
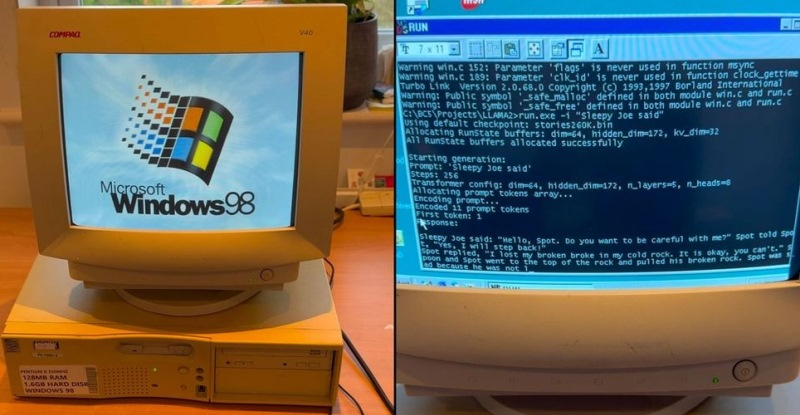
Especialistas do EXO Labs conseguiram executar um Llama de modelo de linguagem grande (LLM) bastante poderoso em um computador de 26 anos rodando o sistema operacional Windows 98. Os pesquisadores mostraram claramente como um PC antigo equipado com um processador Intel Pentium II com um processador Intel Pentium II funciona. frequência de operação de 350 MHz e 128 MB de RAM, após a qual a rede neural é iniciada e interage posteriormente com ela.
Fonte da imagem: GitHub
Para executar o LLM, os especialistas do EXO Labs usaram sua própria interface de saída para o algoritmo Llama98.c, que foi criado com base no mecanismo Llama2.c, escrito na linguagem de programação C pelo ex-funcionário da OpenAI e da Tesla, Andrej Karpathy. Depois de carregar o algoritmo, ele foi solicitado a criar uma história sobre Sleepy Joe. Surpreendentemente, o modelo de IA realmente funciona mesmo em um PC tão antigo, e a história é escrita em boa velocidade.
A misteriosa organização EXO Labs, formada por pesquisadores e engenheiros da Universidade de Oxford, emergiu das sombras em setembro deste ano. Ela supostamente defende a abertura e acessibilidade de tecnologias baseadas em inteligência artificial. Os representantes da organização acreditam que as tecnologias avançadas de IA não deveriam estar nas mãos de um punhado de empresas, como é o caso agora. No futuro, eles esperam “construir uma infraestrutura aberta para treinar modelos avançados de IA, permitindo que qualquer pessoa os execute em qualquer lugar”. Demonstrar a capacidade de executar o LLM em um PC antigo, na opinião deles, prova que os algoritmos de IA podem ser executados em praticamente qualquer dispositivo.
Em seu blog, os entusiastas disseram que para realizar a tarefa, adquiriram um PC antigo com Windows 98 no eBay. Depois, ao conectar o aparelho à rede por meio de um conector Ethernet, conseguiram transferir os dados necessários para a memória do aparelho via. FTP. Provavelmente, compilar código moderno para Windows 98 acabou sendo uma tarefa mais difícil, que foi resolvida pelo trabalho de Andrei Karpaty publicado no GitHub. No final das contas, conseguimos atingir uma velocidade de geração de texto de 35,9 tokens por segundo usando um LLM de 260K com a arquitetura Llama, o que é muito bom considerando as modestas capacidades de computação do dispositivo.