
Hoje, a relevância da lei de Moore levanta cada vez mais questões, por isso os cientistas da NVIDIA propuseram um novo olhar para o futuro da computação: a lei de Huang. Nomeada em homenagem ao fundador e CEO da NVIDIA, Jensen Huang, esta lei pressupõe que o impulso que vimos no desempenho do processador continuará no futuro, impulsionado em grande parte pela engenhosidade humana.

Fonte da imagem: NVIDIA
A principal diferença entre a Lei de Huang e a Lei de Moore é a ênfase na inovação arquitetônica e algorítmica, em vez de simplesmente dobrar o número de transistores em um chip a cada dois anos por meio da redução do tamanho do processo. O cientista-chefe da NVIDIA, Bill Dally, destacou na recente conferência Hot Chips 2023 que a transição da tecnologia de processo de 28nm para 5nm ao longo de uma década trouxe apenas um aumento de 2,5x no desempenho, enquanto a maior parte do crescimento foi alcançada por meio de inovações importantes na arquitetura e processamento de números.
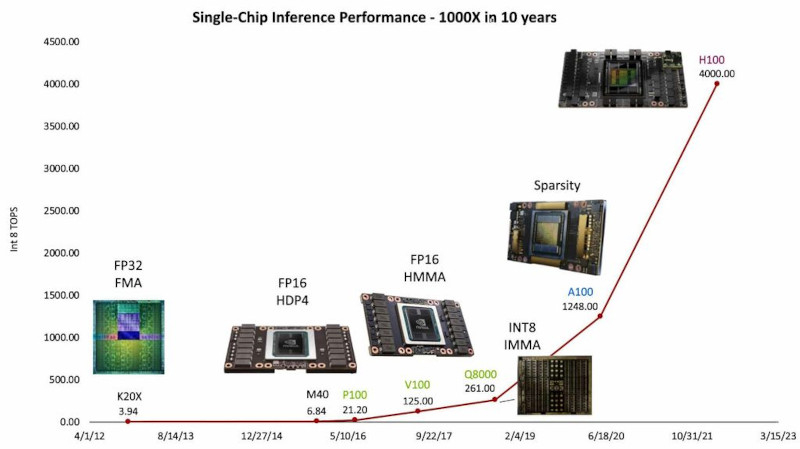
A principal contribuição para o aumento de 1.000 vezes na produtividade foi a simplificação da representação dos números utilizados pelos computadores para cálculos. A introdução da arquitetura NVIDIA Hopper com o motor Transformer tornou possível dar um passo significativo na aceleração do processo de treinamento de modelos de IA. Os núcleos tensores Hopper, que podem misturar formatos de ponto flutuante de 8 e 16 bits, tornaram-se essenciais para acelerar os cálculos de IA no treinamento de transformadores (um certo tipo de redes neurais profundas) sem comprometer a precisão necessária. Esta inovação permite os mais altos níveis de eficiência computacional, o que é fundamental para os desafios atuais de IA.
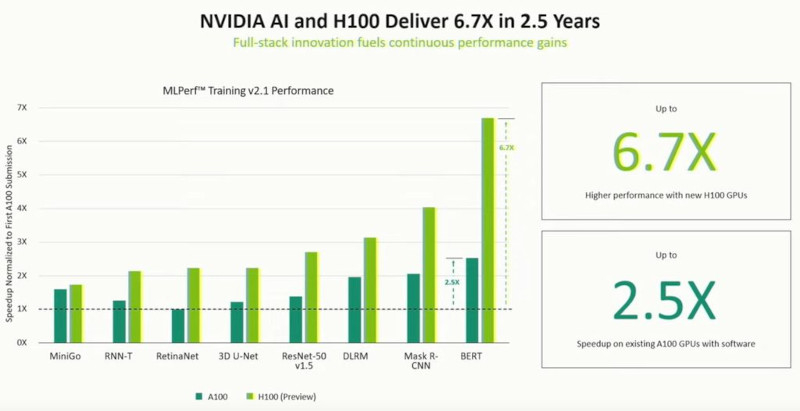
Além disso, o desempenho das operações de ponto flutuante nos formatos de 32 bits, 64 bits, 16 bits e formatos inteiros de 8 bits triplicou, o que também contribuiu para a aceleração geral dos processos de computação. Combinados com o mecanismo Transformer e a tecnologia NVIDIA NVLink de quarta geração, os Hopper Tensor Cores oferecem aceleração de ordem de magnitude para computação de alto desempenho (HPC) e cargas de trabalho de IA.
Além disso, a equipe de Daly, composta por mais de 300 pessoas na NVIDIA Research, desenvolveu instruções avançadas que permitem à GPU organizar seu trabalho de forma mais eficiente, economizando energia e aumentando o desempenho em 12,5 vezes. Inovações como a dispersão estrutural na arquitetura NVIDIA Ampere proporcionam um aumento adicional de 2x no desempenho sem comprometer a precisão dos modelos de IA.
Essa mudança de foco está abrindo caminho para arquiteturas e algoritmos novos e mais eficientes, tornando este um momento extremamente emocionante para profissionais de engenharia da computação e design de chips. A indústria da tecnologia da informação parece estar a abrir-se a uma nova era de oportunidades, onde o génio humano e a inovação são os principais motores do progresso.