
A principal dificuldade do FLUX.1 [dev] do ponto de vista do proprietário de um PC econômico é a incapacidade de encaixar o modelo UNet correspondente na memória de vídeo (embora neste caso, estritamente falando, não seja um UNet, como SD 1.5 e SDXL, mas um DiT – transformador de difusão, mas a terminologia já foi estabelecida) em sua totalidade, a menos que você recorra à compressão/quantização completamente impiedosa de seus pesos, que mencionamos no anterior “Oficina”. Parece que esta é a solução: em vez do FP16 básico codificado em UNet/DiT ou mesmo GGUF Q8_0, usamos uma versão muito mais compacta, usamos para encontrar uma composição adequada, fechando os olhos para as inevitáveis falhas nos detalhes, e então reexecutaremos o ciclograma com as mesmas dicas e uma semente, mas com um modelo não tão comprimido. Isso funcionará?
Espaço de trabalho ComfyUI com um ciclograma básico, com o qual interagiremos principalmente desta vez
⇡#Você sabe desenhar?
Lembramos, por precaução, que estamos analisando os modelos da família FLUX.1 pela terceira vez consecutiva, e todas as informações sobre eles, bem como nosso ambiente de trabalho ComfyUI padrão (no momento) para implantação em um PC local, já foi fornecido em artigos anteriores, bem como informações sobre quantização de pesos de modelos de IA usando o método GGUF. Para fins de experiência, vamos baixar mais três modelos do repositório UNet/DiT quantizado por GGUF para FLUX.1, a saber:
- Flux1-dev-Q2_K.gguf – aproximadamente 4 GB,
- Flux1-dev-Q4_K_S.gguf – 7 GB,
- Flux1-dev-Q5_K_S.gguf — 8 GB.
- Flux_dev.safetensors – 23 GB (esta é a versão base FP16 do FLUX.1 [dev], originalmente enviada pelo Black Forest Labs),
- Flux1-dev-fp8.safetensors — 12 GB,
- Flux1-dev-Q8_0.gguf — 13 GB.
Os maiores pontos fortes do FLUX.1 são a adesão meticulosa a longas descrições, realismo fotográfico e exibição de texto. Portanto, convidaremos o sistema a criar uma imagem viva de um personagem literário famoso usando a seguinte dica (a mesma neste caso para CLIP e para T5; é usado um ciclograma de referência da página com exemplos compilados pelo próprio ComfyAnonimous, minimamente modificado para permitir o carregamento de modelos codificados em GGUF) –
— E execute-o com a mesma semente “646124957372314” para todas as seis UNets alternadas com diferentes graus de compactação.

Nunca antes Kisa Vorobyaninov esteve tão perto do fracasso (fonte: geração de IA baseada no modelo FLUX.1 [dev])
O resultado é desanimador, para ser honesto. Para começar: a exibição de texto relativamente longo é realmente excelente em todos os modelos, exceto talvez para o Q_2_K compactado abertamente (embora as letras sejam geralmente corretas), e destacando na dica de ferramenta o apóstrofo exigido pelas regras da gramática francesa com um a barra invertida ajuda – este apóstrofo na palavra “N’AI” é claramente visível mesmo nas fotos onde o sinal diacrítico acima do “E” está perdido. As coisas também estão indo bem com o realismo, bem como com a adesão composicional geral ao prompt. Mas aqui estão os detalhes…
Em primeiro lugar, a notória barba, neste caso associada não à espada (examinamos este exemplo da última vez), mas à idade. Como o cavalheiro é designado como “envelhecido” na dica de ferramenta, é extremamente difícil se livrar da barba e do bigode na imagem gerada pelo modelo destilado (e, além disso, parece estranhamente caoticamente censurado) – mesmo apesar da persistência menção de “rosto mal barbeado (sem barba, sem bigode: 1,5)”. Na versão Q4_K_S para esta semente em particular, 646124957372314, o lugar da barba ainda era ocupado pela barba por fazer de cinco dias, o que mais uma vez enfatiza o quão imprudente seria esperar encontrar uma semente de sucesso com modelos quantizados mais leves, e depois com ela e com a mesma dica obtenha uma composição completamente semelhante já com um UNet/DiT completo – Q8_0 ou FP16.
Outro ponto sutil: preste atenção no chapéu. Embora a dica indique diretamente que ele deveria ficar de cabeça para baixo, o FLUX.1 não permite que você obtenha essa posição, mesmo se você quebrá-lo – e testamos isso em várias dezenas de gerações com sementes diferentes. Não são apenas os chapéus: os objetos invertidos deste modelo geralmente são difíceis de capturar e muito menos danificados. Vasos quebrados, cicatrizes de batalha nos rostos de guerreiros severos, feridas nos corpos de monstros derrotados, até mesmo piercings aparentemente inocentes – quase todos os pedidos de imagens de objetos fortemente deformados/modificados que são bem conhecidos do modelo em sua forma intocada são atendidos muito mal. Na comunidade de entusiastas, foram expressas ideias de que talvez os objetos danificados estivessem completamente ausentes do banco de dados de treinamento FLUX.1 ou não tenham sido deliberadamente acompanhados por uma descrição de texto correspondente, de modo que no final o conjunto de tokens no qual o O pacote T5+CLIP analisa a menção de um “chapéu invertido” “, não indica nada específico no espaço latente. Mas em qualquer caso, enquanto as matrizes de imagens de treinamento do FLUX.1 com suas descrições detalhadas continuarem fechadas ao público em geral, é impossível julgar isso com total confiança.
O menu do gerenciador de complementos ComfyUI (aliás, ele também se considera um complemento – com número de série 1, é claro) permite que você atualize de forma conveniente e rápida versões do próprio ambiente de trabalho e do complemento já instalado -ons
E agora – o mais importante: vejamos as velocidades. As variantes UNet/DiT utilizadas geraram imagens com resolução de cerca de 1 Mpix (832×1216 pixels) a uma taxa de aproximadamente 30 s por iteração para os três primeiros (Q_2_K, Q4_K_S, Q5_K_S) e cerca de 40 s/it. para os três restantes – Q8_0, FP8, FP16. Sim, em nossa máquina de teste (GTX 1070 8 GB + 24 GB DDR3) seria difícil esperar uma forte diferença de desempenho entre as variantes Q8_0 e FP16, mas sua ausência (praticamente; apenas dentro de algumas unidades do s/it. ) para Q_2_K e Q5_K_S , que diferem em volume quase pela metade, é muito mais impressionante. Provavelmente, a necessidade de movimentar muitos gigabytes de dados entre a memória de vídeo e a RAM lenta do sistema durante o carregamento sequencial dos primeiros modelos T5 e depois UNet anula a vantagem proporcionada pelo fato de que variantes com compactação mais séria cabem inteiramente na RAM de vídeo. De uma forma ou de outra, o sacrifício da qualidade da imagem ao usar Q_2_K em comparação até mesmo com Q4_K_S, sem falar em Q8_0, não parece muito justificado. Em outras palavras, é possível usar um modelo supercomprimido e mais rápido, mas não se deve esperar que mais tarde, tendo encontrado uma combinação bem-sucedida de uma dica e uma semente com sua ajuda, você obterá um resultado completamente semelhante na composição, só que com qualidade melhorada, ocupando um volume UNet maior. Isso significa que a prototipagem rápida apenas devido à compactação do modelo FLUX.1 [dev] principal não funcionará. Pelo menos com garantia.
⇡#Largura e altura
Quais são as melhores opções? A primeira coisa que vem à mente é aproveitar a versatilidade orgulhosamente apontada pelos criadores do FLUX.1 em termos de suporte a uma ampla gama de resoluções de imagem, de 0,1 a 2,5 megapixels. É intuitivamente claro que uma imagem pequena deve ser gerada muito mais rapidamente do que uma imagem grande. E, talvez, se entre as fotos com resolução de 0,1 megapixels (convencionalmente aproximadamente 300 × 300 pixels) rapidamente preparadas pela modelo, você se deparar com uma composição que faz sucesso – mas, claro, não repleta de detalhes – será possível, mantendo as mesmas dicas e sementes, mudar para, digamos, 2 megapixels – e obter aproximadamente a mesma imagem, mas com uma resolução de quase 1400 × 1400?
Vamos verificar. E vamos começar alterando o nó “Empty Latent Image”, que define as dimensões da tela no ciclograma de referência ComfyAnonimous, para um mais conveniente ao trabalhar com FLUX.1 – permitindo que você defina essas dimensões de forma mais prática do que calcular manualmente o número de pixels de cada lado. Para fazer isso, por sua vez, você precisará enriquecer o ComfyUI com a próxima adição e, ao mesmo tempo, iremos lembrá-lo de como instalar essas mesmas adições no ambiente de trabalho.
Informações sobre os acréscimos necessários para executar o ciclograma fornecidas logo no início na janela de informações do gerenciador ComfyUI
No momento em que este Workshop foi escrito, a versão atual do ComfyUI era 2.0.7. Já discutimos mais de uma vez como instalá-lo como um pacote independente (simplesmente descompactando-o no diretório de trabalho a partir de um arquivo ZIP, sem o procedimento usual de instalação do Windows com configuração de variáveis de ambiente no registro). Por uma questão de comodidade, complementaremos este ambiente de trabalho com um gerenciador de instalação – ComfyUI-Manager na versão atual 2.48.1. As instruções para implantá-lo são fornecidas na página inicial do projeto no GitHub e são extremamente transparentes. Em particular, para o nosso caso – quando o próprio ComfyUI é instalado como um pacote independente (versão portátil) – é necessário:
- Instale o git (aqueles que instalaram o AUTOMATIC1111 conosco já fizeram isso uma vez),
- Carregue o script de instalação scripts/install-manager-for-portable-version.bat no diretório onde o ComfyUI já está implantado (deve estar próximo ao script de inicialização padrão para o ambiente de trabalho – run_nvidia_gpu.bat),
- Clique duas vezes no arquivo deste script e aguarde a conclusão do processo.
Em seguida, após iniciar o ambiente de trabalho – apenas usando o mesmo run_nvidia_gpu.bat – um botão “Gerenciador” aparecerá na parte inferior do menu principal da interface web do ComfyUI. É através disso que instalaremos os add-ons necessários e ao mesmo tempo atualizaremos eles e o ambiente de trabalho como um todo – isso é muito mais conveniente do que manualmente.
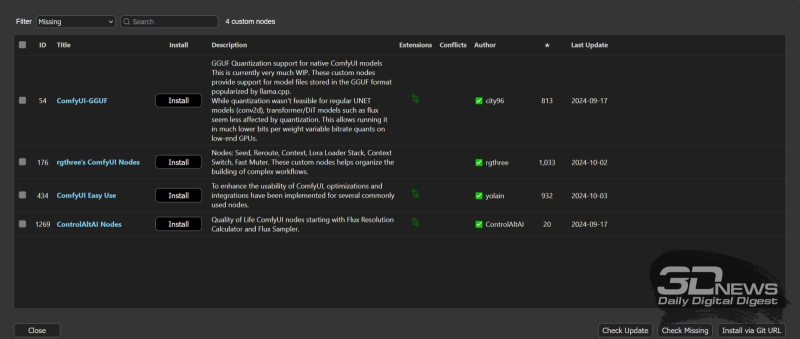
Na verdade, forneceremos imediatamente tudo o que você precisa inicialmente. Tendo aberto o menu do gerenciador ComfyUI, clique no botão “Custom Nodes Manager” no topo da coluna do meio dos controles disponíveis ali – e na janela que aparece com uma lista de extensões disponíveis, encontraremos através da janela de pesquisa , selecione e instale o seguinte sequencialmente (links para as páginas do projeto correspondentes no GitHub são fornecidos diretamente na interface, o que permite mais uma vez garantir que o complemento correto esteja selecionado corretamente):
- ComfyUI-GGUF – sem ele é impossível carregar versões quantizadas de modelos, e quem trabalhou conosco na prototipagem rápida com [schnell] já deveria ter,
- Rgtrês-comfy – contém muitos nós de serviço que são convenientes para nosso próximo trabalho,
- ComfyUI-Easy-Use também são nós de serviço convenientes, mas com suas próprias especificidades,
- ControlAltAI é outro conjunto de nós de serviço úteis voltados especificamente para modelos FLUX.
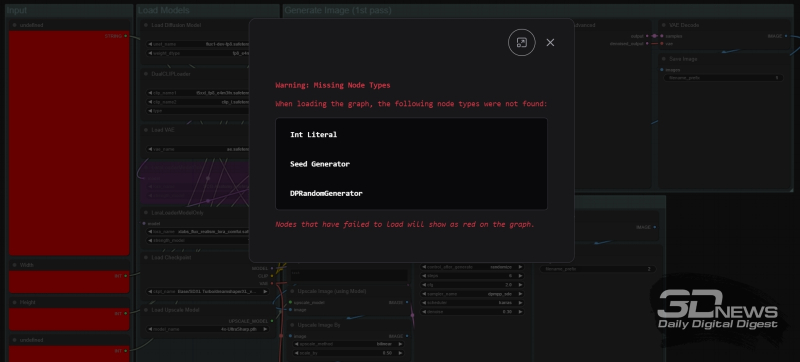
É assim que o gerenciador ComfyUI informa sobre a presença de extensões que ainda não foram instaladas no ciclograma carregado no ambiente de trabalho
Na verdade, você não precisará inserir manualmente os nomes de todos esses nós na janela de pesquisa se baixar uma coleção de imagens do link fornecido próximo ao final deste “Workshop”, que começaremos a obter agora. Salvos no formato PNG com JSON integrado, esses arquivos, quando arrastados para o espaço de trabalho do ComfyUI, reproduzirão os ciclogramas incorporados neles. Se alguns dos nós do usuário não estiverem implantados no momento, os blocos retangulares correspondentes serão marcados em vermelho no ciclograma e o complemento do gerenciador emitirá um aviso correspondente. Abrindo então o menu do mesmo gerenciador e clicando no botão “Instalar nós personalizados ausentes”, não será difícil instalar sequencialmente todas as extensões necessárias. Também é recomendado – no mesmo menu – executar regularmente, pelo menos uma vez por semana, o comando “Atualizar tudo”: isso manterá atualizados o próprio ambiente de trabalho e todos os seus acréscimos.
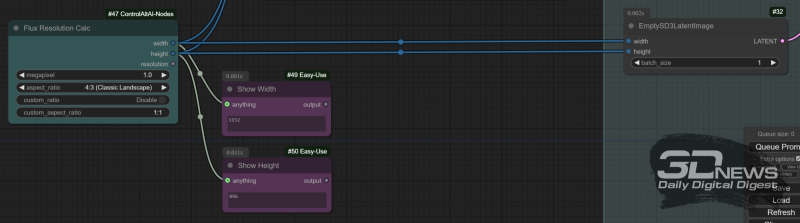
O nó “Flux Resolution Calc” do complemento ControlAltAI permite que você não pense no número exato de pixels em cada lado da tela selecionada: basta definir a proporção desses mesmos lados e a resolução geral da imagem em megapixels. Por sua vez, os nós “Mostrar Qualquer Coisa”, neste caso utilizados para controlar os valores exatos da largura e altura da tela, exibirão em suas janelas os valores calculados por esta “calculadora”
Para verificar se pelo menos a composição geral da imagem gerada pelo FLUX.1 [dev] é preservada ao aumentar apenas a resolução da tela (sua área em megapixels) mantendo outros parâmetros – dicas e sementes, modificamos o ciclograma original obtido da página com exemplos de ComfyAnonimous, que já foram mencionados mais de uma vez. Lá, o tamanho da tela é definido pelo nó “EmptySD3LatentImage”. Por que “SD3” – significando SD3M, é claro – sim, porque esse modelo de desenvolvimento de IA de estabilidade não muito bem-sucedido, assim como a família FLUX.1, está focado em suportar telas em uma ampla gama de resoluções, até 2,5 megapixels Se você usar o gerador de imagem latente padrão para SDXL/SD 1.5, cujo limite é de 1 megapixel, poderá encontrar problemas indesejados em altas resoluções.
No entanto, “EmptySD3LatentImage” envolve definir manualmente a largura e a altura da tela. Vamos facilitar nossa vida: convertemos os campos de entrada desses dois valores em entradas para conexão de nós externos – para isso, clique com o botão direito no retângulo que o representa e no menu que aparece selecione a opção “Converter Widget para Entrada”, no menu do próximo nível – “Converter largura em entrada” e faça o mesmo com a altura da tela. Mas apenas para definir valores específicos de largura e altura, usaremos o nó “Flux Resolution Calc” do complemento ControlAltAI recém-instalado – para que ele apareça na área de trabalho do ComfyUI, basta clicar duas vezes com o botão esquerdo do mouse em qualquer área livre dele e comece a digitar a palavra-chave “resolução”. O nó permite definir a resolução da tela na faixa de 0,1 a 2,5 megapixels e também escolher entre uma ampla variedade de proporções de aspecto ou definir a sua própria manualmente. Para controlar os valores exatos do comprimento e largura da imagem futura, os nós “Show Any” do pacote “Easy Use” são úteis: basta colocar dois deles perto de “Flux Resolution Calc” e conectar o “width ” e saídas de “altura” deste último para eles. As mesmas saídas irão para as entradas correspondentes dos nós “Model Sampling Flux” e “EmptySD3LatentImage”.

Todas as três imagens mostradas têm a mesma proporção (4:3), sementes e pontas. No canto superior esquerdo está uma imagem com resolução de 0,1 Mpix (368 × 272), abaixo está 0,5 Mpix (816 × 608), à direita está 1,0 Mpix (1152 × 896) (fonte: geração AI baseada no FLUX modelo .1 [dev])
Agora tudo é simples: insira prompts de texto nos campos apropriados, selecione a versão UNet/DiT GGUF com quantização Q8_0 como modelo, fixe o valor inicial (no nó “Random Noise”, altere o valor do parâmetro “control_after_generate” de “randomizado” para “fixo”), selecione qualquer proporção desejada em “Flux Resolution Calc” – e inicie a geração sequencial com a mesma parâmetros, mas com resolução consistentemente variável, a partir de 0,1 megapixels. Como mostra a prática, embora em geral as composições e esquemas de cores das imagens sejam semelhantes, a diferença mesmo em grandes detalhes é grande demais para ser negligenciada. Em outras palavras, você não conseguirá economizar tempo preparando imagens de 0,1 megapixels em alta velocidade e esperando que uma particularmente bem-sucedida apareça, e então enviar uma imagem com a mesma semente, mas com uma resolução mais alta, para geração . É uma pena; Definitivamente valeu a pena tentar.
⇡#Movimento do cavaleiro
Deve-se dizer que o uso de uma resolução reduzida, é claro, proporciona economia de tempo: se uma imagem de 0,5 megapixel for gerada em nossa máquina de teste a uma velocidade de 17-19 s/it., então uma imagem de 1 megapixel será gerado em 36-38 s/it. Considerando que as etapas para geração de imagens com FLUX.1 [dev] normalmente são necessárias no mínimo 20 (e, aliás, a diferença entre 20, 25 e 30 não é muito grande e nem sempre favorece gerações mais longas – outro evidência da natureza destilada deste modelo), a diferença é bastante perceptível. Mas aqui está o problema: se a imagem implica a presença de pequenos detalhes significativos – letras combinadas em palavras significativas; mãos de mãos humanas que não se assemelhariam a vassouras desgrenhadas; padrões finamente elaborados que não se fundem em uma confusão caótica de pixels, então, com uma diminuição na resolução, a qualidade dessas pequenas coisas (que não são nada pequenas) diminui radicalmente. O modelo simplesmente não possui pixels suficientes nesta área específica da imagem extraída do espaço latente para exibir adequadamente os elementos sutis exigidos pela dica.
Então, você ainda terá que sair do FLUX.1 [dev] para uma busca gratuita por seed, sem esperança de aumentar de alguma forma a velocidade da prototipagem?
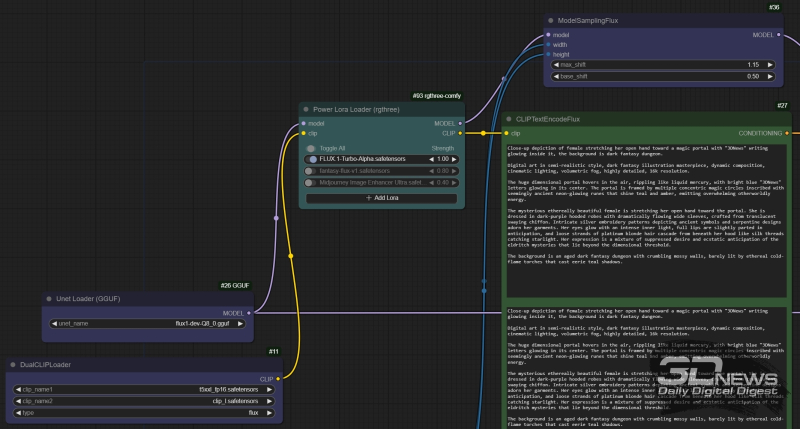
O nó “Power Lora Loader” do pacote rgtrês é inserido no fluxo de dados “model” entre os nós “Unet loader (GGUF)” e “ModelSamplingFlux”, e no fluxo “clip” – entre “DualCLIPLoader” e “CLIPTextEncodeFlux ”
Mas não! Um problema semelhante para SDXL foi parcialmente resolvido pelo (pré) treinamento de versões aceleradas do modelo correspondente – por meio da destilação, já familiar para nós no FLUX.1. Somente, aplicada a um modelo inicialmente não destilado, tal destilação não levou àquela notável diminuição na qualidade que distingue FLUX.1 [schnell] de [dev]. Por exemplo, SDXL Turbo é capaz de se contentar com até mesmo uma etapa de geração para gerar imagens bastante toleráveis em vez de 30-50 para a versão básica – graças à tecnologia de destilação por difusão adversária (ADD) e SDXL Lightning em várias variações – dois , quatro ou oito. Na verdade, FLUX.1 [schnell] é uma versão de [dev] destilada de maneira semelhante ao ADD, mas esse procedimento, como é fácil de ver, levou a uma queda muito perceptível na qualidade estética subjetiva das gerações [schnell] , especialmente em termos de exibição de pele humana, gradientes suaves de cores e texto.

Imagens obtidas com parâmetros básicos completamente idênticos, mas a primeira – com FLUX.1-Turbo-Alpha e em 8 passos, e a segunda e terceira – sem LoRA e em 20 e 30 passos, respectivamente; linha superior – com resolução de 0,5 megapixels, linha inferior – 1,0 megapixels (fonte: geração de IA baseada no modelo FLUX.1 [dev])
O exemplo acima mostra, em primeiro lugar, que para FLUX.1 [dev] realmente não há diferença fundamental entre as etapas de 20 e 30 gerações – além disso, pequenos detalhes significativos (mãos, runas brilhantes em um círculo mágico) provavelmente perderão qualidade à medida que o número de etapas aumenta o que eles compram. O acelerador FLUX.1-Turbo-Alpha.safetensors, por sua vez, torna ligeiramente mais grosseiros os pequenos detalhes e até trata os grandes (rosto, capuz, cabelo) com certa liberdade – mas ao mesmo tempo preserva a estética geral e a composição da imagem ( para cada resolução de tela selecionada) e, em geral, fornece um resultado bastante decente, especialmente em termos de reprodução de texto. A economia de tempo para cada geração é significativa: afinal, são 8 etapas de cerca de meio minuto cada (no caso de uma tela de 1 megapixel), e não 20, e principalmente não 30.
Assim, para prototipagem rápida com FLUX.1 [dev], parece lógico utilizar um acelerador LoRA (no nosso caso – FLUX.1-Turbo-Alpha.safetensors) com redução no número de etapas de geração para 8, também como a escolha de 1,0 Mpix como resolução básica – e se pequenos detalhes não forem tão importantes, então 0,5 megapixels servirá. Então, preparar cada imagem no modo de pesquisa livre levará no máximo 4 a 5 minutos, o que é bastante aceitável. Mais precisamente, é aceitável se for possível alimentar o modelo generativo com uma sugestão de que ele seria interpretado de forma otimizada – e quase garantido que geraria um resultado adequado ao operador, se não o primeiro, então o terceiro, o quinto, ou pelo menos pior décima vez (enquanto no caso do SD 1.5/SDXL, com toda a riqueza de pontos de verificação/adições disponíveis para eles hoje e a alta velocidade de inferência, uma busca livre por um visual bem-sucedido a implementação de um prompt de texto pode levar horas, senão dias). Isso é mesmo real?
Em princípio sim, e agora vamos finalmente explicar que tipo de texto (e por que exatamente) foi colocado nas janelas do nó “CLIPTextEncodeFlux” para obter as imagens mostradas até agora nos exemplos com uma figura em um gás capa em frente ao portal. O conceito original da imagem, formulado em inglês em linguagem natural (tendo em vista a sua posterior interpretação para CLIP pelo modelo T5 – falamos detalhadamente sobre esta funcionalidade do FLUX.1 na última vez), era o seguinte:
Simples, conciso, fácil de lembrar; mas para o CLIP isso certamente será demais, e para o T5 – muito pouco. Vamos dar asas à nossa imaginação e transformar a descrição telegraficamente precisa da imagem pretendida em uma mais detalhada, focando nos detalhes que são importantes para a imagem final – uma descrição mais detalhada do próprio portal, da figura que está na frente dele , suas roupas e arredores:

À esquerda está uma imagem com a dica expandida que acabamos de dar, seed 1002970411169969 e resolução de 0,5 megapixels; à direita – tudo é igual, mas a resolução é de 1,0 megapixels (fonte: geração de IA baseada no modelo FLUX.1 [dev])
Em princípio, este já é um texto suficientemente extenso para que o FLUX.1, ávido por longas descrições, possa criar pinturas pitorescas a partir dele. Mas não é possível oferecer ao modelo instruções ainda mais detalhadas para aumentar ao máximo a probabilidade de produzir uma imagem conhecidamente aceitável (para começar, um texto bem legível)?
⇡#Profundidade de detalhe
O par de imagens mostrado acima, gerado por nossa dica de ferramenta expandida, indica claramente que, embora o FLUX.1 [dev] acelerado por LoRA tenha capturado a composição geral corretamente neste caso, ele tem problemas óbvios em exibir até mesmo um texto tão curto. Talvez o fato seja que este texto deva estar localizado no meio, ou mesmo no fundo, e portanto obviamente não pode ocupar muito espaço na tela – portanto, em particular, uma tentativa de reproduzi-lo de 0,5 megapixels parece muito pior do que uma tentativa de 1- opção de megapixels. Mas não é só isso.
Os modelos da família FLUX.1 simplesmente adoram dicas extensas e bem detalhadas – você deve ser guiado por 150 palavras, melhor ainda, 200. Nem todos, especialmente se o inglês não for sua língua nativa, são capazes de fazê-lo artisticamente e ao mesmo tempo descrever substantivamente a ideia de um futuro digital, a obra-prima é tão completa. Está tudo bem – os chatbots inteligentes virão em seu socorro e, se você não tiver acesso direto ao ChatGPT ou ao Claude, poderá sempre usar modelos generativos disponíveis gratuitamente na Internet. Por exemplo, Junia.ai, que está posicionado como “AI Prompt Writer & ChatGPT Prompt Generator”. Tudo é simples aí: inserimos a versão original da nossa dica na janela do site – esta é a mesma, apenas expandida manualmente a partir da frase curta original – e após clicar no botão “Gerar” obtemos (por exemplo, já que cada vez que o texto na dica gerada será um pouco diferente) o seguinte:

Novamente os mesmos parâmetros de geração, incluindo a semente, novamente à esquerda está uma imagem com resolução de 0,5 Mpix, e à direita – 1,0 Mpix, mas desta vez foi usada uma dica Junia.ai enriquecida (fonte: geração de IA baseada em o modelo FLUX.1 [dev])
Já com menos de 180 palavras, já é muito bom – e é imediatamente perceptível, aliás, que este serviço generativo é otimizado especificamente para compilar dicas para desenho de IA: por iniciativa própria, adicionou ao texto indicações do estilo da imagem , sua resolução, detalhes, etc. Tudo parece ótimo, e se você colocar este texto em ambas as janelas de entrada do nó “CLIPTextEncodeFlux”, o resultado deverá ser mais adequado à tarefa.
Acontece que é esse o caso, embora ainda haja definitivamente espaço para melhorias, especialmente em termos de texto: digamos que, dado o ponto de partida dado, ele simplesmente se recusa a ser exibido. E aqui, novamente, você não pode prescindir da participação direta de um operador ao vivo do outro lado da tela – os bots inteligentes claramente não conseguem lidar com a situação sozinhos. Na comunidade de entusiastas do desenho de IA, existe uma opinião bastante definida de que T5, apesar de todos os seus méritos, não é o intérprete mais talentoso, e para facilitar seu trabalho, uma longa dica (escrita de forma independente ou usando modelos generativos que convertem texto para texto) deve ser organizado de uma determinada maneira. Nomeadamente:
- No primeiro parágrafo, dê uma descrição geral da imagem pretendida – sua composição, posição relativa e características principais dos elementos principais, e apenas com o mínimo necessário de adjetivos, com foco nos substantivos,
- No segundo parágrafo, registre o estilo visual da imagem – deve ser fotorrealista ou copiar algum tipo de estilo pictórico; qual é a suposta resolução da imagem, qual é a sua paleta de cores, etc.,
- Em seguida, dedique um parágrafo a uma descrição detalhada ao máximo, rica em adjetivos e verbos, de cada um dos objetos-chave da composição,
- E, por fim, o último parágrafo deve ser dedicado ao fundo da imagem futura, se for significativa em termos de composição.
Tendo trabalhado desta forma no texto proposto por Junia.ai, construímos isto:

Dica expandida e repensada (parágrafo por parágrafo), semente 1002970411169969, resoluções: esquerda – 1,5 Mpix (1408 × 1088 pixels, 155 s/it.), no centro – 2,0 Mpix (1632 × 1216 pixels, 374 s/it. . ), à direita – 2,5 megapixels (1824×1376 pixels, 814 s/it.) (fonte: geração de IA baseada no modelo FLUX.1 [dev])
Estilo de arte digital, iluminação cinematográfica, neblina volumétrica, altamente detalhada, resolução de 8k, arte de fantasia sombria.
O fundo é uma masmorra de fantasia escura e envelhecida com paredes cobertas de musgo em ruínas, mal iluminada por tochas etéreas de chamas frias que lançam sombras azuis misteriosas.
Na verdade, apresentamos anteriormente as imagens obtidas justamente com esta dica e semente 1002970411169969 como ilustrações com resoluções de 0,1, 0,5 e 1,0 megapixels. Aliás, é perceptível que quando o número de pixels aumenta acima de 1,5 megapixels, embora melhore a elaboração nos detalhes individuais (texturas de tecido, pedra, etc.), as letras voltam a funcionar pior para o modelo. Aparentemente, 1,0 megapixels é a resolução mais bem equilibrada em termos de equilíbrio entre a qualidade de exibição de letras de tamanho médio, ponteiros e outras pequenas coisas que não são nada pequenas. Detenhamo-nos nisso mais tarde.
⇡#Mas isso não é tudo
A questão permanece: o que fazer com a distribuição dos parágrafos de texto recebidos em um par de janelas de entrada do nó “CLIPTextEncodeFlux”? Nos exemplos anteriores, tanto a janela “clip_l” quanto a janela “t5xxl” simplesmente copiaram toda esta longa dica na íntegra, todos os cinco parágrafos, embora os leitores de nosso último “Workshop” devam lembrar que existe um direito à vida e uma abordagem diferente quando apenas uma descrição geral da imagem é fornecida à entrada do conversor de texto em tokens CLIP, e uma descrição mais extensa é fornecida à entrada do “intérprete” T5. Talvez, neste caso, faça sentido limitar-se apenas ao primeiro ou dois primeiros parágrafos da janela superior e inserir todos eles por extenso ou apenas os restantes da descrição geral, na inferior?

Várias versões de combinações de cinco parágrafos da nossa dica completa nas janelas de entrada de texto para CLIP e T5; veja explicações no texto (fonte: geração de IA baseada no modelo FLUX.1 [dev])
Conduzimos um experimento bastante simples: primeiro, deixando todos os cinco parágrafos do texto de dica preparado na janela inferior do nó “CLIPTextEncodeFlux”, inserimos os dois primeiros juntos, ou apenas o primeiro, ou apenas o segundo na janela superior ; então os dois primeiros parágrafos foram retirados da janela do T5, deixando apenas o terceiro ao quinto, e na janela do CLIP foi repetido o ciclo anterior – os dois primeiros parágrafos, só o primeiro, só o segundo. Os resultados são óbvios: a primeira opção é melhor que as outras em termos de composição e qualidade de detalhes (principalmente texto) – quando o modelo CLIP alimenta os dois primeiros parágrafos, delineando a construção geral e a solução artística da imagem pretendida, e para T5 estes parágrafos são duplicados, complementados por mais três com instruções mais detalhadas sobre como e o que deve ser representado. Com todas as outras combinações de parágrafos, ou a figura do misterioso estranho no portal sofre (o pescoço está excessivamente esticado), ou o texto, ou as misteriosas runas nos círculos mágicos, ou tudo isso junto.

À esquerda estão dicas de ferramentas idênticas em ambas as janelas do nó “CLIPTextEncodeFlux”; à direita – para CLIP apenas os dois primeiros parágrafos, para T5 – todos os cinco (fonte: geração de IA baseada no modelo FLUX.1 [dev])
Contudo, seria ainda imprudente privar o CLIP da oportunidade de trabalhar no texto completo de forma independente, e não apenas com a ajuda do T5. No exemplo que damos, há uma diferença entre imagens com duplicação completa dos prompts de texto e com apenas os dois primeiros parágrafos restantes no campo CLIP. Sim, é quase imperceptível – manifesta-se apenas em detalhes sutis como a expressão facial da figura no portal, a elaboração do bordado em sua capa e a maior/menos semelhança do ornamento de âmbar na parte externa da magia. círculo com uma escrita alfabética misteriosa, e não apenas com padrões abstratos. Se você limitar o trabalho de gerar uma imagem adequada ao operador com resolução de 1 megapixel, pode não fazer sentido copiar o mesmo texto em ambas as janelas “CLIPTextEncodeFlux” – mesmo que a superior contenha apenas as instruções mais gerais para o Artista de IA e apenas o segundo contém uma dica completa. Mas tendo em conta que a imagem pode (e muitas vezes precisa ser!) ampliada, não só sem perder qualidade nos detalhes, mas com o seu aumento, é melhor ficar com a duplicação completa.
Como já vimos que ampliar a geração do FLUX.1 [dev] simplesmente aumentando a resolução do canvas mantendo todos os outros parâmetros não funciona – no sentido, viola a composição original – vamos nos voltar para uma ferramenta que tem sido bem conhecida desde os dias do SD 1.5. Ou seja, à transformação imagem em imagem, durante a qual a imagem original passa a ser a base da tela para uma maior, de forma que a imagem ampliada não seja gerada em um retângulo obtido a partir de uma semente aleatória, caoticamente preenchido com manchas coloridas, mas, na verdade, em uma imagem original esticada e apenas ligeiramente barulhenta. Todos os nós necessários para isso já estão disponíveis nas extensões que instalamos para o ComfyUI, e o ciclograma correspondente é apresentado no conjunto de imagens que acompanha este “Workshop” (um link para elas é fornecido mais próximo ao final do texto) chamado Dev_upscaled_B_00014_ .png.
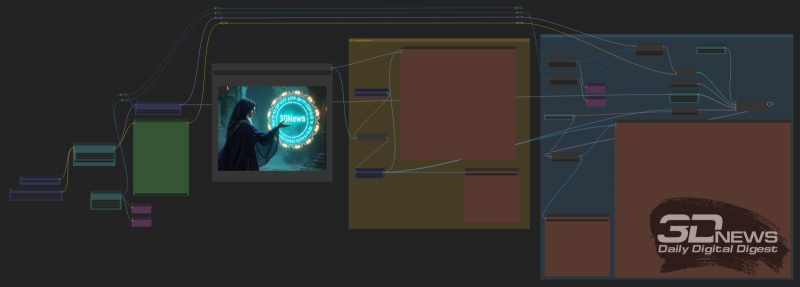
Vista geral do ciclograma para uma ampliação dupla (para cada uma das medições) da imagem de 1 megapixel que recebemos usando o mesmo modelo FLUX.1 [dev]
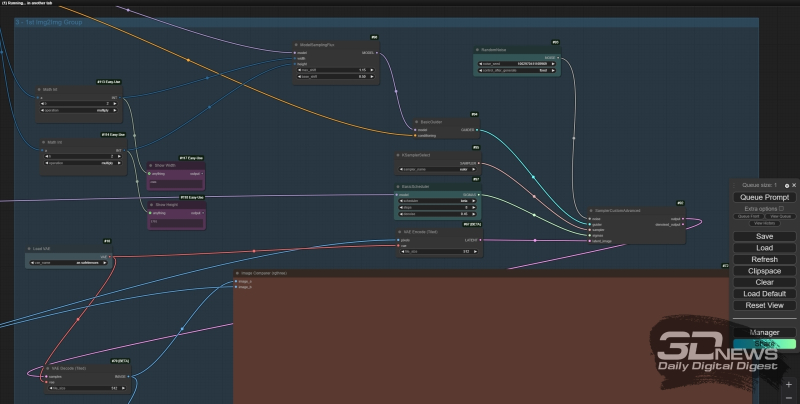
Organização do bloco de nós “1st Img2Img Group”: o parâmetro “denoise” (neste caso – 0,45) do nó “BasicScheduler” é responsável pela força da influência da nova geração no resultado da anterior.
Na verdade, com esta exceção – que em vez da imagem latente diretamente de “EmptySD3LatentImage”, a entrada do nó principal do processador FLUX.1, “SampleCustomAdvanced”, é alimentada através de “VAE Encode (Tiled)”, uma imagem esticada por um externo upscaler destinado à ampliação – o “1º” bloco Img2Img Group” é quase completamente idêntico ao ciclograma original com o qual o considerado Temos apenas imagens com cinco parágrafos de texto como dica. Do ponto de vista prático, o nó “Image Comparer (rgtwo)” do add-on correspondente é interessante: permite, simplesmente movendo o mouse para a esquerda e para a direita, comparar visualmente duas imagens fornecidas às suas entradas. E, como você pode ver, a qualidade realmente melhora com essa ampliação.
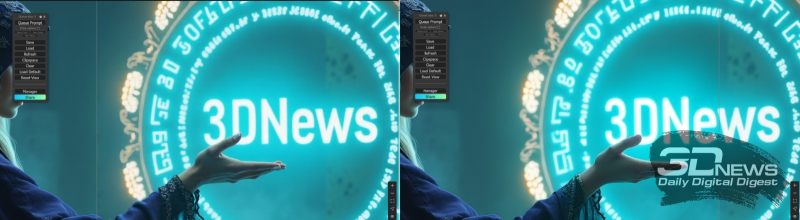
Uma demonstração visual do funcionamento do nó “Image Comparer (rgtwo)”: à esquerda – a linha vertical do controle deslizante é deslocada para a esquerda; o campo da imagem à direita dela, incluindo a mão e o portal mágico, corresponde ao resultado do dimensionamento com qualidade aumentada; à direita – o controle deslizante foi movido para o outro lado e agora é claramente visível que a imagem simplesmente ampliada usando “Upscale Image By” é claramente inferior em detalhes à final
Mais adiante em nosso computador de teste, dimensionar a imagem da mesma maneira – carregando a imagem agora salva no arquivo Dev_upscaled_B_00014_.png no nó “Load Image” no mesmo diagrama e simplesmente repetindo o processo – é problemático: reter na memória e processar simultaneamente a imagem distribuída duas vezes em ambas as dimensões A imagem não será suficiente nem para a quantidade total de RAM e RAM de vídeo à sua disposição. O upscale de mosaico bem desenvolvido para SD 1.5/SDXL baseado em ControlNet para modelos FLUX ainda está em sua infância, embora já sejam conhecidos exemplos razoavelmente funcionais do uso de tal técnica. No entanto, ninguém se preocupa em aplicar o upscale lado a lado à imagem resultante com um ponto de verificação SDXL, por exemplo, o que ao mesmo tempo eliminará o problema de a pele humana parecer excessivamente antinatural, especialmente em resoluções tão altas.
Vista geral do ciclograma para a próxima ampliação de imagem dupla (para cada uma das dimensões) – mas com o ponto de verificação SDXL Turbo
Para fazer isso, você precisará instalar outra extensão, UltimateSDUpscale, através do gerenciador ComfyUI, e usar um ciclograma extremamente simples, que está integrado ao arquivo UltimateSDUpscale_00002_.png do nosso arquivo com exemplos. Como resultado, uma imagem com resolução de 4 megapixels (2304 × 1792) resultará em uma qualidade ainda mais aprimorada de 16 megapixels (4608 × 3584).
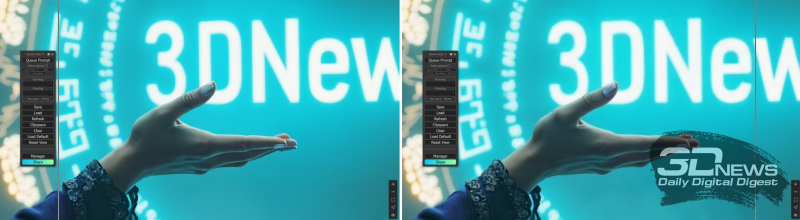
E o nó “Image Comparer (rgtwo)” funciona novamente, somente após UltimateSDUpscale: à esquerda – saída do dimensionamento final com FLUX.1 [dev]; à direita está uma ampliação dupla (para cada uma das dimensões, ou seja, quatro vezes em área) com o ponto de verificação DreamShaper XL Turbo v. 2.1
Por fim, se isso não bastasse, os entusiastas contam com a poderosa ferramenta Make Tile SEGS Upscale do pacote ComfyUI-Impact-Pack, que também precisa ser instalada no ambiente de trabalho por meio do gerenciador. Para usá-lo, porém, você terá que ter bastante paciência – em nosso computador de teste, o procedimento para obter uma imagem com resolução de 9216 × 7168 pixels, o arquivo MakeTileSEGS_upscale_00017_.png com tamanho de 54 MB, demorou mais mais de seis horas, mas se você quiser imprimir a imagem resultante na forma de um pôster A3, por exemplo, este é o tamanho certo.

Por motivos técnicos, nesta página podemos colocar uma imagem com tamanho horizontal máximo de apenas 1600 pixels, enquanto na original são 9216 (fonte: geração de IA baseada no modelo FLUX.1 [dev])
Todos os arquivos mencionados ao longo deste “Workshop” podem ser baixados em um único arquivo (atenção: 104 MB!) da nuvem. E aqui paramos de estudar a família de modelos FLUX.1 – e começamos a dar uma olhada mais de perto no Stable Diffusion 3.5: a comunidade de entusiastas do desenho de IA tem grandes esperanças nisso. Talvez este modelo não destilado consiga se tornar a principal ferramenta de trabalho dos fãs da computação gráfica generativa, deslocando finalmente o merecido SDXL deste pedestal? Espere e veja.