas e prontas para uso, a situação aqui é a seguinte:
Serviço
Conjunto de software
Aws
O líder absoluto, em uma instância, existem todas as versões populares de bibliotecas de aprendizado de máquina + NVIDIA-Docker pré-instalado. Há um arquivo Leiame com informações breves sobre como alternar entre versões de toda essa diversidade.
Google
Comparável ao HOSTKEY, mas você pode montar seu Google-drive e ter acesso muito rápido ao conjunto de dados sem a necessidade de transferi-lo para a instância.
Colab do Google
É oferecido gratuitamente, mas a cada 6 a 10 horas a instância “morre”. Não há software limpo, incluindo o Docker + NVIDIA-Docker2, além da capacidade de instalá-los, embora você possa ficar sem eles. Não há conexão SSH direta, mas é possível o acesso rápido ao Google drive.
Hostkey
O servidor pode ser fornecido sem software e já totalmente configurado. Para o autoajuste, você pode usar o software na forma de Docker + NVIDIA-Docker2. Para um usuário experiente, isso não é um problema.
Resultados da Experiência
Uma equipe de especialistas do projeto Catalyst realizou um teste comparativo do custo e da velocidade do treinamento do modelo usando a GPU NVIDIA nos servidores dos seguintes provedores: HOSTKEY (de um a três GeForce GTX 1080 Ti + Xeon E3), Google (Tesla T4) e AWS (Tesla K80). Os testes usaram a arquitetura ResNet padrão para essas tarefas de visão computacional, que determinaram os nomes dos artistas de suas pinturas.
No caso do HOSTKEY, havia duas opções de acomodação. Primeiro: uma máquina física com uma ou três placas de vídeo, CPU Intel Xeon E5-2637 v4 (4/8, 3,5 / 3,7 GHz, cache de 15 MB), 16 GB de RAM e SSD de 240 GB. Segundo: um servidor VDS virtual dedicado na mesma configuração com uma placa de vídeo. A única diferença é que, no segundo caso, o servidor físico possui oito cartões ao mesmo tempo, mas apenas um deles é entregue à disposição total do cliente. Todos os servidores estavam localizados no data center na Holanda.
As instâncias de ambos os provedores de nuvem foram lançadas nos data centers de Frankfurt. No caso da AWS, a variante p2.xlarge foi usada (Tesla K80, 4 vCPU, 61 GB de RAM) e parte do tempo do computador era gasta na preparação de dados. Uma situação semelhante ocorreu na nuvem do Google, onde uma instância com 4 vCPUs e 32 GB de memória foi usada, à qual um acelerador foi adicionado. O cartão Tesla T4, mesmo focado em inferência, foi escolhido porque está localizado em algum lugar entre o GTX 1080 Ti e o Tesla V100 em termos de desempenho do treinamento. Portanto, na prática, ainda é usado algumas vezes para treinamento, pois custa muito menos que o V100.
Uma tabela comparando o tempo de treinamento e o custo de treinamento do modelo em diferentes plataformas
Plataforma
GPU
GPU
Modelo
Qualidade Total, CUA
Tempo de treinamento, s
Custo de treinamento, ¢ / s
Propinas, €
Hostkey
1 × GeForce GTX 1080 Ti VDS
1 1
Pesado
0,9835
7 581
0,0062
0,47
Hostkey
1 × GeForce GTX 1080 Ti
1 1
Pesado
0,9835
7 092
0,0062
0,44
Hostkey
3 × GeForce GTX 1080 Ti
3
Pesado
0,9835
2.430
0,0202
0,49
Aws
1 × Tesla K80
1 1
Pesado
0,9835
13 080
0,0429
5,61
Google
1 × Tesla T4
1 1
Pesado
0,9835
1 003
0,4087
4,50
Hostkey
1 × GeForce GTX 1080 Ti VDS
1 1
Fácil
0,9091
1.445
0,0062
0,09
Hostkey
1 × GeForce GTX 1080 Ti
1 1
Fácil
0,9091
1.157
0,0061
0,07
Aws
1 × Tesla K80
1 1
Fácil
0,9091
3 930
0,0545
2,14
Google
1 × Tesla T4
1 1
Fácil
0,9091
872
0,2294
2,00
O modelo foi utilizado em duas versões: “pesado” (resnet101) e “leve” (resnet34). A versão pesada tem o melhor potencial para obter alta precisão, enquanto a versão leve oferece um aumento maior no desempenho com mais alguns erros. Modelos mais pesados são geralmente usados onde é necessário obter o máximo de resultados como uma previsão, por exemplo, ao participar de competições, enquanto os leves – em locais onde é necessário manter um equilíbrio entre precisão e velocidade de processamento, por exemplo, em sistemas carregados que processam dezenas de milhares de solicitações diariamente .
O custo do treinamento de um modelo em um servidor HOSTKEY com placas “domésticas” é quase uma ordem de magnitude menor do que no caso do Google ou da Amazon, e leva um pouco mais de tempo. E isso apesar do fato de a GeForce GTX 1080 Ti estar longe de ser a placa mais rápida para resolver tarefas de aprendizado profundo hoje. No entanto, como os resultados experimentais mostram, em geral, placas de baixo custo como a GeForce GTX 1080 Ti não são tão piores que suas contrapartes mais caras em termos de velocidade, devido ao seu custo significativamente menor.
Se a placa é uma ordem de magnitude mais barata, no desempenho em modelos pesados ela é apenas 2-3 vezes inferior, e você pode aumentar a velocidade adicionando mais placas. De qualquer forma, essa solução será mais barata que as configurações da Tesla em termos de custo de treinamento do modelo. Os resultados também mostram que o Tesla K80 na AWS, que demonstra alto desempenho em computação de precisão dupla, mostra um tempo muito longo com precisão única – pior que 1080 Ti.
Conclusões
A tendência geral é a seguinte: placas gráficas mais baratas no nível do consumidor oferecem melhores taxas de preço / desempenho do que as caras GPUs Tesla. A perda na velocidade “pura” da GTX 1080 Ti em comparação com a Tesla pode ser compensada por um aumento no número de cartões, enquanto ainda está ganhando.
Se você planeja executar uma tarefa que leva muito tempo para ser calculada, haverá servidores suficientes com o GTX 1080 Ti barato. Eles são adequados para usuários que planejam trabalho de longo prazo com esses recursos. Instâncias caras baseadas em Tesla devem ser selecionadas nos casos em que o treinamento do modelo leva pouco tempo e você pode cobrar pelo trabalho a cada minuto do treinamento.
Você também deve considerar a simplicidade de preparar o ambiente nas plataformas – instalar bibliotecas, implantar software e fazer download de dados. Os servidores de GPU – reais e virtuais – ainda são visivelmente mais caros do que as instâncias de CPU clássicas, portanto, os longos tempos de preparação levam a custos extras.
.