

No momento, a NVIDIA apresentou apenas um processador gráfico de última geração, o Ampere – o principal GA100, que formou a base do acelerador de computação NVIDIA A100. E agora o chefe da empresa OTOY, especializada em renderização em nuvem, compartilhou os primeiros resultados de teste deste acelerador.
A GPU Ampere GA100 usada no NVIDIA A100 inclui 6912 núcleos CUDA e 40 GB de RAM HBM2. A própria GPU é fabricada usando uma tecnologia de processo de 7 nm nas instalações da TSMC. O acelerador de computação está disponível nas versões com interfaces PCIe 4.0 e SXM4. Inicialmente, os aceleradores NVIDIA A100 estão disponíveis como parte dos sistemas de computação proprietários NVIDIA DGX A100, que incluem até oito GPUs.
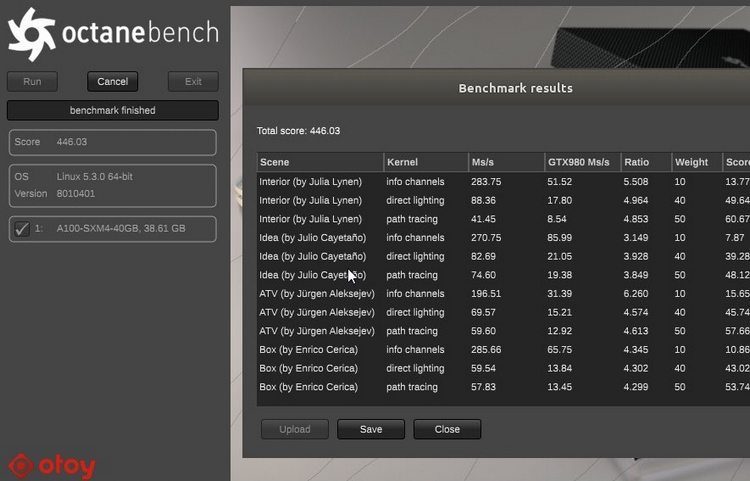
O NVIDIA A100 Compute Accelerator foi testado no benchmark OctaneBench não tão popular, que testa o desempenho da GPU ao renderizar com o mecanismo Octane Render. Ele se baseia na tecnologia NVIDIA CUDA, o que significa que só pode ser renderizado ao usar as GPUs NVIDIA. E a empresa mencionada OTOY está desenvolvendo esse mecanismo.

É relatado que o acelerador NVIDIA A100 mostrou um resultado recorde no OctaneBench, que foi de 446 pontos. Para comparação, a NVIDIA Titan V, baseada em Volta, obteve 401 pontos (11% a menos), enquanto a placa gráfica mais rápida da geração Turing, a Quadro RTX 8000, obteve apenas 328 pontos (43% atrás).
Portanto, o alto desempenho teórico do processador Ampere se traduz em uma velocidade de renderização mais rápida. Lembre-se de que o desempenho máximo do NVIDIA A100 é de 19,5 e 9,7 teraflops com precisão única e dupla, respectivamente. Ao mesmo tempo, o mencionado Quadro RTX 8000 da geração Turing pode oferecer desempenho apenas nos níveis de 16.0 e 0.5 teraflops.