
Segundo a definição do Dicionário Filosófico, o intelecto é a capacidade de pensar, ou seja, a totalidade daquelas funções mentais – incluindo a comparação, a geração de abstrações, a formação de conceitos, julgamentos, conclusões, etc. (em outras palavras, fixação indiscriminada do fluxo de informações recebidas) em conhecimento (uma compreensão estruturada dos meandros de um objeto, processo ou fenômeno que tem potencial para ação prática). Neste sentido, a IA generativa – e, de facto, os modelos de aprendizagem automática em geral – claramente não possui qualquer inteligência. Uma máquina treinada para reconhecer imagens de gatos com precisão de 99,999% não é capaz de formular o que é um “gato” em sua representação, ou seja, reduzir os critérios para esse mesmo reconhecimento por ela desenvolvidos a uma forma obviamente compreensível por um operador biológico. Que significa
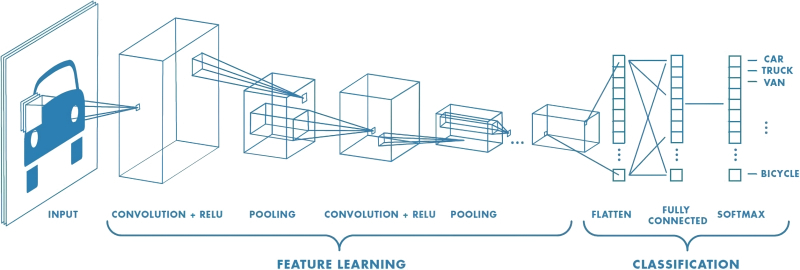
O esquema geral de operação de uma rede neural que reconhece (classifica) objetos em imagens: aprendizado de recursos – uma seção com sub-redes convolucionais (fonte: Saturn Cloud)
Mas a intuição, segundo o mesmo dicionário, é uma experiência ou insight inspirado adquirido diretamente. Isto é, realizado não através da reflexão introspectiva (reflexão), sem a qual o trabalho do intelecto é inimaginável, mas através de uma apreensão implícita, explicitamente inconsciente e não interpretável (quem disse: “Extração do espaço latente”?) De uma certa essência . Aqui está, a decodificação correta da segunda letra da sigla “AI” – “intuição”! Um sistema bem treinado simplesmente pega e combina uma entidade digitalizada com outra. O pedido “escreva um trabalho de conclusão de curso para mim” é um texto convincentemente dobrável que atende adequadamente à definição de “trabalho de conclusão de curso”; a dica “castelo abandonado em uma rocha sombria” – uma imagem imbuída do clima esperado, etc. até que ponto as conclusões tiradas no texto correspondem à realidade, ou a que época histórica ou universo de fantasia pode pertencer a estrutura reproduzida na imagem (se isso não estiver explicitamente indicado na dica). Intuição em sua forma mais pura.
Está relacionado à intuição humana (e ao animal, aliás, também – ao contrário de um intelecto desenvolvido, esta não é de forma alguma uma característica específica do Homo sapiens) o trabalho da IA generativa e o próprio princípio de funcionamento de um neural digital rede. Os sinais passam por um feixe denso de múltiplas camadas de neurônios artificiais (perceptrons), formando resultados intermediários que não podem ser interpretados adequadamente por uma pessoa, mas no final obtemos um texto, ou uma imagem, ou outra saída bastante acessível para compreensão pela mesma pessoa. Além disso, em alguns casos, a IA lida melhor com as tarefas de reconhecimento de certos objetos (em imagens do espaço, por exemplo) do que os operadores vivos que o fazem há anos – simplesmente porque não está sujeita à fadiga, à distração minuciosa e outros fatores que afetam uma pessoa.
⇡#Descartando o não essencial
Como primeira aproximação, já descrevemos o dispositivo e o princípio de funcionamento das redes neurais computacionais: esperemos que um leitor atento e memorizado já tenha uma ideia de um perceptron e de uma rede neural densa multicamadas de dimensão unitária (com o mesmo número de perceptrons em cada camada). E será útil, justamente como base, para entendermos o que falaremos a seguir, já que a rede neural convolucional (CNN) tem dimensão variável: nem todas as suas camadas são iguais. É precisamente por isso que consegue, como em breve ficará claro, resolver de forma mais eficaz as tarefas práticas que lhe são atribuídas, em comparação com a tarefa unitária. Na maioria das vezes – reconhecimento de padrões em imagens e vídeos estáticos,
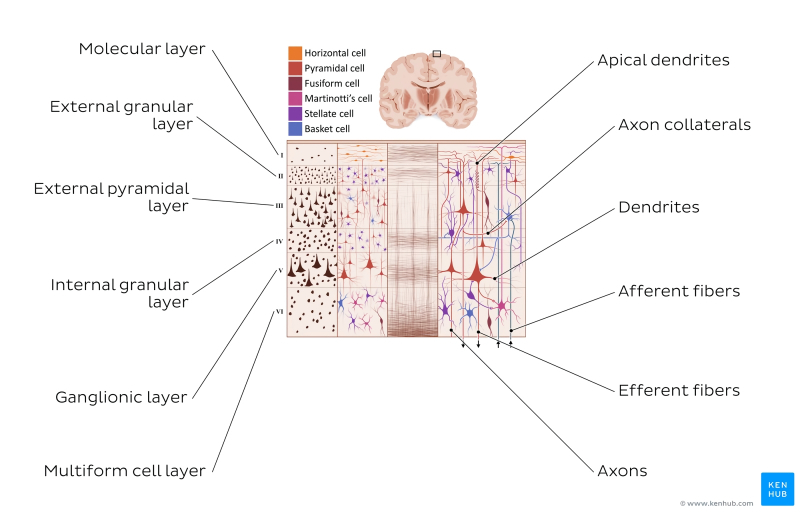
Diferentes camadas e células do córtex cerebral (fonte: Kenhub)
De onde veio a ideia de complicar o projeto de uma rede neural diferenciando suas várias camadas? Comecemos com o fato de que uma estrutura de rede neural natural de referência como o córtex cerebral humano é essencialmente heterogênea. Sem sequer mencionar o fato de possuir zonas que realizam diversas tarefas (reconhecimento de fala, percepção de sensações táteis, etc.), o próprio córtex é geralmente multicamadas, e diferentes partes de suas camadas estão dispostas de forma diferente e contêm diferentes – tanto em tamanho e no número de conexões formadas – células nervosas. Além disso, mesmo dentro do mesmo nível da mesma camada, a atividade de diferentes neurônios pode variar significativamente.
Em particular, o córtex visual, devido ao qual a imagem visual do mundo circundante é formada na mente, é composto por células muito heterogêneas. Cada um dos neurônios visuais possui seu próprio campo receptivo – uma área com receptores que respondem a determinados estímulos. Por exemplo, para as células ganglionares da retina, os receptores são bastonetes e cones familiares no curso escolar de fisiologia humana – células que reagem à força da luz percebida e/ou à sua composição espectral. Por sua vez, um determinado conjunto de células ganglionares funciona como campo receptivo para um neurônio já localizado no córtex visual do cérebro – em sua parte occipital, bem distante da retina. E os critérios para disparar estes neurônios são bastante seletivos: por exemplo,
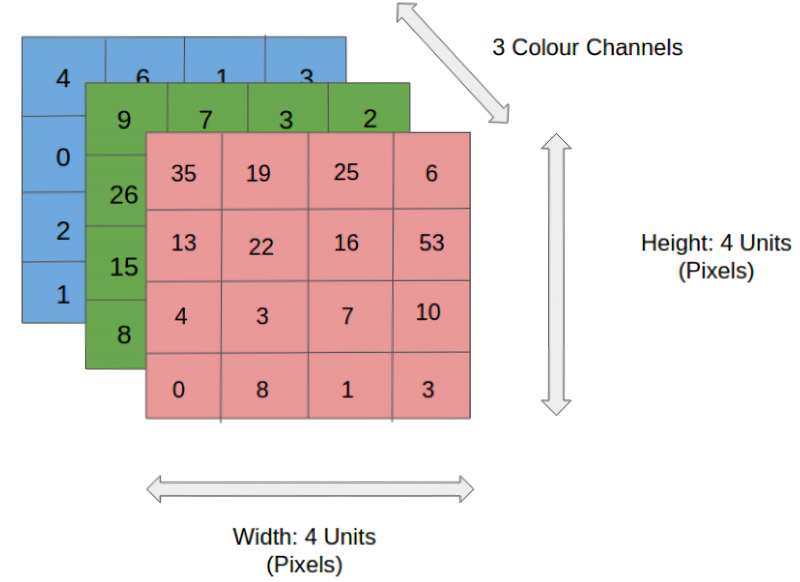
Codificação de imagem colorida 4 × 4 × 3 – com quadratura de 4×4 pixels e configuração de três canais de cores (fonte: Saturn Cloud)
Além da consideração óbvia “uma vez que a evolução escolhe redes neurais com redução de dimensionalidade em camadas subsequentes para processamento de dados visuais, esta pode vir a ser a mais eficiente”, há outra justificativa para preferir CNNs a redes de máquinas de dimensão unitária, nada menos convincente: técnico e económico. Suponha que uma determinada imagem quadrada colorida possa ser codificada com apenas 16 pixels na primeira aproximação aproximada, em uma grade 4 × 4, grandes pontos multicoloridos são transformados pela adição gradual do “ruído” necessário nos lugares certos em uma imagem identificável por humanos ). A propósito, não se esqueça que para salvar as informações de cores será necessário formar já três matrizes 4 × 4 – para canais vermelho, verde e azul. Assim, um registro de dados, mesmo sobre uma imagem tão codificada, será representado não por 16, mas por 48 números (codificação 4 × 4 × 3, onde os dois primeiros valores correspondem à dimensão da imagem, e o último indica o número de canais de cores: se você escolher a codificação CMYK, os últimos já serão 4).
Sim, tecnicamente não é nada difícil converter esses 48 números de um formato matricial para um formato vetorial (de várias tabelas em uma única coluna) e alimentar a sequência de dados resultante para a entrada de uma rede neural unitária totalmente conectada com retropropagação de erros – deixe-o procurar padrões ali. Mas com o aumento das dimensões da imagem original, a tarefa torna-se cada vez menos difícil. Para codificar papéis de parede de desktop em Full HD, você precisará de 1920 × 1080 × 3 ≈ 6,22 milhões de números – e é por isso que, aliás, o formato BMP (imagens nas quais foram salvas de maneira antieconômica aproximadamente semelhante) praticamente caiu em desuso agora: também os arquivos apresentados nesta forma tornam-se impraticavelmente pesados. Agora está claro que uma rede neural para processamento de imagens de alta resolução – seja a classificação de objetos nelas ou, inversamente, criação de imagens com base em instruções de texto – precisa ser reduzida em tamanho; por razões de pelo menos uma suficiência razoável do poder de computação gasto em sua operação. Mas como exatamente essa redução será feita?
⇡#Só não em um tubo!
Na verdade, a “convolução” no nome da CNN apenas indica o método utilizado para reduzir a dimensão das camadas da rede neural e é simplesmente chamada de convolução. É intuitivamente claro que “colapsar” na aplicação aos dados não significa apenas “reduzir” (então seria mais lógico dizer “cortar” ou “arredondar”), mas “compactar com a preservação da informação mais importante”. ” E é assim que a CNN faz.
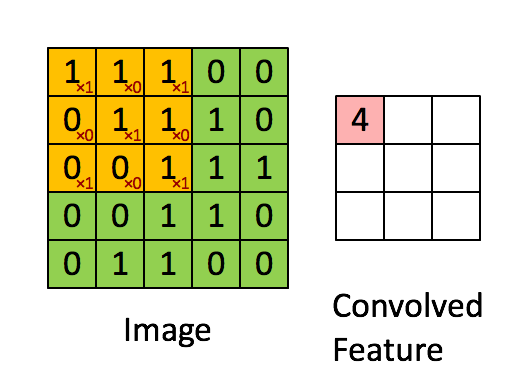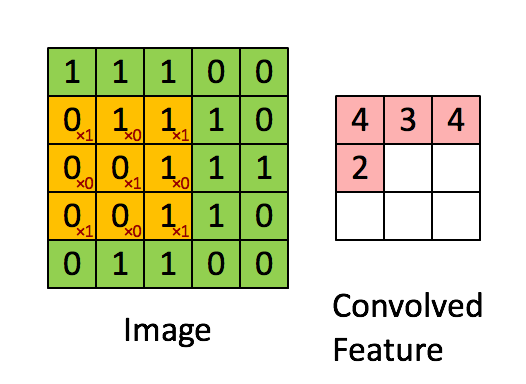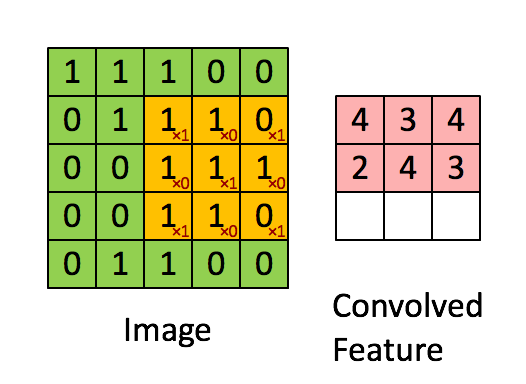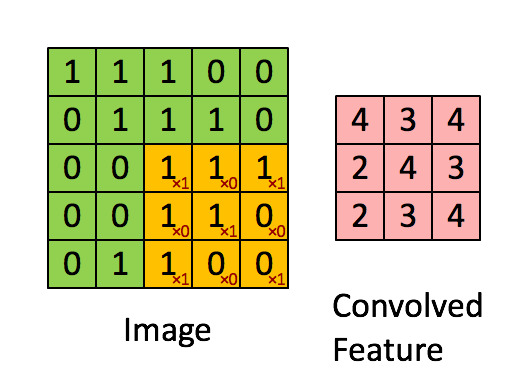
Aplicando sequencialmente a operação de convolução a uma das camadas da imagem digitalizada original (fonte: Saturn Cloud)
Que haja uma matriz inicial de valores – digamos pixels de alguma imagem – de alta dimensão. No nosso exemplo – 5 × 5 (mais precisamente, 5 × 5 × 1 – não esqueçamos que cada posição pode corresponder não apenas a um número, mas a um vetor que codifica algumas informações adicionais). Para a operação de convolução, utiliza-se o chamado kernel ou filtro (kernel/filtro) – uma pequena matriz de pesos, geralmente representada por números inteiros. Assim como os pesos nas entradas dos perceptrons, os componentes de peso que compõem o kernel podem (e devem, no caso geral!) ser corrigidos durante a operação da rede neural usando o método de retropropagação, mas por enquanto, para maior certeza, assumimos que o kernel é uma matriz fixa 3 × 3 da seguinte forma:
1 0 1
0 1 0
1 0 1
A reviravolta em si é:
- Impondo o kernel sequencialmente na matriz original, começando no canto superior esquerdo,
- Multiplicando os números nas células correspondentes, somando os resultados obtidos –
- E escrever a soma em uma célula da matriz de saída, que já terá uma dimensão obviamente menor que a original.
Um quadrado 3 × 3 permite mover-se ao longo de uma matriz 5 × 5 com deslocamento de uma posição (sem ultrapassar seus limites) exatamente três vezes tanto na horizontal quanto na vertical – portanto, neste exemplo, a matriz de saída terá uma dimensão de 3 × 3. Se, para o mesmo kernel (3 × 3), a matriz original fosse 7 × 7, a saída já teria recebido uma dimensão de 5 × 5.

O filtro Sobel clássico envolve a imagem original ao longo de uma das dimensões, destacando claramente as bordas das estruturas alongadas na mesma dimensão (fonte: TowardsDataScience)
Hoje, quase todos os que têm à mão, nomeadamente num simples editor de fotos pré-instalado em quase todos os smartphones, possuem um filtro de convolução analógico Sobel – uma ferramenta para realçar os limites dos objetos numa imagem. Em particular, o filtro Sobel horizontal é a matriz
+1 0 –1
+2 0 –2
+1 0 –1
Ao multiplicar a imagem original (em formato digitalizado, é claro), na qual os detalhes de baixo contraste desaparecem e as bordas nítidas são ainda mais realçadas. A razão é que no decorrer de tal operação, pixels vizinhos – células da matriz original – com valores aproximadamente iguais (neste caso, brilho) após convolução com a matriz do filtro fornecem valores próximos de zero na saída , e se os valores vizinhos nas células diferirem muito, como resultado, essa diferença será significativamente aumentada.
Na verdade, este é o propósito da convolução: não apenas reduzir a dimensão da matriz original para reduzir a carga computacional no hardware do sistema, mas identificar certos padrões na matriz de dados original, além disso, em diferentes canais ( ou seja, em cada estágio, a convolução não é realizada com um, mas com vários filtros, e então esses fluxos de dados – canais – são processados separadamente). A próxima operação de convolução transforma a matriz de dados de entrada em uma unidade linear limpa (unidade linear retificada, ReLU), que é um mapa aprimorado (descartando tudo de pouco significado; daí o termo “limpo”) das características distintivas desta matriz, em que a cada iteração mais e mais conexões não lineares entre seus componentes aparecem com mais clareza.
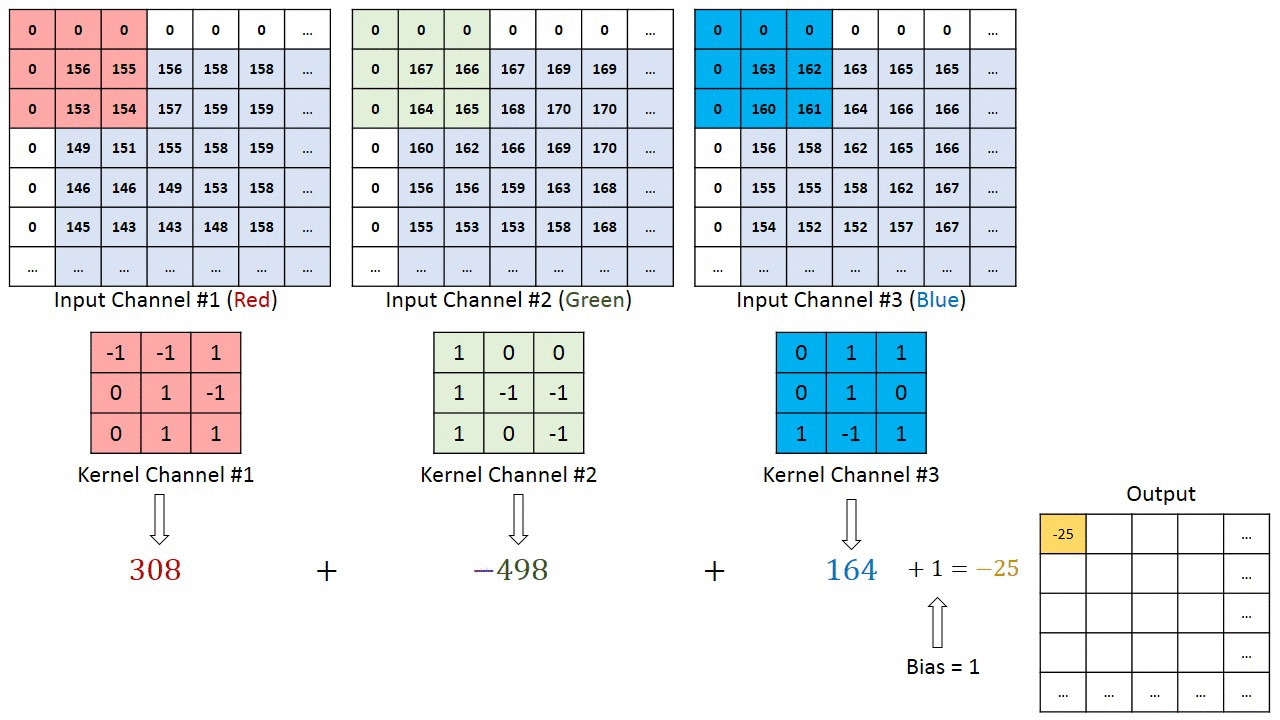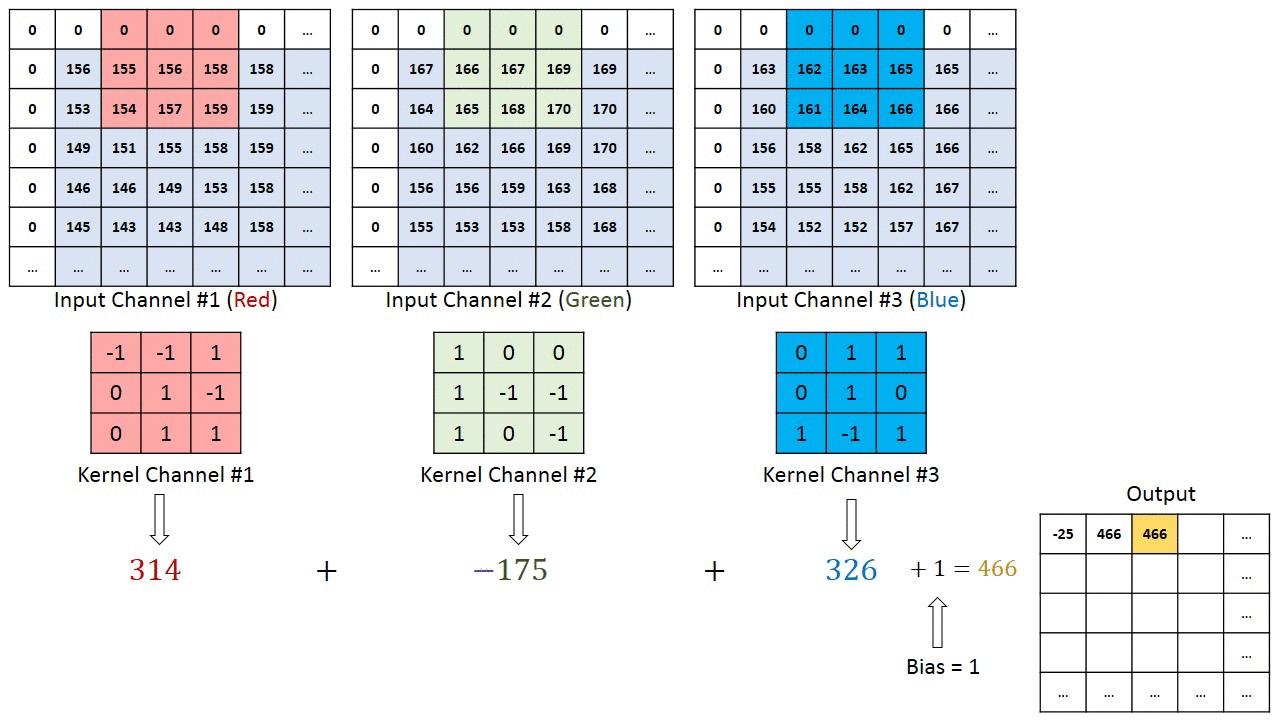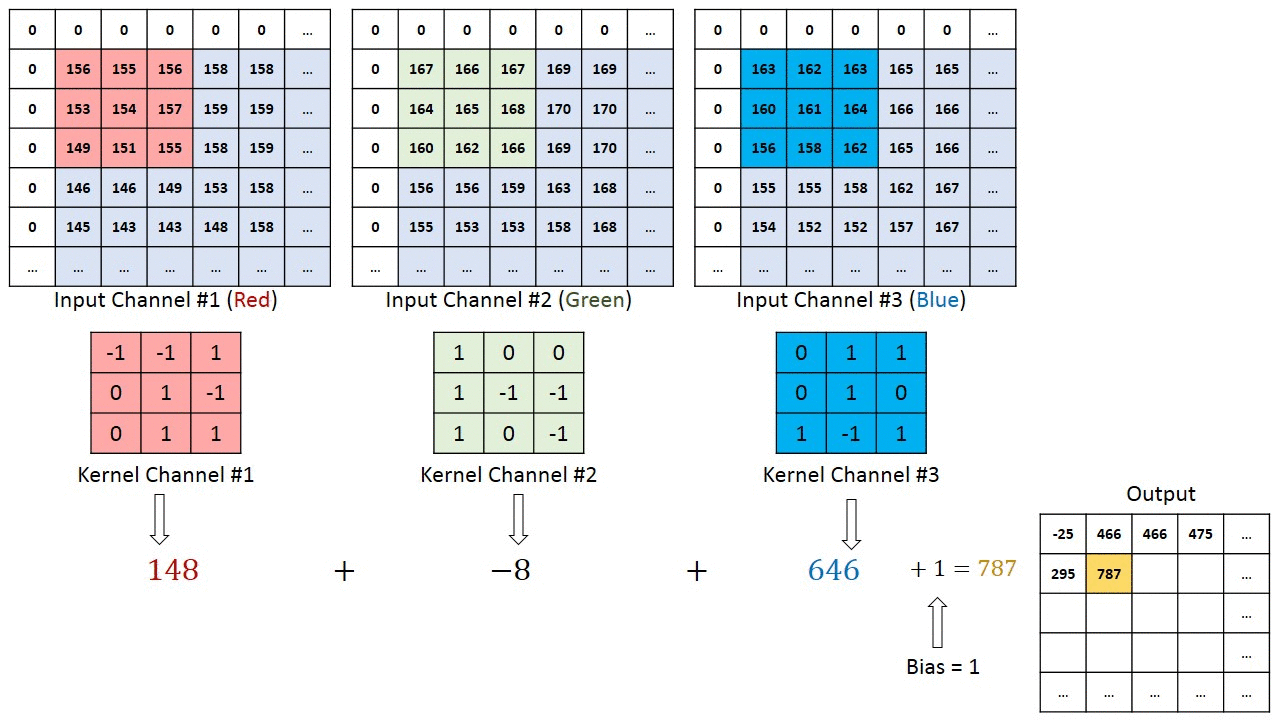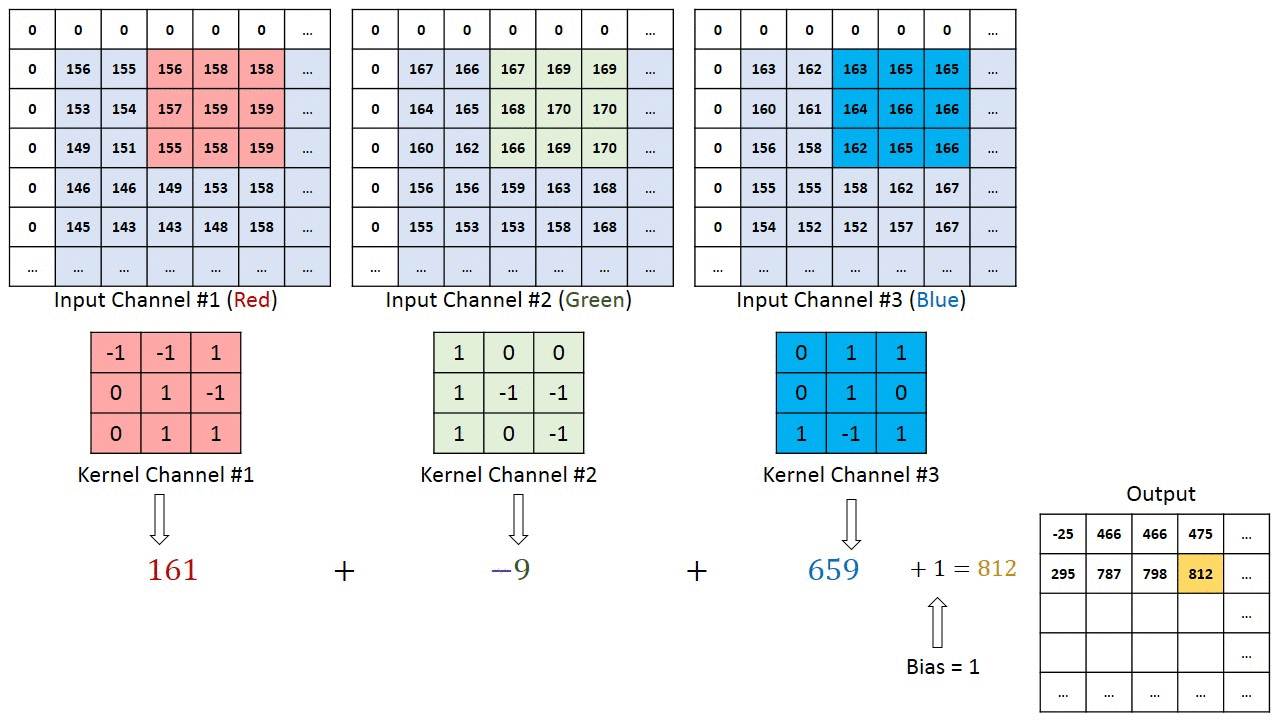
Se a imagem original for digitalizada com uma matriz M × N × 3 de três canais, a convolução correta pode exigir filtros diferentes para cada um dos canais de codificação de cores (fonte: Saturn Cloud)
No entanto, não devemos esquecer que só faz sentido interpretar os resultados da convolução de qualquer forma explícita (compreensível para a consciência humana) quando esta operação é aplicada à primeira matriz de dados – no exemplo em consideração, a uma imagem digitalizada e pixelada imagem. As redes neurais modernas são essencialmente multicamadas, e quando a operação de convolução é realizada para uma das camadas profundas (ocultas) do modelo, e mesmo com a utilização de um filtro com pesos ajustados no processo de retropropagação do erro, ela já é essencialmente impossível fixar o conteúdo semântico dos valores obtidos como resultado desta operação. Esta, aliás, é a base da proposta de comparar o trabalho da IA com a intuição e a intuição, e não com as operações estritamente lógicas da inteligência natural.
Além da convolução descendente e de um deslocamento unitário do filtro na matriz original, outras operações são aplicadas, como um deslocamento de salto do kernel em 2 células (nesse caso, pode ser necessário preencher a matriz original com linhas e /ou colunas com valores zero para respeitar a dimensão) e até “inchaço” é uma espécie de dobramento inverso, cuja saída é uma matriz de dimensão maior. A aritmética da convolução é uma disciplina essencial para o campo do aprendizado de máquina profundo, mas seria redundante aprofundá-la no âmbito de um artigo de revisão.
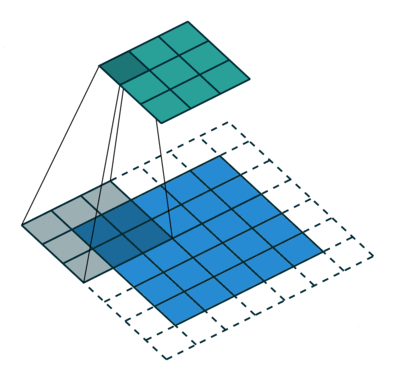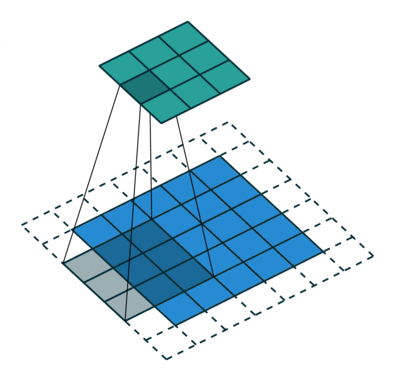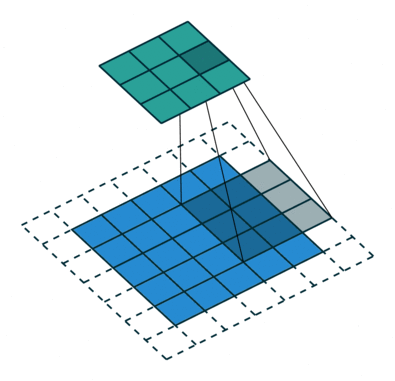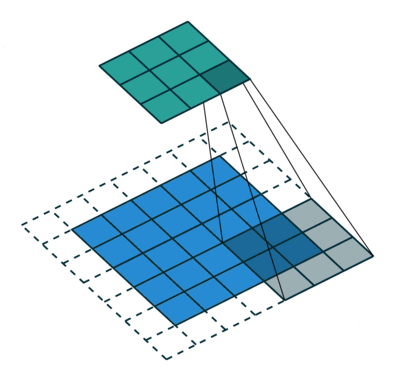
Se a imagem original for digitalizada com uma matriz M × N × 3 de três canais, a convolução correta pode exigir filtros diferentes para cada um dos canais de codificação de cores (fonte: Saturn Cloud)
Como as próprias camadas convolucionais são organizadas uma após a outra sequencialmente (organizadas por camadas de agrupamento, que serão discutidas abaixo), isso permite identificar padrões ocultos na matriz de dados original de um nível cada vez mais alto – desde a detecção de um par de horizontais e um par de segmentos verticais, passe a identificar o que é mostrado no quadrado da imagem, por exemplo. Grosso modo, um princípio semelhante está subjacente ao processo de difusão estável, graças ao qual a rede neural é primeiro treinada para associar o termo “quadrado” (mais precisamente, o conjunto de tokens que o codifica) a pesos bem definidos em matrizes de convolução, e então o processo é invertido – de modo que da miscelânea inicial de manchas multicoloridas, de acordo com a dica apropriada, surge uma figura completamente geometricamente correta em várias iterações.
Após a convolução, as camadas individuais no modelo de IA são submetidas a uma operação ligeiramente diferente, embora em muitos aspectos semelhante – agrupamento ou agrupamento. Em vez de, como no caso da convolução, multiplicar elemento por elemento um fragmento da matriz original pelos pesos do filtro e depois somar o resultado, ao agrupar, uma determinada função estatística é calculada para um fragmento do original matriz coberta pelo núcleo do filtro. Esta função geralmente acaba sendo um simples “valor máximo”: se uma amostra 3 × 3 selecionou tal fragmento da matriz –
3 3 2
0 0 1
3 1 2
— Então o “valor máximo” para os elementos tomados desta forma neste caso será “3” (e se pelo menos uma célula tivesse quatro, então seria “4”). Você também pode usar uma função que consome mais recursos – calcular a média. A essência do procedimento de agrupamento é, em primeiro lugar, reduzir a dimensão da matriz (o que novamente alivia a carga no hardware do sistema de IA) e, em segundo lugar, identificar características invariantes do objeto representado pela matriz original mais eficientemente do que a convolução. Grosso modo, se uma janela retangular for mostrada em uma imagem digitalizada em perspectiva, e até mesmo filmada em um ângulo (plano de ângulo holandês), para identificar tal objeto por uma rede neural como uma janela de algumas camadas convolucionais, em geral, levará mais tempo do que se você combiná-los com agrupamentos.
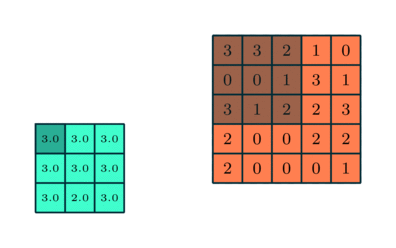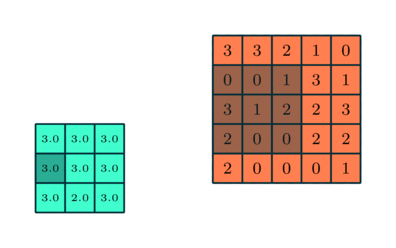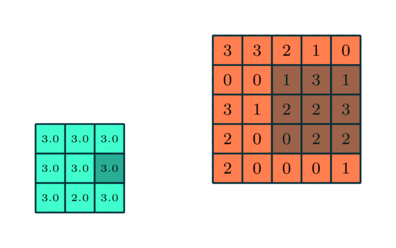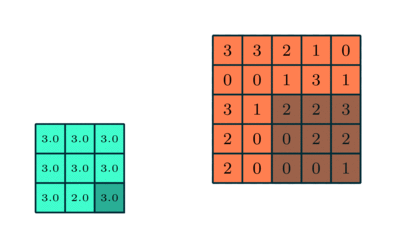
Operação de agrupamento com seleção do valor máximo em cada um dos fragmentos da matriz original, coberto na próxima etapa pelo filtro (fonte: Saturn Cloud)
Normalmente, em sistemas de aprendizado de máquina focados no reconhecimento de padrões, as camadas convolucionais e de agrupamento em cada canal são organizadas em pares, e o número de tais pares pode ser bastante grande. Como resultado, a cada nível de processamento da matriz original (imagem pixelizada), a imagem original gera abstrações de nível cada vez mais alto, descartando detalhes insignificantes – incluindo ruídos, leves gradientes de cores e até sombreamento/sobreposição parcial. Digamos que uma coluna antiga, vista através dos galhos das árvores, acabará sendo classificada graças às circunvoluções – e principalmente aos agrupamentos – precisamente como um único objeto sólido do fundo. Porém, para ver a “imagem de uma coluna antiga” nas células da matriz correspondente nas profundezas da rede neural convolucional, apresentada na forma de uma série de tabelas preenchidas com números,
⇡#O que está aqui?
No exemplo acima com uma rede neural focada no reconhecimento visual de padrões, a própria estrutura dessa rede é dividida em dois grandes blocos: “aprendizado de características” e “classificação” propriamente dita. Além disso, se uma sub-rede multicamadas de pares de camadas convolucionais e de agrupamento funciona na identificação de características, então uma sub-rede multicamadas, mas já unitária e totalmente conectada, em que cada camada é formada pelo mesmo número de perceptrons, também está envolvida na classificação. “Totalmente conectado”, neste caso, significa que as saídas de cada um dos perceptrons da camada anterior transmitem sinais para as entradas de cada um dos neurônios artificiais da próxima.
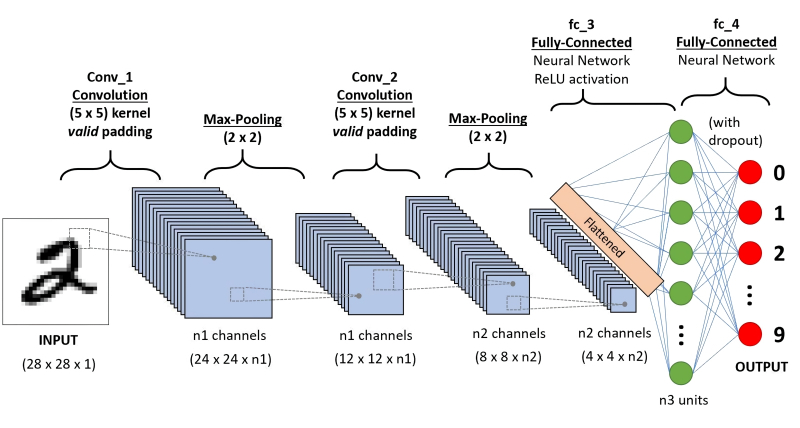
Diagrama esquemático de uma CNN usada para reconhecer dígitos manuscritos: depois de repetir as operações de convolução e amostragem duas vezes em vários canais, a saída é “achatada” de uma matriz para um vetor e passada para a entrada de uma rede neural densa totalmente conectada (fonte: Nuvem de Saturno)
Estritamente falando, uma rede tão totalmente conectada é capaz de se engajar no reconhecimento confiável de padrões – no material anterior sobre este tópico, por exemplo, consideramos o dispositivo de tal rede com retropropagação de erros, envolvida na identificação de um triplo manuscrito. Outra coisa é que, para imagens grandes e altamente detalhadas, o reconhecimento por meio de uma rede unitária totalmente conectada será muito caro – tanto em termos de tempo, quanto de recursos de hardware gastos e consumo de energia. A unidade de detecção de recursos, que executa operações de convolução e agrupamento repetidamente, é necessária precisamente para reduzir significativamente a dimensão da matriz de dados original, preservando ao mesmo tempo todas as informações-chave contidas nela (de uma forma codificada e transformada repetidamente). , claro).
E agora esse conjunto de dados altamente refinado (repetidamente retificado, se lembrarmos do ReLU) é alimentado na entrada de uma rede neural totalmente conectada, que faz um excelente trabalho de classificação de acordo com características significativamente heterogêneas, como demonstramos anteriormente. Além disso, não importa o tamanho do array original: em qualquer caso, uma rede neural totalmente conectada funcionará com um vetor de dados unidimensional e relativamente curto. Acontece que é extremamente simples: digamos que a imagem original foi processada na unidade de detecção de características ao longo de 50 canais, cada um dos quais, na saída de uma série de operações de convolução e agrupamento, produziu uma matriz 3 × 3. Essas matrizes são convertido em vetores (a primeira célula da primeira linha torna-se o primeiro elemento do vetor, a última – a terceira, a primeira da segunda linha – a quarta, etc.),
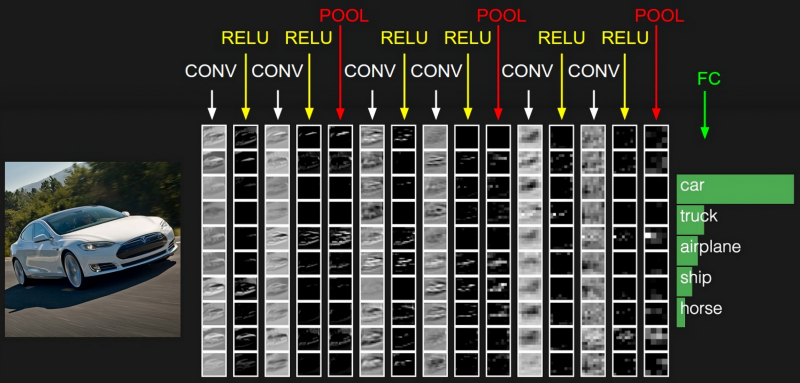
Uma tentativa de compreender exatamente quais padrões a rede neural revela na imagem original, devido à visualização (transformação de matrizes em imagens por pixels) em cada etapa da operação CNN: convolução (CONV), limpeza (RELU), agrupamento (POOL) – e a saída é uma sub-rede de classificação totalmente conectada (totalmente conectado, FC) (fonte: Universidade de Stanford)
As redes convolucionais têm servido bem à causa da visão artificial por muitos anos, uma vez que ferramentas estáticas como o filtro Sobel mencionado anteriormente foram usadas para revelar as características mais importantes das imagens. CNNs com retropropagação de erros para ajuste fino de filtros durante o processo de aprendizagem possibilitaram, em particular, automatizar a detecção de determinados objetos em uma foto/vídeo – e fazer isso em uma base de hardware relativamente modesta, incluindo chips integrados de não as webcams mais caras. Recentemente, porém, eles têm uma aplicação ainda mais impressionante (pelo menos para uma parte significativa do público da Internet): trabalhar como parte de redes adversárias generativas (GANs). Os mesmos que após treinarem em uma vasta gama de dados visuais anotados, eles próprios se tornam capazes de criar imagens de objetos do mundo real ou fantástico – do ponto de vista humano, eles são bastante confiáveis. Bem, ou abstrato/surreal, mas exatamente na medida que o operador que compilou a dica de texto correspondente espera.
De forma mais geral, a modelagem generativa – aliás, não é tão importante o que exatamente: imagens, vídeos, sons ou textos – é definida como o resultado de automação (ou seja, implementada no decorrer do aprendizado de máquina na ausência de um professor, aprendizagem não supervisionada) identificação de certos padrões em uma grande variedade de dados de entrada, seguida pela aplicação do modelo resultante para gerar objetos de natureza semelhante que são tão plausíveis do ponto de vista de um operador humano que poderiam ser incluídos por ele na matriz inicial de informações de treinamento. Parece um tanto uroboros, mas na verdade é assim: o objetivo da modelagem generativa é a geração mecânica de tais entidades (para ser mais específico, imagens) que, aos olhos de uma pessoa, seriam indistinguíveis daquelas criadas por outras pessoas.
Na verdade, uma IA generativa, uma vez treinada para obter um modelo fixo (um certo conjunto de pesos nas entradas de todos os seus perceptrons – o que geralmente é chamado de ponto de verificação no desenho de IA), faz um excelente trabalho ao desenhar imagens por conta própria – em a ausência de supervisão adicional de terceiros – desenhos com base em instruções de texto. : os leitores dos “Workshops” correspondentes podem ser convencidos disso por experiência própria. Mas para treinar tal posto de controle, é necessário treinar com um professor (aprendizagem supervisionada) no âmbito da rede generativa-adversária mencionada acima. Implica uma articulação ativa – e além disso, também competitiva! – o trabalho de dois modelos de IA, atuando respectivamente nas funções de criador (gerador) e crítico (discriminador).
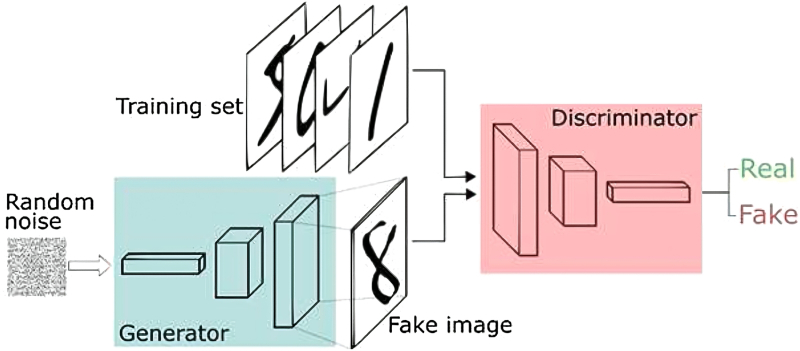
A estrutura de um GAN típico: o ruído branco é alimentado na entrada de um gerador pré-treinado, com base no qual é criada uma imagem “falsa” (não incluída no conjunto de dados de treinamento), e o discriminador, analisando o mesmo conjunto de origem (mas não por enumeração direta, mas também como uma rede neural), decide se lhe foi oferecida uma imagem falsa ou não (fonte: Journal of Real-Time Image Processing)
O gerador é treinado para criar novas imagens com base no processamento da matriz de dados original; o discriminador tenta reconhecer se a próxima imagem recebida pelo gerador pertence ao pool de treinamento – ou é notavelmente diferente dele. O final do treinamento costuma ser considerado o momento em que o crítico passa a considerar a priori mais da metade das imagens incluídas no conjunto original daquelas que o criador cria. Ou seja, neste caso, a “aprendizagem supervisionada” não envolve a participação de um operador ao vivo, mas de outro modelo de IA, cuja tarefa é verificar se o gerador consegue criar imagens enganosamente verossímeis. Ou frases sintetizadas para voz humana, ou textos fingindo ser de autoria, enfim, tudo que pode ser digitalizado para formar um pool de dados primário (de treinamento). Importante,
Portanto, uma das abordagens mais comuns na construção de uma GAN tornou-se a arquitetura de redes adversárias generativas convolucionais profundas (DCGAN). Sua vantagem é que o DCGAN reduz significativamente a probabilidade de colapso do modo (colapso do modo) em uma situação em que a propagação da variabilidade da saída do gerador é muito mais estreita do que a largura dos dados originais definidos por algum parâmetro. Este é um tipo de análogo do overtraining do modelo perceptron, que foi discutido em um de nossos materiais anteriores: se, em resposta ao prompt de texto “cachorro”, o posto de controle, que foi conscientemente alimentado durante o processo de treinamento com muitas imagens de várias raças, desenha um sharpei com probabilidade de 0,6, e com probabilidade de 0,4 – um collie, esta é uma evidência direta do colapso do regime. O problema aqui é
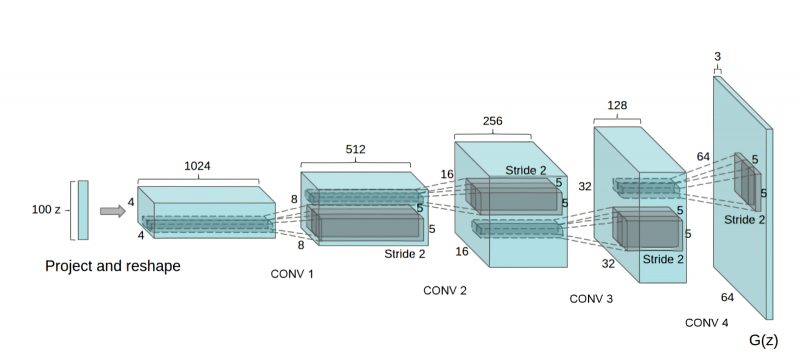
A arquitetura do gerador DCGAN se assemelha a uma CNN retroativa para reconhecimento de padrões (Fonte: GeeksForGeeks)
A essência da arquitetura DCGAN é que as amostras para controle são alimentadas na entrada do discriminador não uma por uma, mas em pequenos grupos, e a estrutura desta rede neural é organizada de tal forma que a cada passo de convolução a dimensão de as matrizes processadas aumentam e o número de canais de processamento paralelo diminui. Em geral, o design do discriminador se assemelha à estrutura da rede neural convolucional mais comum – com uma série de características específicas, como o fato de que a etapa de mudança do filtro (passo convolucional) geralmente é considerada igual a dois em vez da unidade típica para redes de reconhecimento de imagens, o que permite descartar de forma mais eficaz pequenos detalhes e identificar padrões mais gerais na imagem em estudo.
O trabalho de uma rede neural que gera certas entidades perceptíveis pelo homem, na primeira aproximação, se resume a duas operações – codificação e decodificação; compressão de informações e expansão da forma compacta resultante para a imagem final, texto, conjunto de sons, etc. Mas, ao contrário do arquivamento algorítmico (quando a matriz de dados original é reduzida em volume sem perda de informações e depois restaurada), no processo de cortar tudo o que é supérfluo pela rede neural, um espaço de entidade latente (oculto) que retém apenas as informações mais essenciais – e ignora completamente qualquer ruído.

A imagem inicial, passando pela rede neural generativa de imagem de IA, gradualmente parece estar livre de ruído excessivo – de acordo com a descrição do texto (fonte: geração de IA baseada no modelo SDXL 1.0)
Por exemplo, preserva-se o conceito de “cachorro em geral” – mais precisamente, uma compreensão intuitiva da essência deste termo, formada pelo modelo no processo de aprendizagem – e em uma imagem específica de um cão de uma determinada raça em um ou outro ângulo e entourage, é transformado já de forma pseudo-aleatória em processo de decodificação – recuperação utilizando, em particular, uma rede neural convolucional.
Então, se não fossem essas redes, quem sabe hoje poderíamos facilmente extrair do espaço latente tudo o que temos a oportunidade de nos surpreender, alegrar e até mesmo nos ressentir agora?