
A Tesla já anunciou seu próprio processador D1, criado nos laboratórios da empresa, que se tornará a base do supercomputador Dojo AI. Precisamos desse sistema para criar um campo de treinamento virtual para o motorista de IA, recriando detalhadamente situações reais nas estradas. Naturalmente, tal simulador requer um enorme poder de computação: em nosso mundo, as condições de tráfego são muito complexas, mutáveis e incluem muitos fatores e variáveis.
Até recentemente, não se sabia muito sobre Dojo e D1, mas na conferência Hot Chips 34, muitas coisas interessantes foram reveladas sobre a arquitetura, design e recursos desta solução Tesla. A apresentação foi apresentada por Emil Talpes, que trabalhou anteriormente na AMD por 17 anos em design de processadores para servidores. Ele, como vários outros desenvolvedores proeminentes, está atualmente trabalhando na Tesla para criar e melhorar o hardware da empresa.
Imagens: Tesla (via ServeTheHome)
A ideia principal do D1 era a escalabilidade, então, no início do desenvolvimento de um novo chip, os criadores reconsideraram ativamente o papel de conceitos tradicionais como coerência, memória virtual etc. – nem todos os mecanismos escalam da melhor maneira quando se trata de construir um sistema de computação realmente grande. Em vez disso, foi dada preferência a uma rede de armazenamento distribuída baseada em SRAM, para a qual foi criada uma interconexão que estava uma ordem de grandeza à frente das implementações existentes em sistemas de computação distribuída.
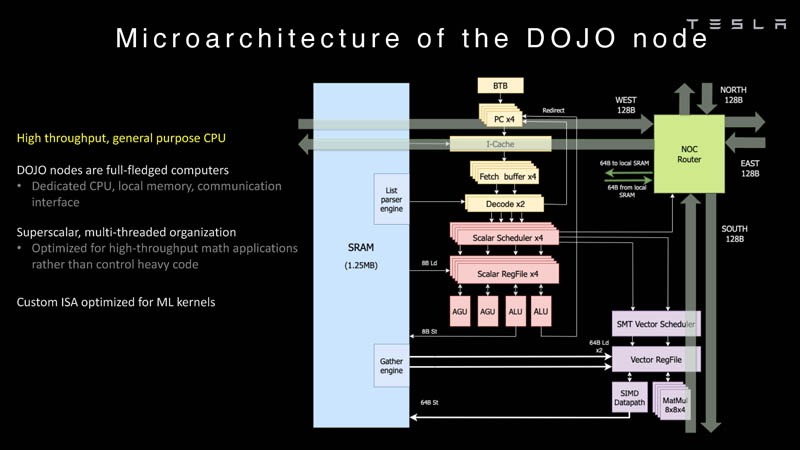
A base do processador Tesla era um núcleo de computação inteiro, baseado em algumas instruções do conjunto RISC-V, mas complementado por um grande número de instruções proprietárias otimizadas para os requisitos dos núcleos de aprendizado de máquina usados pela empresa. O bloco de matemática vetorial foi criado quase do zero, de acordo com os desenvolvedores.
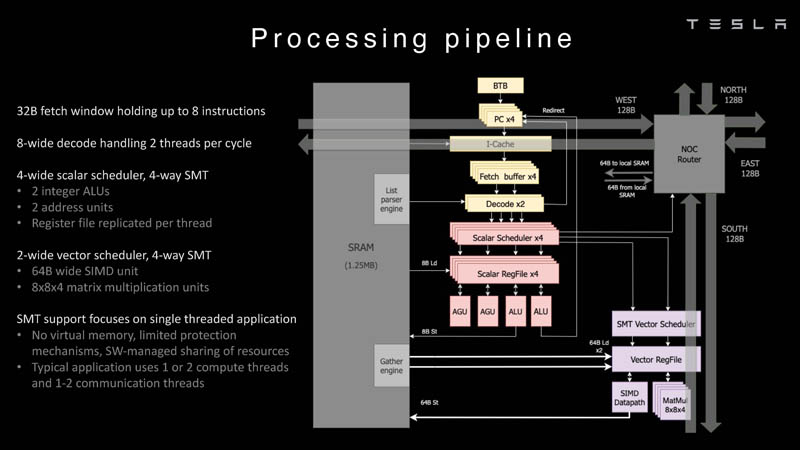
O conjunto de instruções do Dojo inclui instruções escalares, matriciais e SIMD, bem como primitivas específicas para mover dados da memória local para a memória remota, bem como semáforos com barreiras – estas últimas são necessárias para coordenar o trabalho da memória em todo o sistema. Quanto às instruções específicas para aprendizado de máquina, elas são implementadas no Dojo em hardware.
O primogênito da série, o chip D1, não é um acelerador per se – a empresa o considera um processador de uso geral de alto desempenho que não precisa de aceleradores específicos. Cada unidade de computação Dojo é representada por um único núcleo D1 com memória local e interfaces de E/S. Este é um kernel superescalar de 64 bits.
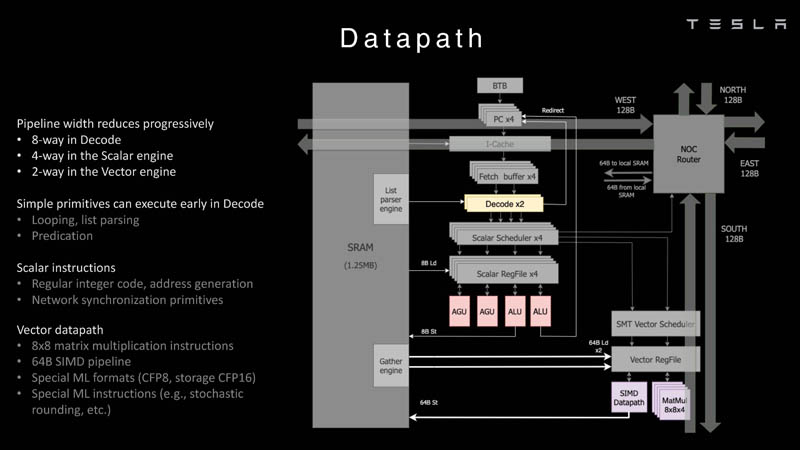
Além disso, o kernel suporta multithreading (SMT4), que é projetado para aumentar o desempenho por clock (em vez de isolar tarefas diferentes umas das outras), portanto, essa implementação de SMT não suporta memória virtual e os mecanismos de proteção são bastante limitados em funcionalidade. O gerenciamento de recursos do Dojo é tratado por uma pilha de software especializada e software proprietário.
O kernel de 64 bits possui uma janela de busca de 32 bytes, que pode conter até 8 instruções, o que corresponde à largura do decodificador. Ele, por sua vez, pode processar duas threads por ciclo. O resultado vai para os escalonadores, que o enviam para uma unidade de computação inteira (duas ALUs) ou uma unidade vetorial (simD de 64 bytes + multiplicação de matriz 8×8×4).
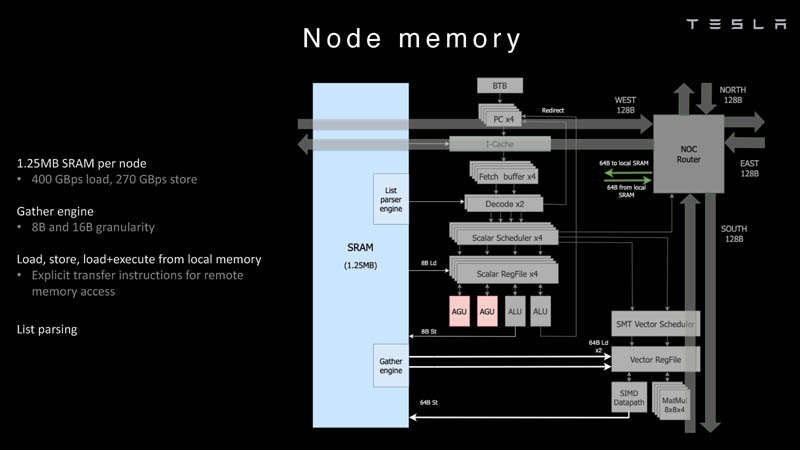
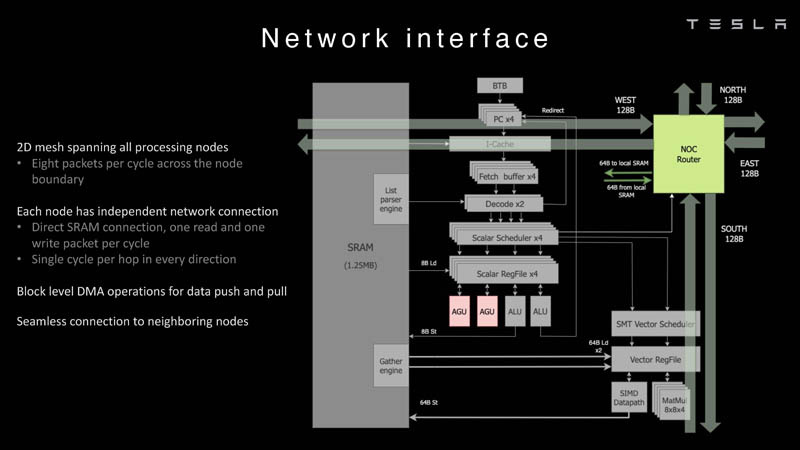
Cada núcleo D1 tem 1,25 MB de SRAM. Esta memória não é um cache, mas é capaz de carregar dados a uma velocidade de 400 GB / s e armazenar a uma velocidade de 270 GB / s e, como já mencionado, são implementadas instruções especiais no chip que permitem trabalhar com dados em outros núcleos Dojo. Para isso, o bloco SRAM possui mecanismos próprios, de modo que trabalhar com memória remota não requer operações adicionais.

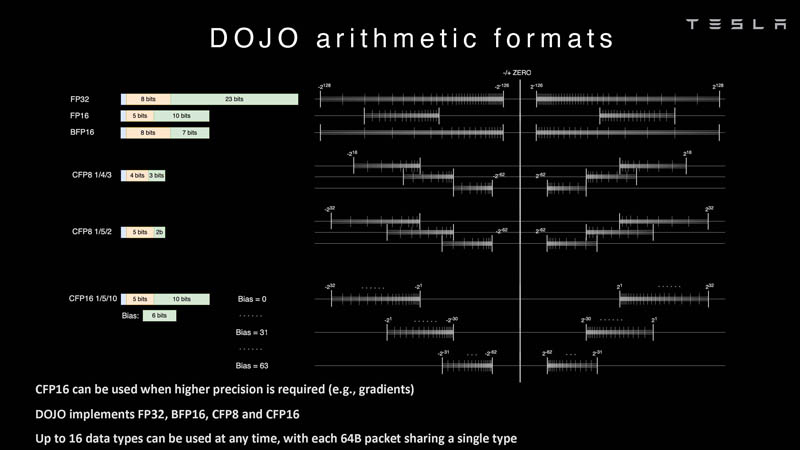
Quanto aos formatos de dados suportados, o bloco escalar suporta formatos inteiros de 8 a 64 bits, enquanto os blocos vetoriais e matriciais suportam uma ampla gama de formatos de ponto flutuante, inclusive para cálculos de precisão mista: FP32, BF16, CFP16 e CFP8. Os desenvolvedores do D1 passaram a usar todo um conjunto de representações de dados configuráveis de 8 e 16 bits – o compilador Dojo pode alterar dinamicamente os valores da mantissa e do expoente, para que o sistema possa usar até 16 formatos vetoriais diferentes , desde que não mude.

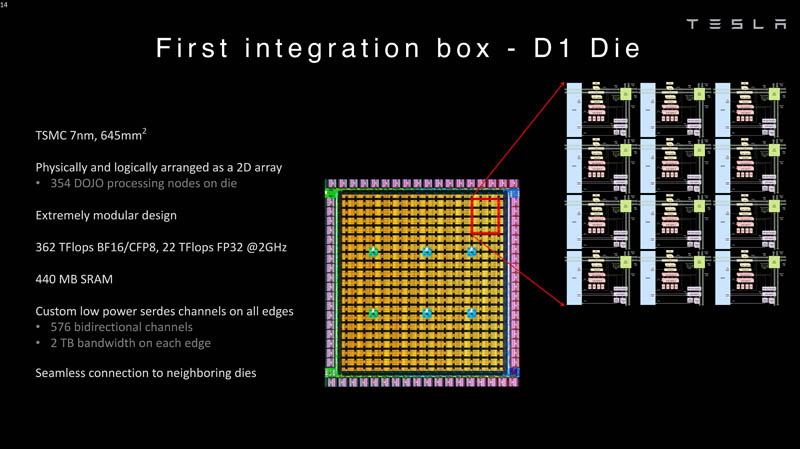
Como já mencionado, a topologia D1 utiliza uma estrutura de malha na qual cada 12 núcleos são combinados em um bloco lógico. Todo o chip D1 é um array de 18×20 núcleos, mas apenas 354 dos 360 núcleos presentes no chip estão disponíveis. A própria matriz, com área de 645 mm2, é produzida nas instalações da TSMC usando uma tecnologia de processo de 7 nm. A frequência do clock é de 2 GHz, a quantidade total de SRAM é de 440 MB.

O processador D1 desenvolve 362 Tflops no modo BF16/CFP8, no modo FP32 esse número cai para 22 Tflops. O modo FP64 não é compatível com blocos vetoriais D1, portanto, esse processador não é adequado para muitas cargas de trabalho de HPC tradicionais. Mas a Tesla construiu o D1 para uso interno, então não se importa com a compatibilidade. No entanto, nas novas gerações, D2 ou D3, esse suporte pode aparecer se estiver de acordo com os objetivos da empresa.
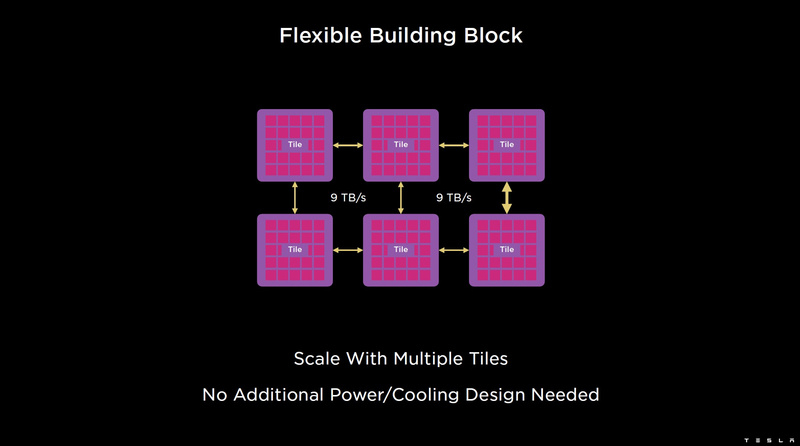
Cada matriz D1 possui uma interface SerDes externa de 576 bits com um desempenho combinado de 8 TB/s nos quatro lados, para que não se torne um gargalo ao conectar D1. Essa interface combina os cristais em uma única matriz 5×5, essa matriz de 25 cristais D1 é chamada de bloco de treinamento Dojo.
Este bloco é projetado como um módulo termoeletromecânico completo, possuindo uma interface externa com uma taxa de transferência de 4,5 TB/s por lado, com um total de 11 GB de SRAM, além de seu próprio sistema de alimentação de 15 kW. O poder de processamento de um bloco Dojo é de 9 Pflops no formato BF16/CFP8. Nesse nível de consumo de energia, o Dojo só pode ser resfriado a líquido.

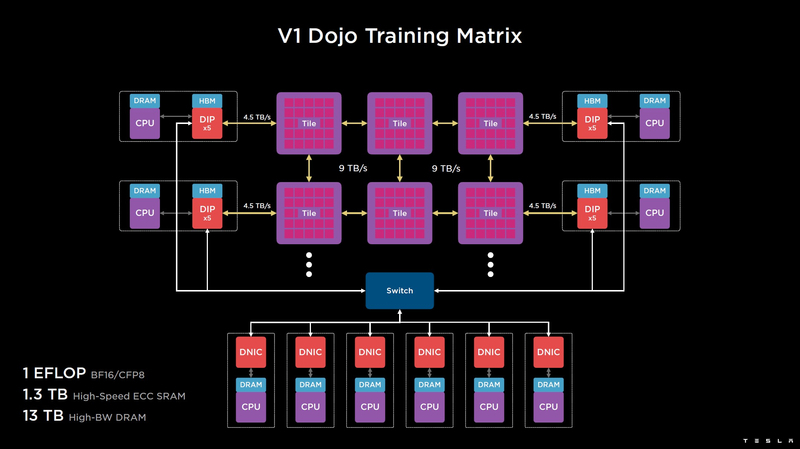
As telhas podem ser combinadas em matrizes ainda mais produtivas, mas exatamente como o supercomputador Tesla está fisicamente organizado não é totalmente claro. Para se comunicar com o mundo exterior, são usados blocos DIP – Dojo Interface Processors. Estes são processadores de interface através dos quais os blocos se comunicam com os sistemas host e são atribuídos a funções de controle, armazenamento de matrizes de dados, etc. Cada DIP não apenas executa funções de E/S, mas também contém 32 GB de memória HBM (não especificado, HBM2e ou HBM3).
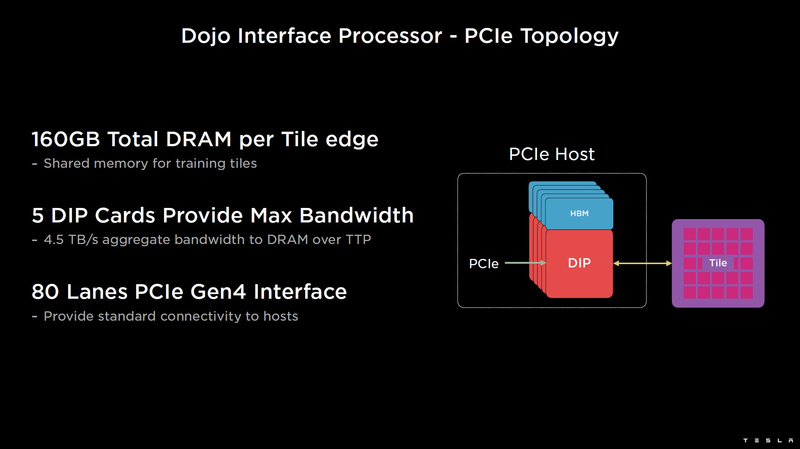
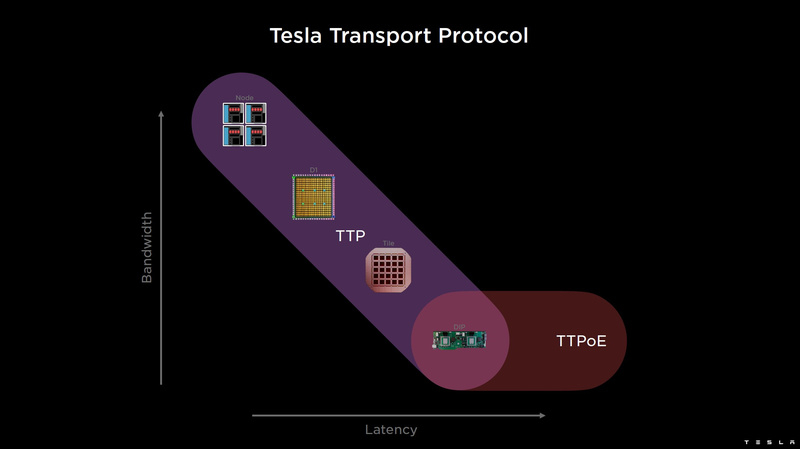
O DIP usa todo o seu protocolo de transporte (Tesla Transport Protocol, TTP), desenvolvido pela Tesla e fornecendo uma taxa de transferência de 900 GB/s, e via Ethernet – 50 GB/s. A interface externa das placas é PCI Express 4.0 e cada placa de interface carrega um par de DIPs. Existem 5 DIPs instalados em cada lado de cada fileira de ladrilhos, o que proporciona uma velocidade de até 4,5 TB/s de pilhas HBM para ladrilhos.

Nos casos em que o acesso ladrilho a ladrilho em todo o sistema requer muitos saltos (até 30 no caso de acesso borda a borda), o sistema pode usar DIPs conectados externamente por uma rede de árvore de gordura de 400 GbE, reduzindo assim o número de saltos para no máximo quatro. A taxa de transferência sofre neste caso, mas a latência vence, o que é mais importante em alguns cenários.
Na versão básica, o supercomputador Dojo V1 produz 1 Eflops no modo BF16/CFP8 e pode carregar modelos de até 1,3 TB diretamente na SRAM, outros 13 TB de dados podem ser armazenados em assemblies DIP HBM. Deve-se observar que o espaço SRAM em todo o sistema Dojo usa um único endereçamento simples. A versão full scale do Dojo terá um desempenho de até 20 eflops.
Quanto esforço a empresa precisará para lançar esse monstro e, o mais importante, fornecer software funcional e útil, é desconhecido – mas obviamente muito. O sistema é conhecido por ser compatível com o PyTorch. Atualmente, a Tesla está recebendo chips D1 pré-construídos da TSMC. Enquanto isso, a empresa está se contentando com o maior supercomputador NVIDIA AI instalado do mundo.