
Se você se lembrou imediatamente das vitórias de AMD EPYC ou Ryzen no CINEBENCH e decidiu que, dizem, tudo está claro aqui, então não se apresse – trabalhar em efeitos CG e animação na realidade não é tão simples e a presença de muitos núcleos ainda não decide nada. Com o apoio do escritório de representação da AMD em Moscou, o distribuidor do ASBIS e do estúdio CGF, preparamos um material sobre os meandros do trabalho do estúdio e sua experiência de operação experimental dos novos processadores da série AMD EPYC 7002, que o estúdio testou para avaliar a possibilidade de seu uso posterior no parque de servidores.
O estúdio possui centenas de obras – de efeitos especiais para longas-metragens a curtas-metragens, até filmes totalmente animados. No entanto, mesmo as chamadas avarias de efeitos visuais, a partir das quais o espectador aprende o que era real e o que não estava na tela, não refletem totalmente a profundidade e a complexidade de criar até mesmo alguns segundos de vídeo de tirar o fôlego, que na realidade podem levar horas ou mesmo dias. Não será possível contar todas as sutilezas e nuances, já que o estúdio tem seus próprios segredos, mas dá para ter uma ideia geral dos processos.
Um cenário típico para um estúdio trabalhando em efeitos especiais para um filme não é fácil de descrever, já que tudo depende das especificidades de um determinado projeto. No caso geral, a tarefa é processar o material original da filmagem – adicionar objetos que estão ausentes, remover os desnecessários ou corrigir os filmados. O material de vídeo original da filmagem pode ter dezenas de terabytes de dados. Normalmente, este vídeo é armazenado em várias fitas LTO. Junto com o crescimento da capacidade de armazenamento da fita, a qualidade do vídeo, sua resolução e profundidade de cor também estão crescendo, portanto, uma fita LTO-5 de 1,5 TB pode acomodar apenas 5-10 minutos de gravação (sem compressão).
No caso mais difícil, tudo começa com a digitalização física ou modelagem do zero de futuros objetos “artificiais” no quadro, bem como simulação, ou seja, cálculos físicos do comportamento e da interação de tais objetos. Em seguida, ocorre a renderização – a renderização dos objetos modelados. E já no final, a composição ocorre – a combinação de objetos renderizados e renderizados com o vídeo original. É claro que essa descrição formalmente simples esconde dezenas de horas de trabalho de um grande número de especialistas.
Para a modelagem inicial de objetos, estações gráficas são utilizadas, principalmente com o Autodesk Maya. SideFX Houdini é responsável pela simulação, cálculos físicos, renderização e assim por diante. Para a composição, o estúdio usa The Foundry Nuke. Existem plug-ins e módulos adicionais separados para cada software. Ele também tem sua própria caixa de ferramentas local. Cada estágio é dividido em tarefas separadas, unidades de cálculos razoavelmente independentes. Quase todas essas tarefas acabam no farm de renderização.
«O problema com muitos estúdios pequenos para os padrões de Hollywood é o orçamento limitado para a compra de novos farms de servidores e estações de trabalho. E no caso do CGF, o ciclo de atualização de equipamentos, que ainda é bastante caro, pode variar de 4 a mais de 7 anos. Para rentabilidade econômica, qualidade de trabalho e rapidez na execução dos pedidos, o estúdio precisa usar todos os equipamentos disponíveis da forma mais eficiente possível ”, observa Kirill Kochetkov, CTO do estúdio CGF, sob cuja liderança foram realizados os testes de novas plataformas.
Como resultado, o farm de renderização CGF não é completamente unificado, mas consiste em vários tipos de blades e sistemas de servidor antes caros. Em seu tempo livre, estações gráficas individuais de funcionários também são conectadas como nós adicionais da fazenda. E ao escolher um novo hardware, é importante selecionar processadores e plataformas para cargas específicas e manter um equilíbrio, uma vez que as tarefas descritas acima têm requisitos de recursos visivelmente diferentes: single- e multi-threading, núcleo IPC, largura de banda da memória e assim por diante.
Muitas tarefas de simulação consomem muitos recursos – o tempo de contagem de um quadro pode ser de várias horas. Nesse caso, há cenários que usam todos os recursos do processador (8-24 threads) e tarefas específicas que realmente usam apenas um thread e para as quais a frequência e o IPC de um núcleo vêm à tona. Isso inclui alguns cálculos físicos, onde cada próximo estado depende diretamente do anterior – por exemplo, a desintegração de um objeto em partes com sua subsequente interação entre si e com o ambiente, que eles também influenciam. A renderização em si é, em média, bastante paralelizada.
Para a maioria das tarefas, os cálculos da CPU são usados predominantemente. Em alguns casos, as GPUs podem fornecer aceleração, mas esta não é uma solução universal. Desde que determinado projeto seja devidamente financiado, alguns estúdios montam sistemas com aceleradores para softwares específicos. No caso do CGF, adicionar uma GPU ao farm existente do estúdio não faz mais sentido, devido à obsolescência do lado do servidor e das ferramentas acumuladas.
O segundo recurso importante é a RAM. Seu consumo depende de uma tarefa específica (e até mesmo de um frame específico) e, se estiver ausente, um desequilíbrio e uma desaceleração no trabalho geral são possíveis. Em particular, a tarefa pode consumir quase toda a RAM do nó, enquanto carrega apenas uma pequena parte dos núcleos disponíveis. Finalmente, o tempo de contagem aumenta significativamente quando a RAM livre do nó se esgota e você tem que usar arquivos de troca em discos
Finalmente, não se esqueça do subsistema de disco. Os requisitos para isso também dependem das tarefas. Alguns requerem uma grande quantidade de dados de entrada, mas a saída é muito pequena. Para outros, tudo é exatamente o oposto (geralmente são simulações de física), e para outros, os resultados dos cálculos intermediários ocupam um lugar enorme, mas a entrada e a saída são relativamente pequenas. Outra nuance é que as tecnologias comuns de cache não são eficazes na maioria das tarefas, já que os arquivos geralmente são lidos apenas uma vez. Alguns dos cálculos baseados em algoritmos podem ser executados com muita eficiência na nuvem ou em um cluster remoto, já que você não precisa direcionar dezenas de terabytes de dados em drives e entre nós e sistemas de armazenamento.
Para simplificar o processo de atribuição de tarefas, cada uma delas tem um determinado peso, que reflete os requisitos de recursos. Cada nó da fazenda, respectivamente, tem uma certa capacidade. Se, por exemplo, a capacidade de um nó é de 1000 unidades convencionais (unidades padrão), então ele será capaz de processar simultaneamente dez tarefas de 100 USD. Ou seja, cada uma ou duas tarefas por 350 USD e. e dois por 150 usd. e. Mas a tarefa para 2000 anos. Ou seja, esse nó não será mais controlado e não cairá sobre ele.
«Equilibrar os recursos disponíveis e necessários permite que o CGF use com eficiência a capacidade de hardware disponível. E se a carga não for distribuída por toda a fazenda, isso é uma perda direta de dinheiro devido ao tempo de inatividade ou uso insuficiente do equipamento. O ideal é que toda a fazenda esteja sempre 100% aproveitada e, na prática, esse é o objetivo ”, afirma o CTO do estúdio CGF.
O farm CGF baseado em sistemas blade (4U, 10 “blades”) tornou possível dispersar mais densamente os recursos de computação nas áreas disponíveis do estúdio. Atualmente, duas variantes de tais nós são usadas com base nas gerações anteriores do Intel Xeon:
- Um “blade” de processador duplo é mais simples, em duas versões (doravante denominadas Blades 1 e Blades 2), mas com a mesma configuração: 2 × Intel Xeon E5645 (6C / 12T, 2,4-2,67 GHz, 80 W), 64 GB RAM;
- «Blade “é mais poderoso, também com processador duplo (Blades 3): 2 × Intel Xeon E5-2670 (8C / 16T, 2,6-3,3 GHz, 115 W), 128 GB de RAM.
Mas isso não é tudo, todas as estações de trabalho do estúdio estão envolvidas na fazenda quando estão livres do uso interativo dos funcionários. As configurações típicas incluem um processador de alta frequência com 8 ou 12 threads – Intel Core i7-6700K, i7-8700K ou i7-9700K – e 64 GB de RAM. O número total de nós ativos no pico chega a 150.
Na fazenda são lançadas tarefas de simulação e renderização, cálculo de modelos, bem como tarefas de montagem da imagem final. O software de farm de renderização é executado na distribuição Linux do Debian 10. As tarefas são distribuídas pelo gerenciador CGRU, um popular software de gerenciamento de farm de renderização de código aberto. Devido ao fato de que existem muitas tarefas e são todas relativamente independentes umas das outras, o farm está pronto para aceitar quase qualquer “hardware” adequado, e sempre há algo para carregá-lo.
Portanto, os servidores de teste baseados nos modernos processadores AMD EPYC e Intel Xeon Escaláveis foram adicionados a este farm de renderização para avaliar as possibilidades de uso. Em primeiro lugar, foi interessante descobrir como as tarefas do estúdio serão realizadas no servidor AMD de soquete único mais avançado com o número máximo de núcleos e dois sistemas de dois soquetes com processadores AMD e Intel com aproximadamente o mesmo número total de núcleos por máquina.
Infelizmente, no momento do teste, não conseguimos obter as configurações mais semelhantes com o novo Intel Xeon Gold 6248R, que, em comparação com o 6248, tem mais núcleos e frequências mais altas a um preço mais baixo (1ku RCP 700) e o novo AMD EPYC 7F72 (1ku RCP 450) com o mesmo número de núcleos, mas com maior frequência. Como resultado, as configurações foram feitas com processadores um pouco mais simples, mas também mais baratos, o que do ponto de vista do custo do CPU (veja abaixo) parece ser uma opção bastante aceitável para teste.
Servidor de processador único baseado em AMD EPYC 7702 (doravante denominado EPYC x1):
- Plataforma Gigabyte R162-Z11-00 (1U);
- 1 × AMD EPYC 7702 (64C / 128T, 2,0-3,35 GHz, 180 W);
- 512 GB (8 × 64 GB) DDR4-3200;
- SSD Seagate FireCuda 520 (M.2, NVMe, 500 GB);
- Controlador de rede 10GbE;
- 2 × 1200 W PSU (80+ Platina).
Servidor AMD EPYC 7402 de processador duplo (doravante denominado EPYC x2):
- Plataforma Gigabyte R282-Z91-00 (2U);
- 2 × AMD EPYC 7402 (24C / 48T, 2,8-3,35 GHz, 180 W);
- 1 TB (16×64 GB) DDR4-3200;
- SSD Seagate FireCuda 520 (M.2, NVMe, 500 GB);
- Controlador de rede 10GbE;
- 2 × BP 1600 W (80+ Platina).
Servidor de soquete duplo baseado em Intel Xeon Gold 6248 (doravante denominado Xeon x2):
- Plataforma Gigabyte R281-3C2 (2U);
- 2 × Intel Xeon Gold 6248 (20C / 40T, 2,5-3,9 Гц, 150 Вт);
- 768 GB (12 × 64 GB) DDR4-2933;
- 2 × Samsung PM883 SSD (SATA, 240 GB; LSI RAID);
- Controlador de rede 10GbE;
- 2 × 1200 W PSU (80+ Platina).
Todas as máquinas estavam executando no perfil de desempenho e a AMD ficou com um domínio NUMA padrão por soquete. Todas as máquinas foram instaladas com a mesma pilha de software usada na fazenda; não houve problemas com ele. Em discos locais, de fato, havia apenas software, enquanto o acesso aos dados de trabalho em um sistema de armazenamento externo com NFS era feito em uma rede de 10 GbE. Todas as máquinas foram configuradas com memória 1DPC na maior frequência possível para cada plataforma. Para as tarefas atuais do estúdio, calculadas na fazenda, essa quantidade de memória costuma ser excessiva, mas em testes definitivamente não se tornará um fator de limitação de desempenho.
Em uma máquina de cada tipo – EPYC x1, EPYC x2, Xeon x2, Blades 1, Blades 2 e Blades 3 – foram executados os mesmos cenários de teste, que incluem ambas as cargas exclusivamente sintéticas, que na prática são apenas partes de problemas maiores e reais cálculos dos projetos em que o estúdio trabalhou durante o período de teste que durou várias semanas.
Para a avaliação inicial do desempenho dos nós, foram usados cálculos físicos (simulações) de vários tipos de objetos e substâncias no software SideFX Houdini:
- Pano – tecido e vestuário;
- FLIP – líquido;
- Grão – substâncias soltas;
- Piro – gás;
- RBD – dinâmica do corpo rígido;
- Tecido de velino e cabelo de velino são dinâmicas corporais suaves baseadas em conexões explícitas entre pontos.
Esses cálculos são relativamente rápidos e têm requisitos diferentes para o número e a frequência dos núcleos. Por exemplo, a ferramenta Pano é de rosca única, portanto, a frequência máxima de um núcleo só é importante para ela. Outras ferramentas são capazes de paralelizar cálculos em um grau ou outro. Neste teste, exatamente um problema de design foi atribuído a cada nó.
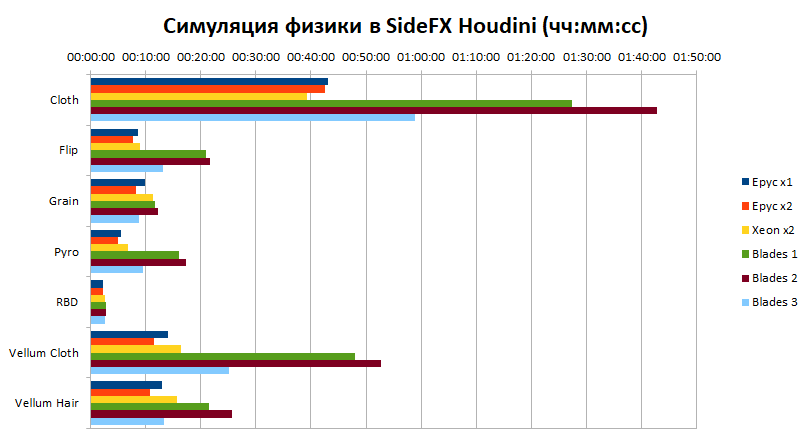
O gráfico acima mostra o tempo que os nós levaram para calcular cada simulação dos tipos acima. Essa grande diferença entre os nós antigos e novos se deve em grande parte às melhorias arquitetônicas dos processadores e plataformas em geral que ocorreram na última década. Se compararmos apenas as plataformas modernas entre si, tomando os resultados de uma máquina com Xeon como nível básico, então a diferença não é mais tão gigantesca, embora muito significativa.
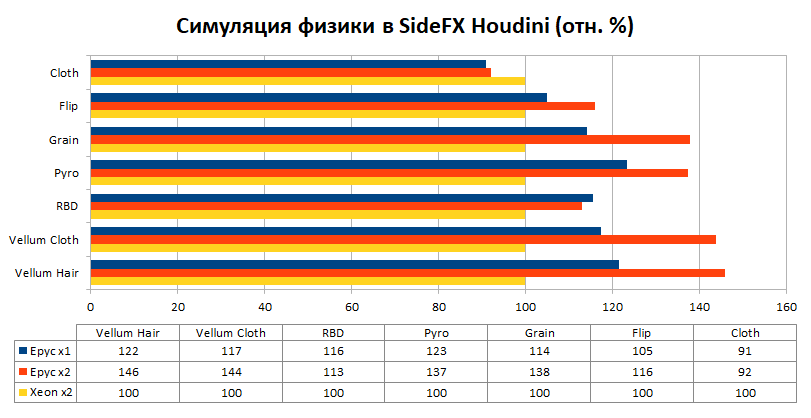
Em média, a vantagem de um sistema baseado em um processador AMD EPYC é de cerca de 20%, e um sistema baseado em dois processadores AMD EPYC é de 30%. Soluções com processadores AMD superam o concorrente em todos os testes, exceto no primeiro, que, como mencionado acima, difere em que os cálculos matemáticos funcionam no modo single-threaded. Lembre-se que o processador Intel Xeon Gold 6248 tem uma frequência turbo de 3,9 GHz, enquanto as soluções AMD – apenas 3,35 GHz. Isso provavelmente explica a defasagem de 10% neste teste.
Os sistemas em teste funcionaram como parte do farm de renderização do estúdio por várias semanas, portanto, conseguimos coletar estatísticas bastante extensas sobre as tarefas, das quais várias centenas foram processadas durante esse tempo. Uma vez que, no caso geral, a distribuição de tarefas entre os nós computacionais foi realizada em modo automático, as tarefas mais representativas foram selecionadas para o relatório final: com um grande número de quadros e com um tempo de contagem de um quadro na máquina mais rápida de pelo menos um minuto.
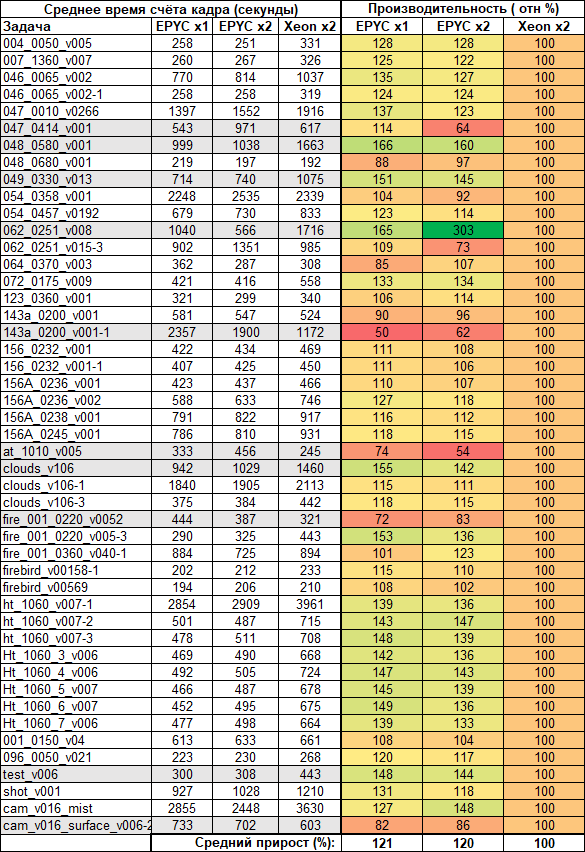
Na grande maioria dos casos, os servidores baseados em EPYC acabaram sendo mais rápidos do que a máquina Xeon, e o sistema EPYC de soquete único foi até um pouco mais rápido em média. Em média, a vantagem dos sistemas baseados em AMD em comparação com servidores baseados em Intel foi de 20-21%. Mas como essas são tarefas reais que envolvem diferentes tipos de cargas, o ganho não é uniforme em todos os lugares. Por exemplo, em um caso, dois processadores AMD acabaram sendo três vezes mais rápidos do que dois processadores Intel, no outro – quase duas vezes mais lento. Essa disseminação é uma consequência direta do fato de que nem sempre tarefas únicas são dimensionadas de forma eficiente para um grande número de núcleos.
Neste caso, a distribuição pode ser mais lucrativa não com base em “uma tarefa por um nó”, como nos testes anteriores, mas “várias tarefas por um nó”. Para avaliar as duas abordagens, um conjunto de 10 quadros de renderização foi enviado para cada sistema de teste. Na versão sequencial, cada frame foi enviado aos servidores um a um e em paralelo – tudo de uma vez. O resultado é o tempo total de computação. Os testes mostraram que os servidores de processador duplo com AMD e Intel nesta tarefa acabam sendo cerca de um terço mais rápidos no caso de renderização simultânea de quadros e um servidor AMD de processador único – cerca de 20%. Em termos de velocidade geral, os sistemas com AMD estão na liderança.
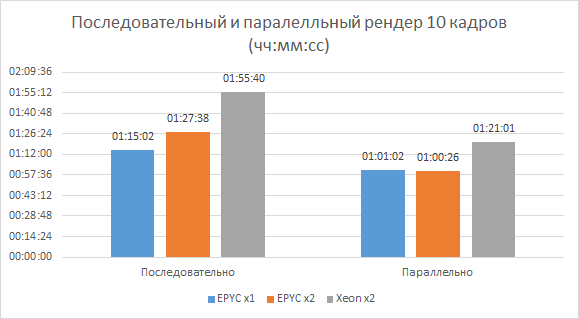
No próximo teste especial, para estudar com mais precisão a eficiência da paralelização, usamos mais uma, diferente da anterior, tarefa de renderização, composta por oito frames. Ao mesmo tempo, o tempo de contagem de cada um nos nós da fazenda do estúdio (Blades) era geralmente de 10 a 20 minutos, dependendo de seu desempenho. Esta tarefa foi lançada em um servidor com um processador AMD (EPYC x1) com configurações do sistema de gerenciamento de tarefas para contar um, dois, quatro e oito quadros no servidor simultaneamente. Assim, a primeira opção será sequencial e todas as demais serão paralelas.
É aqui que o software de renderização funciona. Uma das opções para paralelização universal automática de suas tarefas é dividir o campo da imagem de destino em vários blocos e calcular cada um com um thread de renderização separado. Em geral, o usuário pode escolher para sua tarefa em quantos blocos ela pode ou deve ser dividida. Neste caso, a renderização de cada quadro não sabe que algo mais está sendo considerado no nó, e é guiada pelo número de núcleos computacionais para selecionar o número de threads a serem executados para contagem de blocos.
Como resultado, verifica-se que o cálculo simultâneo de oito quadros já está usando ativamente os meios de processadores e o sistema operacional para processar o número de threads que são significativamente maiores do que o número de núcleos. A tabela com os resultados mostra que, neste caso, você pode obter um bom ganho – o tempo total para obter o resultado é cerca de um terço a menos do que se todos os quadros fossem contados sequencialmente, embora formalmente todos os núcleos do processador sejam usados ativamente em ambas as versões.
Conforme observado acima, para alguns cenários de computação, usar um servidor poderoso com um grande número de núcleos e uma grande quantidade de RAM pode não ser muito eficaz devido à complexidade do gerenciamento de tarefas heterogêneas nele. Em particular, isso se deve às diferenças de recursos, como kernels e RAM. O primeiro afeta diretamente apenas a velocidade dos cálculos, mas pode ser simplesmente impossível prever o consumo de RAM por tarefas heterogêneas e gerenciá-lo.
Neste caso, você pode considerar a opção de “fatiar” um servidor “grande” em vários servidores virtuais com uma determinada distribuição de recursos. Essa abordagem também permitirá que você ajuste a alocação de recursos em tempo real, escolhendo a melhor opção para as tarefas atuais. Para testar essa abordagem, o gerenciamento de máquina virtual de código aberto Proxmox foi instalado em um único servidor com processador AMD (EPYC x1).
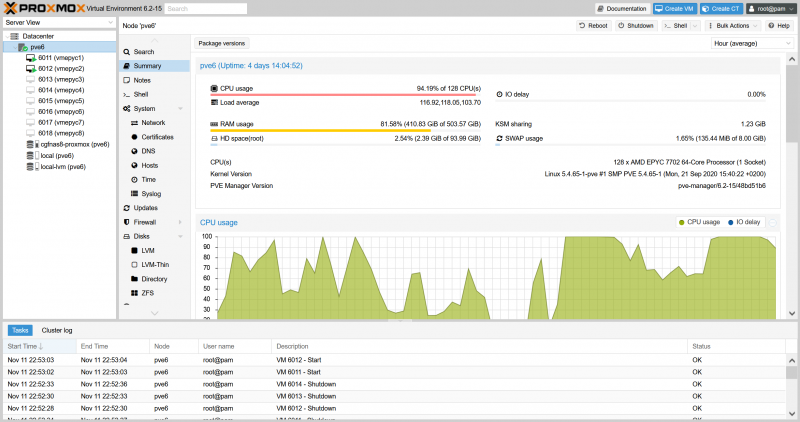
Para a máquina EPYC x1 – 64 núcleos / 128 threads e 512 GB de RAM – as máquinas virtuais (VMs) com configurações de 16 núcleos e 64.000 MB de RAM foram usadas na quantidade de oito peças para até uma VM com 128 núcleos e 512.000 MB de RAM. Ao contrário dos testes realizados anteriormente com servidores reais, este cenário pode ter certas limitações de desempenho devido à colocação de discos da máquina virtual em um sistema de armazenamento externo conectado via NFS por meio de uma conexão de rede de 10 Gbps.
Em primeiro lugar, deve-se notar que o melhor resultado de velocidade pouco difere do melhor resultado obtido em um sistema real sem o uso de virtualização. Isso sugere que os processadores AMD EPYC de vários núcleos são adequados para tais cenários e podem lidar com altas cargas de trabalho. Ao mesmo tempo, na virtualização, o esquema “8 máquinas virtuais contando cada uma com seu próprio quadro” teve o melhor desempenho. Em geral, podemos dizer que as soluções com AMD EPYC são as mais eficientes em termos de velocidade precisamente em cenários “sobrecarregados” quando um grande número de tarefas ou threads simultâneos com uso intensivo de recursos são usados.
O consumo de energia e a eficiência energética são parâmetros tão importantes na avaliação de sistemas quanto seu desempenho. Os sistemas blade mais antigos têm suas próprias especificações: um chassi 4U para dez blades consome cerca de 3 kW (aproximadamente 260-300 W por nó) e requer cabos separados para cada uma das quatro fontes de alimentação. Em contraste, os sistemas de teste são muito menos exigentes – eles só precisam de dois cabos por nó 1U ou 2U. A comparação da densidade e do consumo de sistemas modernos e servidores blade antigos é dada em termos de volume de 4U de espaço em rack – esta é a quantidade de espaço necessária para cada sistema blade à disposição do estúdio.
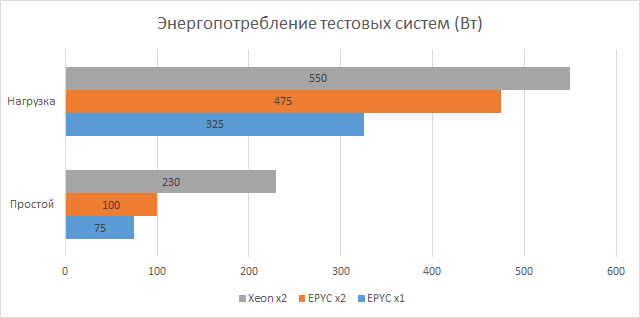
Durante o teste, o monitoramento remoto do consumo foi configurado em todos os três servidores usando sensores integrados à plataforma. O gráfico acima mostra os valores de consumo de energia máximo e mínimo. Os primeiros são os maiores valores sustentados registrados sob carga, enquanto os últimos foram obtidos sem carga nos servidores. A maior eficiência das soluções AMD é provavelmente em parte devido ao processo técnico mais fino.
O sistema 1U de processador único com AMD EPYC 7702 é de grande interesse em termos de densidade de recursos. Quatro desses sistemas oferecem 256 núcleos para um consumo total de cerca de 1,3 kW. Já o antigo sistema blade (Blades 3) em um chassi 4U possui 160 núcleos e, como mencionado acima, o consumo está na casa dos 3 kW. Ou seja, uma solução AMD moderna tem 1,6 vezes mais núcleos com mais de duas vezes a diferença de consumo.
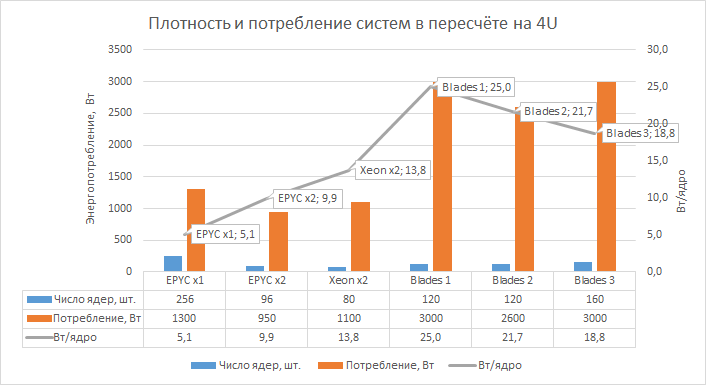
Dois sistemas 2U de processador duplo com AMD EPYC 7402 acabaram sendo um pouco menos densos: 96 núcleos com um consumo de 950 W, ou seja, 1,66 vezes menos núcleos e mais de três vezes menos consumo em comparação com um blade 4U (Blades 3). Finalmente, para o sistema de teste com Intel Xeon Gold 6248 sob as mesmas condições de comparação, obtemos metade do número de núcleos e um pouco menos de três vezes a diferença no consumo de energia.
Além disso, os servidores de teste 1U / 2U exigem menos resfriamento em comparação com blades e podem, se desejado, atualizar suas GPUs (desde que a plataforma suporte esse recurso), o que pode acelerar alguns cálculos ou ser usados para organizar VDI. Se tal versatilidade não for necessária, mas um aumento ainda maior na densidade for necessário, os nós 2U4N podem ser usados.
Vale a pena fazer uma reserva imediatamente que o cálculo do custo das plataformas de teste é aproximado, já que normalmente essas compras são de natureza muito mais complexa e todo o projeto é levado em consideração, e não as máquinas individuais. A ASBIS, que forneceu os servidores para teste, também cotou preços para cada uma das plataformas base (CPU + memória + chassis) para uma única compra. Naturalmente, ao comprar mais carros, o custo será diferente.
Os preços para as três plataformas estão na mesma ordem. Ambos os sistemas AMD em testes de carga real revelaram-se quase idênticos em desempenho e são visivelmente mais rápidos do que um servidor com Xeon. No entanto, dada a maior densidade e eficiência de energia, é o sistema de soquete único da AMD que é o mais lucrativo.
Se compararmos os sistemas realmente testados com os teoricamente mais adequados (Xeon Gold 6248R, EPYC 7702P e 7F72), a imagem se torna ainda mais interessante. A política de preços da AMD para processadores da série P, que são adequados apenas para sistemas de soquete único, visa suplantar as configurações de soquete duplo da Intel – com menores custos de CPU, você pode obter maior densidade e / ou número de núcleos. E isso se aplica a modelos ainda mais “simples”, sem o aumento da frequência e enorme cache como em 7Fx2.
Ao mesmo tempo, a AMD deliberadamente não segmenta os processadores em todos os outros parâmetros: qualquer EPYC 7002 tem 8 canais de memória DDR4-3200 e 128 linhas PCIe 4.0, em contraste com 6 canais DDR4-2666 / 2933 e 48 linhas PCIe 3.0 da Intel. E os sistemas AMD de processador duplo podem já ser necessários para fornecer uma frequência base mais alta para o número de núcleos, com a necessidade de mais de 4 TB de memória, com certos requisitos de volume e largura de banda de memória por núcleo, bem como para sistemas HPC / AI.
⇡#Conclusão
Uma das principais conclusões que o estúdio tirou para si mesmo com base nos resultados dos testes não diz respeito ao hardware, mas ao software. Mais precisamente, sua compatibilidade total com as plataformas AMD. Todos os pacotes de software usados pelo CGF funcionaram sem problemas ou ajustes finos adicionais. Incluindo em cenários mais complexos de processamento de blocos e virtualizado. É o receio de incompatibilidade de software que ainda é uma das barreiras psicológicas, nem sempre justificadas, na escolha de um equipamento. Não houve problemas de compatibilidade ao instalar unidades ou adaptadores de rede adicionais.
No lado do hardware, a estratégia de soquete único da AMD acertou em cheio no estúdio. As plataformas de teste são da mesma ordem de magnitude e são muito mais rápidas do que os sistemas blade mais antigos, mas o sistema de dois soquetes da AMD ainda é um pouco mais caro do que os outros. Ao mesmo tempo, ambas as plataformas AMD em tarefas reais de estúdio para simulação e renderização são em média 20-21% mais rápidas do que os sistemas baseados em Xeon. Considerando que o uso da versão P do processador em um servidor AMD de soquete único reduzirá ainda mais o custo, torna-se óbvio que esta plataforma em particular entre todas as testadas é a mais atrativa em termos de relação preço / desempenho.
Além disso, é mais eficiente em termos de energia e mais denso em termos de número de núcleos em relação a outras plataformas de teste e sistemas blade mais antigos. Simplificar o cabeamento e reduzir as contas de luz são, sem dúvida, aspectos muito importantes para um estúdio. A combinação de todos esses fatores levou ao fato de que, mesmo antes da conclusão de todos os testes como parte do farm de renderização, o estúdio adquiriu independentemente outro servidor de soquete único baseado em AMD EPYC 7002 para estudar seus recursos em outros cenários das tarefas de TI da empresa.
Com base nos resultados dos testes, o estúdio está considerando a possibilidade de uma atualização parcial do farm de renderização, até agora sem abandonar definitivamente os sistemas blade, utilizando plataformas AMD de processador único com altura de 1U, mas em uma configuração diferente do sistema de teste. O principal fator ainda são as finanças, já que a economia do estúdio está em grande parte ligada às necessidades dos pedidos executados – quanto maiores e mais complexos são os projetos tecnicamente, maiores são os requisitos de hardware.
Na situação atual, existe a necessidade de um cluster pequeno, relativamente barato, mas rápido o suficiente e versátil para as necessidades diárias do estúdio. Inclusive para o desenvolvimento de novas técnicas e oportunidades. Devido à combinação de muitos fatores, tarefas de projeto superpesadas simples são frequentemente mais lucrativas do ponto de vista econômico para “descarregar” em sites externos – grandes clusters ou nuvens.
«Quanto pendurar nos núcleos? O mais ideal para nós agora são sistemas 1U com processadores AMD EPYC 7502P de 32 núcleos (2,5-3,35 GHz, 128 MB de cache L3, 180 W TDP). Eles alcançam um equilíbrio entre custo, incluindo chassi e memória, densidade, consumo de energia, desempenho e versatilidade para garantir desempenho de estúdio eficiente no ambiente atual ”, conclui CGF CTO.