
A Untether AI anunciou a arquitetura de IA de próxima geração speedAI (codinome “Boqueria”), focada em cargas de inferência. Com uma eficiência energética de 30 Tflops/W e desempenho de até 2 Pflops por chip, o speedAI define um novo padrão para eficiência de energia e densidade de computação, diz a empresa.

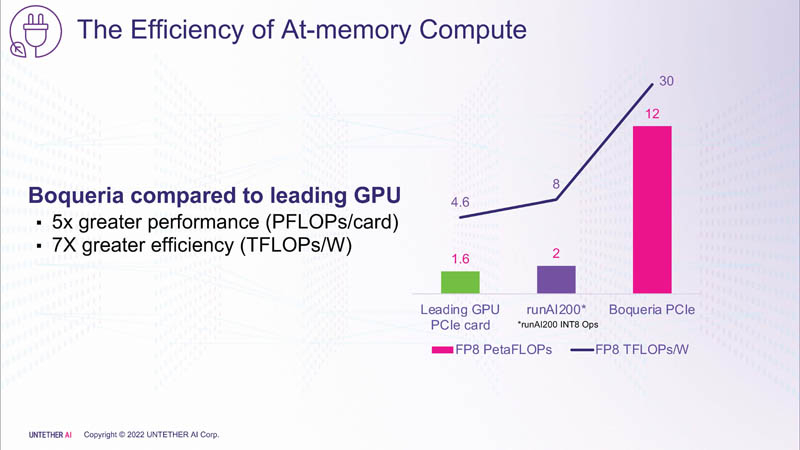
Como a computação na memória é muito mais eficiente em termos de energia do que as arquiteturas tradicionais em algumas tarefas, ela pode fornecer maior desempenho para a mesma quantidade de energia. A primeira geração de dispositivos runAI em 2020, o Untether AI atinge uma eficiência energética de 8 Tflops/W para computação INT8. A nova arquitetura speedAI já entrega 30 TFlops/W.
Imagens: Untether AI (via ServeTheHome)
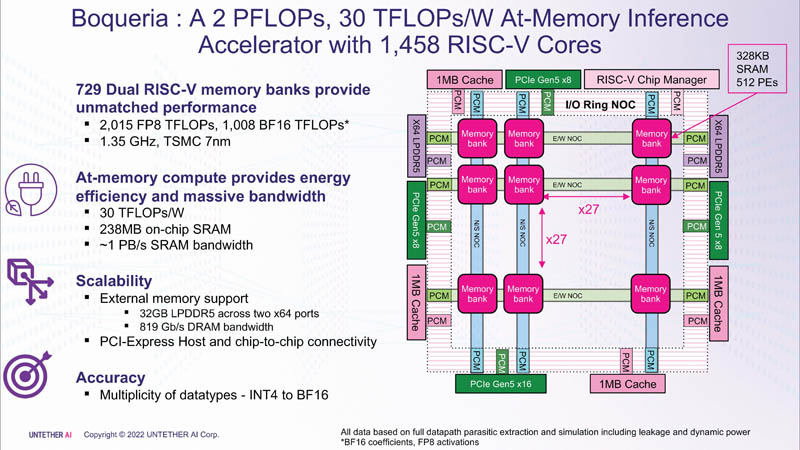
Isso foi alcançado graças à arquitetura de segunda geração, ao uso de mais de 1400 núcleos RISC-V de 7 nm otimizados (1,35 GHz) com instruções personalizadas, controle de fluxo de dados com eficiência energética e a introdução do suporte FP8. Juntos, isso possibilitou quadruplicar a eficiência do speedAI em comparação com o runAI. A novidade pode ser adaptada de forma flexível a várias arquiteturas de redes neurais. Conceitualmente, o speedAI se assemelha a outro chip RISC-V de mil núcleos – Esperanto ET-SoC-1.
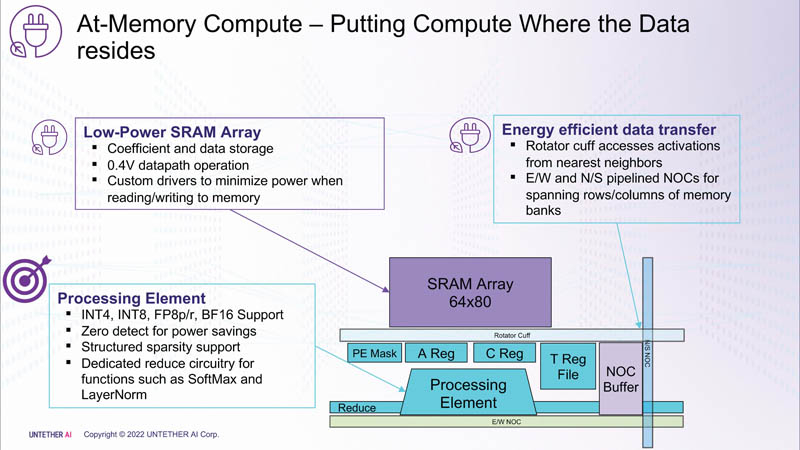
O primeiro membro da família speedAI, speedAI240, fornece 2 Pflops para cálculos FP8 ou 1 Pflops para operações BF16. Isso resulta em eficiência líder do setor, como a alegação de desempenho do BERT de 750 solicitações por segundo por watt (qps/w), que a empresa diz ser 15 vezes mais rápida que as GPUs atuais. Foi possível obter um aumento de desempenho devido à estreita integração de elementos de computação e memória.

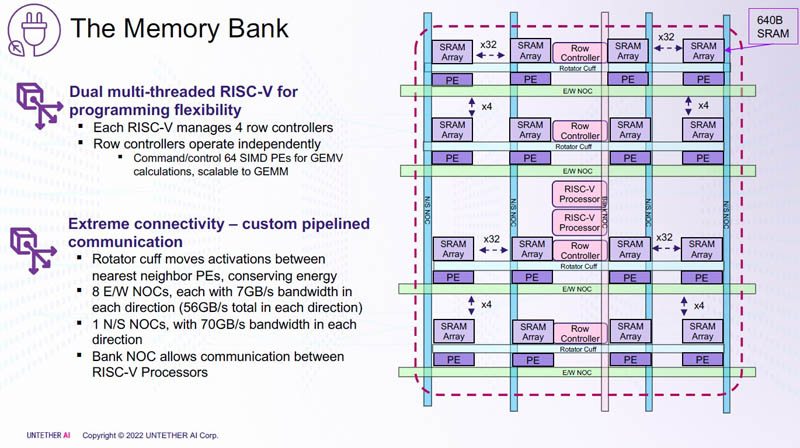
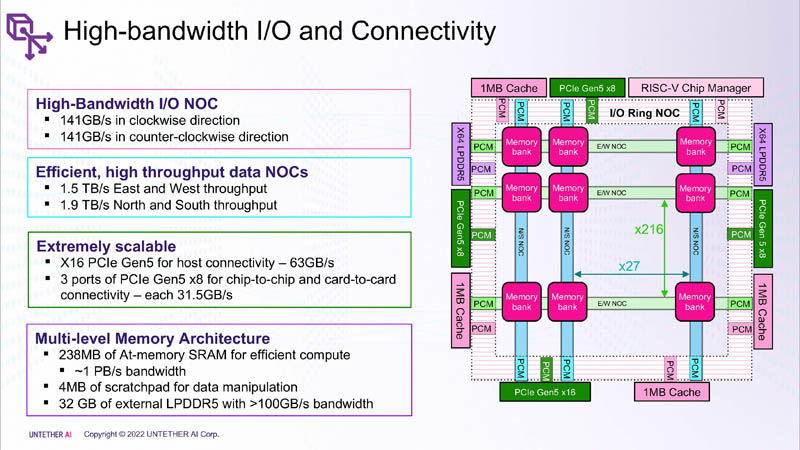
Para cada bloco SRAM de 328 KB, existem 512 unidades de computação que suportam os formatos INT4, INT8, FP8 e BF16. Cada unidade de computação tem dois núcleos RISC-V personalizados de 32 bits (RV32EMC) com suporte para quatro threads e 64 SIMDs. Existem 729 blocos no total, portanto, no total, o chip carrega 238 MB de SRAM e 1458 núcleos. Os blocos são conectados entre si por uma rede mesh, à qual também está conectado um barramento de E/S em anel, transportando quatro blocos de cache compartilhados de 1 MB, dois controladores LPDRR5 (64 bits) e portas PCIe 5.0: uma x16 para conexão com o host e três x8 para combinar fichas.
A taxa de transferência total da SRAM é de cerca de 1 PB/s, as redes mesh são de 1,5 a 1,9 TB/s, os barramentos de E/S são de 141 GB/s em ambas as direções e 32 GB de DRAM são pouco mais de 100 GB/s. As interfaces PCIe permitem combinar até três aceleradores, com seis chips speedAI240 cada. As soluções speedAI serão oferecidas tanto na forma de chips individuais quanto como parte de placas PCIe prontas e módulos M.2. As primeiras entregas para clientes selecionados devem começar no primeiro semestre de 2023.