
Não é segredo que não existe uma única arquitetura de computação ideal. Diferentes tipos de tarefas e cenários dão origem a diferentes tipos de cargas de trabalho que diferentes processadores manipulam de maneiras diferentes. Programar para toda essa variedade é muito difícil, e é por isso que a Intel assumiu a tarefa de criar um modelo de desenvolvimento unificado dentro do projeto oneAPI, cujo primeiro grande lançamento foi lançado outro dia.
Arquitetura Intel oneAPI
À medida que as tecnologias de computação e TI penetram em todas as áreas da vida, mais e mais novos tipos de cargas nascem. Por exemplo, o suporte para formatos de inteiros do tipo INT8 recentemente se tornou muito popular para tarefas de aprendizado de máquina, onde a precisão alcançada no formato FP64 pode ser sacrificada para velocidade e eficiência. Os processadores estão sendo “carregados” com novas instruções, novas classes inteiras de dispositivos de computação aparecem – e sobre todos eles surge a questão de como escrever software de maneira eficaz para tudo isso.
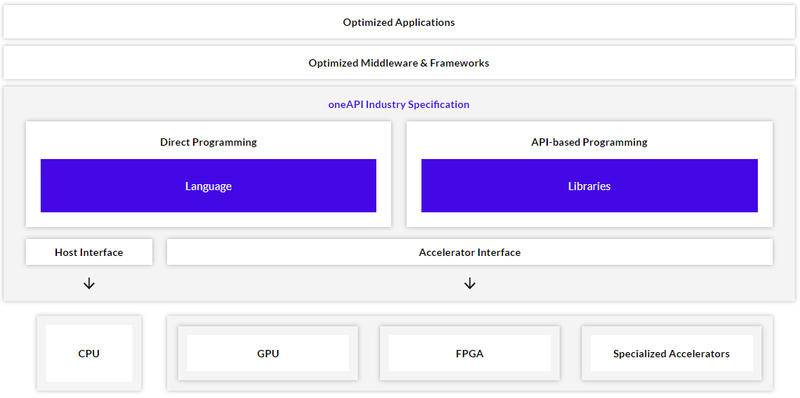
Muitos veem a resposta na criação de camadas intermediárias unificadas, como o VMware recentemente mencionado com seu Projeto Monterey. A Intel tem uma visão semelhante com seu projeto oneAPI. Este desenvolvimento é uma plataforma de software unificada e aberta que permite abstrair da arquitetura de hardware de dispositivos e escrever código que usa todos os recursos de computação disponíveis, sejam CPU, GPU, DPU ou outros. A oneAPI é baseada na linguagem DPC ++ que, por sua vez, é baseada nos padrões C ++ e Kronos SYCL.
Uma API para controlar todos (tipos de computação)
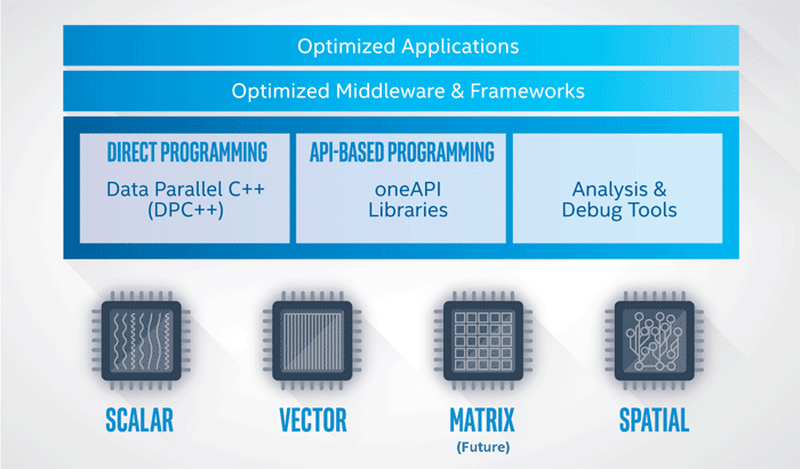
O mundo conheceu o oneAPI pela primeira vez no final de 2018 e hoje o projeto atingiu um marco importante: a empresa anunciou oficialmente o lançamento do oneAPI 1.0. O projecto, como já foi referido, tem especificações em aberto, que se encontram na secção correspondente do site dedicado a umaAPI; a novidade também tem seu próprio repositório no GitHub. OneAPI inclui bibliotecas principais, um compilador DPC ++ baseado em LLVM / Clang, várias bibliotecas de desempenho Intel e ferramentas de depuração e análise de código.
Também é importante que o projeto inclua uma ferramenta de migração de código escrito em CUDA – assim, todo o patrimônio de software desenvolvido para aceleradores NVIDIA pode ser disponibilizado para outras plataformas. A riqueza de bibliotecas para a criação de aplicativos usando aprendizado de máquina e análise merece uma menção separada: oneDNNL, uma biblioteca de processamento de vídeo e outras. Você também pode experimentar um API em uma área restrita de nuvem especial, implantada pela Intel especificamente para desenvolvedores interessados em novos métodos de desenvolvimento de software.
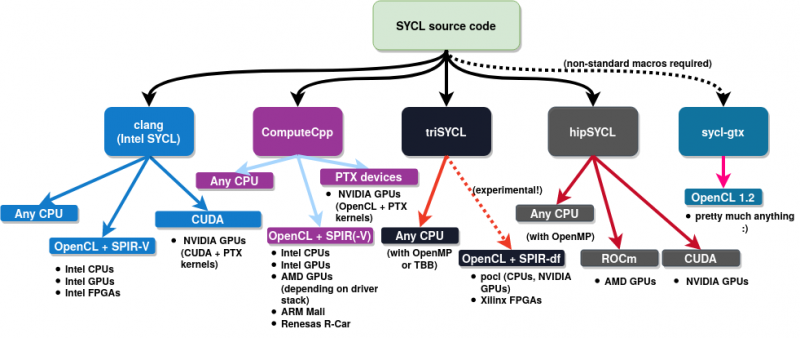
Como a plataforma em si e a infraestrutura LLVM subjacente são abertas, é relativamente fácil estender os recursos de uma API, que é o que várias organizações estão fazendo. Por exemplo, Codeplay está trabalhando na compatibilidade com NVIDIA, o centro URZ está ocupado adicionando extensões DPC ++ ao projeto hipSYCL, que funciona com qualquer CPU (OpenMP), NVIDIA GPU (CUDA) e AMD Radeon (HIPC / ROCm). E algumas bibliotecas da própria Intel já têm suporte para ARM e POWER. A Intel também tem bases para seus próprios FPGAs, mas o Xilinx parece ter sido deixado de fora por enquanto. Este último, porém, tem uma visão própria do processo de desenvolvimento.