

Foto original (esquerda) e uma variação de seu tema gerada usando o modo de controle Canny da ferramenta ControlNet (fonte: esquerda – PX Aqui, direita – geração de IA baseada no modelo SD 1.5)
Antes de embarcar em uma introdução mais detalhada ao ControlNet do que da última vez, seria útil relembrar o conteúdo dos artigos anteriores da série “AI Drawing Workshop”:
- O primeiro tratou da instalação inicial do modelo generativo Stable Diffusion 1.5 com todas as dependências necessárias em um PC local com placa de vídeo minimamente adequada para tal tarefa (foi utilizada uma máquina com uma GeForce GTX 1070 8 GB, mas em princípio 6 ou mesmo 4 GB teriam sido suficientes),
- O segundo descreveu o ambiente de trabalho AUTOMATIC1111, indicou os principais controles para geração de imagens nele e deu um exemplo de criação de uma imagem na resolução básica de 512 × 768 pixels com seu posterior dimensionamento (não simples, mas implicando aumento de detalhes) para 3584 × 2560,
- No terceiro, houve um conhecimento casual do mais recente desenvolvimento do Stability.ai na época – o modelo generativo SDXL 1.0; foi demonstrado como atualizar o ambiente de trabalho AUTOMATIC1111 e complementar sua funcionalidade com extensões externas,
- Na quarta, prestamos mais atenção ao SDXL 1.0 e um dos mais adequados para trabalhar com este modelo, embora não seja o ambiente de trabalho mais fácil de aprender, o ComfyUI,
- Na quinta, foram dadas as instruções mais gerais sobre como alterar as configurações (bastante sutis) do AUTOMATIC1111 para que as imagens produzidas pelo sistema correspondam com mais precisão à intenção do operador,
- Na sexta, examinamos brevemente (novamente, com ênfase em SD 1.5 e AUTOMATIC1111) ferramentas de detalhamento inteligentes que permitem, em um computador relativamente fraco, criar telas digitais com milhares e dezenas de milhares de pixels de cada lado, não apenas sem perda de qualidade, mas com o seu aumento , – Contratações. correção, ADetailer e ControlNet.
No entanto, esta última é uma ferramenta significativamente mais multifuncional – na verdade, um conjunto de redes neurais adicionais que podem enriquecer significativamente o arsenal de um artista de IA. Começaremos a falar sobre que tipo de redes neurais são essas e como exatamente elas podem ser úteis neste artigo – talvez apenas comecemos, porque uma descrição completa dos recursos do ControlNet será necessariamente bastante extensa.
⇡#Verificação do motor
Qualquer software em desenvolvimento ativo recebe atualizações constantemente, e o ambiente de trabalho AUTOMATIC1111 não é exceção. No quinto episódio do AI Drawing Workshop, já mostramos como verificar novas versões – basta executar o comando git pull na janela do Git Bash aberta no diretório de instalação deste ambiente.
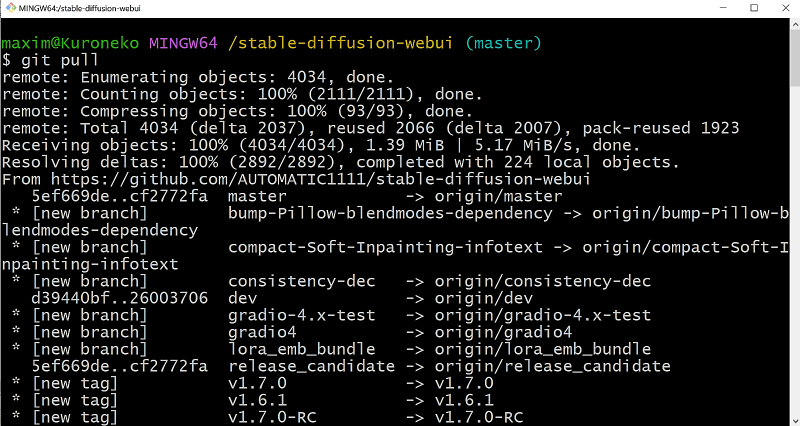
Após a conclusão da execução deste comando, o AUTOMATIC1111 será atualizado – e deverá ser iniciado da maneira usual, clicando duas vezes no arquivo webui-user.bat no Explorer. No momento em que este artigo foi escrito, a versão atual do ambiente de trabalho era 1.8.0 e esse número era exibido na parte superior da janela do servidor AUTOMATIC1111 que é aberta.
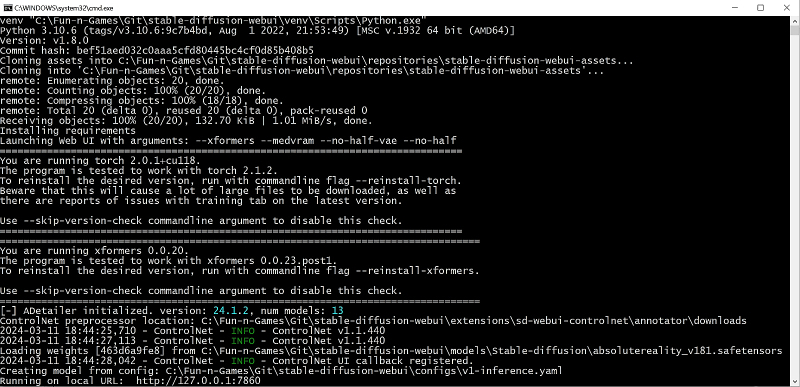
O ambiente de trabalho, quando iniciado pela primeira vez após a atualização, detectará automaticamente os pacotes ausentes (ou seja, as versões mais recentes do torch e xformers), se houver, e se oferecerá para instalá-los. Você não precisa fazer isso, mas, via de regra, novas versões desses pacotes proporcionam geração mais rápida de imagens e processamento mais correto de dicas de ferramentas, portanto você não deve negligenciá-las.

Na verdade, a instalação do torch versão 2.1.2 e do xformers versão 0.0.23.post1 será feita em modo semiautomático, sem exigir que o operador do ambiente de trabalho tenha qualquer conhecimento de programação Python ou dos meandros da atualização do Git sistema. Você só precisa adicionar alguns argumentos apropriados ao arquivo inicial, webui-user.bat, para que a linha para passar parâmetros de chamada para o sistema fique assim:
Definir COMMANDLINE_ARGS=–reinstall-torch –reinstall-xformers –xformers –medvram –no-half-vae –no-half
E não como antes:
Definir COMMANDLINE_ARGS=–xformers –medvram –no-half-vae –no-half
Claro, para fazer tudo corretamente, você precisa parar o servidor AUTOMATIC1111 (é melhor não apenas fechar sua janela usando “Alt” + “F4”, mas primeiro executando o comando de interrupção, “Ctrl” + “C” , e digitando “y” em resposta ao prompt que aparece “), abra webui-user.bat em um editor de texto simples como o Bloco de Notas e faça as correções apropriadas e, em seguida, reinicie o sistema.

Você pode, em teoria, deixar os comandos para reinstalar o torch e o xformers no arquivo inicial para sempre – neste caso, eles serão atualizados toda vez que você iniciar o ambiente de trabalho, assim que as atualizações correspondentes aparecerem no repositório online. No entanto, por razões de estabilidade do sistema, é ainda mais sensato monitorar cuidadosamente as mensagens do servidor AUTOMATIC1111 na inicialização – e atualizar o software correspondente somente após o próprio ambiente de trabalho sugerir isso. Portanto, depois de aguardar a conclusão do download e da instalação de novos pacotes, faz sentido fechar o servidor novamente, retornar o arquivo webui-user.bat ao seu estado anterior (sem –reinstall-torch —reinstall-xformers) e reinicie o sistema – agora completamente pronto para uso.
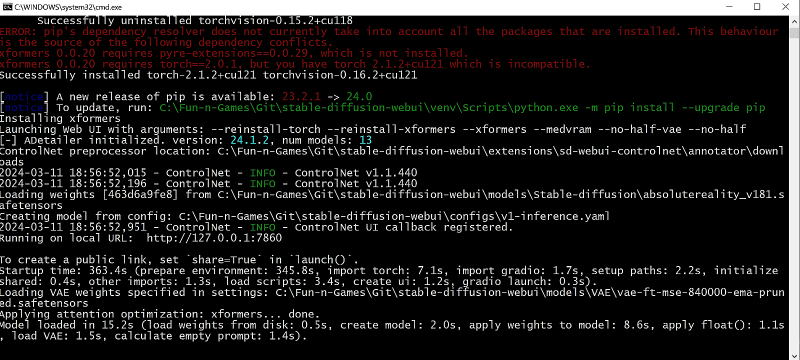
Lembramos que se durante o processo de instalação o sistema indicar o surgimento de uma nova versão do pacote pip, que serve para gerenciar atualizações no Git, a forma mais fácil de atualizá-lo é diretamente na linha de comando do Painel de Controle do Windows . Você só precisa especificar o caminho correto para a versão do Python que o AUTOMATIC1111 usa e os argumentos de inicialização corretos.
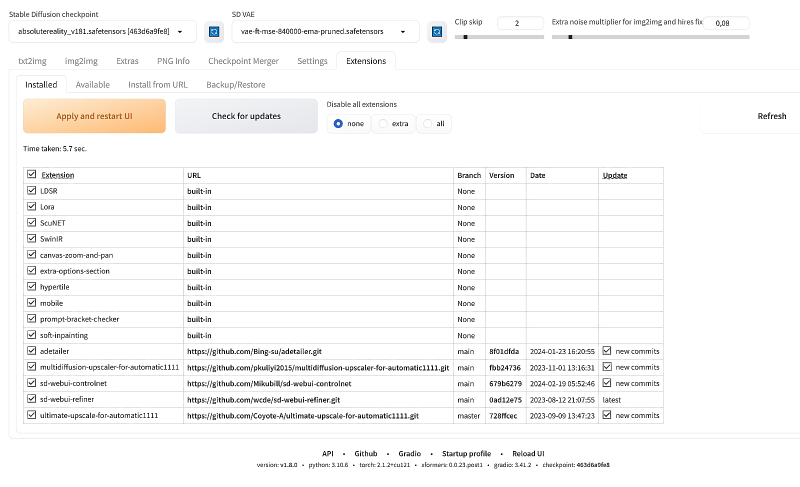
Tendo atualizado o próprio ambiente de trabalho, vamos perguntar se há alguma nova versão das extensões instaladas nele anteriormente (durante os seis episódios anteriores do “AI Drawing Workshop”). Para fazer isso, como antes, vá até a aba “Extensões” da interface web e clique no grande botão cinza “Verificar atualizações”. Se houver atualizações – isso é evidenciado pela marca “novas confirmações” na coluna “Atualizações” – você precisará clicar em “Aplicar e reiniciar UI”, após o que, para ter certeza, por precaução, reinicie também completamente o Servidor AUTOMATIC1111 (novamente com “Ctrl ” + “C” e a próxima execução de webui-user.bat).
⇡#Geração sob supervisão
A arquitetura da rede neural, conhecida pelos entusiastas da IA como ControlNet, é baseada em um artigo científico de 2023 sobre a adição de uma ferramenta de controle adicional aos modelos de difusão para converter sinais de texto em imagens estáticas.
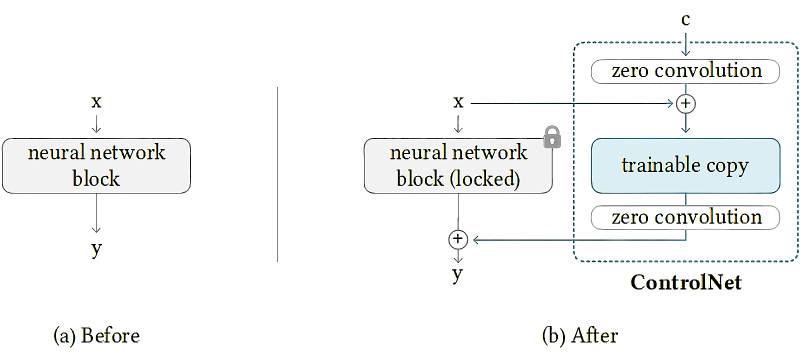
Como funciona o ControlNet (fonte: Git Hub)
A essência do método proposto pelos pesquisadores é simples: em vez de treinar sempre o modelo original, adicionando algumas conexões adicionais a ele, é preciso treinar sua cópia. Com isso, a cópia modificada adquire a capacidade de fazer o que o original também era inicialmente capaz, mas com muito menos eficiência: por exemplo, detectar e reconhecer corretamente as poses de figuras humanas em imagens, as bordas dos objetos, a “profundidade do quadro” (quais objetos estão localizados em primeiro plano, quais estão mais ao longo da linha de visão) e assim por diante.
Sim, uma cópia treinada para um determinado truque perde a amplitude de capacidades do original, mas o modelo original em si não desaparece; mas o tamanho (expresso no número de pesos diferentes de zero usados pelo modelo ou diretamente em unidades de informação, mega e gigabytes) desta cópia torna-se significativamente menor. A combinação do modelo original e adicionalmente treinado – controlador – dentro de um único ciclograma de trabalho permite uma arquitetura neural com “convoluções zero” (convoluções zero; camadas de convolução com inicialização zero), que protegem os pesos do modelo original da influência do ruído parasita do controlador fundiu-se com ele. Você pode ler mais sobre isso, por exemplo, na página oficial do projeto ControlNet no Git Hub.

Foto original (esquerda) e uma variação de seu tema gerada usando o modo de controle SoftEdge da ferramenta ControlNet (fonte: esquerda – PX Aqui, direita – geração de IA baseada no modelo SD 1.5)
Resumindo e mais especificamente, o ControlNet permite gerar figuras em poses especificadas pelo operador, reproduzir a composição da imagem original (no sentido mais amplo, desde a posição relativa dos objetos no quadro até suas cores), criar uma imagem que é muito semelhante ao original, mas ainda assim certamente diferente dele, transforme um esboço em um desenho completo ou mesmo em uma imagem fotorrealista – e muito mais. Essencialmente, ControlNet é uma rede neural para controlar uma rede neural, nomeadamente o modelo generativo de difusão estável, adicionando outro ao conjunto usual de parâmetros (dicas de texto, número de etapas, CFG, ponto de verificação, etc.) – mais frequentemente especificado por uma imagem. Na verdade, começamos a falar sobre como funcionam os modos de controle ControlNet mais comumente usados - Canny, Depth e OpenPose – na última edição do AI Drawing Workshop.
Também indicou como instalar a extensão ControlNet para o ambiente operacional AUTOMATIC1111. Esta ferramenta também foi desenvolvida para ComfyUI e SDXL 1.0 (pelo menos modos de controle separados, incluindo Canny, Depth e OpenPose), mas para PCs com menos de 8 GB de RAM de vídeo, é o primeiro ambiente de trabalho em combinação com SD 1.5 que continua ser ideal com base em um conjunto de parâmetros, como os recursos de hardware necessários para sua operação, o tempo de geração de uma única imagem condicional e a amplitude de possibilidades de ajuste fino/experimentação com parâmetros disponíveis para alteração.
O menu suspenso disponível após a instalação do ControlNet para trabalhar com esta rede neural está localizado na interface web AUTOMATIC1111 na aba “txt2img”, logo abaixo de “Tiled VAE”. Existem muitas opções, mas você não deve ter medo de sua variedade: a princípio quase tudo funciona perfeitamente nas posições padrão. Diferentes modos de controle são bons para diferentes casos: por exemplo, MLSD é especializado para pesquisar e destacar linhas retas em uma imagem (e, portanto, é ótimo para trabalhar com imagens arquitetônicas) e Scribble/Sketch é para processar esboços e esboços. Na verdade, não apenas um desenho realmente grosseiro e primitivo, mas também quase qualquer imagem com contornos bem definidos pode funcionar como um esboço. Por exemplo, tomando como base a foto de um jovem esportivo em uma postura característica, você pode, com uma dica
Feroz feiticeiro orc lançando uma bola de fogo dentro de uma masmorra sinistra e escura, foto vencedora do prêmio Hasselblad
Transforme-o na imagem de um orc lançador completamente brutal em um típico cenário de fantasia.

O pré-processador scribble_pidinet, o modelo control_v11p_sd15_scribble e a opção “ControlNet é mais importante” estão envolvidos aqui. A escolha do Scribble/Sketch neste caso se deve ao fato do modelo OpenPose, curiosamente, ter grande dificuldade em reproduzir os dedos na imagem resultante – embora o pré-processador os detecte de forma bastante adequada. Talvez o fato seja que o esquema de codificação de cores dos fragmentos do corpo do OpenPose seja imperfeito – em particular, não contém tons claramente distinguíveis para diferentes dedos.
⇡#Pose aberta
A principal vantagem do ControlNet para os entusiastas do desenho com IA, especialmente aqueles que não possuem um PC com uma placa gráfica moderna e poderosa, é a significativa economia de tempo. Teoricamente, se você descrever bem e claramente a cena/pose desejada em um prompt de texto, mais cedo ou mais tarde – com uma das sementes possíveis – ela será reproduzida na imagem final. Mas se uma maneira de definir explicitamente a composição (ou outras características importantes) de um quadro tiver sido proposta e já testada, é muito mais provável que o sistema extraia do espaço latente um resultado aceitável para o operador. E seria um pecado não tirar vantagem disso.
Um dos modos de controle ControlNet mais atraentes para muitos entusiastas ainda é o OpenPose, uma rede neural que reconhece a pose de uma figura humana em uma imagem e a codifica de uma forma especial adequada para processamento posterior. Apesar de todas as deficiências, este modo de controle de Difusão Estável abre um amplo espaço para a criatividade, já que a pose extraída da imagem original (de referência) é o mais lacônica possível. Trata-se simplesmente de uma estatueta de “arame” com segmentos multicoloridos que correspondem a fragmentos individuais do corpo, sobre um fundo preto sólido. Conseqüentemente, nenhum outro traço da estrutura do quadro original permanece após o uso do pré-processador (“extrator” de informações específicas para este modo; aquela rede neural muito adicional treinada para uma única tarefa) no modo OpenPose – enquanto Depth, Canny e Scribble transmitem ao sistema de processamento dos contornos não apenas de figuras humanas, mas também de outros objetos presentes na imagem original.
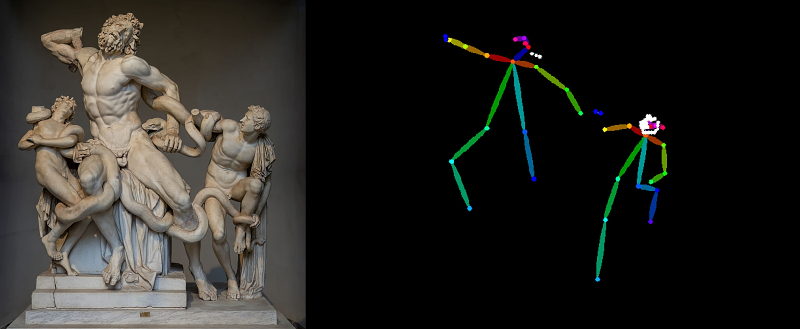
Infelizmente, o OpenPose nem sempre lida adequadamente com sua tarefa: no famoso grupo escultórico “Laocoonte e Seus Filhos”, o pré-processador openpose_full deste modo, por exemplo, se recusa categoricamente a reconhecer (com configurações padrão) a figura humana esquerda e desenhar “ fios” para ele (fonte: à esquerda – Wikimedia Commons, à direita – geração de IA baseada no modelo SD 1.5)
Notemos entre parênteses que existe até um pré-processador OpenPose especialmente treinado para reconhecer poses de animais. Mas, como exemplo, vamos pegar a imagem de um homem correndo do repositório de fotos distribuídas gratuitamente PX Here (domínio público CC0, gratuito para uso pessoal e comercial, sem necessidade de atribuição) e gerar uma imagem completamente diferente com base nela, mas com a mesma pose. Vamos definir uma dica positiva como
Mulher nigeriana correndo pelo deserto
Negativo –
Nsfw, nu, nu, BadDream, (UnrealisticDream:1.2)
Vamos selecionar um checkpoint que foi inicialmente treinado para criar as imagens mais realistas que se assemelham a fotografias: AbsoluteReality na versão 1.8.1. Seu autor recomenda utilizar os parâmetros “Escala CFG” na faixa de 4,5 a 10, “Passos” – de 25 a 30, amostrador – DPM++ SDE Karras. Por uma questão de certeza, vamos nos concentrar em CFG = 7, Steps = 28, e como amostra faremos uma amostra rápida e de altíssima qualidade, conforme observado na última edição do AI Drawing Workshop, DPM++ 3M SDE Karras. Na descrição do posto de controle no site Civitai, o autor enfatiza especialmente que não se deve complicar demais as dicas – nem negativas (aliás, as inversões de texto BadDream e UnrealisticDream também são sua recomendação direta) nem positivas. Descrições de texto pesado apenas confundem o decodificador CLIP, no qual o SD 1.5 depende para tokenizar a solicitação do operador – é melhor tentar encaixar uma dica positiva em 75 palavras e usar ativamente ferramentas adicionais, como LoRA ou ControlNet.
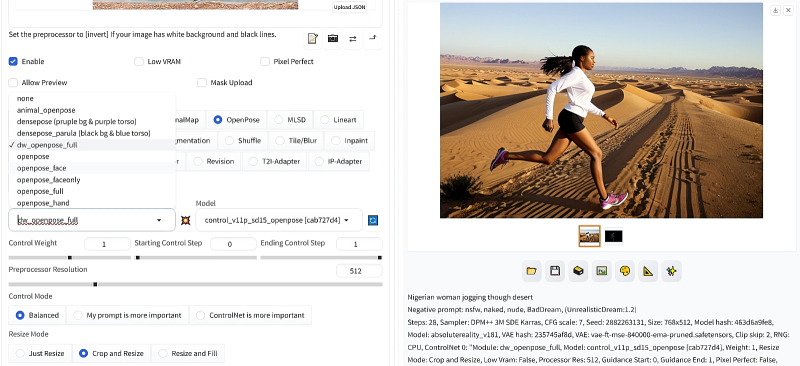
Vamos definir o modelo padrão vae-ft-mse-840000-ema-pruned.safetensors no menu suspenso VAE e definir o controle deslizante “Clip skip” para a posição “2”. Se o parâmetro “Multiplicador de ruído extra para img2img e contratação de correção” foi preservado na parte superior do painel de controle desde a última vez, faz sentido defini-lo para um valor médio razoável de 0,05 – isso será útil ao dimensionar a imagem para melhorar a qualidade.
Agora ativamos o modo de controle OpenPose no menu suspenso ControlNet usando o botão de opção correspondente. Por padrão, o pré-processador openpose_full e o modelo control_v11p_sd15_openpose serão carregados nos menus suspensos de segundo nível logo abaixo. Você pode substituir o pré-processador padrão por um mais relevante, dw_openpose_full, – para tal imagem (uma pose bem articulada com membros bem espaçados, quase fundindo os dedos e um rosto pouco detalhado) não haverá muita diferença entre eles. Você não precisa tocar em mais nada – clique no botão “Gerar” e é isso que obtemos com a semente 2882263131 (à esquerda está uma foto de referência, no centro está o resultado do pré-processador, à direita está a imagem final):
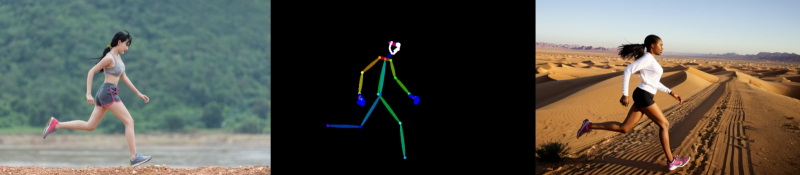
⇡#Meus olhos estão mais altos
Em vez de uma garota nigeriana, pode haver qualquer personagem antropomórfico – um elfo negro, um autômato vitoriano, um predador – a pose permanecerá a mesma. Entre os pré-processadores disponíveis hoje, faz sentido escolher dw_openpose_full como uma encarnação posterior deste modo de controle ControlNet. Anteriormente, para gerações baseadas em retratos, onde o rosto e as mãos são mostrados em detalhes, o pré-processador openpose_face era frequentemente usado – aqui, por exemplo, ele transforma esta fonte (também uma foto disponível publicamente) de acordo com a dica positiva Medieval bruxa olhando maravilhada e com a negativa anterior:
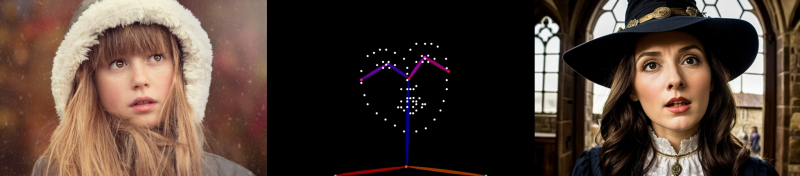
Uma versão um pouco mais especializada do pré-processador, openpose_faceonly, concentra-se especificamente no rosto:

E é assim que dw_openpose_full trata esta imagem:

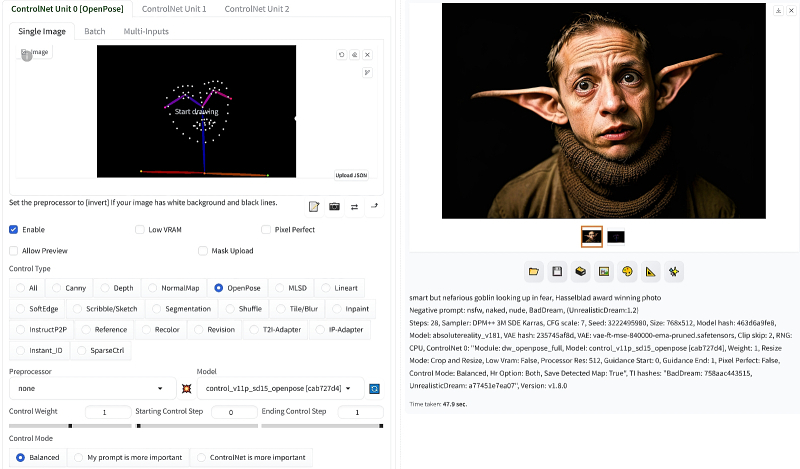
Como você pode ver, a última opção, que se baseia no trabalho de Estimativa Efetiva da Pose de Corpo Inteiro com Destilação em Dois Estágios, realmente mostra os resultados mais notáveis. E como o modo OpenPose depende apenas de pontos-chave do rosto e do corpo da imagem original, você pode fazer quase tudo usando o Stable Diffusion. Bem, digamos que esta dica positiva – um duende inteligente, mas nefasto, olhando para cima com medo – com todos os outros parâmetros em sua forma anterior dá o seguinte resultado:

Aqui você pode ver claramente a influência da amostra original: obviamente, havia uma boa quantidade de fotografias de bruxas convencionalmente bonitas (cosplay, fotos de filmes, etc.) no banco de dados no qual o posto de controle que opera neste caso foi treinado, enquanto os goblins acabaram sendo representados principalmente por desenhos – o que afetou os resultados do processamento de uma dica tão simples. Por isso, vale a pena ajustar a dica positiva acrescentando uma indicação explícita do tipo de imagem: uma foto, e de preferência não uma foto qualquer, mas coroada com os louros do vencedor de um famoso concurso de fotografia:
Duende inteligente, mas nefasto, olhando para cima com medo, foto vencedora do prêmio Hasselblad
E é isso que sai:

Prestemos atenção em como as limitações naturais dos modos de controle ControlNet se manifestam. Os pré-processadores OpenPose codificam a localização dos olhos, mas não indicam a direção do olhar e, portanto, não é tão fácil obter uma imagem com um personagem olhando diretamente para cima – principalmente as pupilas e as íris ficarão centralizadas. Para efeito de comparação, vamos processar a mesma imagem com parâmetros de geração absolutamente idênticos no modo de controle Canny:

E agora vamos avaliar claramente suas próprias limitações – afinal, não apenas o OpenPose as possui. A detecção dos contornos dos objetos na imagem original ajuda a reproduzir detalhadamente até mesmo detalhes tão pequenos como a direção de visão. Mas também limita severamente a liberdade do modelo, que é solicitado a retratar algo muito diferente da fonte. Aqui você pode ver como o sistema tentou adicionar características de goblin ao rosto da garota, até mesmo retratando algo como uma barba espessa de capitão com folhas secas presas nela, mas a sensação geral do resultado é, para dizer o mínimo, desconfortável. Mas os olhos realmente olham para cima – o pré-processador Canny capturou esse detalhe perfeitamente no close-up do rosto.
O que fazer se você realmente precisar olhar para cima? Editar a imagem no Gimp/Photoshop ou transferi-la para a aba “img2img” e iniciar o redesenho (inpaint) são opções completamente aceitáveis. Mas primeiro, faz sentido simplesmente classificar as sementes – iniciar o modo “Gerar para sempre” com um parâmetro “Semente” aleatório. Para agilizar o processo – já que já temos uma “figura do fio” da configuração necessária – vale colocar no campo da imagem de referência do ControlNet o resultado do trabalho do pré-processador, ou seja, aquele mesmo homenzinho feito de bastões multicoloridos em um fundo preto. Em seguida, deixe OpenPose como modo de controle, selecione a posição “none” no menu suspenso de pré-processadores e deixe o modelo igual – control_v11p_sd15_openpose. E espere até que um goblin apareça olhando para cima. Aliás, fortalecer a parte desejada da dica também vai ajudar:
Duende inteligente, mas nefasto (olhando para cima com medo: 1.3), foto vencedora do prêmio Hasselblad

Muito digno! Claro, a marca indelével dos rostos dos duendes (e especialmente das orelhas) do filme épico de Harry Potter é perceptível, mas para objetos com uma representação relativamente baixa no conjunto de treinamento original, tais distorções são inevitáveis. Se você escolher um posto de controle treinado em ilustrações de fantasia com anotações cuidadosas ou encontrar um LoRA que seja especificamente focado na imagem de goblins, você poderá obter um tipo mais exclusivo.
Os entusiastas da IA apreciaram essa flexibilidade do OpenPose – não é à toa que o já mencionado site Civitai tem muitas coleções de uma ampla variedade de poses. Aqui, por exemplo, está o Super Pose Book – uma coleção de três dúzias de arquivos PNG com “wire men” (além de exemplos de seu uso, que podem ser carregados na guia “PNG Info” da interface web do AUTOMATIC1111 para ver o texto dicas envolvidas em sua geração). E é isso que acontece, por exemplo, com a pose aberta (2), o alerta positivo e orgulhoso paladino de fantasia caminhando no caminho da montanha rochosa, o hipnotizante fundo do pôr do sol, a elaborada armadura brilhante, a foto premiada da Hasselblad e a semente 611118914:

⇡#Ao infinito e além
Observemos que, embora a imagem de referência com a pose seja vertical, ainda temos uma tela horizontal com dimensões de 768 × 512 pixels especificadas em AUTOMATIC1111 – e a imagem final fica exatamente assim. A opção “Redimensionar e preencher” na seção “Modo de redimensionamento” do extenso menu ControlNet permite evitar distorções: neste caso, a imagem que não corresponde ao formato da tela é colocada no centro, cabendo proporcionalmente no especificado tamanho vertical, e o espaço nas laterais é aproveitado pelo modelo para acabamento do desenho – seguindo o mesmo princípio do modo Outpaint, já familiar aos nossos leitores de longa data, disponível na aba “img2img” .
O modo de controle OpenPose é especialmente bom nesses casos, já que os pré-processadores Canny, Depth, etc. processarão cuidadosamente todos os objetos no quadro original – e deixarão espaços vazios nas laterais dele (após expandir a tela). Que o posto de controle atual preencherá de acordo com seu próprio “entendimento” (e dentro da estrutura indicada pelo prompt de texto, é claro) – mas o contraste entre o centro, rico em detalhes originais, e as áreas externas pobres, mas limpas, do a imagem final pode acabar sendo muito deliberada. No caso do OpenPose, todo o espaço ao redor da figura (ou várias figuras) transformado pelo pré-processador é preto e preto, então a composição geral fica muito mais natural.
Vamos fazer outra pose preparada, de outra coleção, 25 Pose Collection, – imagem o18 com dica
Senhora bárbara musculosa e tendinosa flexionando os músculos em um prado exuberante, pintura de guerra, armadura de couro de fantasia intrincada, rio sinuoso e vasto fundo do céu, foto vencedora do prêmio Hasselblad
(A dica negativa é exatamente a mesma de todos os casos anteriores):

Lembramos que não é surpreendente que com os parâmetros de geração que usamos em uma tela medindo 768 × 512 pixels, os rostos em planos médios e especialmente pequenos fiquem assustadores – discutimos isso anteriormente enquanto estudávamos as ferramentas ADetalier e Hires. consertar. Vamos aplicar ambos à imagem resultante – com parâmetros, aliás, recomendados pelo mesmo autor do checkpoint AbsoluteReality que usamos neste caso. Tomemos dois modelos para ADetailer – face_yolov8m.pt e hand_yolov8s.pt, e para Hires. corrigir o valor de “Força de eliminação de ruído” será definido como 0,4. Observemos especialmente que sempre faz sentido escolher um modelo específico de geração de imagens não apenas com base nas imagens de exemplo fornecidas, mas também com base na profundidade de elaboração do comentário do autor – em muitas situações, as informações daí acabam sendo verdadeiramente inestimável.
Resultado:

Porém, mesmo isso (as dimensões da imagem resultante são 1536 × 1024 pixels) pode não ser suficiente se você quiser fazer papel de parede para sua área de trabalho ou enviar a imagem para impressão em formato A3. O aumento consistente com o aumento da qualidade, como apontamos repetidamente em edições anteriores do AI Drawing Workshop, não é uma tarefa fácil: se você definir o valor de “Força de eliminação de ruído” muito baixo, quase nenhum detalhe será adicionado, o a imagem ficará desfocada; muito grande – há uma chance de estragar o que está lá devido ao aparecimento de artefatos de ampliação indesejados.
ControlNet tem surpresa, surpresa! — existe uma solução para este caso: modo de controle upscale do bloco ControlNet. Você precisa usá-lo na aba “img2img”: transfira a imagem resultante para lá clicando no botão correspondente na janela de geração na aba “txt2img”, defina os valores “Multiplicador de ruído extra para img2img e contrata correção” – 0,05, “Etapas de amostragem” – 30, “Força de eliminação de ruído” – 0,3. Deixaremos o “Método de amostragem” igual ao da geração inicial – DPM++ 3M SDE Karras.
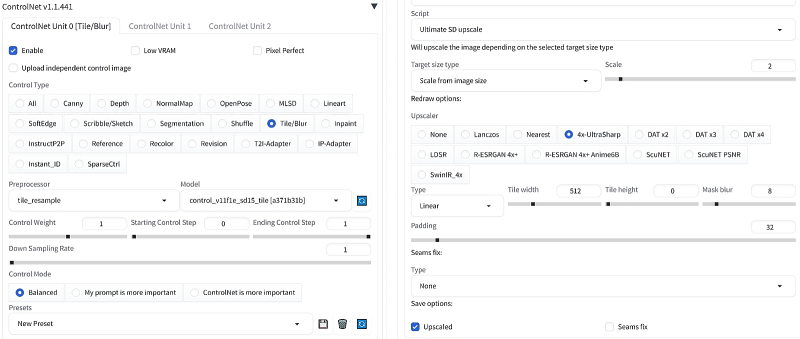
Ativamos “Tiled VAE” no menu suspenso com os mesmos parâmetros da aba “txt2img”. A seguir, no menu suspenso ControlNet, selecione o modo “Tile/Blur” com o pré-processador tile_resample e o modelo control_v11f1e_sd15_tile (felizmente, é o único lá). A própria imagem transferida para “img2img” será a referência, mas se você precisar de outra (por que exatamente isso pode ser necessário, explicaremos mais tarde), a opção “Carregar imagem de controle independente” será útil. Agora você precisa abrir o menu suspenso “Script” localizado ainda mais abaixo e selecionar “Ultimate SD upscale”, para o qual especifique “Target size type” – Escala do tamanho da imagem, x2, “Upscaler” – 4x-UltraSharp, e você não precisa tocar em mais nada.
Uma dica positiva para luxo seria:
Pele brilhante, skindentation, resolução ultra alta, mais alta qualidade, detalhes excepcionais
Não há nada negativo, e é isso que acontece:

Uma opção mais do que digna (o original com dimensões 3072 × 2048 é postado aqui por precaução: carregado no AUTOMATIC1111 via “PNG Info”, permitirá restaurar os parâmetros de escala da imagem) – e examinamos isso, embora com alguns detalhes , apenas um dos modos ControlNet de controles disponíveis! E existem, além dos bastante evidentes Canny e Depth, redes neurais interessantes como Reference ou adaptadores IP – mas elas merecem ser discutidas em detalhes um pouco mais tarde.