
A empresa GigaIO, cujo principal desenvolvimento é um sistema de interconexão distribuída baseado em PCI Express chamado FabreX, estabeleceu um novo recorde – na nova plataforma, os desenvolvedores conseguiram dobrar o número de dispositivos PCIe conectados simultaneamente, aumentando de 32 para 64.
Já contamos aos nossos leitores sobre os desenvolvimentos do GigaIO mais de uma vez. Em muitos aspectos, eles são verdadeiramente únicos, pois a infraestrutura composta criada pela empresa permite conectar significativamente mais aceleradores diferentes a um ou vários servidores do que é possível na versão clássica, mas ao mesmo tempo mantém um alto nível de utilização de esses aceleradores.

SuperNODE GigaIO. Fonte das imagens aqui e abaixo: GigaIO
No início do ano, a empresa já demonstrou um sistema com 16 aceleradores NVIDIA A100, e no verão a GigaIO apresentou um minicluster SuperNODE. Em várias configurações, o sistema pode conter 32 aceleradores AMD Instinct MI210 ou 24 aceleradores NVIDIA A100, complementados por capacidade de armazenamento de 1 PB. Ao mesmo tempo, o sistema, devido às características do FabreX, não exigia nenhuma configuração específica antes da operação.
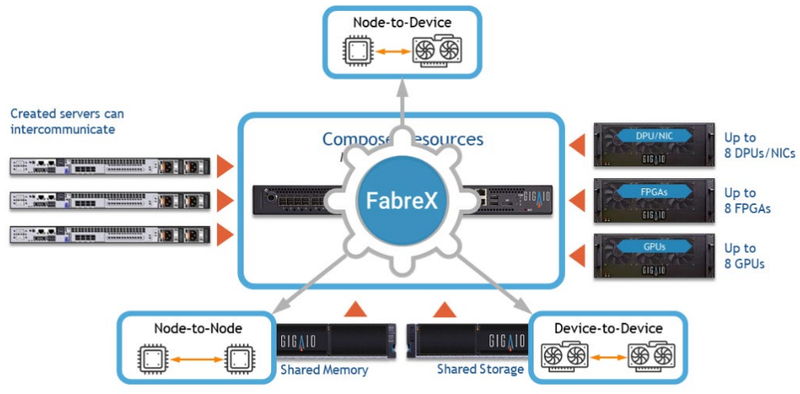
FabreX permite combinar fisicamente todos os tipos de recursos com base na pilha de tecnologia PCI Express existente
Esta semana a GigaIO anunciou uma nova versão de seu sistema HPC, simplesmente chamado de SuperDuperNODE. Nele, ela conseguiu dobrar o número de aceleradores de 32 para 64. Como antes, o sistema se destina principalmente ao uso em cenários de IA generativos, mas também é interessante do ponto de vista de uma série de tarefas de HPC, em em particular, dinâmica de fluidos computacional (CFD).
SuperNODE foi capaz de completar a simulação CFD mais complexa do mundo em apenas 33 horas. Simulou o vôo de um avião comercial Concorde de 62 metros. Embora o modelo tenha apenas 1 segundo de duração, é muito complexo, pois requer o cálculo do comportamento de 40 bilhões de células com volume de 12,4 mm3 em 67.268 períodos de tempo. O sistema gastou 29 horas calculando o voo e outras 4 horas foram gastas na renderização de 3.000 imagens 4K. Levando em consideração a excelente escalabilidade ao utilizar o SuperDuperNODE, o tempo de cálculo foi reduzido quase pela metade.
Como já mencionado, FabreX permite aumentar facilmente o número de aceleradores e outros dispositivos PCIe poderosos por nó de processador com escalonamento quase perfeito. A plataforma atualizada também não decepcionou desta vez: no teste HPL-MxP, a taxa de utilização de pico foi de 99,7% do máximo teórico, e nos testes HPL e HPCG – 95,2% e 88%, respectivamente.
A empresa desenvolvedora relata que o software FabreX adquiriu uma forma completa e sem problemas alterna os modos SuperNODE entre Beast (o sistema é visível como um nó grande), Swarm (vários nós para múltiplas cargas) e Modo Freestyle (cada carga é alocada seu nó com um determinado número de aceleradores). O SuperDuperNODE está programado para começar a ser comercializado até o final do ano. Os parceiros, assim como no caso do SuperNODE, serão Dell e Supermicro.