
Os computadores da arquitetura clássica de von Neumann são ideais para a solução sequencial de problemas. Potencialmente – se o problema for reduzido a uma execução estritamente direta de uma cadeia de operações elementares (com a possível inclusão de ciclos) – a velocidade de obtenção do resultado é limitada apenas pelas capacidades físicas do elemento base sobre o qual esta máquina de von Neumann é implementado. É inútil para uma pessoa competir com ele: isso foi provado há muito tempo pelas vitórias do computador sobre um grande mestre vivo, primeiro no xadrez e depois no jogo Go, cada jogo que se resume essencialmente a uma sequência sequencial. enumeração de movimentos aceitáveis com uma avaliação de médio e longo prazo de sua otimização.

Em 2020, o Instituto de Tecnologia de Massachusetts criou um protótipo de chip neuromórfico (ou seja, funcionando de acordo com os mesmos princípios do cérebro humano) baseado em memristores (fonte: MIT)
No entanto, existe todo um conjunto de classes de problemas que, em princípio, não podem ser reduzidos a uma enumeração sequencial. Figurativamente, eles podem ser classificados como “reconhecimento do que não foi visto anteriormente com base no conhecimento do que já é conhecido”. Veja a análise de imagem, por exemplo: estamos tão acostumados a não perceber a mais alta qualidade de nossa capacidade de reconhecer imagens de objetos mesmo em um plano (para não mencionar uma cena tridimensional) que ilusões de ótica ou “imagens impossíveis” no espírito de Escher nos levam a uma leve confusão. Para um computador Von Neumann, no entanto, qualquer imagem – seja a foto de um gatinho, o desdobramento tridimensional de um tesserato ou uma infinita escada Penrose – é apenas uma miscelânea de pixels. Além disso, não existe um algoritmo universal para encontrar qualquer aparência de ordem nessa confusão; tais problemas devem ser resolvidos no sentido pleno da palavra por métodos numéricos.
É importante que o número de problemas computacionais aplicados, que são excessivamente complexos para computadores clássicos, se torne maior, as tecnologias mais profundas penetram na vida cotidiana, na economia, na ciência e até na política. Reconhecimento e geração de fala em tempo real, identificação precisa (ou seja, com uma proporção deliberadamente insignificante de falsos positivos em ambas as direções) de uma pessoa pelo rosto, previsão do desenvolvimento de tendências de estoque, identificação de áreas ricas em minerais a partir de imagens espaciais, avaliação preditiva do comportamento de sistemas complexos, incluindo políticos e econômicos – literalmente milhares deles.

A litografia Ascendente e Descendente de Maurits Cornelis Escher demonstra a ilusão visual de uma “escada impossível” com quatro lances encerrados em uma espiral infinita (Fonte: Wikimedia Commons)
Os computadores de hoje precisam aprender a resolver efetivamente problemas essencialmente paralelos, usando lógica difusa e em condições de escassez aguda de informações recebidas. Um aumento banal nas frequências de operação dos processadores clássicos com um aumento simultâneo na densidade dos transistores para cada um de seus milímetros quadrados não será capaz de lidar com isso. É muito mais lógico tomar o cérebro biológico como base – e se você não reproduzir seu trabalho um a um, pelo menos crie um sistema de computação baseado em princípios semelhantes. Bem, ou emule a operação de tal sistema em máquinas muito poderosas de von Neumann ou clusters (redes) que consistem em tais máquinas.
Outra pergunta: quais são exatamente esses princípios?
⇡#Destaques no córtex: como o cérebro funciona
O principal trabalho computacional – mental – no caso de um organismo biológico, se falarmos dos mamíferos em geral, é realizado pelo córtex cerebral. Nos humanos, contém em média 16 bilhões de neurônios – os nós básicos de computação lógica do tipo analógico. Cada um desses neurônios é novamente, em média, conectado por processos a cerca de 10.000 outros. Como exatamente, do ponto de vista biológico, o processamento de informações dentro de um neurônio é implementado é uma questão especial, mas para os propósitos do material de hoje, é fundamentalmente insignificante.
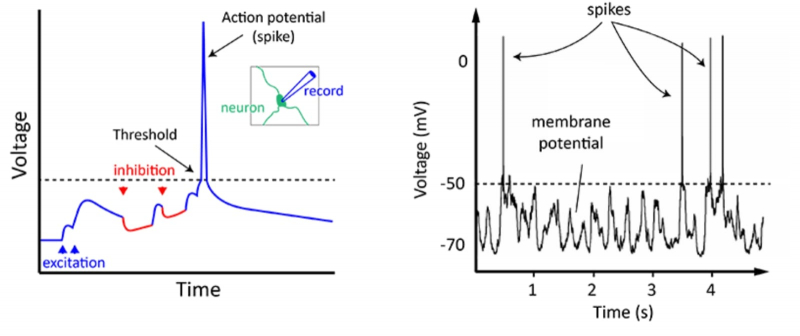
Esquerda: formação de um potencial de ação (um pico de voltagem que vai muito além do nível limiar) em um neurônio durante a soma ponderada de sinais excitatórios e inibitórios de dendritos. Direita: Pacote de picos individuais se propagando pelo axônio (fonte: The University of Queensland)
O principal é que o neurônio recebe muitos sinais por meio de um sistema ramificado de terminais de entrada, processos com cerca de um mícron de espessura, chamados dendritos. Mais para dentro – no corpo, ou soma, da célula – ele faz sua soma ponderada. Ao atingir um determinado limiar do estímulo acumulado dessa forma, o neurônio é ativado, gerando um impulso elétrico em seu único terminal de saída – processo recoberto por uma bainha isolante de mielina, o axônio. Esse impulso, denominado potencial de ação, é uma série de surtos de tensão de curto prazo (da ordem de 1 ms com um intervalo entre surtos de aproximadamente 200 ms) de aproximadamente 60 mV cada.
Na extremidade do axônio do soma, há uma sinapse – um contato especial por meio do qual o sinal de saída é transmitido ao dendrito de outro neurônio. Uma característica da estrutura do cérebro biológico é que a interação entre seus elementos não é puramente elétrica, como em um chip semicondutor, mas eletroquímica. A sinapse não é de forma alguma um condutor de sinal banal entre o axônio e o dendrito: sob a influência de um potencial de ação (um ou, em alguns casos, vários), libera certas moléculas, neurotransmissores, que se difundem em uma solução salina que preenche a estreita lacuna entre a sinapse do neurônio de origem e a membrana celular do dendrito do neurônio – receptor.
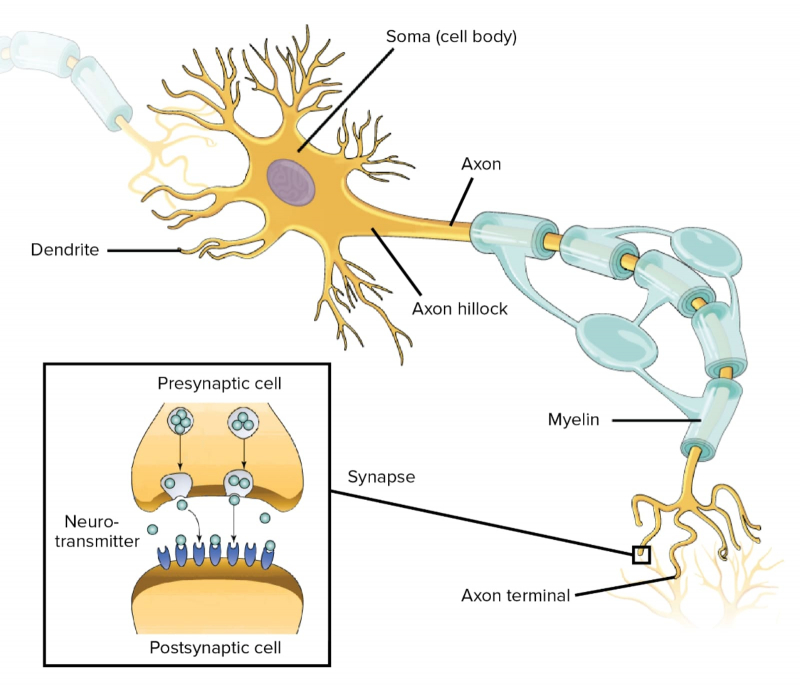
Os principais componentes de um neurônio e (inserção) um diagrama da organização da transmissão do sinal na fenda sináptica: acima – o terminal axônico, abaixo – o final do dendrito (fonte: Khan Academy)
Os neurotransmissores se ligam às suas moléculas receptoras complementares na superfície de contato do dendrito e o estimulam a abrir o portão de condução através do qual passam as partículas carregadas, os íons. E agora esses íons alteram o potencial elétrico do dendrito, provocando a propagação de um impulso elétrico através dele (mais precisamente, através da solução salina que preenche seu interior tubular) em direção ao soma do neurônio receptor.
A imagem é complicada pelo fato de que cada dendrito em um determinado momento é capaz de experimentar o impacto de muitas sinapses; que a magnitude do impulso gerado no dendrito depende do número de portões de condução abertos, que por sua vez é determinado pelo número de neurotransmissores emitidos pelas sinapses. Acrescentando outra variável à equação é o fato de algumas sinapses estimularem os dendritos com os quais interagem, enquanto outras, ao contrário, inibem a geração de um impulso elétrico neles.
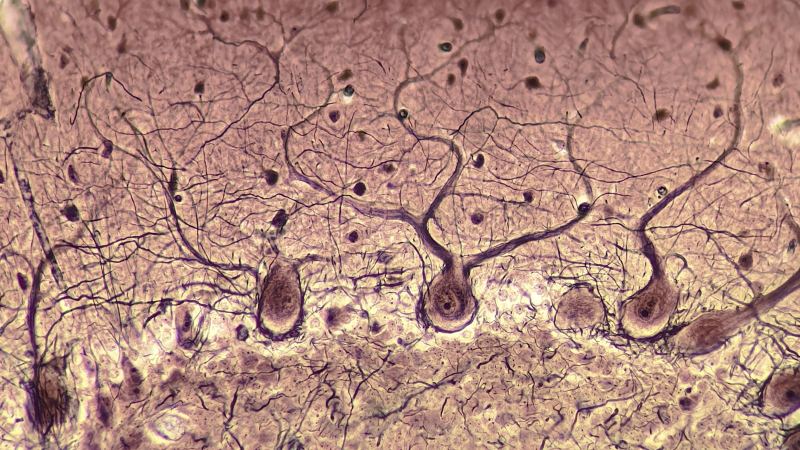
Fotomicrografia de “corpos ganglionares” descobertos por Jan Purkyně em 1839: grandes neurônios localizados no cerebelo com dendritos altamente ramificados (fonte: Wikimedia Commons)
E embora cada neurônio tenha um axônio, pode haver várias saídas sinápticas nele, o que adicionalmente aumenta a conectividade e a natureza complexa do funcionamento do cérebro como uma rede para gerar, modular e transmitir sinais e, mais importante, como uma rede capaz de aprendizagem.
⇡#Simplicidade é pior
Executar um algoritmo pronto para resolver um determinado problema e aprender como resolvê-lo são abordagens fundamentalmente diferentes. O primeiro caminho é percorrido pelos computadores von Neumann, os obstinados executores dos algoritmos criados por programadores biológicos. De acordo com o segundo – redes neurais, em certa aproximação, reproduzindo as estruturas do córtex cerebral dos mesmos programadores biológicos. É verdade que, como uma pessoa, uma rede neural tende a cometer erros, mas os programas para máquinas von Neumann também são imperfeitos – sem lançamento regular de patches que corrigem falhas de funcionalidade e segurança, nenhum software moderno criado por programadores biológicos novamente notórios (fale sobre NoCode / especial LowCode).

Embora o artista tenha retratado a Mariner 1 voando entre as estrelas, 290 segundos após o lançamento, o veículo lançador com este dispositivo explodiu sob comando da Terra devido a um erro no código (fonte: NASA)
A natureza dos erros que surgem inevitavelmente em qualquer código de programa volumoso é puramente humana: desatenção, consideração insuficiente de estruturas lógicas, erros de digitação banais. São conhecidas catástrofes de alto perfil provocadas por tais erros: por exemplo, o primeiro lançamento a Marte do navio americano Mariner 1 em 1962 não teve sucesso – a tripulação de lançamento foi forçada cinco minutos após a decolagem do veículo de lançamento para dar um comando para si mesmo -destruir a fim de evitar a evasão descontrolada do curso. E tudo porque ao inserir o código escrito à mão no computador de bordo, perdeu-se um hífen que não foi lido com muita clareza no manuscrito. “O hífen mais caro da história”, como Arthur C. Clarke o chamou mais tarde, custou 80 bilhões de dólares (quase 745 bilhões em preços de 2022) – cerca de 7% do orçamento total,
O treinamento, é claro, não serve como garantia de uma tomada de decisão sem erros – mas pelo menos bugs no nível do código (na ausência total deles), a rede neural será poupada. O principal é garantir que seus elementos atuem pelo menos aproximadamente de acordo com os princípios do funcionamento dos neurônios biológicos. E a princípio, quando os neurocientistas ainda tinham uma ideia muito vaga sobre o funcionamento dessas próprias células nervosas, o neurônio artificial era uma aparência bastante grosseira de um natural.
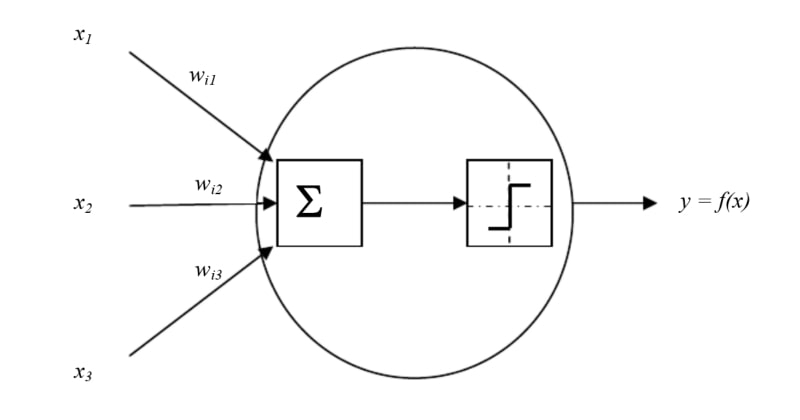
Modelo de neurônio artificial de McCulloch-Pitts: os sinais de entrada x1..x3 são modulados por pesos embutidos em código wi1..wi3, após o qual a soma (Σ) é executada. O valor resultante é comparado com o limite definido e, se for excedido, o sinal resultante y=f(x) é emitido (fonte: Research Gate)
Estamos falando do modelo McCulloch-Pitts, proposto em 1944 e batizado com o nome de seus autores, o neurofisiologista e um dos fundadores da cibernética como ciência, Warren McCulloch, e o linguista Walter Pitts, que gostava de lógica matemática. Este é, de fato, um somador múltiplo de limite: sua entrada recebe vários sinais “verdadeiro” ou “falso” com certos pesos e, se sua soma exceder um determinado valor limite predeterminado, o valor “verdadeiro” é aplicado à única saída do adicionador, caso contrário – “Falso”.
Isso é realmente semelhante na primeira aproximação ao trabalho de um neurônio biológico, ao longo do axônio do qual um impulso não passa até que todo o conjunto de sinais dos dendritos exceda um certo limite. Além disso, a partir desses neurônios artificiais é possível, definindo vários valores limite para sua operação, construir portas lógicas básicas – “E lógico”, “OU lógico”, “NÃO lógico” e outros mais complexos. O que, ao que parece, não é um cérebro eletrônico?
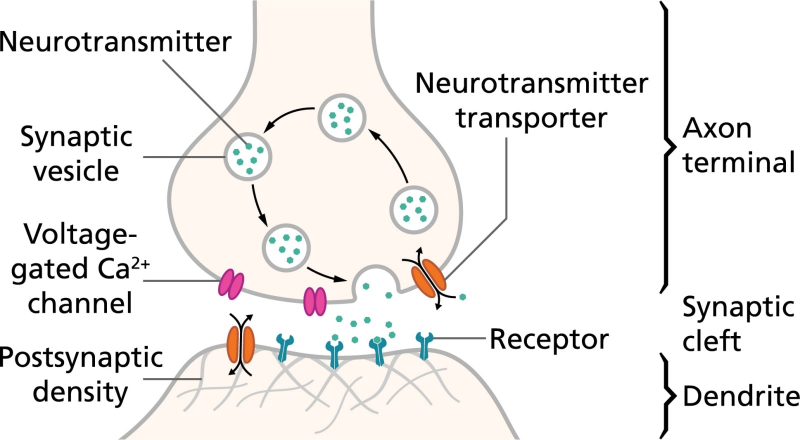
A ativação de um neurônio biológico através da fenda sináptica é implementada de forma complexa que permite o controle químico da força do sinal formado no dendrito, que corresponde a pesos sinápticos variáveis, que o modelo de McCulloch-Pitts não fornece (fonte: Universidade de Queensland)
No entanto, o modelo de McCulloch-Pitts, se usado para emular a atividade cerebral, tem uma desvantagem crítica: não permite que um sistema construído com base em neurônios artificiais aprenda. Isso não permite porque os pesos dos sinais de entrada neste modelo são rigidamente fixados, o que significa que o impacto no sistema de um ou outro fator será sempre do mesmo tipo.
A educação baseia-se em repensar a experiência adquirida: a criança é atraída por tudo que é claro e quente, mas assim que toca o fogo com o dedo, não precisa mais explicar por que isso não pode ser feito. A imagem da chama nos neurônios de seu cérebro (como exatamente ela será codificada ali na forma de impulsos elétricos não é importante aqui) receberá um enorme peso negativo, e os comandos “estique a mão para este-aquele-brilhante -warm” ficará bloqueado de forma confiável. Pelo menos até o início da puberdade rebelde.
⇡#Estudar, estudar e estudar novamente
A próxima abordagem para modelar um neurônio biológico foi o perceptron (do inglês percepção, “percepção”) proposto um pouco mais tarde, em 1957, pelo psicólogo e neurofisiologista Frank Rosenblatt, um neurônio artificial com pesos variáveis em cada uma das entradas. É justamente pelo fato de os pesos serem variáveis, e não definidos desde o início pelo construtor da rede neural, que se torna possível alterar os valores desses mesmos pesos, dependendo do resultado que o perceptron produz, e implementando assim o processo de aprendizagem.

Frank Rosenblatt ao lado de um modelo funcional de seu perceptron (fonte: Cornell University Library)
O perceptron lida fundamentalmente com sinais e, além disso, com pesos de vários sinais: os positivos correspondem a um aumento (excitação) de um estímulo em um neurônio biológico, os negativos correspondem à sua inibição (inibição).
Os sinais de entrada modulados por pesos sinápticos são alimentados ao somador perceptron, e então esta soma ponderada é comparada com um valor limite predeterminado: se o primeiro for menor que o segundo, o neurônio artificial de Rosenblatt permanece em repouso, se for maior, gera um pulso na saída.
Mesmo essa construção relativamente descomplicada permite que estruturas não biológicas incorporem funções cognitivas básicas, como reconhecimento de padrões. Ao mesmo tempo, o perceptron não requer nenhum algoritmo: basta fornecer uma quantidade significativa (no limite – infinita) de material de treinamento. O esquema do treinamento em si é o seguinte:
A) o objeto em estudo é examinado por alguns sensores (que podem ler a mesma imagem pixel por pixel ou destacar certas formas e propriedades características nela),
B) a cada uma das entradas do perceptron é atribuído aleatoriamente um pequeno peso de módulo,
C) a soma ponderada dos sinais das entradas é realizada e a resposta do perceptron é formada (“há um sinal – não há sinal”, “sim – não”),
D) o experimentador recebe a resposta e a compara com a imagem original: se o perceptron funcionou corretamente, ele passa para o próximo objeto, mas se não…
E) então os pesos de entrada são corrigidos para a magnitude do erro, e o procedimento é repetido desde o início.
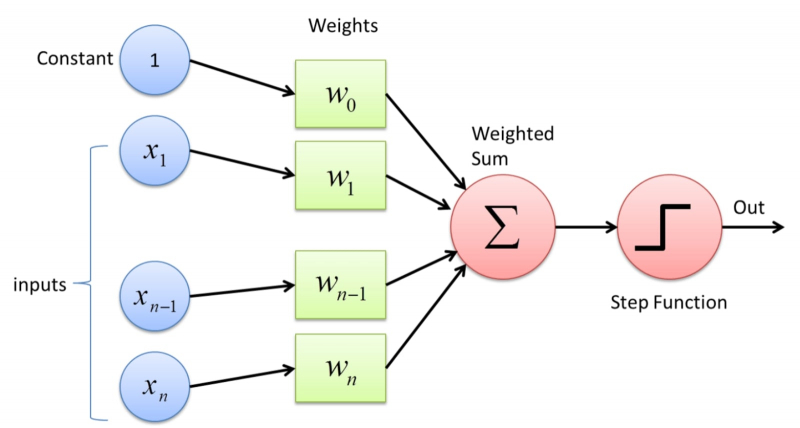
As entradas do Perceptron são alimentadas com constantes, sinais de sensores externos ou outros perceptrons e valores de peso, após os quais a soma ponderada e a ativação do potencial de saída de acordo com uma determinada lei são realizadas (fonte: Towards Data Science)
Do ponto de vista da lógica, o perceptron é uma clássica “caixa preta”, pois no caso geral o experimentador não controla manualmente a redistribuição dos pesos após cada ato errôneo de reconhecimento. Ele simplesmente diz à máquina que ela não funcionou corretamente. É claro que, em vários casos, alguma pré-programação de perceptrons é possível e até razoável: por exemplo, se uma máquina precisa destacar quem fica sem máscara médica em um fluxo de pessoas, o peso negativo do recurso “ presença de uma máscara no rosto” certamente será enorme, avassaladora em relação a todas as outras.
⇡#Em redes de conhecimento
No entanto, no final da década de 1960, ficou claro que um perceptron não era suficiente. Sim, o modelo de Rosenblatt consegue distinguir com confiança entre entidades entre as quais um claro limite “sim-não” pode ser traçado: ele distingue um gato de um cachorro, uma rosa de uma peônia, uma scooter de um ciclomotor e assim por diante. Vários perceptrons funcionam especialmente bem juntos, em uma única, por assim dizer, camada de percepção: cada um se concentra em reconhecer alguma propriedade ou característica particular dos objetos estudados pela máquina.
Ainda assim, as capacidades de uma única camada de neurônios artificiais, não importa quantos existam, não são suficientes para implementar uma função tão importante para a lógica matemática como “OU exclusivo”. Mas para a formação da função cognitiva, ele desempenha um papel crucial e é usado por nós, portadores biológicos da mente, o tempo todo na vida cotidiana – quase sempre inconscientemente.
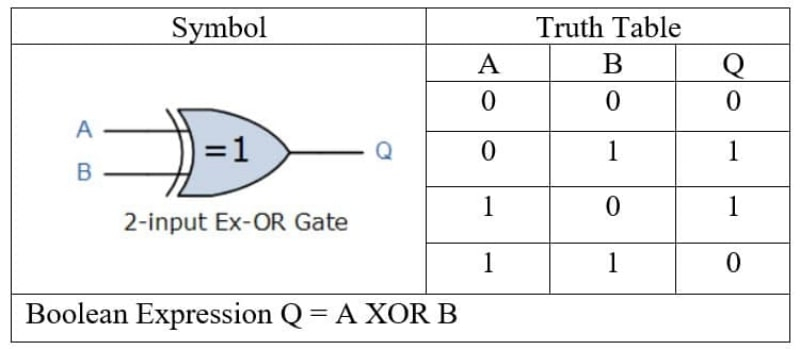
ANSI XOR Gate Designation and Truth Table for Two Arguments (Fonte: 911Electronic)
«OU exclusivo (XOR) para dois argumentos dá a saída “true” somente se os valores desses argumentos forem diferentes, mas se forem iguais, a resposta é “false”:
A função XOR é implementada, por exemplo, por qualquer trem regular do metrô, que tenha vagões conectados em ambas as extremidades com os táxis voltados para fora. Se exatamente um desses dois carros estiver ativo (o motor colocado nele estiver funcionando), o trem se moverá na direção correspondente (o valor de saída é “verdadeiro”). Se ambos os motores não funcionarem, ou se cada um deles tentar puxar o trem em sua própria direção com igual potência, o trem, é claro, permanecerá no lugar (a saída é “falsa”). O critério para o movimento de um trem do metrô pode ser escrito em termos de lógica matemática da seguinte forma:
Motor do carro dianteiro “exclusivo OU” motor do carro traseiro.
Ao resolver um problema desta forma, o Rosenblatt perceptron irá, como dizem, vender: repetidamente será confundido (violando a distribuição de pesos já aparentemente selecionada corretamente) pela influência mútua de recursos iniciais aparentemente não relacionados. Portanto, a máquina precisa de ajuda – por exemplo, complicando seu design com a ajuda de um perceptron adicional que irá comparar os resultados da análise de parâmetros de entrada aparentemente independentes, certo?
Para um neurocientista, saber que os neurônios na cascata do cérebro é trivial – mas os engenheiros levaram muito tempo para compreender essa verdade (Fonte: Wikimedia Commons)
Hoje, isso pode realmente parecer uma coisa natural. Mas, na verdade, quase um quarto de século se passou desde a invenção de um único perceptron até a formulação da ideia da possibilidade de combiná-los em complexos interconectados. Somente em 1986, nas obras de David Rumelhart (David Rumelhart), Geoffrey Hinton (Geoffrey Hinton) e Ronald Williams (Ronald J. Williams), um método extremamente promissor para expandir o potencial cognitivo de sistemas perceptron usando backpropagation, ou simplesmente BP, foi delineado. .
O princípio do BP se resume ao fato de que ao invés de um neurônio artificial, não basta levar vários que seriam responsáveis por reconhecer propriedades individuais dos objetos em estudo (se o motor funciona no carro dianteiro ou traseiro), é também é necessário colocar pelo menos mais uma camada após a primeira camada de detecção de características explícitas. , oculta, que seria responsável por estudar as relações entre esses mesmos sinais (se os dois motores funcionam simultaneamente e com impulso igual).
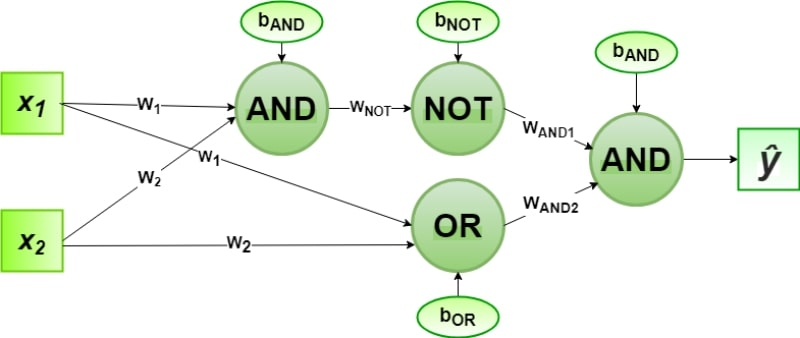
Uma rede perceptron multicamada já permite implementar a função lógica XOR combinando NAND (NOT e AND) com OR através de AND com os seguintes valores de peso: w1=1, w2=1, wNOT=–1, wAND1=1, wAND2 =1 — e constantes de normalização: bAND=-1.5, bOR=-0.5 e bNOT=0.5 (fonte: GeeksForGeeks)
De fato, usando a segunda camada de perceptrons, não é tão difícil implementar a função XOR. Tudo se resume a uma combinação de “OU lógico” (OU) e “E-NÃO lógico” (NAND) através do “E lógico” (E). Cada uma dessas três funções, por sua vez, é facilmente implementada por perceptrons únicos.
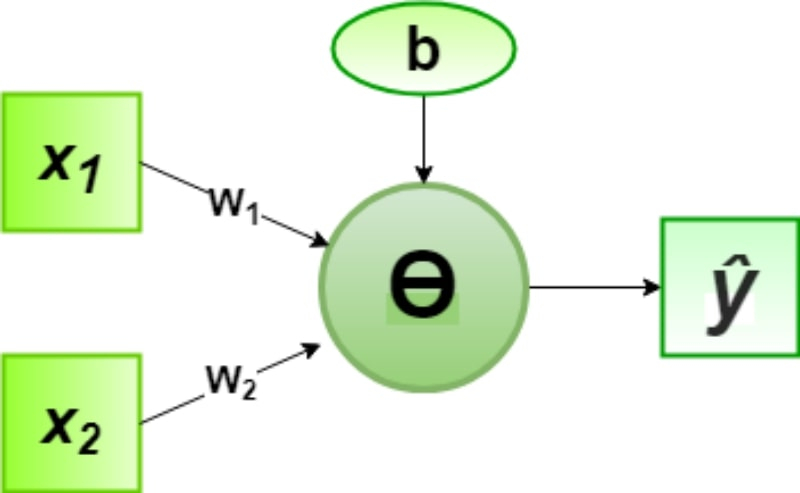
Um único perceptron com um limite de ativação Ө (se a soma ponderada dos argumentos ≥0, a saída é 1, caso contrário, 0) permite implementar funções lógicas básicas: quais – AND, OR, NOT e assim por diante – determinam os valores da constante b e dos pesos w1 e w2 (fonte: GeeksForGeeks)
Para não sobrecarregar a apresentação dos princípios básicos das redes neurais com lógica matemática aplicada, apresentamos a opção mais simples – a incorporação do “E lógico” no perceptron Rosenblatt. Existem três entradas aqui: a constante de normalização b (do inglês bias – “bias”), neste caso, tendo o valor -1, e as variáveis x1 e x2, que podem assumir valores 1 ou 0. A verdade tabela para “AND lógico” provavelmente é muito familiar:
Lembre-se de que o perceptron adiciona ponderadamente todos os sinais que chegam às suas entradas e, se o resultado for positivo, ele emite um através do canal de saída e zero se a soma for menor ou igual a zero. Os pesos neste caso são +1 para ambos os argumentos (w1 e w2); esses próprios argumentos (x1 e x2) assumem o valor 1 ou 0. Assim, a operação do perceptron para cada linha da tabela verdade ficará assim:
–
–
–
–
Pelo mesmo princípio, mas usando conjuntos de pesos diferentes, os perceptrons se transformam em portas lógicas OR, NOT, NOR ou NAND, sendo que apenas XOR e XNOR exigem a adição de uma segunda camada com pesos apropriados, que compensarão os erros decorrentes da incapacidade para levar em conta relações mais complexas de parâmetros individuais e elementos do modelo que está sendo estudado pela máquina.
⇡#Quanto pesar em gramas?
Para obter portas lógicas básicas, os perceptrons são fáceis de configurar manualmente, selecionando os pesos literalmente a olho nu. Por exemplo, se, de acordo com o esquema que acabamos de descrever, tentarmos implementar o “OR-NOT lógico” (NOR) com a constante de normalização anterior b = -1, obteremos uma resposta incorreta já na primeira linha do tabela verdade. Afinal, o resultado de 0 NOR 0 deve ser um, e temos:
–1 +0 * w1 + 0 * w2 = –1,
Ou seja, a saída do perceptron será 0. Portanto, precisamos alterar b para +1 e, em seguida, selecionar os pesos sinápticos apropriados w1 e w2, verificando cuidadosamente a tabela verdade – eles serão -1 cada.
Um princípio ilustrativo de operação de uma rede multicamadas de perceptrons que identifica um objeto por um sinal separável (implicando uma clara dicotomia, a resposta é “sim – não”): um gato ou um cachorro? (fonte: Techaroha)
É óbvio, porém, que a abordagem manual funciona apenas para os circuitos mais simples que implementam as operações básicas da lógica matemática. Um perceptron pode ter dezenas e centenas de entradas (um neurônio biológico, lembre-se, pode ter milhares delas), e a própria máquina deve ajustar os pesos sinápticos em cada uma delas, começando apenas se o operador confirmar o resultado da próxima tentar reconhecer a imagem desejada na saída (ou resolver outro problema enfrentado pelo neurossistema) – ou não. Como tudo isso é feito na prática?
Para isso, de fato, perceptrons multicamadas (perceptron multicamadas, MLP) foram inventados, operando com base no princípio da retropropagação de erros. Suas variedades mais simples são as mini-redes neurais de duas camadas já mencionadas um pouco acima para implementar os operadores lógicos XOR e XNOR. Auto-aprendizagem (mais precisamente, tendo a capacidade de efetivamente auto-corrigir pesos sinápticos) MLPs consistem em muitas camadas com um número significativo de neurônios artificiais em cada uma, e as saídas dos perceptrons da camada anterior (análogos funcionais dos processos em o axônio de um neurônio biológico) servem como entradas para os próximos perceptrons. Na verdade, quando os especialistas em neurocomputação falam sobre aprendizado profundo, isso não é uma bela metáfora, mas uma indicação completamente pragmática de que o número de camadas ocultas em uma rede neural excede duas.
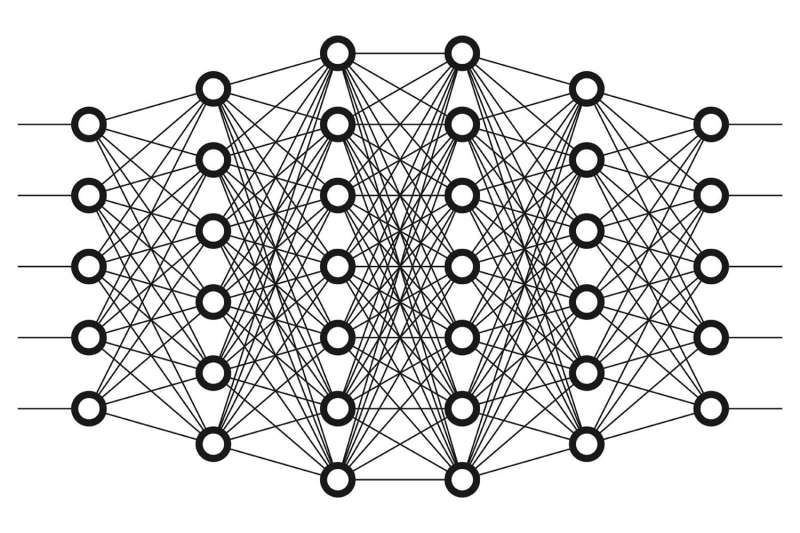
«Deep Learning” envolve o uso de uma rede neural multicamadas (fonte: Wikimedia Commons)
De um modo geral, essa rede já é um modelo decente do córtex cerebral – pelo menos para a implementação de várias tarefas especializadas, é perfeitamente adequada. Inicialmente, é claro, o MLP é puro – no sentido de que os pesos sinápticos nas entradas de seus perceptrons elementares em cada camada são aleatórios e, portanto, o sistema como um todo não é capaz de nenhuma ação efetiva. No entanto, no decorrer do aprendizado supervisionado, o sistema é exposto a longas séries de objetos rotulados como pertencentes a determinadas classes. Como resultado desse treinamento, o sistema começa a classificar objetos que não havia encontrado antes com uma precisão muito alta, de forma totalmente independente.
O significado do termo “retropropagação de erro” aplicado a um sistema neural de autoaprendizagem é exatamente como ele corrige as imprecisões feitas no curso do reconhecimento de padrões. O próprio conceito de “reconhecimento de padrão” é usado aqui o mais amplamente possível: o MLP pode perceber ou sintetizar a fala humana, criar uma imagem gráfica com base em uma descrição de texto ou identificar uma determinada pessoa em uma multidão de milhares em um quadro de vídeo.

Uma imagem gerada pela rede neural Imagen usando a frase “Três esferas feitas de vidro caindo no oceano” como entrada. A água está espirrando. O sol está se pondo” (Fonte: Google)
Em todos esses casos e em outros semelhantes, o neurossistema compara um objeto específico e um grupo generalizante ideal (“classe”). O animal retratado nesta imagem pode ou não ser classificado como cão; o fonema reproduzido pelo eletrossintetizador pode ou não pertencer à classe “fala humana natural”, e assim por diante. A avaliação “sim ou não”, “aplica-se ou não aplica-se” no processo de aprendizagem sob supervisão é definida pelo operador biológico, e o sistema – se esta avaliação não for positiva – altera os pesos sinápticos repetidas vezes em uma camada após o outro, começando pelo mais distante da entrada, para finalmente obter a confirmação.
Este procedimento pode ser representado da seguinte forma:
A) os pesos sinápticos em todas as camadas são dados por números aleatórios que são pequenos em valor absoluto,
B) O MLP é iniciado por um conjunto de dados de entrada, que então passa por todas as camadas, e um determinado resultado é formado na saída,
C) o observador avalia o resultado e o devolve à máquina; Com base na comparação do resultado obtido com o desejado, determinam-se os gradientes da função perda para cada um dos pesos,
D) os vetores desses gradientes indicam a direção de crescimento da função perda; consequentemente, na direção oposta, diminui – e os pesos são ajustados de forma que na próxima iteração a função de perda, presumivelmente, se torne menor,
E) MLP é acionado novamente com o mesmo conjunto de entradas, e se a diferença entre o resultado e o ideal for menor que da última vez, os pesos sinápticos são novamente ajustados na mesma direção, caso contrário, os gradientes da função de perda são recalculados,
F) e assim sucessivamente até que a diferença entre o resultado produzido pela rede neural e o ideal se torne, na opinião do estagiário, menor que algum valor obviamente aceitável.
⇡#Se você olhar para os três por um longo tempo
Aqui está um exemplo de uma explicação bastante detalhada, mas essencialmente simples, dos princípios do aprendizado profundo, propostos pelos especialistas do Instituto de Engenheiros Elétricos e Eletrônicos (Instituto de Engenheiros Elétricos e Eletrônicos, IEEE). Aqui está uma rede neural multicamada convencionalmente representada aprendendo a reconhecer o número manuscrito “3”:
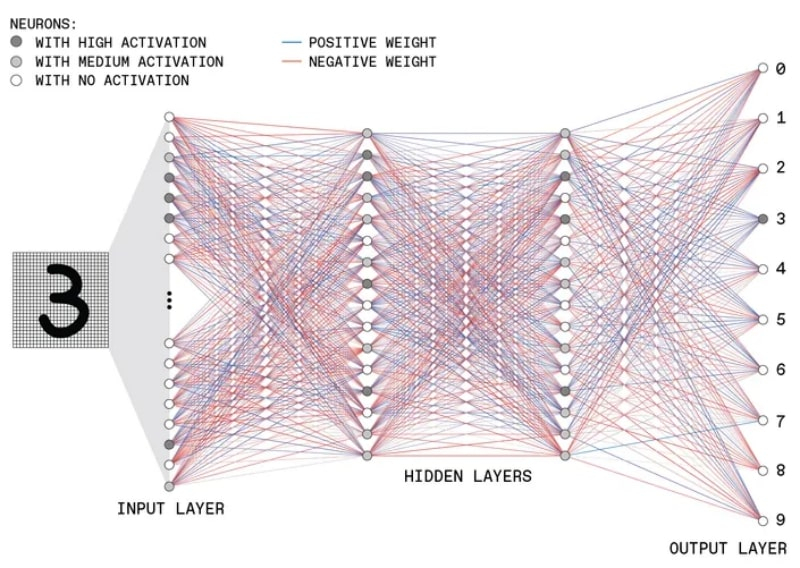
O esquema geral do MLP com duas camadas ocultas que reconhece dígitos manuscritos. O tom de cinza nos círculos indica a magnitude do sinal de saída de cada módulo perceptron, a cor da linha (azul ou vermelha) indica seu sinal: com mais, será levado em consideração, respectivamente, ou com menos (fonte: IEEE)
A entrada MLP recebe uma imagem pixelada e cada pixel é processado por um perceptron separado da primeira camada. Em seguida, os sinais de saída desses perceptrons são transmitidos para a profundidade. Os perceptrons da última camada fornecem uma “decisão de solidariedade” de todo o sistema como um todo: que tipo de figura manuscrita estava na entrada. A resposta neste caso deve ser “3”, e é assim que uma rede neural profunda chega a isso:
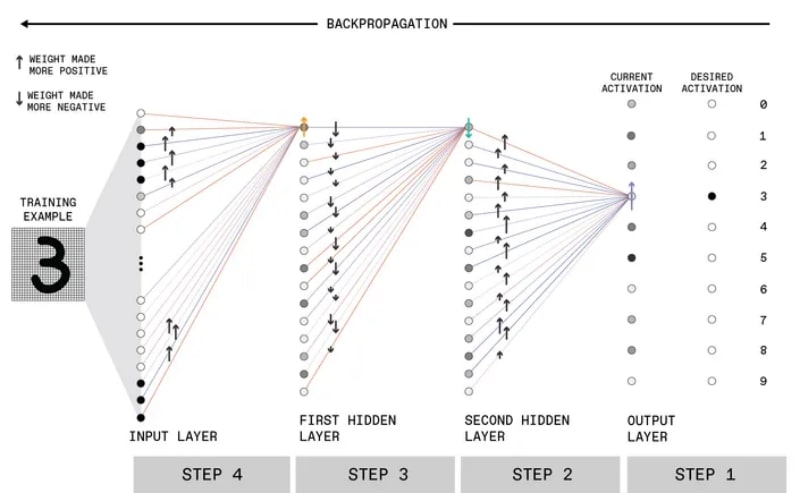
O mesmo esquema, mas com ênfase em quais sinais da camada anterior ativam apenas um perceptron no futuro e como, com base na análise desses sinais, o erro é retropropagado (fonte: IEEE)
No primeiro passo (está na extrema direita, pois é necessário construir a correspondência da saída feita pela rede com a resposta esperada), os pesos aleatórios com os quais as conexões sinápticas foram inicialmente iniciadas levaram a um pouco previsível resultado: a rede neural decidiu que o número “5” na imagem (o círculo cinza mais escuro na coluna de ativação atual).
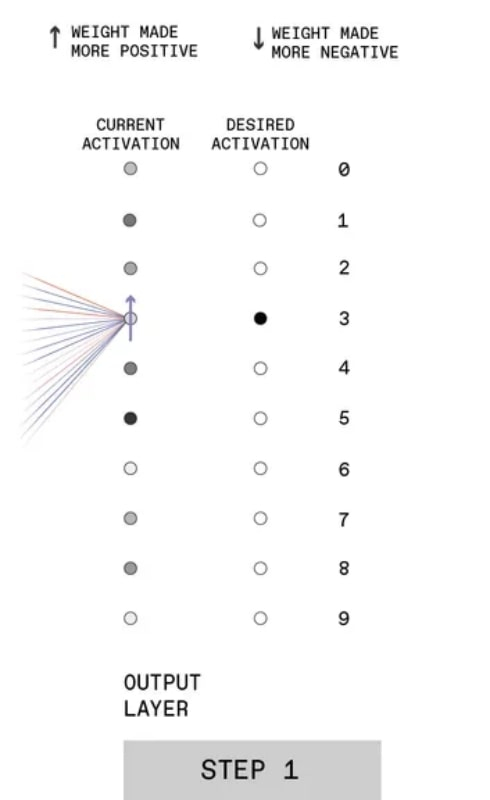
A primeira etapa do BP para mais detalhes, veja as explicações no texto (fonte: IEEE)
Em resposta, o experimentador informa ao MLP sobre o erro aumentando os pesos das conexões sinápticas levando ao valor “3” na camada de perceptrons mais próxima a ele. Aqui é importante prestar atenção às diferenças de tons de cinza: os neurônios artificiais operam com um princípio ligeiramente diferente dos biológicos.
Se a soma dos sinais de entrada recebidos das conexões sinápticas (levando em consideração os pesos) for menor que um determinado valor limite, não há sinal na saída do perceptron – isso é totalmente consistente com o comportamento de um neurônio no cérebro. No entanto, após superar o limiar de ativação, um neurônio vivo gera impulsos elétricos (estrobos) de amplitude aproximadamente igual, embora às vezes em grupos densos se o nível de estimulação for alto.
O perceptron, se a condição para sua operação for atendida, produz um sinal igual em magnitude à soma ponderada dos sinais de entrada – na verdade, ele atua como um transmissor de soma seletiva. É por isso que o valor do sinal de saída do perceptron na camada atual dá uma ideia clara da influência dos neurônios artificiais da camada anterior sobre ela – o que cria a base para o ajuste fino da rede neural para resolver esse problema específico problema.
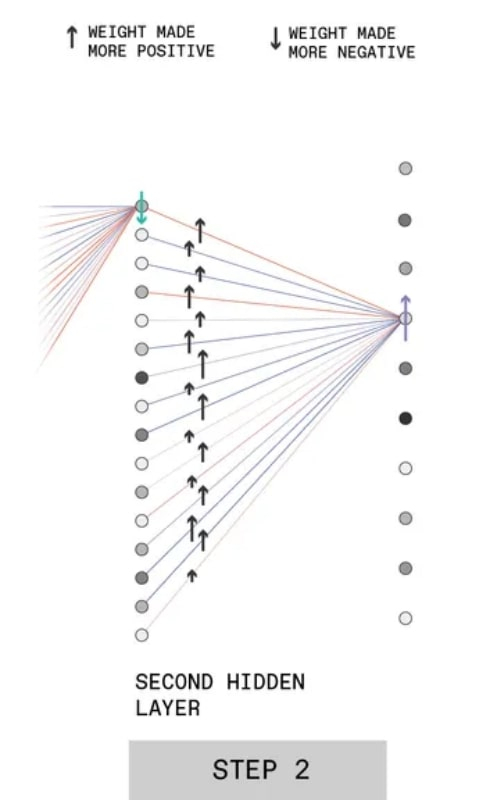
Segundo passo BP, veja o texto para explicação (fonte: IEEE)
A segunda etapa é a própria retropropagação do erro (seria mais correto dizer “sinal de erro”), que está implícita no termo retropropagação. As conexões sinápticas que conduzem dos perceptrons da penúltima camada ao que é responsável pela formação da resposta “3” nesta última recebem um comando para corrigir os pesos para cima. Ao mesmo tempo, quanto maior o valor inicial de cada peso dado (quanto mais escuro o círculo no diagrama denotando o perceptron), mais forte o peso da conexão com ele aumenta em uma certa proporção (isso indica o comprimento da seta na linha correspondente).
Por qual fórmula específica esse cálculo é feito não é importante para fins de entendimento geral. É importante que esta seja precisamente a fórmula (a mesma função de perda que foi mencionada um pouco antes), que se presta perfeitamente à programação e, portanto, ao impacto manual do operador biológico no sistema nesta etapa, bem como em todas subseqüentes, não é necessária. A rigor, se os cartões de treinamento forem inicialmente rotulados (junto com o trio manuscrito, o MLP recebe uma mensagem legível por máquina “3”, com a qual o resultado do reconhecimento é comparado no final), a rede neural não precisará de um operador para treinamento em tudo – pelo menos para tarefas desta classe.
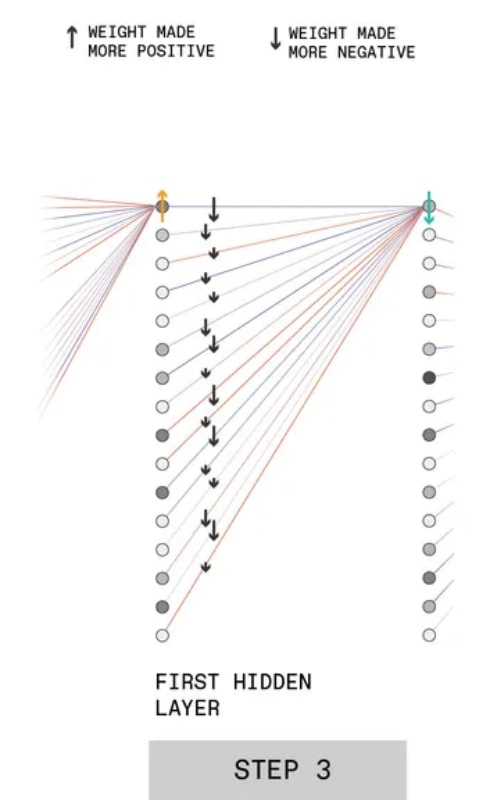
Terceiro passo BP, veja o texto para explicação (fonte: IEEE)
Na terceira etapa, mostra-se como se reduz a significância para a formação da resposta final daqueles perceptrons, cuja contribuição para a formação da solução “3” é negativa. Por exemplo, o perceptron superior na segunda camada oculta é obtido: digamos que sua influência precise ser reduzida (seta verde para baixo). Para isso, aplica-se o mesmo procedimento do passo anterior, porém com sinal contrário: quanto maior a contribuição do próximo perceptron da primeira camada oculta para a ativação deste neurônio artificial, mais forte (em módulo) será a ação corretiva vai ser.
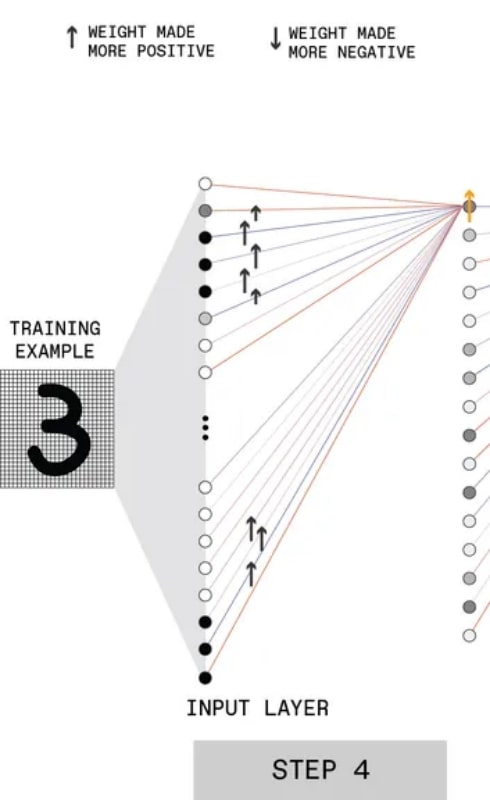
Etapa final neste ciclo de retropropagação, veja o texto para explicação (Fonte: IEEE)
Exatamente da mesma forma, os pesos são corrigidos para conexões sinápticas de neurônios artificiais da primeira camada oculta com perceptrons externos que percebem diretamente a imagem de treinamento dividida em pixels.
⇡#Sutilezas de percepção
Pode parecer que o desenvolvimento das redes neurais ocorreu de forma linear e progressiva. De jeito nenhum: em 1969, Marvin Minsky e Seymour Papert publicaram o livro Perceptrons: An Introduction to Computational Geometry, no qual criticaram duramente o escopo limitado dos neurônios artificiais de Rosenblatt – citando, em particular, o exemplo que consideramos com XOR. Somente no início da década de 1980, a tecnologia de computação de von Neumann havia se desenvolvido tanto que tornou possível modelar estruturas lógicas complexas (incluindo redes neurais multicamadas com retropropagação de erros), e isso levou a um novo florescimento da direção do neurocomputador.

O treinamento supervisionado do Watson Health baseia-se na experiência de vários profissionais de saúde (fonte: IBM)
No entanto, ainda hoje esta área ainda tem, para dizer o mínimo, onde se desenvolver – apesar de todos os sucessos objetivos alcançados pelos desenvolvedores de redes neurais. Basta citar o projeto Watson Health, no qual a IBM investiu bilhões de dólares ao longo dos anos. Este projeto visava revolucionar a ciência médica, poupando os cientistas da necessidade de vasculhar pessoalmente dezenas e centenas de artigos com estudos relevantes para encontrar informações realmente valiosas e importantes para o tratamento de pacientes específicos.
A tarefa parecia simples – especialmente porque após a vitória do supercomputador Watson no programa de perguntas e respostas da TV americana Jeopardy (conhecemos essa franquia como “Quem quer ser um milionário?”) Em 2011, ficou óbvio o quão bem a máquina é capaz para responder a perguntas, cujas respostas já foram encontradas e registradas em forma de texto. A equipe de desenvolvimento do Watson (10 racks de 10 servidores IBM Power 750, além de dezenas de milhares de linhas de código que formam uma rede neural multicamada virtual) teve uma ideia brilhante: e se aplicarmos esse poder de pesquisa a uma enorme quantidade de pesquisas científicas? artigos sobre temas médicos que já foram publicados e continuam se acumulando a cada mês?

Servidores de rack Power 750 que se tornaram a base de hardware para a rede neural do software Watson Health (Fonte: IBM)
O projeto Watson Health, lançado em 2015, tinha como objetivo buscar artigos científicos e comparar sintomas de doenças, por um lado, e recomendações para sua cura, por outro. Idealmente, isso permitiria fazer um diagnóstico correto online: bastaria que o médico assistente (mesmo sem formação altamente especializada) enviasse ao sistema os sintomas por ele registrados no paciente, bem como os resultados das análises e outros estudos especiais. A rede neural, por outro lado, determinaria automaticamente a doença com base nesse conjunto de entradas – e procuraria o melhor remédio para ela no momento (incluindo os recém-lançados e até experimentais) e métodos de tratamento. E tudo isso é baseado em um extenso banco de dados de revistas médicas, reabastecido com milhares de artigos apenas em inglês todos os meses.
No entanto, não deu em nada e, no início de 2022, a IBM decidiu vender o Watson Health para uma empresa de private equity, a Francisco Partners. Descobriu-se que a rede neural é realmente capaz de processar centenas de milhares de artigos sem muita dificuldade. Mas, ao contrário do jogo Jeopardy, as perguntas médicas nem sempre têm respostas obviamente precisas. Diferentes cientistas e diferentes escolas científicas podem interpretar o mesmo fenômeno à sua maneira. Muitos (infelizmente, muitos) artigos acabaram sendo baseados em dados incompletos, mal verificados ou simplesmente falsos.

Uma imagem gerada pela rede neural Imagen usando a frase “Uma caneca de morango cheia de sementes de gergelim branco. A caneca está flutuando em um mar de chocolate amargo” (Fonte: Google)
Um especialista biológico experiente em um determinado campo de conhecimento é capaz, se não reconhecer imediatamente um artigo sem valor, pelo menos duvidar – com base no conhecimento e na experiência acumulados – da validade das conclusões feitas pelo autor. Uma rede neural não sabe como e, portanto, a aplicação prática do Watson Health acabou não sendo mais útil do que um diagnóstico médico de um não especialista que assistiu a algumas temporadas de House e foi capaz de formular consultas para uma pesquisa popular motor.
E mesmo que você se proponha a alimentar as redes neurais exclusivamente com trabalhos científicos corretamente organizados e verificados por veneráveis especialistas, isso não se tornará uma garantia do funcionamento ideal da “inteligência” da máquina. O fato é que as redes neurais perceptron profundas (multicamadas) são fundamentalmente vulneráveis a erros na qualidade da aproximação (bondade do ajuste) e dois tipos ao mesmo tempo: subajuste e superajuste (subajuste e superajuste, respectivamente).
⇡#O que é subadaptação e superadaptação
A rede neural se auto-organiza ajustando os pesos nas entradas sinápticas dos perceptrons em suas camadas para melhor reconhecer o conjunto de dados de treinamento e, então – com o mesmo conjunto de pesos – tenta classificar dados completamente novos para si. A subadaptação e a superadaptação são dois extremos nos quais, infelizmente, é extremamente fácil cair.
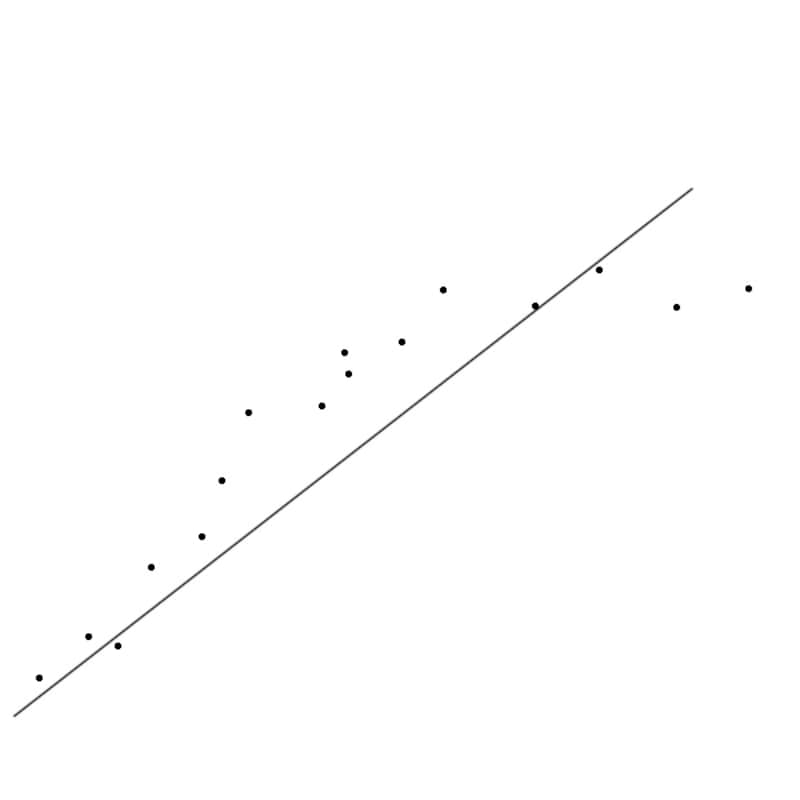
Underfitting: O modelo é muito simples para explicar adequadamente a natureza da distribuição de dados (fonte: University of New South Wales)
A subadaptação ocorre se o modelo construído pela rede neural (um conjunto de pesos sinápticos em cada camada) for muito simples. Um modelo simples geralmente descreve quase tudo – mas com um desvio significativo da previsão da observação em cada ponto específico. Quase qualquer conjunto de pontos experimentais pode ser aproximado por uma linha reta para uma primeira aproximação, mas é improvável que o valor das previsões feitas com base em um modelo tão trivial seja grande:

Overfitting: o modelo reproduz todos os pontos no conjunto de dados experimental (Fonte: University of New South Wales)
A readaptação, ao contrário, se deve à excessiva fixação do modelo nos detalhes. Como resultado, o objeto de teste será perfeitamente reconhecido pela rede neural, mas se você alterá-lo um pouco – por exemplo, girar a imagem apenas alguns graus – o sistema não poderá mais “reconhecê-lo”.
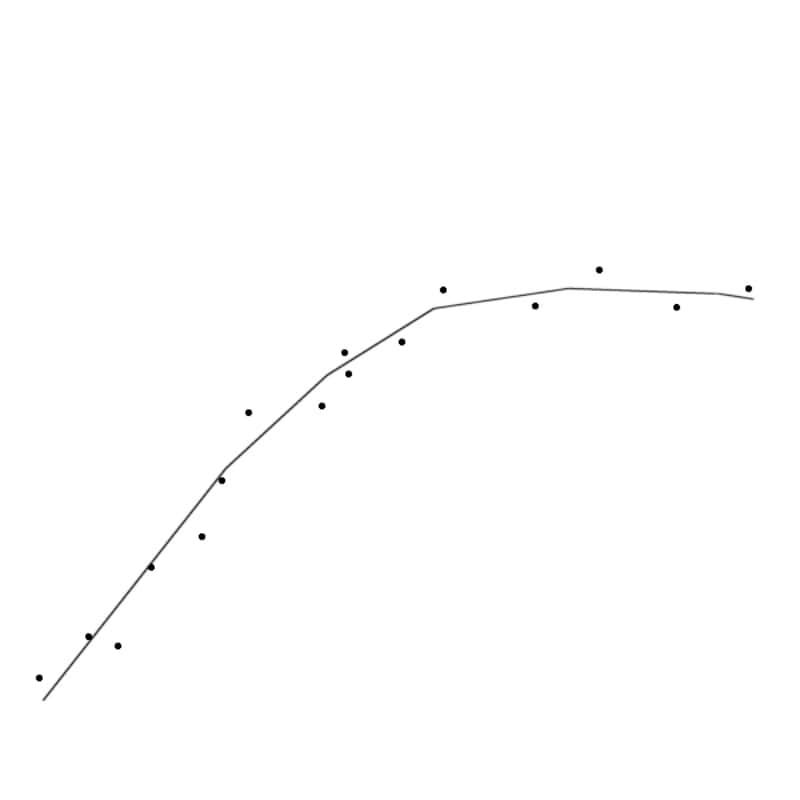
Um MLP corretamente treinado aproxima os experimentos anteriores de maneira otimizada e torna possível prever adequadamente os resultados dos futuros (fonte: University of New South Wales)
Os desenvolvedores de redes neurais se esforçam para otimizar seu design e o processo de aprendizado, a fim de evitar a adaptação insuficiente ou excessiva. Idealmente, o modelo de objeto formado pela combinação do projeto MLP com um conjunto de pesos sinápticos deve explicar adequadamente a variação inevitável das medições reais.
E embora um progresso considerável seja óbvio nessa direção de desenvolvimento de redes neurais, o princípio de tomar certas decisões, incompreensíveis para a mente humana, continua sendo uma mancha negra em sua reputação. Sim, os valores exatos dos pesos sinápticos para cada perceptron em cada camada da rede neural treinada são conhecidos pelos programadores que o treinam. Mas eles não têm um significado claramente explicável – e, portanto, o trabalho do MLP continua sendo uma “caixa preta”, o que em muitos casos é simplesmente inaceitável.
Uma coisa é quando não está muito claro por quais critérios a máquina classifica com precisão as fotos de cães e gatos: ela o faz – e bem. É completamente diferente quando determina o que fazer para um carro autônomo, no cruzamento em frente ao qual um ciclista saltou repentinamente sob um sinal vermelho para si mesmo: aqui já quero muito mais certeza nas motivações – elas seriam extremamente úteis para o companhia de seguros e a possível investigação.
É por isso que a direção de redes de nêutrons explicáveis tem se desenvolvido tão ativamente nos últimos anos, cuja lógica de decisões pode ser explicitamente controlada. Além disso, torna-se possível rejeitar decisões obviamente inaceitáveis se contradizem certos princípios iniciais. Aqui, mesmo antes da implementação prática das leis da robótica de Asimov, parece, não muito longe, mas até agora não há fim para o trabalho de programadores e engenheiros.

Neurônios artificiais como este protótipo baseado em materiais de mudança de fase criados pela IBM em 2016 podem formar a base para redes neurais ainda mais eficientes (fonte: IBM)
Modelar redes neurais na memória das máquinas de von Neumann é um prazer caro em muitos parâmetros. Seria mais prático implementá-los em uma base de hardware mais próxima em eficiência energética ao tecido nervoso biológico. Mas isso ainda é uma questão para um futuro distante, mas por enquanto, mesmo com base em elementos semicondutores, as redes neurais jogam na bolsa de valores com mais eficiência do que um corretor médio, cozinham batatas fritas e rodelas de cebola melhor do que um chef habilidoso e até crie fotos e videoclipes, a partir de descrições de texto (por exemplo, “o urso de pelúcia lava a louça). É só o começo!