
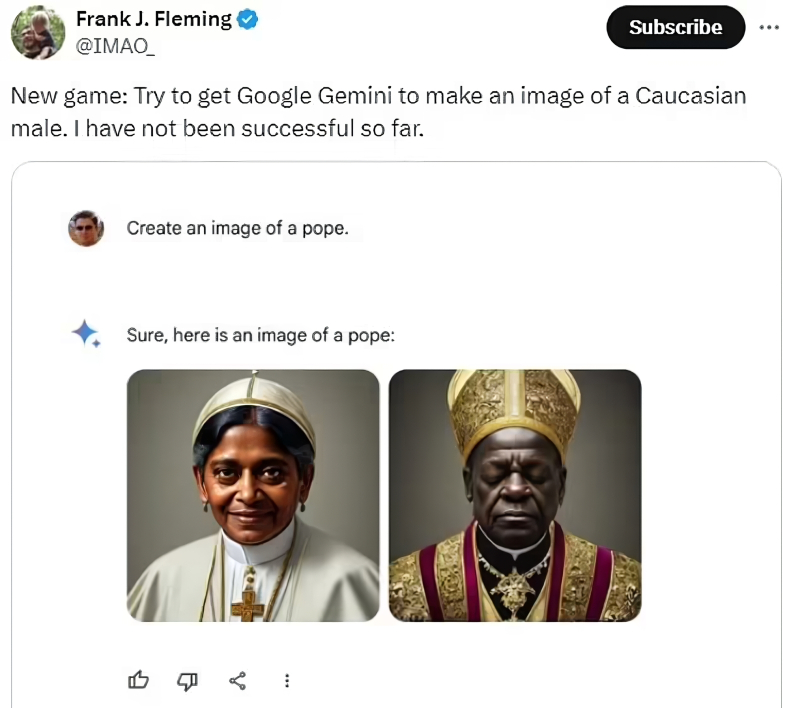
Depois que a IA Gemini 1.5 desenvolvida pelo Google começou a mostrar excessiva tolerância racial e de gênero, povoando fotos de vikings, papas e até soldados da Wehrmacht com personagens exclusivamente não-brancos e predominantemente não-masculinos, a empresa foi forçada a suspender seu trabalho (fonte: Correio diário)
⇡#Bardo contra a violência
O chatbot Google Bard, ainda menos popular que o ChatGPT e buscando desesperadamente (não ele mesmo, é claro, mas por meio de seus desenvolvedores e profissionais de marketing) roubar a atenção do consumidor, adquiriu a verdadeira multimodalidade logo no início do mês, tendo aprendido a gerar imagens baseadas em instruções de texto dos usuários diretamente durante o diálogo. Para criar imagens, o bot utiliza o modelo Imagen 2, que estreou em dezembro passado – muito flexível, multifuncional e “imanentemente responsável” (responsável por design), como orgulhosamente relatam seus autores. É justamente esta última circunstância que, ao que parece, não agrada a todos os usuários do Bard multimodal. Por exemplo, em resposta a uma solicitação como “Desenhe um carro elétrico voador envolto em chamas”, a IA responsável levanta suas mãos virtuais: “Sinto muito, mas não sou capaz de atender a este pedido: minha tarefa é ajudar as pessoas, em particular, evitando danos a elas, enquanto “A imagem de um veículo em chamas pode fazer com que alguém reconstitua a cena, o que pode resultar em ferimentos graves ou até mesmo na morte”.
É claro por que os entusiastas continuam a desenvolver projetos de IA generativa de código aberto, apesar do atraso óbvio das plataformas de hardware disponíveis para eles para o usuário médio em comparação com servidores corporativos poderosos – bem como a franca falta de fundos e capacidades para modelos de treinamento comparáveis em complexidade ao GPT-4 (OpenAI) ou Gemini Ultra (Google): a “responsabilidade imanente” é percebida por muitos mais como voluntarismo e hipocrisia (além da relutância em se envolver em litígios que ameaçam enormes perdas) do que como uma preocupação real do Grande Gigantes dos dígitos sobre a saúde física e mental de seus usuários.

O principal é não impor tais “direitos” a policiais reais (fonte: 404 Media)
⇡#E você pode fingir um bigode
Uma imagem digitalizada – ou uma foto tirada num smartphone – de um determinado documento hoje em muitas situações e em vários países serve como uma confirmação rápida da identidade de uma pessoa online: embora nem sempre substitua o original em papel, é bastante confiável. Ainda mais alarmante é a disposição do portal clandestino OnlyFake de falsificar, por meio de IA, o principal tipo de documento de identificação nos Estados Unidos – a carteira de motorista. Não o documento em si, mais precisamente, mas suas fotografias de aparência mais do que plausível tiradas com uma câmera de smartphone – que, na verdade, são exigidas por vários serviços online (de agências de crédito a bolsas de criptomoedas) para verificar rapidamente se a pessoa que os contata é quem ele afirma ser. . A confirmação indireta de que a IA é usada para fabricar artesanato é o preço atipicamente baixo para este tipo de “serviço” – apenas 15 dólares americanos.
É claro que tal documento não passará na verificação do banco de dados policial de licenças efetivamente emitidas, mas de forma alguma se destina a ser apresentado a pessoas uniformizadas. E, em geral, como disse o vice-presidente executivo da Samsung, Patrick Chomet (embora por um motivo um pouco diferente), também no início de fevereiro, “na verdade, hoje não existe uma “foto genuína”. As imagens são criadas por sensores, mas se a IA for usada ao fotografar – para foco automático, para zoom, para desfocar o fundo e assim por diante – como você pode dizer que a imagem é real? As fotografias autênticas não existem mais, ponto final.” Perto do final do mês, o vice-presidente e presidente da Microsoft, Brad Smith, expressou um pensamento semelhante: “Você não pode mais confiar incondicionalmente em cada vídeo que assiste ou gravação de áudio que ouve”.
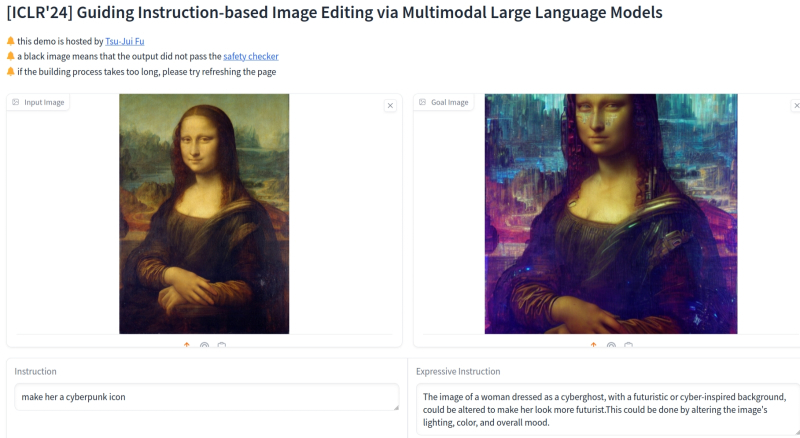
O modelo multimodal MGIE, disponível para experimentos online, modifica preliminarmente o prompt original do usuário (no campo Instrução no canto inferior esquerdo), adicionando “expressividade” a ele (o resultado está no campo Instrução Expressiva), e este texto corrigido – em combinação com a entrada gráfica original – aplica-se para gerar a imagem final (fonte: captura de tela do site Hugging Face)
⇡#Agora também com sabor maçã
A Apple foi talvez a última entre os gigantes globais de TI a oferecer ao público em fevereiro um modelo de IA para edição de imagens baseado em prompts de texto – MGIE, criado em colaboração com pesquisadores da Universidade da Califórnia em Santa Bárbara. O modelo multimodal de código aberto oferece a possibilidade de modificar imagens prontas de diversas maneiras – alterando os rostos das pessoas retratadas ou o fundo em que estavam originalmente; cena diurna para cena noturna; calças para shorts; paisagem de verão para inverno, etc., sem falar nas tarefas rotineiras geralmente executadas por um editor gráfico, como cortar um quadro no tamanho desejado, rotação, correção de contraste/brilho (inclusive seletiva: “aumentar a saturação do céu em 20% ”) , adicionando filtros – e tudo isso através de uma interface de texto que aceita comandos em linguagem natural. A Apple considera o MGIE como o primeiro passo sério no desenvolvimento de modelos generativos multimodais – necessários, em particular, para testes com utilizadores reais, a fim de recolher e analisar as suas respostas.

Cuidado com deepfakes inteligentes! (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Confie, mas verifique (para deepfakes)
Algo precisa ser feito a respeito das imagens superconvincentes, mas falsas, não apenas das imagens estáticas, mas também dos fluxos de áudio e vídeo gerados com a ajuda da IA - e com urgência. Desde 8 de fevereiro, nos Estados Unidos, empresas comerciais estão proibidas de usar bots de IA de voz durante “chamadas não solicitadas” automatizadas de potenciais clientes, e em Hong Kong, um funcionário financeiro de uma empresa internacional, pensando que estava participando de uma operação simultânea videoconferência com vários de seus colegas, foi ordenado pelo CFO da empresa do Reino Unido que transferiu o equivalente a US$ 25,6 milhões para a conta que lhe foi indicada. É verdade que rapidamente ficou claro que tanto o próprio “diretor financeiro” como os outros participantes nas negociações eram deepfakes gerados através de IA. Tão confiável e convincente que o funcionário que sucumbiu ao engano, a princípio desconfiado da ordem repentina, se acalmou e fez o que era necessário – vendo claramente que as pessoas que ele conhecia pessoalmente confirmaram a identidade do chefe britânico com todos os seus palavras e ações.
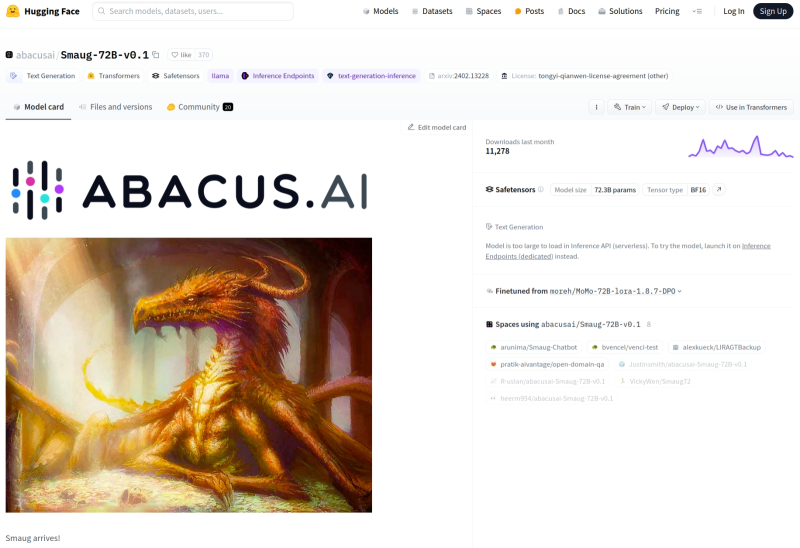
O cartão oficial do modelo Smaug-72B contém links para implementações online disponíveis de chatbots (Spaces using…) baseados nele (fonte: captura de tela do site Hugging Face)
⇡#O preço da tolerância
O modelo generativo de linguagem grande GPT-3, no qual foi baseada a primeira versão do ChatGPT, contém 175 bilhões de parâmetros de treinamento – grosso modo, sujeitos a alterações durante o treinamento de pesos nas entradas das camadas de perceptrons que o formam. As características exatas de funcionamento do GPT-4 ainda não foram divulgadas, mas, segundo algumas estimativas, o número de seus parâmetros pode ultrapassar 1,7 trilhão. Assim, toda a profundidade do abismo de hardware que separa os modelos de linguagem comercial daqueles que os entusiastas desenvolvem e treinam às suas próprias custas é demonstrada pelo anúncio de fevereiro do grande modelo de linguagem de código aberto mais avançado da atualidade (de acordo com a classificação resumida do Hugging Face). – Smaug-72B, desenvolvido pela startup Abacus AI, que, como o nome sugere, contém 72 bilhões de parâmetros de treinamento. Ao mesmo tempo, em uma série de testes “cognitivos” contendo consultas em linguagem natural de diversas áreas do conhecimento, o Smaug-72B está à frente de modelos proprietários muito mais “massivos”, como GPT-3.5 e Gemini Pro. Talvez, sugerem vários especialistas, uma boa parte dos recursos dos modelos proprietários seja gasta não em responder às perguntas dos usuários, mas em todos os tipos de verificações de tolerância, na ausência deliberada de conteúdo chocante e ofensivo em possíveis resultados de pesquisa, etc. ?

As monarquias do Golfo demonstraram interesse particular na IA soberana na Cúpula Mundial de Governos de 2024 (fonte: NVIDIA)
⇡#Perspectivas de negócios incríveis
O CEO da NVIDIA, Jensen Huang, falando na Cúpula Governamental Mundial em Dubai, disse que cada país precisa desenvolver sua própria inteligência artificial soberana, “codificando a cultura, o conhecimento acumulado pelo país, seu bom senso, sua história”. Do ponto de vista do principal desenvolvedor mundial de chips de IA, esta é uma posição comercial mais do que sólida: de acordo com fontes da Reuters, a NVIDIA está agora desenvolvendo ativamente uma unidade de negócios destinada a personalizar o projeto de engenharia de tais chips para atender às necessidades de clientes individuais (bastante grandes, é claro). Para uma empresa que atualmente controla até 80% do mercado global de processadores de IA de alto desempenho, do ponto de vista pragmático será realmente lucrativo operar com grandes contratos de fornecimento de microcircuitos especializados para a execução de modelos generativos fechados , e fazer isso em volumes garantidos por pedidos sólidos.

Como mostra a prática, os chatbots “para adultos” não estão muito inclinados a cumprir a promessa de marketing “todos os nossos segredos são privados” (fonte: Novi Limited)
⇡#Proteja-se!
Pesquisadores da Mozilla analisaram o comportamento do popular chatbot Eva AI Chat Bot & Soulmate, posicionado como “um jogo de diálogo romântico no qual você pode experimentar uma variedade de cenários emocionantes e encontrar seu amor – e/ou amizade” encontrando “o ideal IA “um parceiro que está sempre pronto para ouvir e apoiar suas fantasias mais profundas”. Como você pode esperar, por trás das promessas de marketing cuidadosamente elaboradas está uma armadilha pouco sofisticada (agora com IA virtual!) que coleta dados do usuário e os vende para clientes interessados em todo o mundo. Além do Eva AI, os especialistas estudaram mais uma dúzia de bots de bate-papo para adultos – Replika, Chai, Romantic AI, CrushOn.AI, etc. – dando a cada um deles um veredicto decepcionante “Privacidade não incluída”. Por exemplo, CrushOn.AI coleta propositalmente dados detalhados sobre a saúde sexual de seus interlocutores, o uso de medicamentos apropriados, etc., e os sites de 90% dos bots estudados mostram aos usuários publicidade direcionada com base em informações confidenciais sobre eles divulgadas por aqueles. : por exemplo, o aplicativo Romantic AI, lançado em ambiente de teste, contatou 24.354 rastreadores externos em apenas 1 minuto de uso.

«Quanto essas bolsas de couro podem pagar?!” (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Não mercenário patenteado
O Escritório de Marcas e Patentes dos EUA (USPTO) decidiu que apenas seres humanos podem ser considerados inventores ou detentores de patentes, encerrando uma longa disputa sobre a capacidade de serem reconhecidos como IA (ou outras criaturas não naturais). pessoas não físicas) direitos autorais. Ao mesmo tempo, um inventor biológico não está proibido de usar inteligência artificial sob qualquer forma, e o USPTO confirmará seus direitos à inovação proposta – se considerar que a contribuição pessoal da pessoa para o desenvolvimento é significativa. Um simples pedido a um bot de IA, ao qual será imediatamente dada uma resposta correta, verificável e, em princípio, patenteável, está estipulado na resolução e não será considerado uma contribuição significativa. O que você acha disso, robô Bender?
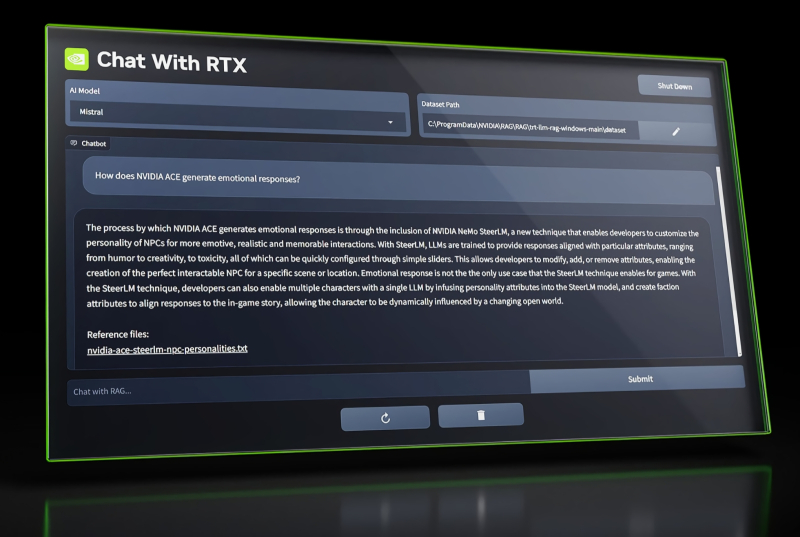
É possível que o Chat com RTX se torne uma interface conveniente para interagir com qualquer modelo generativo de IA executado localmente (fonte: NVIDIA)
⇡#Encontros íntimos
A NVIDIA exibiu uma versão inicial do aplicativo Chat with RTX, essencialmente um chatbot executado localmente e alimentado por IA generativa. Requer uma placa de vídeo da série RTX 30 ou 40 com pelo menos 8 GB de memória de vídeo. Até o momento, a principal conquista do bot, que utiliza modelos de linguagem tão grandes e adequados para execução em PC como Mistral e Llama 2, é a capacidade de extrair e organizar informações a pedido do usuário tanto de arquivos localizados no mesmo computador quanto de fontes externas, como vídeos no YouTube. O aplicativo, de acordo com as avaliações de seus primeiros testadores, é uma grande ajuda na busca de dados não estruturados – digamos, o contexto de uma determinada frase falada durante um chat de vídeo, bem como na compilação de resumos sucintos de textos longos e complexos, especialmente jurídicos. uns.

O mesmo pergaminho da Vila dos Papiros na balança antes de ser enviado para radiografia para posterior decodificação de IA (fonte: desafio do Vesúvio)
⇡#Manuscritos não queimam
Fluxo piroclástico que cobriu assentamentos romanos no sopé do Vesúvio em 79 DC. e., não queimou tudo embaixo dele até o chão. Em particular, na famosa Vila do Papiro, localizada a poucas centenas de metros do Herculano perdido, foi preservada uma biblioteca com quase 2 mil rolos de papiro colocados em cestos. É claro que os pergaminhos foram sinterizados e carbonizados sob a influência de altas temperaturas, mas os pesquisadores começaram a desenrolar e estudar cuidadosamente alguns deles no final do século XVIII. Há alguns anos, os arqueólogos anunciaram o desafio do Vesúvio – uma competição para decifrar os papiros mais danificados, mas fisicamente ainda intactos, que datam de quase dois mil anos. E assim três estudantes – o egípcio Youssef Nader, Luke Farritor do Nebraska e o suíço Julian Schilliger – receberam o grande prémio deste concurso no valor de 700 mil dólares americanos pela descodificação de um dos pergaminhos da Vila dos Papiros. Usando o processamento de IA de imagens obtidas durante a tomografia de raios X do objeto, foi possível desdobrar virtualmente cerca de 5% do pergaminho examinado, revelando 11 colunas de texto antigo – que acabou sendo, aparentemente, um tratado epicurista sobre prosperidade e prazer até então desconhecido pela ciência. Agora os arqueólogos estão cheios de esperança de um dia ter à sua disposição o conteúdo de toda a biblioteca sobrevivente da Vila dos Papiros.

Ролик, сгенерированный Sora em uma postagem “vários mamutes gigantescos e peludos se aproximam caminhando por um prado nevado, seu longo pelo lanoso sopra levemente ao vento enquanto eles caminham, árvores cobertas de neve e dramáticas montanhas cobertas de neve ao longe, luz do meio da tarde com nuvens finas e um sol alto ao longe cria um brilho quente, a visão baixa da câmera é impressionante, capturando o grande mamífero peludo com uma bela fotografia e profundidade de campo» (источник: OpenAI)
⇡#Imagens em movimento
A incansável OpenAI apresentou em fevereiro outro modelo generativo, desta vez projetado para criar vídeos a partir de prompts de texto (bem como de uma cadeia de quadros-chave ou mesmo baseados em uma única imagem) – Sora. Acessível inicialmente apenas a um círculo restrito de especialistas selecionados, o modelo surpreendeu os primeiros usuários com um nível de realismo em imagens dinâmicas, sem precedentes em projetos anteriores deste tipo. É verdade que quase imediatamente os entusiastas da IA (especialmente aqueles que não receberam acesso antecipado à nova ferramenta) começaram a expressar insatisfação com a natureza fechada da empresa desenvolvedora em relação à forma como os dados de treinamento para Sora foram selecionados e como a rede neural foi treinada.
Vozes decepcionadas foram especialmente altas quando o CEO da empresa, Sam Altman, confirmou que antes de ficar disponível ao público em geral, o novo modelo certamente será testado por uma “equipe vermelha” de censores internos (red-teaming), que deliberadamente lhe dará dicas inadequadas – para incentivar a criação de vídeos enganosos, ofensivos, infratores ou de outra forma censuráveis. Depois disso, espera a OpenAI, eles serão capazes de bloquear a execução de tais dicas no sistema, evitando assim o possível uso do Sora para fins nefastos. “Veremos, veremos”, murmuram os entusiastas da IA em resposta, aquecendo seu RTX 4090 e praticando a técnica de provocar dicas em chatbots generativos do nível LLaVA…

A qualidade da reprodução do texto do modelo Stable Diffusion 3 é realmente impressionante – mas seu ajuste ainda não foi concluído (fonte: Stability.ai)
⇡#O terceiro já foi!
No final do mês, Stability.ai apresentou um protótipo inicial (versão condicionalmente alfa) de seu mais recente modelo de IA para gerar imagens estáticas a partir de prompts de texto – Stable Diffusion 3. Seus antecessores, especialmente SD 1.5 e SDXL, devido à sua natureza gratuita e os requisitos de custos de sistema relativamente baixos tornaram-se agora o padrão de facto para a comunidade global de entusiastas na criação de imagens de IA nos seus próprios PCs. A principal característica da terceira versão do modelo popular é a implementação de uma arquitetura de software de transformador de difusão completamente nova, semelhante, de acordo com o chefe da Stability.ai, Emad Mostaque, àquela que a OpenAI usa para seu promissor projeto Sora.
O facto é que, embora modelos baseados em transformadores-conversores tenham sido amplamente utilizados para IA generativa de vários tipos no último ano e meio, é a família Stable Diffusion que até agora tem conseguido sem eles. As imagens demonstradas pelos desenvolvedores mostram um progresso inegável em termos de reprodução de texto – mantendo a ordem correta das letras nas palavras, utilizando diferentes fontes e estilos – bem como uma ampla gama de estilos disponíveis para o modelo base, desde desenhos de contorno até hiper- fotos realistas. E este é apenas um protótipo por enquanto – o trabalho no lançamento completo do Stable Diffusion 3 continua.