
«Se funcionar, não toque” é o conhecido primeiro mandamento de um programador, administrador de sistema e qualquer especialista em TI no sentido mais amplo da palavra. Para o operador de um modelo de IA que cria imagens com base em prompts de texto, isso geralmente também é verdade. Não estamos falando aqui da melhoria constante dessas dicas em si, é claro, mas de tentativas de melhorar o trabalho do ambiente de trabalho que as interpreta. Além disso, se o software utilizado não se adequar de alguma forma ao utilizador, para corrigir a situação – mesmo quando se trata de software de código aberto, como o que considerámos para três “Workshops” AUTOMATIC1111 (um, dois, três) – mais são necessárias qualificações significativas, na verdade específicas do usuário.

Fonte: geração de IA baseada no modelo SDXL 1.0
Mas aqui está o problema: alguns softwares – neste caso, um ambiente de trabalho para gerenciar um modelo generativo que transforma texto em imagens – podem não apenas não funcionar, mas limitar significativamente (devido às suas características inerentes) a funcionalidade deste mesmo modelo. Vejamos o mesmo ambiente AUTOMATIC1111: em menos de um ano de sua existência, ele se tornou quase uma ferramenta padrão para entusiastas de desenho de IA em todo o mundo para explorar pontos de verificação criados com base no modelo generativo básico Stable Diffusion 1.5 (treinando este último em matrizes adicionais de imagens anotadas). Porém, no final de julho de 2023, com o lançamento da versão mais recente do SD, não mais numerada (1.4, 1.5, 2.1, como antes), mas rotulada (com o sufixo XL), tornou-se bastante óbvio que
Mais precisamente, essa consciência apareceu entre os entusiastas do desenho de IA um pouco antes – mesmo na fase da versão beta do SDXL, com o índice condicional 0,9 se tornando disponível publicamente. Na verdade, por esta razão, muitos fãs das Belas Artes continuam a considerar o SD 1.5 a opção mais preferível hoje: ao longo de muitos meses de uso ativo deste modelo, foram desenvolvidas regras bastante eficazes para a formulação de dicas de texto e, o mais importante, , um extenso kit de ferramentas adicionais foi criado, incluindo upscalers (mini-redes neurais para dimensionar a imagem original com detalhes crescentes), inversões de texto, LoRA, vários modelos ControlNet e muitas outras coisas.

Fonte: geração de IA baseada no modelo SDXL 1.0
Porém, a equipe Stability.ai, desenvolvedora do modelo Stable Diffusion, está fazendo sua maior aposta no SDXL 1.0, afirmando diretamente que mesmo seu submodelo básico (explicaremos o significado deste termo a seguir) produz resultados significativamente mais atrativos. ao grupo de controle do que as versões anteriores. Nenhuma dessas declarações foi feita em relação ao “Dvoechka” (SD 2.0 e um pouco mais tarde 2.1), e por razões completamente objetivas. Rapidamente ficou claro que mudar o decodificador de texto (conversor de dicas de texto em tokens digitais, que são então usados para navegar no espaço latente) de CLIP para OpenCLIP foi uma piada cruel para a equipe Stability.ai: uso direto de dicas de “Lortor” para o novo modelo não produziu imagens de melhor qualidade porque seu texto foi decodificado de forma diferente,
Até agora, no portal Civitai, extremamente popular entre os entusiastas de modelos visuais generativos, o checkpoint mais popular para “Dois”, rMada Merge, tem apenas 8,7 mil downloads e 1,5 mil “curtidas”, enquanto o líder na classificação “Um e a half”, DreamShaper, conta com 488 mil downloads e 32 mil curtidas. Aqui você também precisa ter em mente que para baixar um checkpoint do Civitai, em geral, não há necessidade de cadastro, enquanto apenas usuários autorizados podem clicar nos corações ao lado do nome do modelo. Ao desenvolver SDXL, Stability.ai levou esse ponto em consideração – e como resultado, o decodificador de texto para Oversized é uma combinação de OpenCLIP e o modelo de linguagem CLIP original, desenvolvido e usado ativamente por outro pioneiro no campo de IA generativa – OpenAI (o mesmo que custa para ChatGPT). Formalmente, o código do programa CLIP também é aberto, mas o array de imagens no qual este decodificador foi treinado ainda permanece proprietário; o significado do OpenCLIP é que ele é, na verdade, o mesmo CLIP, mas treinado no banco de dados LAION de imagens anotadas disponível publicamente.

NÃO houve menção a Alice Vox na pista de texto desta imagem! (fonte: geração de IA baseada no modelo SDXL 1.0)
De uma forma ou de outra, existem significativamente mais diferenças entre o SDXL e as versões “numeradas” do SD do que entre as versões 1.5 e 2.1. Isso significa automaticamente que a seleção das palavras nas dicas terá que ser feita de forma diferente (embora a versão “Oversized” tenha voltado parcialmente a usar o CLIP, então nesse quesito tudo é um pouco mais simples), e todas as ferramentas, do LoRA ao ControlNet , precisará ser recriado com zero. No entanto, este trabalho já está em andamento: a julgar pela dinâmica de aparecimento de novos modelos no site Civitai, entre os primeiros usuários do SDXL havia tantos entusiastas fascinados pela amplitude de capacidades deste modelo que a divulgação completa de seu o potencial não está longe. E, como o quadro definido pelo AUTOMATIC1111 ainda é demasiado estreito para um conhecimento adequado de todas estas possibilidades,
⇡#Dois mundos, duas abordagens
Para começar, destacamos que além do ComfyUI, pelo menos dois ambientes de trabalho locais são usados ativamente na comunidade de artistas de IA, prontos para liberar amplamente o potencial do SDXL: Fooocus (a interface mais simplificada, instalação elementar, a capacidade de definir a saída de uma imagem no estilo de realismo fotográfico, desenho a tinta ou pixel art) e SD.Next (março de 2023, uma bifurcação do projeto AUTOMATIC1111 com muitas otimizações e suporte expandido para treinar entusiastas de seus próprios modelos). Existem outros, e muitos sites agora oferecem SDXL 1.0 como modelo padrão – mage.space e Clipdrop, por exemplo.
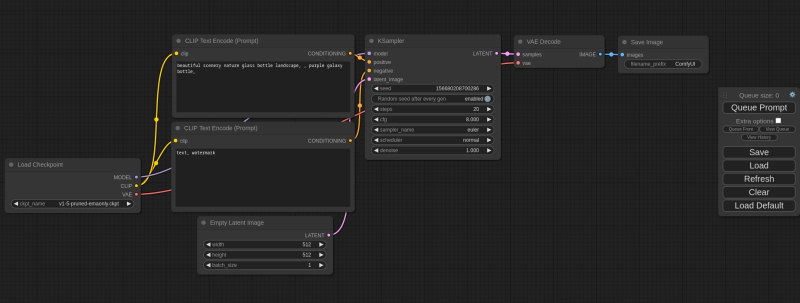
Um ciclograma básico incorporado em uma instalação “limpa” do ComfyUI: o retângulo isolado e desconectado à direita é, na verdade, quase toda a interface deste ambiente de trabalho (fonte: GitHub)
Mas o ComfyUI é muito diferente de todos os outros na forma como organiza o processo de geração de imagens a partir de texto. A questão é que neste ambiente de trabalho, o operador não apenas insere dados nos campos apropriados, marca caixas, pressiona botões e move controles deslizantes, mas constrói pessoalmente um procedimento sequencial de vários estágios (ciclograma) para converter texto em uma imagem por meio de imagens latentes. espaço, conectando os nós responsáveis pelas operações individuais (nós) são conexões lógicas através das quais determinados dados são transmitidos.
Na comunidade de entusiastas generativos das artes plásticas, quase imediatamente após o aparecimento do ComfyUI em março deste ano, nasceu uma piada sarcástica: “AUTOMATIC1111 não é tão automatizado e trabalhar com o ComfyUI não é muito confortável”. Para ser justo, notamos que o nome do ambiente de trabalho em questão não tem a intenção de enfatizar as vantagens ergonômicas de sua interface (que, para o olhar estupefato de um novato, essencialmente não existe): é apenas isso Comfy – mais precisamente, comfyanonymous – é o apelido de seu criador. Agora, a propósito, tendo se juntado à equipe de desenvolvimento do Stable Diffusion por convite urgente, o ComfyUI se tornou o ambiente de trabalho interno padrão no Stability.ai. Este facto por si só constituirá certamente para muitos um forte argumento a favor da mudança para este ambiente de trabalho, se não já hoje.
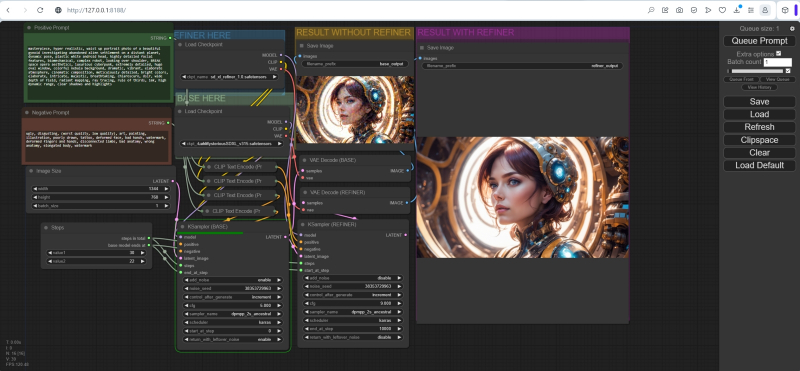
Para estar completamente imerso no mar de capacidades do SDXL, o ciclograma de geração de imagens para este modelo deve garantir a operação sequencial de dois pontos de verificação: a base e o refinador.
Sim, uma versão preliminar do AUTOMATIC1111 está sendo testada (que deve ser numerada 1.6.0 após o lançamento oficial; a versão estável atual no momento da redação deste artigo é 1.5.1), que, segundo rumores, cuidará do Variante XL deste popular jogo generativo, modelos muito melhores. Mas levando em consideração o suporte direto do Stability.ai, as perspectivas para o ComfyUI parecem melhores. Além disso, devido à arquitetura interna do AUTOMATIC1111, este ambiente pioneiro é muito mais complexo do que projetos posteriores, passível de modificação, desenvolvimento e simplesmente suporte. O mesmo comfyanonymous – felizmente o código do projeto é aberto, para que qualquer pessoa possa verificar suas palavras – fala do Avtomatika da seguinte forma: “Você pode quebrar uma perna no código A1111; ele é muito inflexível para lidar com todos os novos produtos,
Na verdade, o ComfyUI tem uma vantagem incondicional como flexibilidade incrível em comparação com o AUTOMATIC1111. Isto é conseguido precisamente devido ao fato de que, em vez de usar uma interface pronta com guias, menus suspensos e controles deslizantes, o operador (agora certamente não o usuário!) do ambiente de trabalho para desenho de IA é solicitado a elaborar de forma independente um ciclograma – um protocolo de execução sequencial (workflow) – de todo o trabalho que o sistema deve fazer. Que não seja escrevendo linhas de código, mas organizando os nós necessários no campo de interface e conectando-os com conexões apropriadas – mas por programação, imergindo assim muito mais profundamente no papel de co-criador de uma imagem digital do que durante a operação de um ambiente de trabalho mais conservador.

Fonte: geração de IA baseada no modelo SDXL 1.0
Felizmente, dominar a programação baseada em fluxo (FBP), que se baseia em uma representação gráfica de nós que executam várias ações e conectá-los a fluxos de dados, é muito mais fácil para um não especialista em TI do que lidar com a escrita canônica de código operador por operador. O conceito de FBP remonta ao final da década de 1960 e recentemente tornou-se especialmente popular como um princípio para organizar ambientes de programação LowCode/NoCode que não exigem (pelo menos em teoria) a participação de programadores altamente qualificados para criar produtos de software de aplicação que estão completamente prontos para uso.
Dentro da estrutura deste conceito, os nós atuam para os operadores como uma espécie de caixas pretas, cuja estrutura interna eles não se importam. Cada nó possui entradas e saídas que estão prontas para receber ou, consequentemente, enviar dados de determinados tipos e em formatos estritamente especificados. Redirecionando os fluxos de informações de um nó para outro, o operador constrói estruturas bastante complexas a partir de nós elementares – de acordo com o mesmo princípio das portas lógicas, somadores e outros componentes do processador.
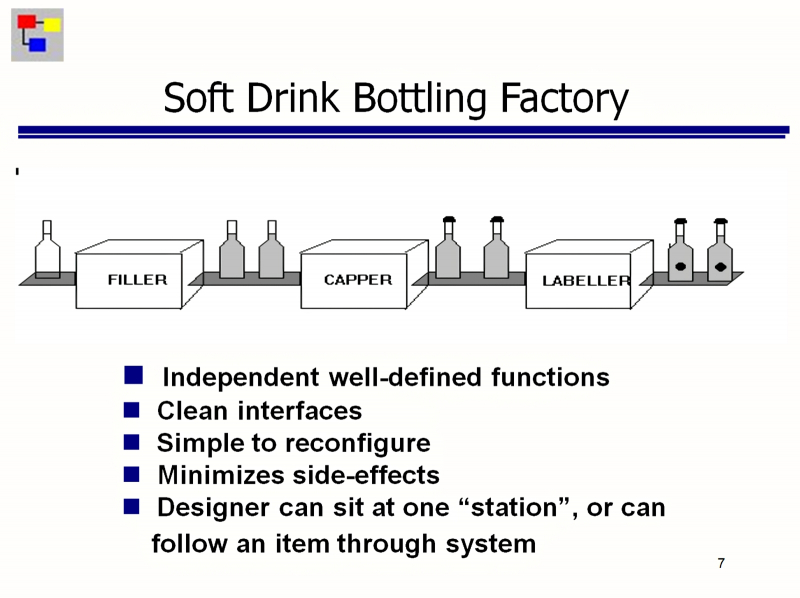
Uma explicação do princípio de funcionamento dos nós FBP como caixas pretas usando o exemplo de uma linha de embalagem em uma fábrica de refrigerantes: o gerente de processo não precisa saber exatamente como o enchimento, a tampa e a etiquetagem são implementados – ele só precisa conectar o necessário nós na ordem correta com uma esteira transportadora (fonte: GitHub)
E ainda assim, com todas as vantagens inegáveis do ambiente FBP, a primeira impressão de quem não está familiarizado com os fundamentos da programação NoCode ao olhar para sua interface é inequívoca: “monstro espaguete”. E até que os pontos de verificação da versão 0.9 do SDXL se tornassem disponíveis publicamente, a parcela de entusiastas do desenho de IA que escolheram deliberadamente o ComfyUI para seus exercícios era francamente pequena. Devemos, no entanto, prestar homenagem ao seu criador: na verdade, não há necessidade particular de que o operador comum deste ambiente entenda muito profundamente a assustadora “macarrão”. Cada arquivo PNG gerado na saída do ComfyUI contém nos campos de texto de seu cabeçalho uma descrição muito detalhada (na conhecida notação de objeto JSON – JavaScript) não apenas de todo o ciclograma a partir do qual foi gerado, mas também da posição relativa desses nós no campo de interface ComfyUI.
Em outras palavras, se um entusiasta que foge do “monstro do macarrão” gostou de algum tipo de desenho de IA gerado neste ambiente de trabalho, ele só precisa implantar o ComfyUI em seu PC (seja no Google Colab, ou usar recursos online que fornecem tal uma oportunidade), então arraste a imagem selecionada do Explorer diretamente para o campo da interface com o mouse. Como resultado, o próprio sistema extrairá todos os dados JSON do cabeçalho – e reproduzirá o ciclograma gerador desta imagem um a um. Incluindo todas as dicas de texto, valores iniciais e CFG, chamadas para o LoRA e upscalers necessários, se eles estiverem envolvidos, etc.
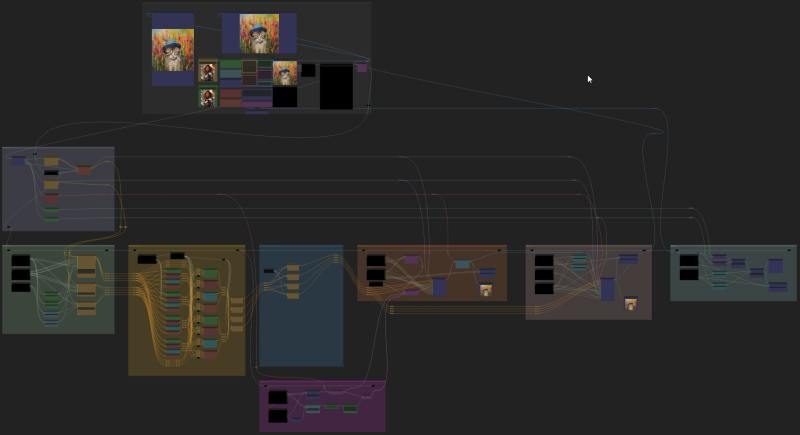
Ciclogramas avançados, como os oferecidos pelo projeto Searge-SDXL, contêm muitos nós auto-escritos (personalizados) e muitos threads de execução disponíveis, entre os quais o operador é livre para alternar dependendo do que ele precisa atualmente (fonte: GitHub)
E agora é muito mais fácil lidar com esse “monstro de macarrão” praticamente domesticado – começando, por exemplo, a variar o conteúdo dos campos de dicas de ferramentas. Sim, há uma série de restrições: por exemplo, nem todos os recursos da web salvam campos de texto de cabeçalho ao publicar arquivos PNG carregados neles. Freqüentemente, todas as informações que acompanham (EXIF e outros metadados) nas fotos são apagadas automaticamente, pois podem conter dados confidenciais – principalmente as coordenadas GPS do ponto de disparo, se estivermos falando de uma foto. Outro ponto importante: algumas das ferramentas utilizadas para criar a imagem podem simplesmente não estar disponíveis para o operador que a baixou: por exemplo, os mesmos LoRA ou upscalers, se foram utilizados pelo autor da imagem original, mas não estão instalados neste PC, terá que ser baixado e implantado manualmente. Se nós personalizados foram usados ao gerar o ciclograma, você também precisará instalá-los. Mas de uma forma ou de outra, um dia um ciclograma bem-sucedido criado por alguém irá para as pessoas – e depois disso será amplamente utilizado por aqueles para quem o FBP foi e continua sendo uma floresta escura. Já existem muitos desses fluxos de trabalho no site Civitai, conhecidos por qualquer entusiasta de desenho de IA.
E ainda assim, para a maioria dos entusiastas, que só precisam de um modelo generativo de IA para representar um dragão (ou não um dragão) de acordo com um simples prompt, a pseudo-interface “espaguete” – o ciclograma – é um pouco complicada, até se você não construir sozinho, mas usar o pré-criado de outra pessoa. Os menus suspensos e seletores do AUTOMATIC1111, embora espalhados por várias dezenas de guias (se você contar as subguias), parecem mais familiares. Então, provavelmente, o ComfyUI estaria destinado a permanecer um ambiente de trabalho não para todos – se não fosse pela ducha fria que caiu sobre os fiéis fãs do AUTOMATIC1111 na época do lançamento da versão XL do Stable Diffusion. Descobriu-se que o ambiente “não totalmente automático”, na melhor das hipóteses, fica abertamente mais lento ao trabalhar com SDXL 0.9 e depois 1.0 e, na pior das hipóteses, se recusa a funcionar,

Fonte: geração de IA baseada no modelo SDXL 1.0
Já nos primeiros dias de uso ativo dos mais novos checkpoints no AUTOMATIC1111, até mesmo proprietários de placas de vídeo com 16 GB de memória relataram dificuldades com a execução do submodelo SDXL 1.0 básico – sem falar em proprietários de hardware mais modesto. No início, muitas pessoas reclamaram que este modelo era apresentado na forma de um arquivo .safetensors medindo 6,6 GB, enquanto um ponto de verificação SD 1.5 típico hoje não ocupa mais do que 2,3 GB. Mesmo assim, mesmo 8 GB de RAM de vídeo deveriam, teoricamente, ser suficientes para carregar totalmente o novo modelo na memória de vídeo! E, no entanto, AUTOMATIC1111, naquela época (apenas um mês atrás desde a redação deste artigo), sem dúvida o ambiente de trabalho mais popular para desenho de IA, não conseguia lidar com a execução do SDXL. Mas além do submodelo principal (base, “base”), como indicaremos a seguir, Este modelo generativo inclui outro, de acabamento (refinador, “mais próximo”), cujo arquivo .safetensors ocupa 5,8 GB adicionais. No AUTOMATIC1111 versão 1.5.1, simplesmente não há mecanismo para execução conjugada (e não apenas sequencial, quando o segundo ponto de verificação recebe o resultado totalmente concluído do primeiro – isso é importante!) desses dois submodelos.
Longo ou curto, descobriu-se que o ComfyUI não tem esse tipo de problema: ele carrega os pontos de verificação SDXL corretamente, mesmo em hardware com 4 GB de RAM de vídeo, e funciona com eles sem travar devido a erros incompreensíveis e a velocidade de processando um e do mesmo prompt com outros parâmetros completamente idênticos, seu desempenho é significativamente superior ao do AUTOMATIC1111, quando ainda consegue forçá-lo a interagir adequadamente com o SDXL.
Felizes proprietários de uma GeForce RTX 3060 com 12 GB de RAM de vídeo relatam que a geração de uma imagem com resolução de 1024 × 1024 (padrão para o modelo XL – em oposição ao tamanho de 512 × 512 característico do SD 1.5) no AUTOMATIC1111 não apenas ocupa toda a memória de vídeo disponível, mas também e finalmente começa a trocar dados ativamente entre VRAM e RAM, retardando significativamente o processo. Ao mesmo tempo, o ComfyUI, para esgotar (mesmo que não completamente) os 12 GB de memória de vídeo disponíveis, precisa gerar simultaneamente, em lote, quatro imagens SDXL 1024 × 1024 – com os mesmos parâmetros de entrada, mas sementes diferentes .

Uma explicação visual da importância do fechamento no SDXL: à esquerda está uma imagem produzida inteiramente pelo submodelo principal; à direita – geração com os mesmos parâmetros, sendo 20% das etapas finais realizadas pelo refinador e apenas os primeiros 80% – pelo modelo base
Então, pelo menos por enquanto – até o lançamento da versão 1.6.0 do ambiente de trabalho AUTOMATIC1111 – o veredicto é quase claro: para experimentar plenamente os benefícios do mais recente modelo generativo de Difusão Estável, é lógico apostar no ComfyUI. Um bom bônus para esta escolha será uma compreensão mais completa e aprofundada do pano de fundo do trabalho da inteligência artificial na extração de imagens do espaço latente – o que, por sua vez, permitirá que entusiastas experientes melhorem suas habilidades na otimização da composição de dicas de texto e seleção de outros parâmetros de geração.
⇡#Cocriação versus herança
Existem diferenças fundamentais entre o SDXL e as versões anteriores do Stable Diffusion. Além disso, tanto quantitativo quanto qualitativo: se o ponto de verificação oficial do SD 1.5 inclui 0,98 bilhão de parâmetros (grosso modo, cada parâmetro é uma fração decimal; o peso em uma das entradas de um dos perceptrons em uma das camadas que formam esta rede neural) , então SDXL 1,0 – já 3,5 bilhões apenas para o submodelo base, enquanto o número de parâmetros para o submodelo refinador chega a 6,6 bilhões.A divisão de um único modelo em dois pontos de verificação operando em conjunto é uma característica essencial do SDXL, não leve em consideração conta que, ao trabalhar com esta versão de IA generativa, significa condenar-se deliberadamente a obter a priori resultados de qualidade inferior aos que tal sistema é, em princípio, capaz de oferecer.
No AUTOMATIC1111 até a versão 1.5.1, a última estável no momento da redação deste artigo, a possibilidade de cocriação de dois pontos de verificação não está implementada. A herança é outra: quando uma imagem é enviada da aba “txt2img” para “img2img” para upscaling, por exemplo, trata-se justamente da aplicação do segundo checkpoint ao resultado do primeiro.
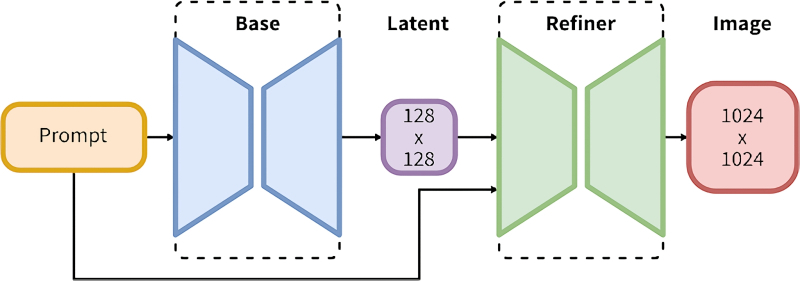
Explicação esquemática do princípio de funcionamento do modelo principal e mais próximo no modo de cocriação (fonte: Stability.ai)
Os modelos SDXL principal e final – se o operador quiser utilizá-los – no AUTOMATIC1111 é exatamente assim que devem ser lançados por enquanto: primeiro, o principal converte os prompts de texto em uma imagem, depois essa imagem é encaminhada manualmente para o img2img aba (sim, apenas um clique no botão correspondente – mas não automaticamente), e já aí, se estiver com vontade, você pode aplicar um mais próximo a ela. O resultado geralmente sai muito melhor – mesmo sem dimensionar para aumentar os detalhes, simplesmente preservando os parâmetros originais da imagem (1024 × 1024 pixels, por exemplo) – mas ainda na maioria das vezes não tão melhor a ponto de se preocupar com o lançamento manual adicional do segundo submodelo . Não é por acaso que os autores de postos de controle SDXL pré-treinados começaram a aparecer em grande número no Civitai, Muitas vezes indicam diretamente nas descrições de seus modelos: “NO REFINER NEEDED”. Eles entendem que a grande maioria dos usuários de seus pontos de verificação fará o download deles, como as versões para “Caminhão”, no AUTOMATIC1111 – e não quer complicar a vida de seu público potencial.
Vamos tentar explicar do que exatamente aqueles que não usam os dois submodelos do SDXL 1.0 para converter texto em imagens estão se privando – e essa consciência, quero acreditar, ajudará muitos a superar a incerteza e o medo em relação ao ComfyUI, no qual, de fato , a implementação de ambos os submodelos na cocriação é realizada com a mesma facilidade e simplicidade que na herança. A documentação oficial do Stable Diffusion XL explica que enquanto o submodelo base foi inicialmente treinado para extrair imagens baseadas em pistas de texto do espaço latente, o refinador é especializado em remover ruído fraco de imagens quase acabadas para que o resultado sejam imagens com maior qualidade em alta qualidade. frequências (para gerar imagens de melhor qualidade de alta frequência).

À esquerda está uma imagem completamente acabada (sem ruído residual) produzida pelo submodelo SDXL 1.0 básico em 20 etapas de geração; no centro – é o mesmo, mas com ruído latente residual antes de ser alimentado na entrada do mais próximo; à direita está o resultado final após 5 etapas de geração no modelo refinador (fonte: geração de IA baseada no modelo SDXL 1.0)
«Frequência” é usada aqui no sentido de “tamanho inverso”: grandes elementos de imagem – como ondas grandes – têm uma baixa frequência de ocorrência/repetição no campo de trabalho de geração (digamos, 1024 × 1024 pixels); pequeno – alto. O verdadeiro flagelo dos modelos generativos são precisamente os elementos de alta frequência: como a imagem primária completamente ruidosa extraída do espaço latente é extremamente pequena (128 × 128 pontos no exemplo do diagrama acima), pequenos detalhes nela acabam sendo extremamente difícil de identificar no processo de conversão de texto em imagem. É por esta razão que o refinador, especialmente treinado para gerar detalhes de alta frequência plausíveis e apropriados para uma determinada imagem, é tão valioso para um modelo que foi inicialmente focado na geração de imagens de grande formato – 1024 × 1024 -.
A documentação oficial mencionada indica duas formas possíveis de utilização dos submodelos base e acabamento: cocriação (romanticamente chamada de Ensemble of Expert Denoisers no texto) e herança simples. O primeiro método (proposto, aliás, sob o nome de eDiff-I pelos pesquisadores da NVIDIA) envolve trazer a imagem latente para o estado “quase pronto” – ou seja, o ruído da imagem não foi completamente removido, 80 passos foram concluídas do número de etapas atribuídas para execução, 85% – e transferindo exatamente essa imagem “não cozida” para o submodelo de acabamento (refinador). E agora, com o melhor de suas amplas capacidades, ele visualiza com a mais alta qualidade possível todos os elementos de alta frequência que estavam ocultos sob pontos turvos relativamente pequenos na imagem intermediária (desfocada).
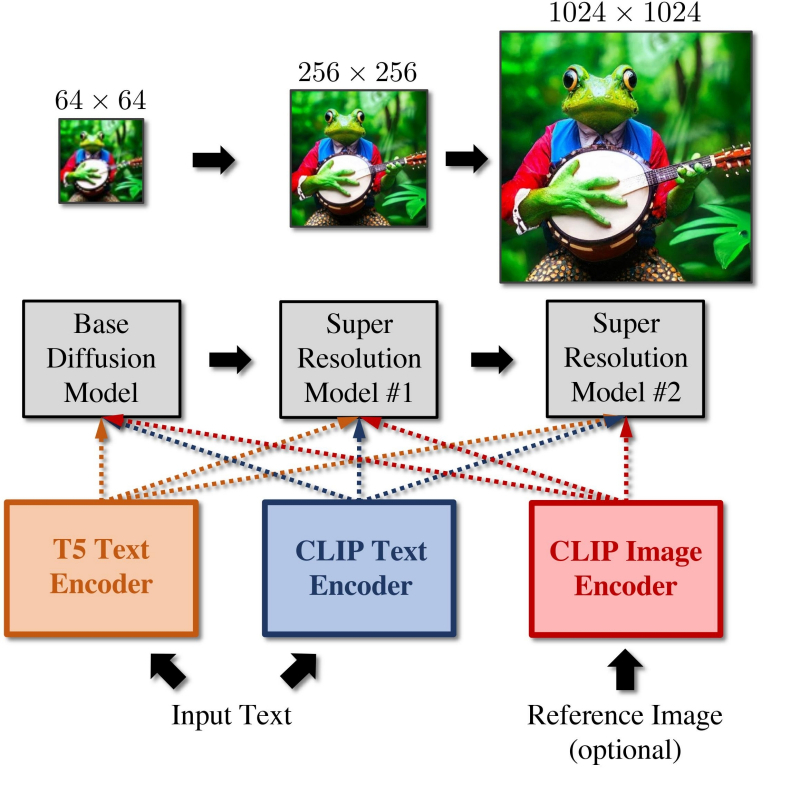
A implementação da cocriação de modelos generativos na abordagem eDiff-I é um pouco diferente daquela incorporada no SDXL, mas o princípio geral é o mesmo (fonte: NVIDIA)
O segundo método é o clássico SDEdit (Stochastic Differential Editing), cuja essência é que a entrada do segundo submodelo no link é fornecida com uma imagem 100% livre de ruído do primeiro submodelo – o resultado da geração normal com qualquer ponto de verificação adequado. Tendo recebido esta imagem, quanto mais próximo a torna um pouco barulhenta (já que o próprio ruído estocástico é uma janela para o espaço latente através da qual os detalhes ausentes de alta frequência podem ser extraídos), e então ocorre a operação normal do modelo generativo – removendo o excesso ruído da imagem resultante resolvendo iterativamente equações diferenciais estocásticas.
Toda a diferença entre a cocriação de dois submodelos e o processamento sequencial de imagens é que no primeiro caso, o refinador lida com o restante do ruído inerente à imagem que está sendo processada; exatamente aquilo que permanece nele a partir do momento em que essa área específica é removida – o espaço em branco para a imagem futura – do espaço latente. No segundo caso, o ruído necessário ao funcionamento do segundo submodelo é adicionado, por assim dizer, artificialmente: mesmo que formalmente a semente seja a mesma, os demais insumos para geração são quase certamente diferentes (sem falar no sistema de produção interna). parâmetros do próprio segundo modelo), portanto o resultado será sem dúvida diferente do primeiro caso. Não é verdade, aliás, que seja necessariamente menos satisfatório para o operador, mas diferente.

Fonte: geração de IA baseada no modelo SDXL 1.0
Assim, o próprio princípio de organização do ambiente de trabalho AUTOMATIC1111 é perfeitamente adequado para implementar uma ligação sequencial de dois submodelos com a transferência entre eles de uma imagem completamente isenta de ruído latente. O código deste ambiente (mais uma vez, façamos uma reserva, até a versão estável 1.5.1 atualmente em vigor) em princípio não implica a capacidade de produzir, mesmo como resultado intermediário, uma imagem com ruído latente residual. Mas no ComfyUI – que, de fato, pela ausência de interface, obriga o operador a construir pessoalmente ciclogramas para geração de imagens – para isso bastava escrever o nó apropriado. Ou seja, uma caixa preta (do ponto de vista do operador, claro, e não do programador que a criou), capaz de receber prompts de texto e outros parâmetros de geração como entrada, e produzir uma imagem como saída,
⇡#Ligue o motor
Assim como o AUTOMATIC1111, o ComfyUI é simplesmente um espaço de trabalho; Não contém modelos reais (pontos de verificação). Você precisará baixá-los (lembre-se, duas peças – uma base e uma mais próxima) na forma de arquivos .safetensors do repositório do desenvolvedor, Stability.ai, no site Hugging Face, usando os links apropriados: https://huggingface .co/stabilityai/stable-diffusion-xl -base-1.0 e https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0. No total, os arquivos ocupam cerca de 13 GB, então seja paciente.
Porém, e aqueles que já usam AUTOMATIC1111 – e, digamos, querem ter certeza, por experiência própria, de que até a versão 1.5.1 esse ambiente é menos adequado para trabalhar com SDXL do que ComfyUI? Copiar os mesmos 13 GB para a pasta apropriada dentro do diretório “Automação”? Isso não é econômico – e não há necessidade, pois o ComfyUI pode usar pontos de verificação fora de seu diretório padrão.
Você pode fazer o mesmo com VAE (autoencoder variável, eutoencoder variacional) – uma mini-rede neural adicional especialmente treinada para melhorar a qualidade da imagem final. O arquivo deste modelo, sdxl_vae.safetensors, deve ser baixado da página https://huggingface.co/stabilityai/sdxl-vae/ e então colocado na pasta models/vae dentro do diretório de instalação do ComfyUI, ou em um similar pasta na instalação AUTOMATIC1111 – com o registro do caminho desejado no arquivo extra_model_paths.yaml.
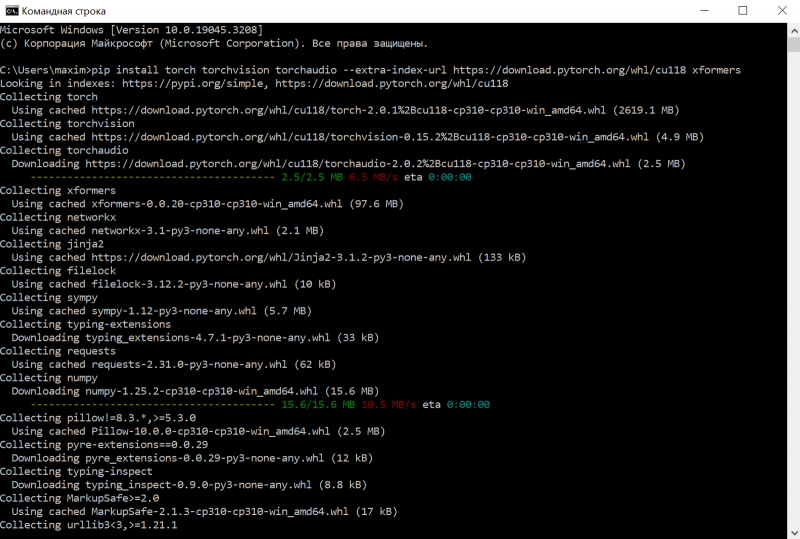
Agora, os sortudos proprietários de placas de vídeo NVIDIA para Windows precisam instalar manualmente vários pacotes adicionais a partir da linha de comando. Assim como na instalação do AUTOMATIC1111, isso é fácil de fazer executando o comando cmd no menu “Pesquisar” do painel do sistema e na janela preta que se abre, executando o seguinte script:
Pip instalar tocha torchvision torchaudio –extra-index-url https://download.pytorch.org/whl/cu118 xformers
Se de repente o pacote torch não estiver configurado corretamente no sistema (e para quem já utilizou o AUTOMATIC1111, tudo deve ficar bem), aparecerá a mensagem “Torch não compilado com CUDA habilitado”. Neste caso, você precisa emitir o comando
Tocha de desinstalação pip
Em seguida, repita o anterior.
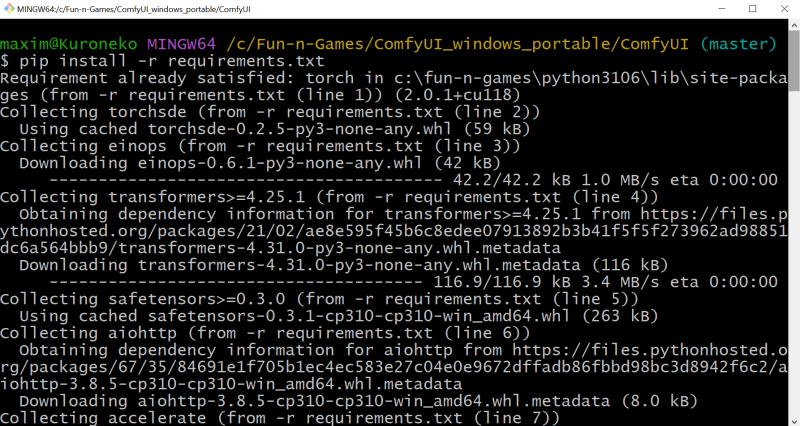
Pip instalar -r requisitos.txt
Se o seu PC tiver uma GPU NVIDIA instalada, você precisará executar o arquivo run_nvidia_gpu.bat; caso contrário, execute_cpu.bat. Neste último caso, o modelo generativo será implantado em RAM e utilizará núcleos de CPU, o que permitirá a obtenção de imagens bastante adequadas – embora em um tempo muito maior. As opções são possíveis para sistemas com gráficos AMD discretos, com placas de vídeo Intel Arc e para computadores baseados em chips Apple Mac Silicon – elas são brevemente revisadas na página oficial do projeto.

Quando você inicia o ComfyUI pela primeira vez, ele informa que encontrou todas as pastas com modelos que baixamos anteriormente para AUTOMATIC1111. A interface web neste caso está disponível em http://127.0.0.1:8188/.
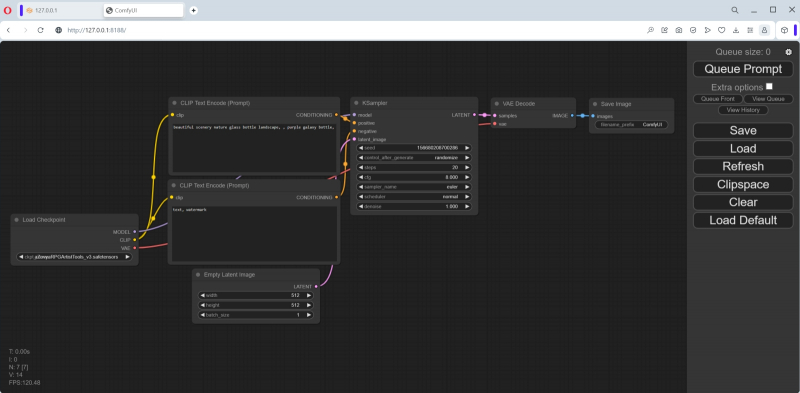
O ciclograma carregado por padrão é chamado de fluxo padrão e é a opção mais simples para organizar o trabalho com nós. Um campo com objetos e conexões espalhadas por ele pode ser ampliado/diminuído rolando, e também movido com o mouse: segurando o botão esquerdo em algum lugar em um espaço vazio e movendo o manipulador, ou pressionando “Espaço” e movendo o rato. No lado direito da tela existe uma coluna com botões, entre os quais a primeira coisa que você deve prestar atenção é o último, “Carregar Padrão”. Se, por hábito ou descuido, algo ficar completamente distorcido, é ela quem permitirá restaurar tudo à sua forma original. E assim que gerarmos a primeira imagem usando o ComfyUI, tudo será mais simples: para reproduzir um a um os nós e conexões envolvidos na sua obtenção,
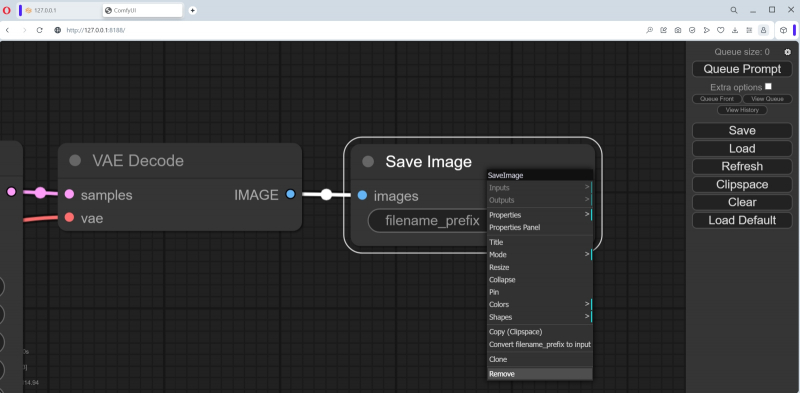
A propósito, o nó mais à direita do ciclograma padrão, “Salvar imagem”, implica o salvamento automático das imagens que ali aparecem. Inicialmente não há janela de saída – ela aparecerá após a geração da primeira imagem. Você pode arrastar o canto inferior direito deste nó com o mouse para obter o tamanho e a forma desejados. Existe outro tipo de nó de saída que simplesmente exibe uma imagem (e para salvá-la, se desejar, o operador terá que clicar com o botão direito e selecionar a opção apropriada). Vamos tentar adicioná-lo.
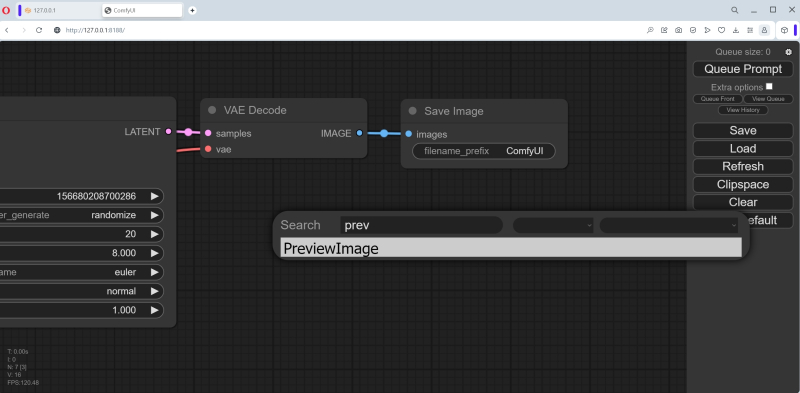
Para fazer isso, você precisa clicar duas vezes com o botão esquerdo do mouse em qualquer parte livre do campo de trabalho e, em seguida, selecionar a opção “PreviewImage” no menu que aparece (aqui está, a interface ComfyUI discreta – ainda está lá , embora de forma latente!).
Não é fácil fazer isso por hábito, pois a lista de nós disponíveis é muito grande. Mas há uma janela para inserir texto – e à medida que você digita as letras p, r, e nela, o número de opções vai diminuindo gradativamente até que reste apenas “PreviewImage”. Clique com o mouse e um novo nó chamado “Imagem de visualização” é criado no campo.
Neste caso, deixaremos os nós “Salvar imagem” e “Visualizar imagem” para mostrar que o ComfyUI pode operar com várias janelas de saída ao mesmo tempo. Mas se não for necessário “Salvar imagem”, não será difícil removê-la clicando com o botão direito sobre ela e selecionando a opção mais baixa do menu que se abre, “Remover”.
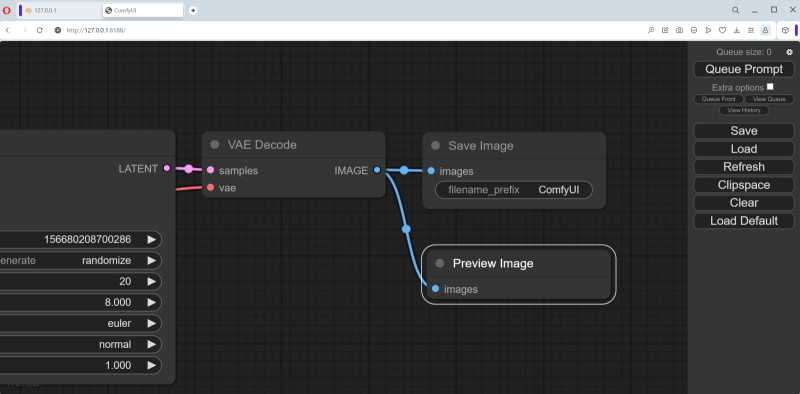
Então, temos um novo nó, “Preview Image”, mas ele não está funcionando – porque não está conectado a nada. Mova o cursor para o nó “VAE Decode” (imediatamente antes de “Save Image”, se este não for excluído) e clique com o botão esquerdo no ponto brilhante próximo ao parâmetro de saída “IMAGE”. Vamos puxar sem soltar e trazer a linha colorida de alongamento para o parâmetro de entrada “images” no nó “Preview Image” recém-criado. Na verdade, é assim que funciona a criação de ciclogramas: os nós são conectados por linhas, e se neste caso particular a conexão for impossível em princípio (digamos, o texto da dica não pode ser submetido a uma entrada que espera um valor numérico), a linha não se juntará ao ponto final. Os erros são praticamente excluídos: ou o ciclograma compilado funcionará e produzirá pelo menos algum resultado, ou não funcionará de todo.
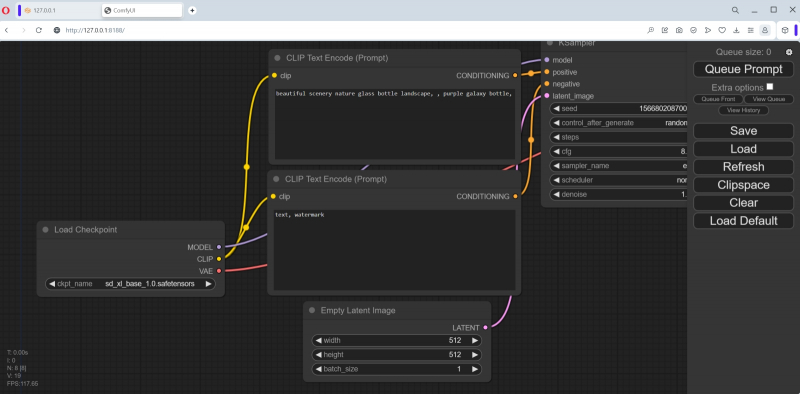
Vamos voltar ao primeiro nó, “Load Checkpoint”, e ver o que está selecionado lá. Como o AUTOMATIC1111 já está implantado neste computador e o ComfyUI descobriu seus repositórios no processo de configuração de dependências, por padrão, o primeiro ponto de verificação disponível em ordem alfabética foi carregado neste nó – aZovyaRPGArtistTools_v3.safetensors desta página no Civitai. Este é um dos modelos populares para criar desenhos em estilo pseudo-realista – como aqueles usados para ilustrar romances de fantasia, cartas para jogos de tabuleiro como MTG, etc. Este é um ponto de verificação baseado em SD 1.5 – mas será ainda mais interessante comparar ambos com ComfyUI e AUTOMATIC1111 funcionarão com os mesmos parâmetros de entrada.
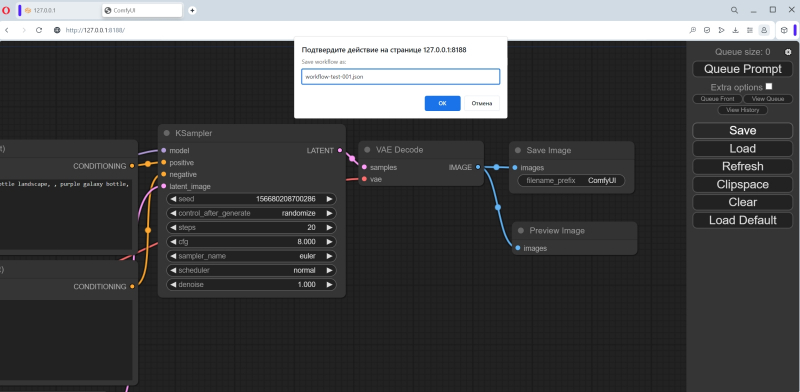
E por falar nisso, vamos aproveitar imediatamente o recurso mais conveniente do ComfyUI – salvar todo o fluxo de trabalho. Ao contrário do AUTOMATIC1111, aqui você não precisa verificar freneticamente todas as vezes, tentando reproduzir o resultado uma vez obtido, se CFG, Clip skip, o número de etapas de geração e outros valores estão indicados corretamente: aqui tudo pode ser salvo em um Arquivo JSON – antes mesmo da geração da primeira imagem no ciclograma construído. Ao clicar no botão Salvar no painel direito, o navegador informará que esta página está solicitando que você salve um arquivo, e nesta janela você poderá definir um nome para ele.
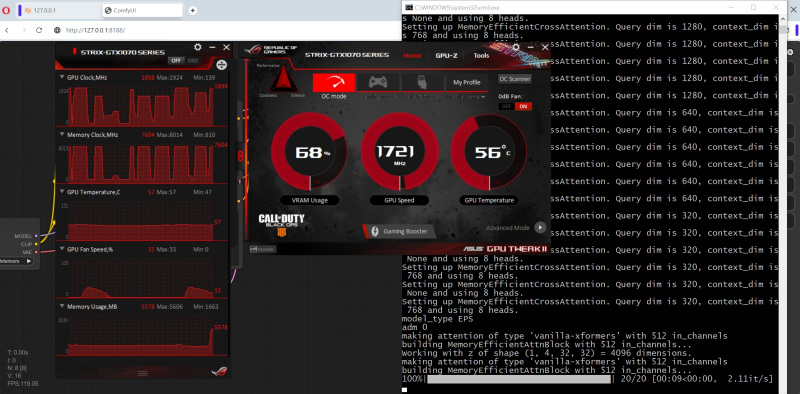
Bem, agora clique no botão “Prompt de fila” no topo do painel direito ou simplesmente “Ctrl” + “Enter” no teclado – e o ciclograma será executado. Como você pode ver, o carregamento da memória de vídeo é bastante suave.
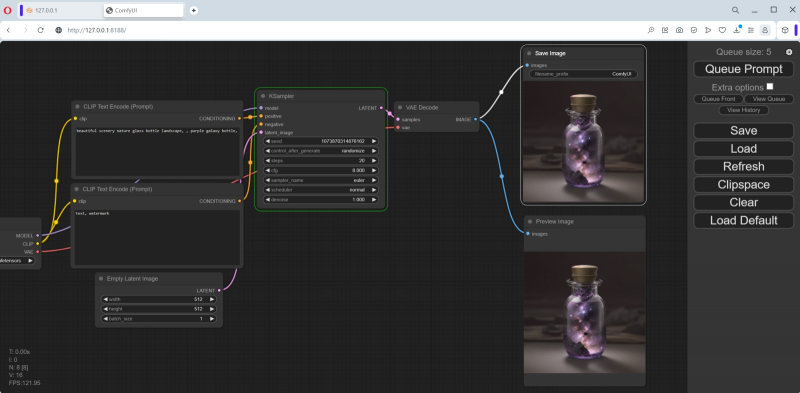
A dica de texto padrão descreve uma galáxia em uma garrafa – e, como podemos ver, a geração correspondente começou. Na interface web você pode acompanhar seu andamento: no canto superior direito, no topo do painel de controle, as gerações na fila estão em contagem regressiva; no topo do nó KSampler (denotando a mesma caixa preta com espaço latente dentro, cujas entradas são fornecidas com parâmetros especificados pelo usuário e a saída é uma imagem) uma faixa verde se move da esquerda para a direita.
Agora vamos ver como o AUTOMATIC1111 lida com a mesma tarefa. Saímos da janela de linha de comando em que o ComfyUI está sendo executado, pressionando “Ctrl” + “C” para confirmar nossa escolha, e agora iniciamos o AUTOMATIC1111.
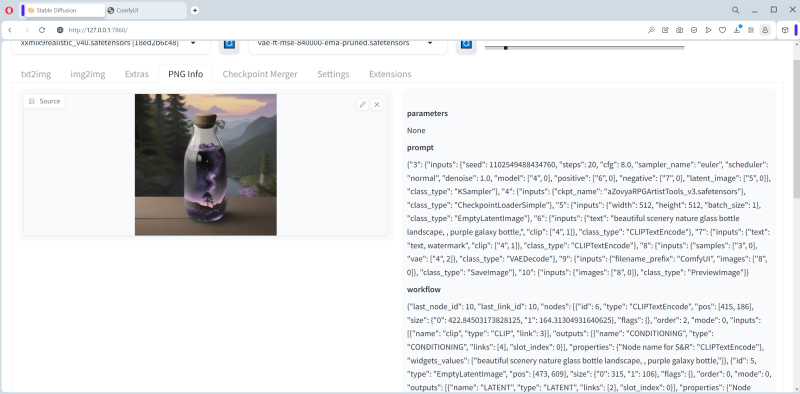
Vamos tentar carregar informações sobre a imagem gerada no ComfyUI através da aba “PNG Info”. Acontece interessante: há dados no arquivo, incluindo um thread de trabalho para reproduzi-lo, mas o formato é claramente diferente, não suportado pelo AUTOMATIC1111. Talvez na próxima versão 1.6.0 seja possível transferir automaticamente informações sobre os parâmetros de geração feitos no ComfyUI para a aba “txt2img” – mas por enquanto você terá que fazer isso manualmente.
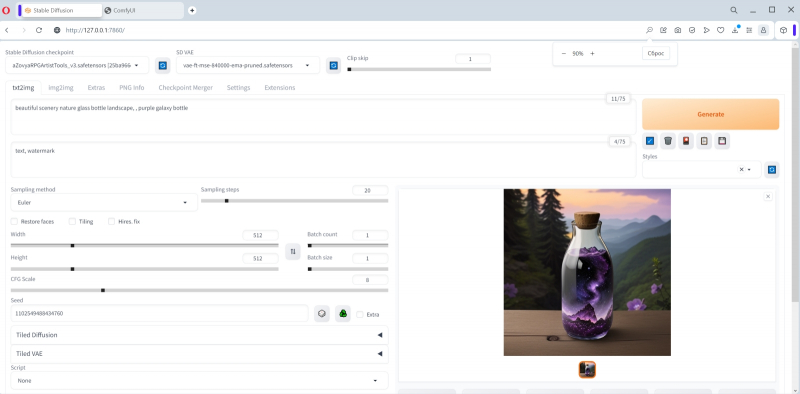
Felizmente, todas as informações extraídas por “PNG Info” do registro JSON no arquivo de imagem são bastante legíveis pelo operador, portanto, inserir os dados necessários nos campos da aba “txt2img” não será difícil. Então, os parâmetros:
Dica positiva – bela paisagem natureza garrafa de vidro paisagem, garrafa galáxia roxa (o espaço delimitado por vírgula é parte integrante dela; vamos deixar no lugar),
Negativo – texto, marca d’água,
Etapas – 20,
Amostrador – Euler
Escala CFG – 8
Semente — 1102549488434760
Tamanho — 512×512.
Vamos indicar aqui o VAE padrão para SD 1.5 e definir “Clip skip” como 1, após o qual lançaremos o AUTOMATIC1111 para execução. Resultados: tempo de geração – 15,5 s; A carga da GPU está em 53%.

À esquerda está o resultado do checkpoint SD 1.5 no ComfyUI com um ciclograma básico; no centro – imagem gerada com os mesmos parâmetros (+VAE vae-ft-mse-840000-ema-pruned) em AUTOMATIC1111, à direita – também em AUTOMATIC1111, mas sem indicação explícita de VAE
Em geral, resultados de geração muito semelhantes em ambos os ambientes de trabalho. Porém, há uma diferença, e não é de forma alguma devido ao VAE: se você substituir a escolha explícita do autoencoder variacional pela opção “Automático”, a imagem fica um pouco mais nebulosa, mas seus detalhes permanecem os mesmos. O fato é que no AUTOMATIC1111 e no ComfyUI o processamento dos vetores de token gerados pelo decodificador CLIP é organizado de maneira um pouco diferente.
No entanto, o ganho de tempo – embora devido a uma pequena desvantagem na utilização do GP – para o ComfyUI é óbvio: quase uma vez e meia para um conjunto tão simples de parâmetros de entrada. Não é de surpreender que muitos entusiastas do desenho de IA, uma vez que se deram ao trabalho de compreender os meandros (e literalmente também) dos ciclogramas deste ambiente de trabalho, comecem a dar-lhe preferência em vez do AUTOMATIC1111 – mesmo para pontos de verificação baseados em SD 1.5
Enquanto isso, passaremos para o SDXL 1.0. Vamos sair do AUTOMATIC1111 (não apenas fechando a janela do navegador, lembre-se, por precaução – você também precisa fechar o servidor do ambiente de trabalho iniciado a partir da linha de comando usando “Ctrl” + “C” com confirmação), execute o arquivo run_nvidia_gpu.bat ComfyUI. Aliás, após iniciá-lo, a página desejada (http://127.0.0.1:8188/) é aberta automaticamente no navegador padrão.
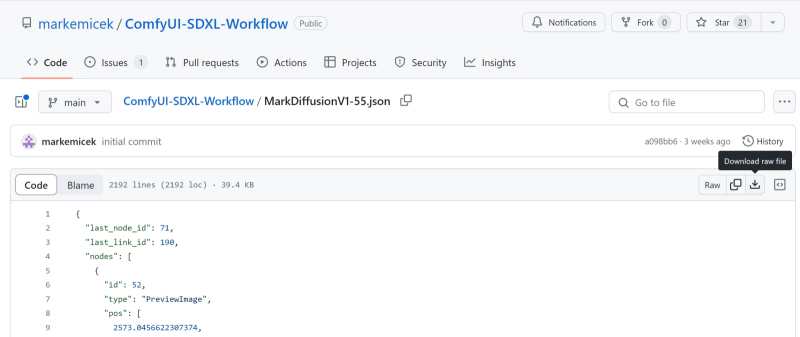
Fonte: captura de tela do GitHub
Recordemos que a característica fundamental do SDXL é a presença de dois postos de controle que atuam em conjunto. Claro, não é tão difícil desenhar manualmente os nós e conexões necessários entre eles no campo da interface ComfyUI, mas entusiastas sofisticados já cuidaram de todos os iniciantes postando um arquivo JSON com um fluxo pré-configurado no GitHub: ComfyUI-SDXL -Fluxo de trabalho. Faça o download no link fornecido (no lado direito da página há uma imagem de uma seta para baixo apontando para um colchete voltada para baixo; você precisa clicar nele para fazer o download), salve-o onde, se necessário, pudermos encontre-o rapidamente e carregue-o no ComfyUI por meio do botão Carregar no painel direito. O arquivo se chama Workflow ComfyUI SDXL 0.9.json, mas não se confunda – é exatamente o mesmo para a versão 1.0: não há diferenças na estrutura do fluxo de trabalho entre eles.
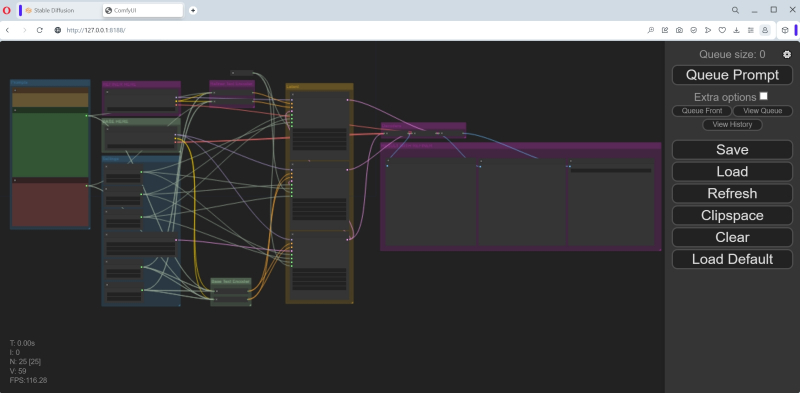
Parece confuso? Na verdade, tudo é lógico – mas é melhor compreender essa lógica de forma sequencial, sem pressa.
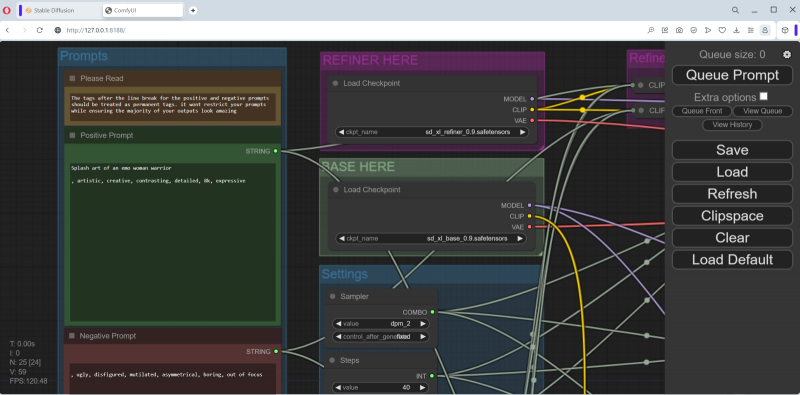
Primeiro, vamos estudar a coluna de nós mais à esquerda combinada no bloco “Prompts”. No topo há um aviso (“Por favor, leia!”) de que para obter imagens de maior qualidade você deve manter a estrutura proposta dos prompts: para um positivo, por exemplo, na primeira linha você precisa dar uma resposta geral descrição da cena que está sendo criada (Splash art de uma mulher guerreira emo), e em seguida, através de uma quebra de linha, separada por vírgula, comandos já relacionados à sua aparência geral (artística, criativa, contrastante, detalhada, 8k, expressiva). A propósito, no exemplo que foi carregado no ComfyUI por padrão, essa lacuna (embora apenas na forma de um espaço) estava presente. Um guerreiro emo é, claro, uma coisa boa, mas vamos primeiro reproduzir a galáxia em uma garrafa no modelo mais recente – e então poderemos dar rédea solta a fantasias mais frívolas.
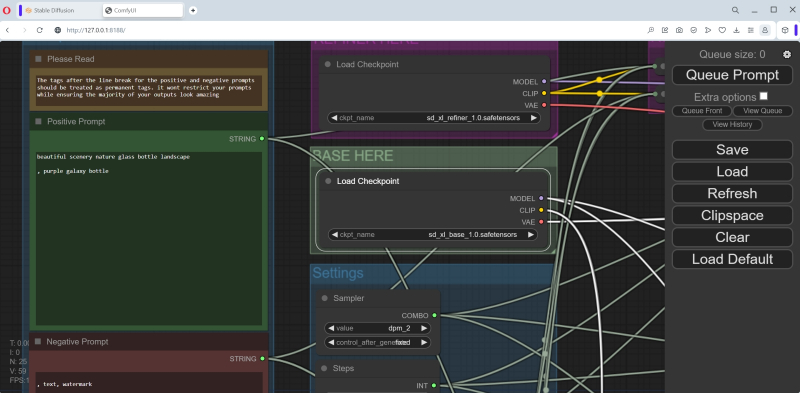
Então, vamos alterar seu conteúdo no nó “Prompt positivo” para
Bela paisagem natureza garrafa de vidro paisagem
, Garrafa de galáxia roxa
(Preste atenção à quebra de linha!) e “Prompt negativo” – para
, Texto, marca d’água
(Exatamente assim: a primeira linha está vazia, para criá-la basta pressionar Enter; o segundo começa com vírgula e espaço).
Ao mesmo tempo, atualizamos as informações na coluna adjacente de nós, onde os dois primeiros representam blocos de chamada para ambos os modelos SDXL, o refinador e a base. Os arquivos correspondentes para a versão 0.9 estão inicialmente listados aqui, pois o autor deste fluxo de trabalho o criou antes do lançamento da versão final do novo modelo. Portanto, clicando nos campos com os nomes dos pontos de verificação com o mouse, selecione sd_xl_refiner_1.0.safetensors para o nó superior e sd_xl_base_1.0.safetensors para o nó inferior.
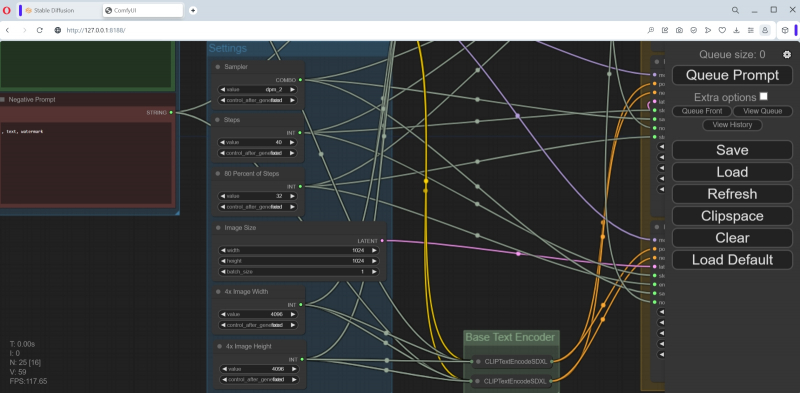
Abaixo, na mesma coluna, há um grande bloco “Configurações” com nós para diversas configurações, que deve ser muito familiar aos leitores de nossos materiais anteriores sobre geração de imagens usando o modelo SD 1.5 no ambiente de trabalho AUTOMATIC1111. Vamos tentar alinhá-los com aqueles com os quais o ComfyUI criou galáxias em uma garrafa durante seu primeiro lançamento.
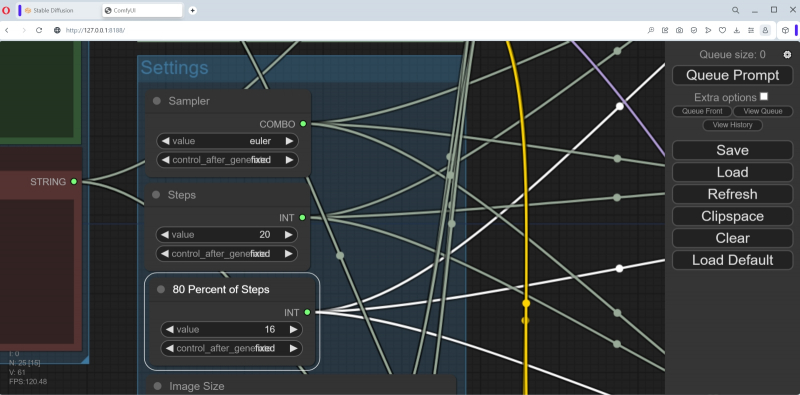
O amostrador foi inicialmente especificado como dpm_2 – altere-o para euler. O número de etapas é 40 – seja 20, como da última vez. “80 por cento dos passos” – obviamente 16 (80% de 40).
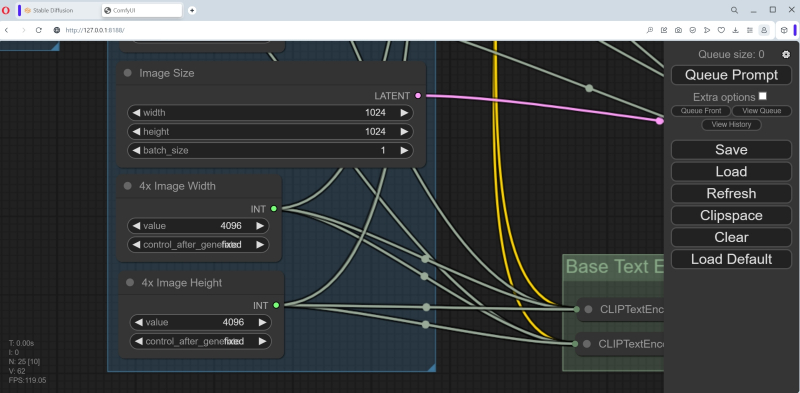
«Tamanho da imagem” seja 1024 × 1024, o padrão para SDXL. O número de imagens em uma série (lote) é 1, a largura e a altura de uma imagem quádrupla (por área, quero dizer) são 4.096 e 4.096, é claro. Essa quadruplicação é puramente auxiliar e será feita dentro da “caixa preta” (para identificar ainda mais claramente os detalhes de alta frequência da imagem) – a imagem final ainda terá o tamanho 1024 × 1024.
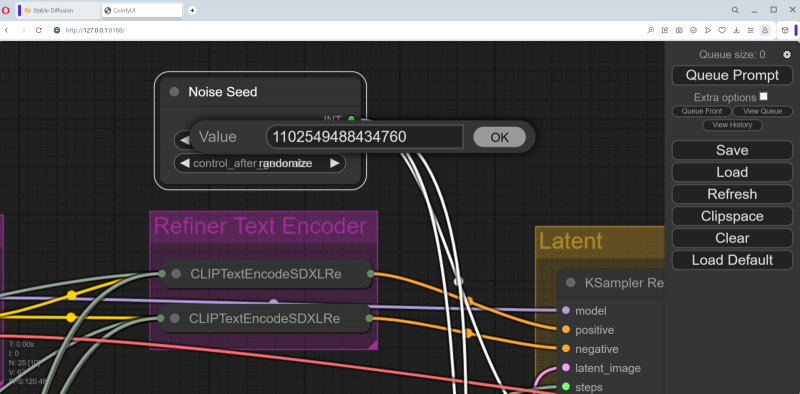
Na coluna à direita do topo, há um nó discreto “Noise seed”. Ele pode ser exibido recolhido (apenas o título em uma caixa estreita), mas clicar no título expandirá o bloco para que dois campos para inserção de parâmetros sejam abertos. No primeiro, “Valor”, colocaremos a mesma semente que tinha a galáxia que recebemos na garrafa – 1102549488434759.
Abaixo estão os mininós de serviço que não requerem configurações do usuário – os pares CLIPTextEncodeSDXLRefiner e CLIPTextEncodeSDXL. Para os interessados em saber exatamente o que faz a rede neural que cria as imagens neste local, remetemos a um breve resumo do próprio conceito de CLIP (em conexão com o parâmetro de geração “Clip drop”) da segunda parte do nosso “ Workshop” sobre desenho de IA, bem como uma descrição geral deste modelo.
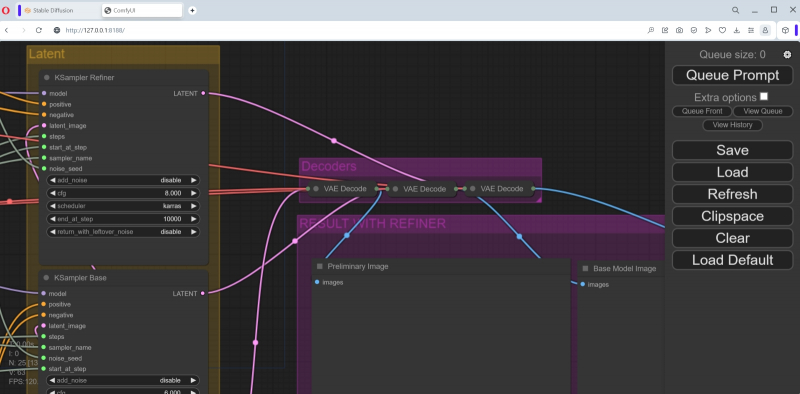
A próxima coluna contém três nós que especificam os parâmetros de entrada dos pontos de verificação SDXL: refinador KSampler, KSampler Base e KSampler preliminar. A partir deles, linhas rosa para emissão de imagens levam aos blocos de pós-processamento VAE correspondentes (na coluna da extrema direita), e abaixo deles há três janelas para as imagens finais. Mais precisamente, no primeiro aparecerá a imagem gerada pelo checkpoint preliminar, no segundo – pela base (que recebeu geração latente do modelo preliminar como um dos parâmetros de entrada), e no terceiro – pelo mais próximo (que , por sua vez, recebeu a imagem para processamento posterior do modelo base). Essencialmente, o KSampler Base é uma visualização (com remoção completa de ruído latente) da operação do submodelo SDXL principal,
Vamos salvar o fluxo de trabalho modificado no arquivo workflow-test-002.json e iniciá-lo para execução clicando no botão “Queue Prompt”. Aqui você precisa ser paciente: a princípio nada parece acontecer, mas a carga da GPU sobe para 20-22% e as mensagens de serviço começam a ser executadas na janela de linha de comando onde o servidor SDXL 1.0 está sendo executado.
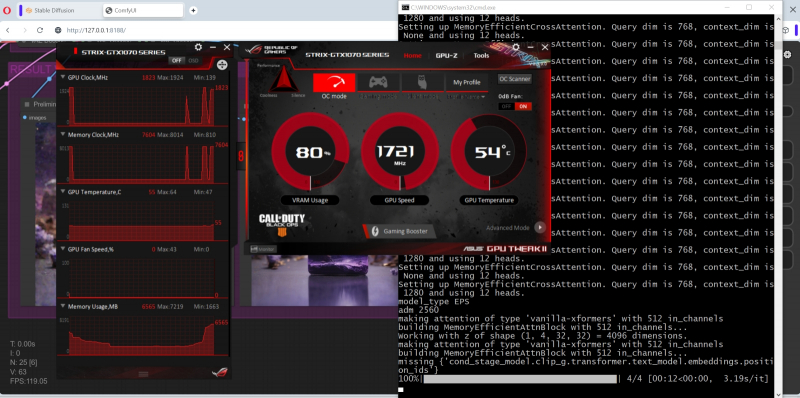
Então nosso computador de teste passou por momentos difíceis: a utilização da GPU saltou para 80%, depois ainda mais, por algum tempo a interface do sistema operacional parou de responder aos comandos do teclado… Em geral, a geração real da primeira imagem também demorou alguns segundos (8-9 – mas somente depois de tudo o que é necessário ter sido previamente carregado na memória de vídeo; por isso faz sentido trabalhar com SDXL em lotes, em vez de uma imagem por vez), e no total o sistema funcionou por 808 segundos até recebeu uma imagem 1024 × 1024 completamente acabada, gastando cada iteração em 3,19 s.

Fonte: geração de IA baseada no modelo SDXL 1.0
Sem dúvida, a imagem é verdadeiramente maravilhosa. Mas será que o jogo vale a pena – para proprietários de placas de vídeo antigas, quero dizer? Pontos de verificação baseados em SD 1.5 em AUTOMATIC1111 podem demorar mais para calcular imagens, mas este ambiente de trabalho consome memória de vídeo moderadamente – e não interfere no trabalho de terceiros no PC (pelo menos ao digitar textos e navegar em páginas da web). Aqui, ao que parece, vale a pena fechar todos os softwares de terceiros, remover a aceleração de hardware nas configurações do navegador – e, em geral, liberar o máximo de memória de vídeo possível, já que o ComfyUI coloca uma carga significativa no hardware disponível para ele.
No entanto, o SDXL, devido à sua arquitetura radicalmente atualizada, está ganhando cada vez mais popularidade – e, portanto, todo entusiasta de desenho de IA deve ter as ferramentas para trabalhar com confiança com este modelo generativo. O que fala a favor da escolha do ComfyUI como tal kit de ferramentas – além de considerações puramente técnicas – é que utilizar um resultado bem-sucedido obtido por alguém neste ambiente de trabalho é extremamente simples. Basta mover a imagem com o mouse do Explorer para o campo principal da interface web – e tudo correrá: você pode selecionar amostradores, alterar pontos de verificação, tentar outras combinações de CFGs e o número de etapas quase indefinidamente, sem se preocupar que alguns um ponto importante foi perdido durante a cópia dos parâmetros originais.

Fonte: geração de IA baseada no modelo SDXL 1.0
Sim, levará algum tempo para dominar o ComfyUI inicialmente, mas depois lidar com o “monstro de macarrão” domesticado se tornará cada vez mais fácil. Para este ambiente de trabalho já existem inversões de texto, LoRA e ciclogramas detalhados para qualquer caso (desde o acabamento/redesenho até o dimensionamento com detalhes) e até guias sobre como redigir dicas de maneira eficaz. Além disso, com o tempo, a julgar pela atitude decisiva do comfyanonymous e de toda a equipe do Stability.ai, o próprio ComfyUI ou um ambiente semelhante em espírito tem todas as chances de receber o status de oficialmente recomendado para uso pelos desenvolvedores do Stable Diffusion.
É claro que no mundo do software de código aberto, a concorrência permanecerá alta em qualquer caso, mas os criadores do AUTOMATIC1111 e de outras ferramentas para desenho de IA local (no sentido, não em um serviço em nuvem) já estão tendo que fazer esforços consideráveis para atender ao alto nível estabelecido pela ComfyUI, o padrão de flexibilidade e eficiência. Além disso, esta competição só pode beneficiar toda a comunidade de entusiastas da computação gráfica generativa.
PS: Por motivos técnicos não é possível postar imagens com metadados no site avalanche noticias. Os interessados podem baixar um arquivo ZIP com fotos ilustrando o verdadeiro “Workshop”, criado no ComfyUI e contendo seus próprios ciclogramas, neste link. Alguns deles foram gerados usando nós Searge SDXL personalizados: para que esses ciclogramas funcionem, você precisará instalar a extensão apropriada para ComfyUI.
PPS: Enquanto o artigo estava sendo preparado para publicação, o autor do AUTOMATIC1111 lançou a atualização 1.6.0-RC (release candidate) – então, muito provavelmente, em um futuro muito próximo, este ambiente de trabalho em sua versão estável receberá suporte expandido para SDXL, incluindo cocriação de submodelos com troca de imagens ruidosas. Fique ligado para novos lançamentos do nosso “Workshop”!