
Também há cada vez mais imagens geradas na Internet todos os dias – mas é difícil encontrar entre elas as realmente interessantes que capturam a imaginação; algo que deixaria alguém seriamente preocupado com as perspectivas de preservação da própria profissão de artista para formas biológicas de vida não é tão simples. Sim, as capacidades da IA generativa em termos de extrair imagens do espaço latente são grandes, mas a atratividade do ponto de vista humano do que é extraído daí resume-se essencialmente à capacidade do mesmo operador biológico de usar o que foi extraído. desenvolvido até agora (suas contrapartes proteicas), aliás) ferramentas.
Nem estamos falando da arte da engenharia imediata em si: compreender o potencial e as limitações do ponto de verificação escolhido para gerar é igualmente importante; a capacidade de avaliar como a ativação de um determinado LoRA ou inversão de texto afetará a imagem criada; disponibilidade de informações sobre meios adicionais de melhorar a qualidade da imagem, como as contratações que analisamos anteriormente. consertar, ADetalier e muito, muito mais. Além disso, a graça da Fortuna desempenha um papel enorme: o mesmo conjunto de parâmetros, executado com sementes diferentes e/ou uma combinação de CFG e o número de etapas de geração, às vezes gera imagens de qualidade surpreendentemente diferente. Então, pode-se perguntar, como pode o operador de um modelo generativo de IA competir com um verdadeiro profissional das artes plásticas, que – embora com reservas em termos de seu talento individual, diligência e outras características puramente humanas – é capaz de produzir imagens de forma confiável de mérito artístico consistentemente elevado?

E nem essas imagens podem ser capturadas do abismo do espaço latente, usando a extensão Dynamic Prompts discutida neste artigo (fonte: geração de IA baseada no modelo SD 1.5)
O problema é agravado pela amplitude ilimitada de capacidades dos modelos modernos de IA para desenho: se o sistema é capaz de retratar, senão tudo, mas muito, incluindo reproduzir o estilo dos melhores artistas biológicos, em cujo trabalho (entre outras coisas ) foi treinado, o que exatamente ele precisa de algo para que a imagem saia realmente de tirar o fôlego? Infelizmente, a julgar pela galeria atualizada regularmente das obras mais populares no mesmo site Civitai, os tópicos das dicas fornecidas aos modelos generativos são praticamente limitados a meninas com vários graus de vestimenta, gatos com chapéus engraçados e paisagens sombrias. Ocasionalmente, porém, aparecem robôs. O crescimento na diversidade de imagens geradas por IA também não é ajudado pelo fato de que a Stable Diffusion (e, em uma extensão um pouco menor, projetos comerciais de código fechado como Midjourney ou Dall-E) acham difícil representar adequadamente imagens de múltiplas figuras. composições e cenas dinâmicas. Eles prometem que o próximo (super)modelo SD 3 fará isso melhor, e os pontos de verificação já disponíveis são bem auxiliados por ferramentas de composição adicionais – como a extensão Tiled Diffusion que analisamos anteriormente.
⇡#E eles não podem ficar juntos
No entanto, na grande maioria dos casos, os modelos generativos para desenho de IA funcionam melhor para retratos, paisagens, naturezas mortas – em suma, imagens com uma composição extremamente estática. Assim que você solicita algo menos trivial ao sistema, começam as dificuldades. “Trivialidade”, é claro, é um conceito relativo – vamos ilustrá-lo com um exemplo claro.
E vamos usar o ponto de verificação CyberRealistic v para implementar este exemplo. O 4.2 é um dos melhores do momento (a julgar pela qualidade das gerações que ilustram a sua utilização) em termos de realismo entre todos aqueles baseados no SD 1.5. A propósito, com este modelo eles propõem usar inversões de texto especialmente otimizadas para dicas negativas – CyberRealistic Negative v. 1.0 e CyberRealistic_Negative_v3 (por algum motivo, o segundo só está disponível no HuggingFace, não no Civitai, mas isso não é um problema: eles são igualmente fáceis de baixar de ambas as fontes).
Primeiro, vamos verificar o quão justificado é usar essas duas inversões juntas – é exatamente assim que o autor do ponto de verificação as usa nos exemplos que o ilustram. Uma ferramenta adequada como parte do ambiente de trabalho AUTOMATIC1111, da qual trataremos novamente desta vez, é o script “Plotagem X/Y/Z”, já bem conhecido dos leitores de longa data dos nossos “Workshops”, ou mais precisamente, o script “Prompt S/R” em sua composição – e esta é a linha de substituições:
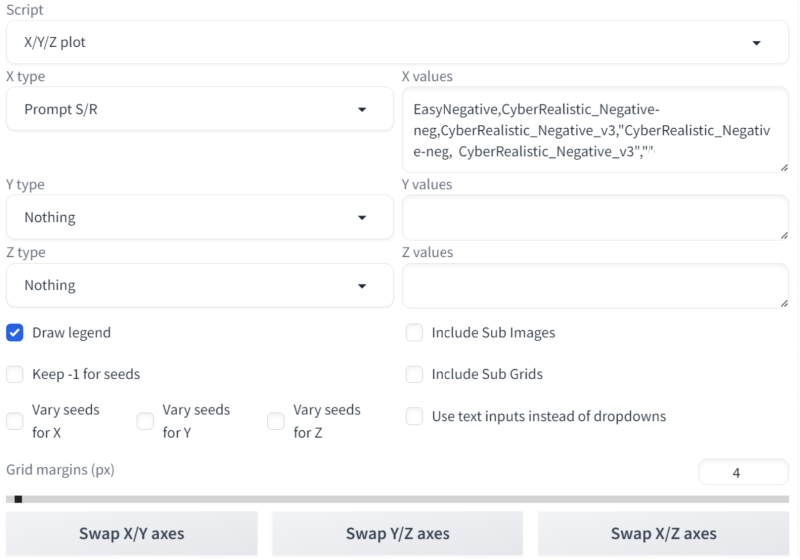
Então, definimos uma dica positiva como esta:
Retrato de um paladino robusto e bonito, cabelo macio, musculoso, meio corpo, masculino, maduro, cabelo grisalho, couro, peludo, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, ilustração
Negativo, como foi dito, simplesmente
FácilNegativo
Escolhemos como modelo “SD VAE”, padrão para quase todas as nossas gerações com os “Lortorka” vae-ft-mse-840000-ema-pruned.safetensors; defina o controle deslizante “Clip skip” para a posição “2”, defina o “Método de amostragem” para “DPM++ 3M SDE Karras” (rápido e ao mesmo tempo de alta qualidade, lembre-se), deixe o valor “Etapas de amostragem” ser “35 ”, “Escala CFG” – “7”. Com a semente 85989958 obtemos isto:

Fonte: geração de IA baseada no modelo SD 1.5
Como você pode ver, mesmo com um campo de dica negativa completamente vazio, este ponto de verificação produz uma imagem bastante decente: talvez mais uma reminiscência de uma ilustração realista ou renderização 3D (especialmente em termos de destaques na pele, que claramente carece de dispersão de subsuperfície adequada), mas ainda. Tal é o poder dos postos de controle modernos e diligentemente treinados! Observe também que a longa e amplamente usada inversão de texto EasyNegative por si só fornece uma exibição completamente aceitável de pele e cabelo; Em comparação, é difícil dizer que CyberRealistic_Negative – ambas as versões 1 e 3 – definitivamente vence. Mas – pelo menos do ponto de vista subjetivo – a combinação das duas últimas inversões fornece precisamente a aproximação mais digna do retrato ao realismo em todos os aspectos – traços faciais, exibição de cabelo e pele, roupas feitas de materiais diferentes, fundo, etc. Vamos nos concentrar nesta combinação de inversões de texto em um campo negativo por enquanto – precisaremos dela mais tarde.
Na verdade, íamos demonstrar a fraqueza do modelo SD 1.5 em termos de composições multifiguradas. Isso é extremamente fácil de fazer com esta dica positiva:
Foto grande angular de (panda chinês) lutando ferozmente com (águia careca americana), fantasia, intrincada, elegante, altamente detalhada, pintura digital, arte conceitual, foco suave e nítido, ilustração
A dica negativa, lembremos, é “CyberRealistic_Negative-neg, CyberRealistic_Negative_v3”; Desta vez faremos a tela paisagem (768 × 512 pixels – dimensões padrão para lados SD 1,5 do retângulo base). Deixe todos os outros parâmetros permanecerem iguais, apenas defina o valor “-1” no campo “Semente”, especificando assim uma escolha aleatória de semente. E com seu valor, por exemplo, 485257449 obtemos isto:

Fonte: geração de IA baseada no modelo SD 1.5
Vamos prestar atenção aos “direitos autorais” e “assinatura do autor” nos cantos inferiores esquerdo e direito: sem adicionar explicitamente “marca d’água, logotipo, assinatura” e outros termos semelhantes à dica negativa, tais artefatos aparecerão com bastante frequência, uma vez que um número significativo Parte do material para o treinamento do Stable Diffusion era fornecido apenas com assinaturas de artistas ou logotipos de diversas franquias, por exemplo. E, no entanto, não é isso que chama a atenção principal se compararmos o quadro com a pista que lhe deu origem: aqui não há águias suficientes, não acham? E não é por acaso: no modo “Gerar para sempre”, tendo recebido cerca de uma centena e meia de imagens com esta dica, ainda não vimos uma única águia. Ok, vamos trocar os animais:
Foto grande angular de (águia americana) lutando ferozmente com (panda chinês), fantasia, intrincada, elegante, altamente detalhada, pintura digital, arte conceitual, foco suave e nítido, ilustração

Fonte: geração de IA baseada no modelo SD 1.5
E aqui, não só a águia está no lugar, mas o panda de repente tem garras e um bico. E esse lixo, acredite (ou melhor ainda, verifique; felizmente, mesmo em nossa máquina de teste com uma placa de vídeo GTX 1070 de 8 Gb, cada imagem é gerada em 6 a 7 segundos, não mais), continuará e continuará. Ocasionalmente, você encontrará pandas com asas de águia e águias com patas de urso, e somente se você tiver muita sorte, a imagem sairá mais ou menos adequada – se não para uso direto, pelo menos para processamento não muito tedioso no acabamento do desenho (usando o método inpainting na aba “img2img” “) ou em um editor gráfico externo. Isso, na verdade, é uma evidência direta de quão difícil é para o “Lortorka” – ou melhor, até mesmo para os mais modernos postos de controle baseados no modelo SD 1.5 – lidar com composições de apenas dois dígitos.
⇡#Vamos traçar uma linha
Não será possível, no entanto, como fizemos mais de uma vez nos nossos últimos “Workshops” sobre o tema do desenho de IA, transformar esta doença em algo útil? Sim, claro: o desejo do modelo generativo de fundir entidades díspares mencionadas na dica dada beneficiará prontamente o artista de IA – gerando quimeras de aparência bastante convincente, que nem todo pintor habilidoso consegue retratar imediatamente.
Na documentação AUTOMATIC1111, uma seção inteira sobre termos alternados, palavras alternadas: a sintaxe é dedicada à criação quimérica
[Panda|águia]
Força o modelo a alterar o objeto alvo em cada etapa (cujo número, lembre-se, é determinado pelo parâmetro “Etapas de amostragem”). Ou seja, no primeiro estágio de geração, a rede neural tentará discernir um panda em uma imagem barulhenta capturada no espaço latente – e, consequentemente, reduzirá a quantidade de ruído na imagem para que o panda apareça ali no futuro. Na segunda etapa, exatamente com o mesmo zelo, a rede neural começará a representar uma águia – embora literalmente tenha funcionado apenas em um panda. Na terceira etapa, será feita novamente uma tentativa de encontrar as características de um panda na quimera que já começou a se formar – e assim por diante, até que todas as etapas descritas sejam concluídas.

Fonte: geração de IA baseada no modelo SD 1.5
É o que sai com todos os parâmetros da geração anterior, inclusive o seed 485257449, e com uma dica positiva modificada para termos alternados (a negativa é a mesma):
Foto grande angular de [panda | águia] lutando ferozmente, fantasia, intrincada, elegante, altamente detalhada, pintura digital, arte conceitual, foco suave e nítido, ilustração
Pandorel? Orlando? (E certamente não Orlandina…) Para maior clareza, daremos um exemplo do que exatamente acontece com a imagem no processo de alternância de termos, novamente usando o script “gráfico X/Y/Z” para isso e fazendo uma tabela unidimensional com o único parâmetro variável – “Passos” – de 10 a 35 em passos de 5:

Fonte: geração de IA baseada no modelo SD 1.5
Pode-se observar que em algum lugar entre o 15º e o 20º passo, os restos visíveis do ruído latente desaparecem da imagem, e então ocorre uma quimerização cada vez mais profunda do objeto exibido. E por falar nisso, ninguém proíbe adicionar mais componentes à quimera gerada pelo modelo generativo:

Fonte: geração de IA baseada no modelo SD 1.5
Há uma dica positiva aqui –
Foto grande angular de [panda | águia | boi | axolotl | gato pallas | lula] lutando ferozmente, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, ilustração
Outros parâmetros são iguais. No entanto, deve-se lembrar que uma quimera tão simples, que requer apenas colchetes e um separador vertical, não funciona com redes neurais adicionais, em particular com LoRA – para este caso existe uma extensão especial sd-webui-loractl: LoRa Controle – Controlador Dinâmico de Pesos.
Outro recurso útil do AUTOMATIC1111 para mixagem produtiva de entidades é a capacidade de editar texto de prompt dinamicamente, o que é um pouco mais sutil do que a alternância sequencial de termos: edição de prompt. A sintaxe usada aqui é –
[De:para:quando]
Onde a palavra (ou palavras) a partir da qual começa a extração da imagem do espaço latente (de) é alterada para outras (para), não a cada iteração por vez, mas apenas a partir da etapa “quando”. Neste caso, em vez do número exato da etapa, você pode especificar a parcela correspondente do número total de iterações: isso significa que no caso de uma dica
Foto grande angular de [nebulosa colorida: floresta de fantasia: 0,3], pintura digital intrincada, elegante, altamente detalhada, arte conceitual, foco suave e nítido, ilustração
Durante os primeiros 30% do ciclo, o sistema representará uma nebulosa colorida, e os restantes 70% tomarão inevitavelmente como base quase um terço desta imagem muito bem definida, uma floresta de fantasia, extraída do espaço latente. Isto é o que acontece com diferentes valores do parâmetro “quando” – 0.3,0.5,0.7,0.9 – ao executar o script “Prompt S/R” do script “Plotagem X/Y/Z”:

Fonte: geração de IA baseada no modelo SD 1.5
Obviamente, quanto mais passos são dados para gerar a primeira das entidades dadas (neste caso, a nebulosa), menos ruído latente permanece na imagem no momento da transição para o segundo termo. A dependência acaba sendo não linear – isso deve ser levado em consideração ao experimentar ideias diferentes.
Também implementaremos um exemplo mais complexo de edição de dicas de ferramentas multicomponentes a partir da descrição de AUTOMATIC1111:
[Montanha:lago:0,25] e [um carvalho:uma árvore de natal:0,75][ em primeiro plano::0,6][ em segundo plano:0,25] [má qualidade:mestre:0,5]

Fonte: geração de IA baseada no modelo SD 1.5
Aqui, o primeiro quarto de todo o processo de geração é desenhado como uma montanha, os restantes 75% como um lago; os primeiros 75% são carvalho, os 25% restantes são árvores de Natal; os primeiros 60% do objeto de modelo especificado são ordenados para serem colocados em primeiro plano, após o que esta instrução simplesmente desaparece da dica de ferramenta (este é o significado da ausência de qualquer coisa entre os dois pontos no fragmento [ em primeiro plano::0.6] ); após 25% das etapas, uma instrução é adicionada à dica de ferramenta para colocar o objeto atual também em segundo plano ([in background:0.25]); finalmente, exatamente na metade do número total de gerações, o “baixo grau” nas características gerais da imagem é substituído por “executado com maestria”. Surpreendentemente, a imagem resultante não parece uma cacofonia visual de diferentes imagens e estilos – isso demonstra a alta qualidade do treinamento do modelo, que “se esforça” (entre aspas, pois em vez de consciência e vontade, os pesos fixados durante o treinamento em as entradas dos perceptrons de uma rede neural multicamadas funcionam aqui) para produzir o resultado é um resultado esteticamente aceitável. Pelo menos tão aceitável quanto os exemplos nos quais ela treinou.
Ema | Heitor | perdiz
Além da quimerização de objetos e até mesmo de conceitos diversos, inclusive formalmente incompatíveis, a edição de dicas em tempo real é utilizada como uma das formas de obter faces consistentes. Uma imagem bem-sucedida é ótima, mas se o operador deseja obter uma série inteira na qual o mesmo personagem estaria reconhecidamente presente (além disso, usando várias sementes e dicas – pelo menos dentro do mesmo ponto de verificação usado), é necessário fazer esforços consideráveis. A edição de uma dica torna possível criar um rosto estável como uma quimera a partir de dois ou mais outros conhecidos pelo modelo generativo – podem ser atores, políticos, outras celebridades e até, por exemplo, personagens de desenhos animados. Digamos que isso seja uma dica:
Retrato de uma linda feiticeira, cabelo macio, frágil, meio corpo, feminino, jovem, cabelos ondulados prateados, seda fluida, pele realista, d&d, fantasia, intricado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido , ilustração
(Outros parâmetros são os mesmos, incluindo a semente 485257449 e uma dica negativa com duas inversões de texto) – produz uma imagem de uma garota bastante fofa, mas reconhecidamente gerada por IA, com um chamado rosto padrão. Sim, de geração em geração, uma pessoa chamada simplesmente “garota” na dica de ferramenta parecerá um pouco diferente e, além disso, ao passar de um ponto de controle para outro, as mudanças serão ainda mais marcantes, mas no geral esta é uma média perfeita. rosto, desprovido de traços expressivos brilhantes, fica entediado rapidamente.

Da esquerda para a direita, a dica é simplesmente “girl”, depois “(Emma Watson:1.0)” e finalmente “Emma Watson|Thylane Blondeau]” (fonte: geração de IA baseada no modelo SD 1.5)
Claro, em vez do abstrato “garota”, você pode especificar a conhecida Emma Watson, por exemplo, e até mesmo substituí-la por “(Emma Watson:1.0)” para conectar com mais precisão o nome e o sobrenome da modelo em uma única entidade. Mas embora isso seja reproduzido com bastante segurança de geração em geração, será uma face muito definida – como dizem, offline! Como gerar algo que não tem correspondência direta no mundo real? É fácil simplesmente construir uma quimera – por exemplo, [Emma Watson|Thylane Blondeau].
Vamos estudar exatamente como isso ficará, novamente, usando o script “gráfico X/Y/Z” de dois parâmetros: deixe os valores iniciais mudarem ao longo de um eixo e o método de quimerização específico no outro (usando o “Prompt S /R” script com parâmetros
Menina,(Emma Watson:1.0),[Emma Watson|Thylane Blondeau],[Emma Watson:Thylane Blondeau:0.3],[Emma Watson:Thylane Blondeau:0.5],[Emma Watson::0.5]
Neste último caso, lembremos que a modelo extrairá dos abismos latentes a aparência brilhante da atriz que interpretou Hermione Granger, apenas até metade dos passos de geração atribuídos, e depois disso simplesmente removerá a menção dela a partir da dica de ferramenta, sem substituí-la por nada e apenas completando a “feiticeira” abstrata – mas com base anteriormente tocada pela imagem de Emma Watson.
Vamos ajustar um pouco a dica original:
Retrato de close-up de uma linda feiticeira, cabelos prateados ondulados e macios, roupões de seda frágeis, femininos, jovens e esvoaçantes, pele realista, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, ilustração
Aqui, em vez de um retrato de meio corpo, um close-up foi escolhido deliberadamente, para que você possa ver mais claramente como o rosto está mudando. Vamos complementar a dica negativa, por precaução, com alguns termos moralmente protetores:
CyberRealistic_Negative-neg, CyberRealistic_Negative_v3, nu, nsfw

Fonte: geração de IA baseada no modelo SD 1.5
É realmente perceptível que de semente em semente o rosto da “menina” sem nome muda visivelmente – pelo menos muito mais visivelmente do que os rostos gerados com base em imagens de pessoas reais. As duas últimas linhas da tabela acima são especialmente indicativas a este respeito: onde, após metade dos passos de geração, o lugar de “Emma Watson” foi ocupado por “Thylane Blondeau”, o rosto sai geralmente mais vivo do que quando ninguém tomou o cargo deixado pela atriz.
⇡#Mais vida!
Em princípio, agora – usando a alternância de entidades e editando a dica de ferramenta em tempo real – você pode esperar obter inspiração adicional do ambiente de trabalho AUTOMATIC1111, especialmente se começar a criar imagens no modo “Gernar para sempre” e até mesmo alterar manualmente parâmetros de geração nas janelas ao longo do caminho, inserindo dicas positivas e negativas, movendo vários controles deslizantes, etc. – neste caso, o sistema captará as alterações após a conclusão da geração da próxima imagem. No entanto, existem formas mais poderosas de despertar a imaginação adormecida de um artista de IA, implementadas em extensões para o ambiente de trabalho que estamos considerando – e acima de tudo são prompts dinâmicos, Dynamic Prompts.
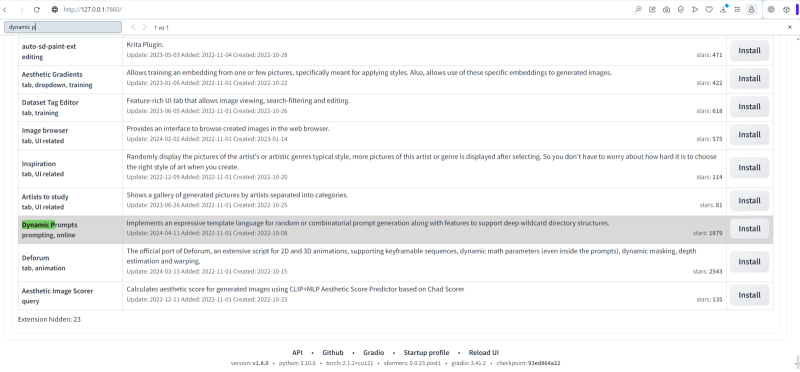
Os leitores de nossos “Workshops” anteriores já devem estar familiarizados com como instalar extensões AUTOMATIC1111. Na aba “Extensões”, na subaba “Disponíveis”, encontramos a extensão “Prompts Dinâmicos” – ela está localizada quase no final da lista. Clique no botão cinza “Instalar”; em seguida, retornando à subaba “Instalados”, realizamos “Verificar atualizações” – as extensões instaladas anteriormente serão atualizadas ao mesmo tempo. Alternativamente, você pode iniciar um aplicativo de linha de comando (por exemplo, instalado durante o primeiro Git Bash AI Drawing Workshop) no diretório de instalação stable-diffusion-webui e executar o comando lá
Clone do git https://github.com/adieyal/sd-dynamic-prompts/extensions/sd-dynamic-prompts
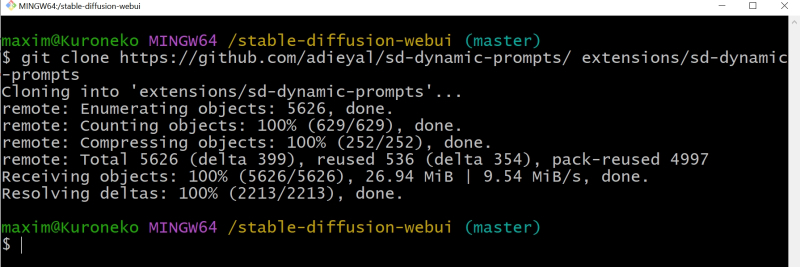
Após o que é melhor reiniciar a interface gráfica do servidor web para maior confiabilidade. A propósito, também existem nós personalizados correspondentes para o ambiente de trabalho ComfyUI – este ambiente é preferível para SDXL (e, presumivelmente, será o mesmo para SD 3), por isso é muito bom que uma ferramenta tão flexível esteja disponível lá também .
A partir de agora, na aba “txt2img” temos um menu suspenso “Dynamic Prompts”, neste caso, logo abaixo de “Tiled VAE”. Observe que a extensão atualmente instalada vem acompanhada de comentários muito claros do autor, disponíveis diretamente em sua interface – nos submenus suspensos “Precisa de ajuda?” e “Ajuda para modelos Jinja2” (dentro dos próprios “modelos Jinja2”).
A essência dos prompts dinâmicos (implementados por meio da extensão de prompts dinâmicos; não deve ser confundida com a edição instantânea de prompts discutida acima, edição de prompts, integrada ao AUTOMATIC1111) é o uso de curingas em vez de termos individuais com a possibilidade de combiná-los ainda mais; repetidas vezes aleatoriamente – ou pesquisando meticulosamente todas as opções possíveis. Após a instalação desta extensão, em vez de colchetes para listar as opções selecionadas por meio de um separador vertical, os curvos são usados por padrão – e isso, enfatizamos, torna muito mais fácil distinguir visualmente entre a alternância de palavras na dica de ferramenta de uma etapa de geração para outra e a escolha de uma entidade entre as propostas. Então, se o fragmento
[Emma Watson|Megan Fox|Audrey Hepburn]
Significa que durante a geração da imagem, na primeira etapa o sistema tenta criar uma quimera – extrair o rosto da primeira das atrizes listadas do espaço latente, na segunda – a segunda, na terceira – a terceira, na quarto – novamente o primeiro, depois a sintaxe
{Emma Watson|Megan Fox|Audrey Hepburn}
Após a instalação de “Prompts Dinâmicos” indica que apenas uma das atrizes listadas será selecionada aleatoriamente para geração cada vez que você pressionar o botão “Gerar”.
É claro que se a cabeça do operador está repleta de muitas entidades que merecem uma combinação maluca, não é razoável enumerá-las todas numa única dica: isso acabará por ser excessivamente complicado. Portanto, a expansão da dica dinâmica é mais frequentemente usada de uma forma diferente e muito lógica do ponto de vista do programador – referindo-se a listas pré-preparadas dessas mesmas entidades.

Os prompts dinâmicos são uma força terrível (fonte: geração de IA baseada no modelo SD 1.5)
A maneira mais fácil de explicar o funcionamento desse mecanismo é usar o exemplo de uma piada bem conhecida: ““(O quê?) (O quê?) Nos levou para (o quê?) floresta? um aluno normal da segunda série deveria abrir esses parênteses, permanecendo dentro dos limites da decência?!” No nosso caso, os parâmetros “nude, nsfw” no prompt negativo serão responsáveis pela decência e, em vez de parênteses, a sintaxe “Prompts dinâmicos” depende por padrão (isso pode ser alterado nas configurações) em um sublinhado duplo: “ __”.
Vamos criar a seguinte parte variável de uma dica positiva:
__type__ __creature__ nos levou a uma floresta __característica__
Vamos adicionar também uma parte constante: uma “salada de palavras”, que é bastante importante mesmo para os pontos de verificação mais recentes do SD 1.5 (como os entusiastas chamam condescendentemente um conjunto de termos vagamente interconectados à primeira vista, projetados de forma semi-mágica, ou seja, difícil de explicar, forma de melhorar a imagem extraída da imagem latente do espaço), já utilizada nas gerações acabadas de realizar:
D&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, suave, foco nítido, ilustração
A seguir, vamos criar três arquivos de texto em qualquer editor – notepad.exe servirá – nos quais, de fato, serão armazenadas várias respostas às perguntas “qual?”, “qual?”. E daí?”. Para maior clareza, tornaremos esses arquivos curtos, com apenas três linhas cada, mas em princípio eles podem ser bastante longos. Os próprios desenvolvedores da extensão em questão fornecem em sua descrição links para uma série de coleções impressionantes, de dezenas de megabytes a gigabytes, de curingas sobre uma variedade de tópicos – desde compêndios de características estéticas de imagens e estilos de artistas específicos até listas de diversas poses, gestos, opções de roupas, objetos comestíveis e assim por diante.
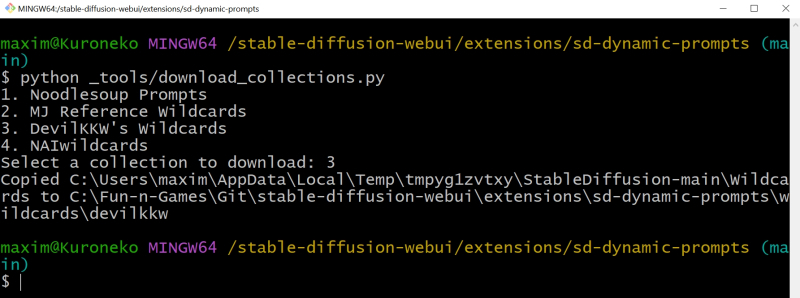
Você também pode baixar os arquivos correspondentes automaticamente – você precisa usar o já familiar Git Bash para executar o comando no diretório de trabalho desta extensão (ou seja, extensions/sd-dynamic-prompts/)
Python _tools/download_collections.py
Akanbe
Garganta cortada
Dedo indicador levantado
Dedo do meio
Mindinho para fora
Acenando
Apontando
Apontando para si mesmo
Apontando para o espectador
Apontando para baixo
Apontando para frente
Apontando para cima
Pose de lareira
Febre de Sábado a Noite
Calar
Polegares para baixo
Afirmativo
O primeiro gesto akambe indicado aqui é bem conhecido de todos os fãs de anime – é puxar simultaneamente a pálpebra inferior para trás com o dedo indicador e esticar a língua; expressa provocação ou desrespeito geral. Modelos treinados em capturas de tela de desenhos de anime e mangaká colocarão com segurança o personagem gerado na posição akanbe – mas não só eles: muitos pontos de verificação que são relevantes hoje foram obtidos pela fusão de modelos inicialmente fotorrealistas e de desenho animado, o que amplia significativamente as possibilidades de interpretação do dado operador de dica.
⇡#Larva ousada
Primeiro, type.txt, com conteúdo
Grotesco
Fofa
Etéreo
Segundo, criatura.txt –
Axolote
Vaca
Libélula
E o terceiro, característico.txt:
Estranho
Ensolarado
Inundado
Cada arquivo consiste exatamente em três linhas; cada linha estritamente da primeira posição contém apenas uma palavra.
Agora vamos voltar ao menu “Prompts Dinâmicos” e marcar a posição “Geração Combinatória”: este comando forçará o sistema não apenas a pegar elementos de dicas aleatórios dos arquivos de substituição, mas a passar por todas as combinações possíveis deles : no nosso caso – 3 vezes 3 e mais 3, ou seja, 27. Mude a imagem para o modo paisagem (768 × 512), deixe os outros parâmetros de geração iguais – e vá em frente!

Fonte: geração de IA baseada no modelo SD 1.5
Em nosso sistema de teste com GTX 1070 8 Gb, 27 imagens SD 1.5 são geradas sem nenhuma melhoria – ADetalier, Hires. consertar, etc. – demorou menos de 20 minutos. Neste pacote de pesquisa existem composições verdadeiramente dignas de nota – e o que é especialmente interessante é que elas podem ser melhoradas ainda mais.
Portanto, “prompt magic” – Prompt Magic – ajudará a adicionar uma certa imprevisibilidade à geração. É implementado através do próximo menu suspenso em “Prompts Dinâmicos”: basta ativar a opção “Prompt Mágico”. A princípio, os controles deslizantes “Comprimento máximo do prompt mágico” e “Criatividade do prompt mágico” devem ser deixados em suas posições padrão, assim como o “modelo mágico” – Gustavosta/MagicPrompt-Stable-Diffusion. Uma dúzia e meia de modelos diferentes estão integrados na versão da dica dinâmica que é atual no momento em que este artigo foi escrito – faz sentido para os interessados experimentá-los pessoalmente.

Fonte: geração de IA baseada no modelo SD 1.5
Não inseriremos nada no campo “Magic prompt blocklist regex” por enquanto: é útil se você deseja excluir alguns parâmetros da geração. Digamos que, ao inserir “amarelo” ali, daremos ao sistema um comando para não usar a cor amarela (embora até que ponto a ordem será executada dependa das características do ponto de verificação atual, do valor CFG e muito mais), e a combinação “amarelo|cachorro|futuro” será interpretada como proibindo o uso de cada uma dessas palavras na pista modificada. Durante o primeiro lançamento do próximo modelo “prompt magic”, levará algum tempo para carregá-lo, além de ficar localizado na memória de vídeo e, assim, reduzir o espaço disponível – mas no geral, o jogo vale a pena.
Digamos o que obtivemos com uma combinação de substituições fofas, axolotes e misteriosas (ou seja, com uma dica positiva, o axolote fofo nos levou a uma floresta misteriosa, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, suave, nítido foco, ilustração), – na seguinte ilustração à esquerda:

Fonte: geração de IA baseada no modelo SD 1.5
Depois de praticar a “dica mágica”, a mesma dica se transformou em
O lindo axolote nos levou a uma floresta misteriosa, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, arte ilustrativa de greg rutkowski e alphonse mucha
E agora está assim, na ilustração acima à direita. Não seria exagero dizer que o pitoresco da imagem – não importa como seja definido em termos culturais – é claramente mais expressivo neste último caso do que no primeiro.
Se em vez do modelo relativamente pequeno Gustavosta/MagicPrompt-Stable-Diffusion (510 MB), que adiciona principalmente estilos característicos de artistas populares, usar outro, Ar4ikov/gpt2-medium-650k-stable-diffusion-Prompt-generator (1,44 GB ), e até mesmo aumentar o limite de comprimento da dica para 150 tokens (duas vezes em comparação com o bloco padrão de 75), ficará ainda mais divertido. Bem, mais precisamente, pode acontecer – o fator acaso é importante aqui:

Fonte: geração de IA baseada no modelo SD 1.5
Observe que o axolote neste caso se transformou – a combinação “fofo, axolote, misterioso” está incorporada na primeira foto desta série, canto superior esquerdo – em uma princesa convencional (a interpretação latino-americana de “A Princesa Sapo”? Já interessante!) porque tocado pelo mágico Com um stick de 1,44 GB de tokens adicionais, a dica original foi transformada quase irreconhecível:
O axolote fofo nos levou a uma floresta misteriosa, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, arte ilustrativa de artgerm e greg rutkowski e alphonse mucha, garota com cabelos longos usando uma regata rosa topo, sentado em uma colina, fantasia, intrincado, elegante, altamente detalhado, pintura digital, artstation, arte conceitual, fosco, foco nítido, ilustração, hearthstone, arte de artgerm e greg rutkowski e alphonse mucha, uma bela renderização 3 d de um gato brincando com um gato vestindo uma fantasia de gato, motor irreal 5, 8k, renderização de octanas, tendências na arte
No final, como você pode facilmente notar, a frase clássica para “saladas de palavras” da era SD 1.5 foi cortada – “tendências no artstation” (ou seja, um site popular entre artistas digitais), e isso deve ser mantido em mente: se qualquer resultado da geração de uma dinâmica O operador não está muito satisfeito com os prompts, talvez valha a pena ter certeza de que o sistema não cortou nada importante; E, em geral, faz sentido – se a dica inicial for realmente importante – definir o limite da dica estendida e o nível de influência da “mágica” sobre ela (o controle deslizante “Criatividade do prompt mágico”) mais baixo.
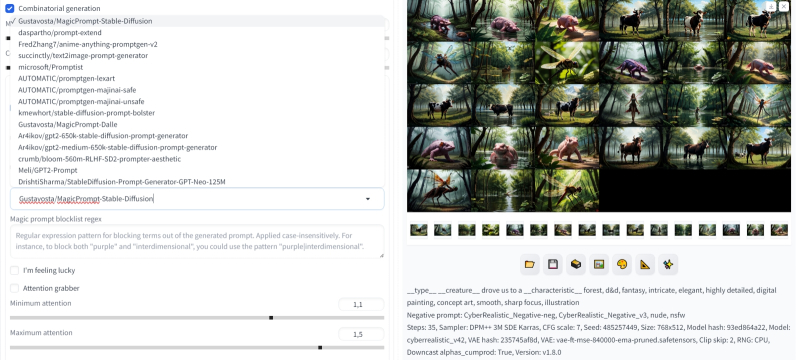
A escolha do modelo de geração combinacional, bem como o comprimento máximo da dica modificada, afetará significativamente o resultado
Aqui está uma imagem expressiva, digamos, que surge se o “foco nítido” for enfatizado:

Fonte: geração de IA baseada no modelo SD 1.5
O axolote fofo nos levou a uma floresta ensolarada, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, suave, (foco nítido: 1.24), ilustração
⇡#Dicas para o stream
E é isso que pode sair assim:

Fonte: geração de IA baseada no modelo SD 1.5
Uma grande estátua de pedra axolote no meio de uma floresta de Greg Rutkowski, Sung Choi, Mitchell Mohrhauser, Maciej Kuciara, Johnson Ting, Maxim Verehin, Peter Konig, fantasia final, 8k fotorrealista, iluminação cinematográfica, HD, detalhes altos, atmosférico,
Bem, você deve se lembrar, é claro, que o acesso à API web resulta em atrasos adicionais.
Não falaremos sobre o submenu “Modelos Jinja2”, o recurso atualmente experimental de “Prompts Dinâmicos” – apenas observaremos que esta linguagem de script relativamente primitiva, mas ainda eficaz, permite que você crie tais, por exemplo, construções –
{%
{%
{% Prompt %}Eu adoro rosas sem dados{% endprompt %}
{% Outro %}
{% Prompt %}Eu odeio nenhuma rosa de dados{% endprompt %}
{% Fim se %}
{% Fim para %}
Como resultado do acionamento deste específico, as três dicas a seguir serão recebidas:
Eu amo rosas vermelhas
Eu odeio rosas azuis
Eu odeio rosas verdes
Aqueles que desejam experimentar esta poderosa ferramenta podem sempre consultar a documentação correspondente.
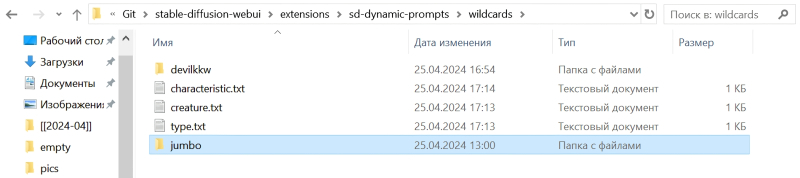
Na linha principal de abas do espaço de trabalho – no mesmo local onde estão localizados “txt2img”, “img2img” e outros semelhantes – existe agora outro, “Wildcards Manager”. Após mover a coleção jumbo e clicar no botão atualizar localizado na parte inferior da página (ou reiniciar a interface web AUTOMATIC1111, o que for mais conveniente), os novos arquivos de substituição ficam visíveis nesta aba – eles podem ser visualizados e até editados . O campo “Arquivo curinga” exibe o nome exato do arquivo selecionado com toda a estrutura de subdiretórios anexada – é isso que deverá ser incluído na dica para geração usando listas de substituição.
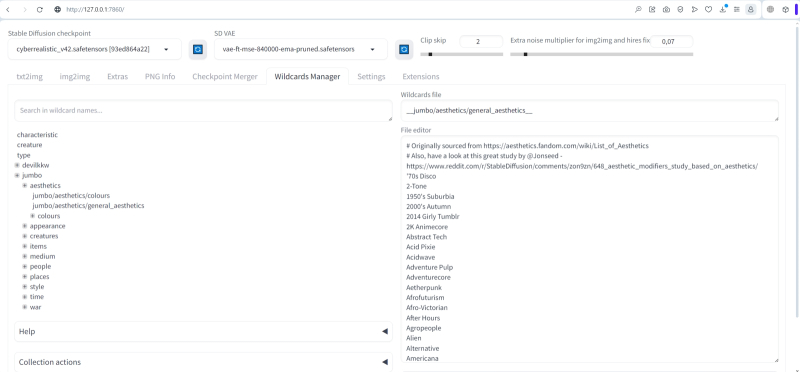
Bem, vamos tentar definir a variação mais flexível sobre o tema “o quê” e “o quê”:
__jumbo/appearance/adjectives__ __jumbo/creatures/animals__ nos trouxe a um __jumbo/appearance/appearance__ __devilkkw/nature and elements/tree_habitats__ em __jumbo/time/timeofday__, no estilo de __jumbo/aesthetics/general_aesthetics__, __devilkkw/composition/image_composition_techniques__, obra-prima de __devilkkw/art/artists__, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, suave, foco nítido, ilustração
Aqui, em vez da palavra “dirigiu”, com a qual, em particular, extraímos do espaço latente do axolote um pouco mais acima, colocamos “trouxe” – já que o primeiro desses dois termos parecia estar firmemente associado durante o treinamento do Modelo de IA com carros: demais Eles aparecem frequentemente nos resultados da pesquisa, embora a dica de ferramenta não contenha nenhuma indicação direta sobre eles.
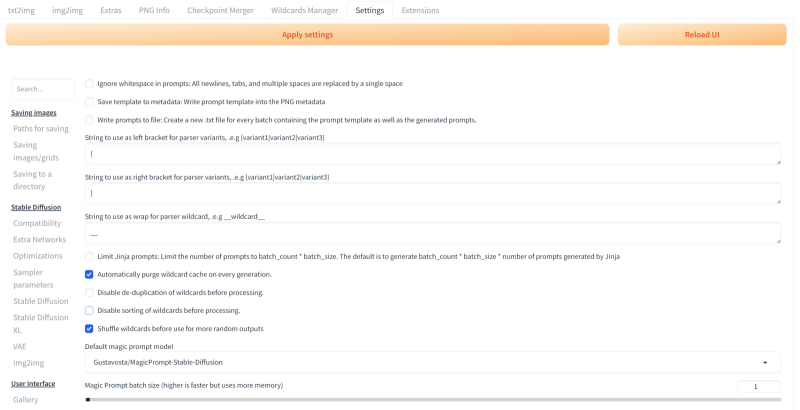
Para que o modo “Gerar para sempre” sempre faça uma nova seleção de linhas nas listas de substituição, você precisa encontrar a seção “Prompts Dinâmicos” na aba “Configurações” (à esquerda da coluna, no “ Categoria Sem categoria”) e marque os parâmetros “Limpar automaticamente o cache de curingas em” a cada geração” e “Embaralhar curingas antes de usar para obter mais saídas aleatórias”.
Após iniciar o modo “Gerar para sempre” com prompts dinâmicos configurados desta forma, imagens verdadeiramente impressionantes começam a aparecer. Mesmo que não com muita frequência, sim, mas nem todo entusiasta de desenho de IA seria capaz de selecionar imediatamente, de cabeça, a combinação apropriada de parâmetros quase aleatórios para obter o seguinte resultado:

Dica positiva: gopher severo nos levou a uma floresta tropical com sombra plana à noite, no estilo de Drain, monocromático múltiplo, obra-prima de Chris Ware, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, ilustração (fonte: geração de IA baseada no modelo SD 1.5)
Ou isto:

Toupeira brilhante nos levou a uma floresta skeuomórfica ao meio-dia, no estilo Nerd, linhas rápidas, obra-prima de Agnes Cecile, d&d, fantasia, intrincada, elegante, altamente detalhada, pintura digital, arte conceitual, foco suave e nítido, ilustração (fonte: Geração II baseada em modelos SD 1.5)
Ou isto:

Mula brilhante nos levou a uma selva psicodélica à tarde, no estilo de Horror Academia, claro-escuro, obra-prima de Ferdinand Knab, d&d, fantasia, intrincado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, ilustração (fonte : Geração II baseada em modelos SD 1.5)
A imprevisibilidade do acionamento de certos termos na dica de ferramenta, como sempre, está fora da escala: “gopher” não se mostrou de forma alguma, a palavra “toupeira” foi claramente entendida como significando “toupeira” e não “toupeira” – exceto aquela “mula” foi um sucesso. E, no entanto, no caso de dicas compostas dinamicamente e alimentadas automaticamente ao sistema, não é tão importante o que exatamente estava contido no campo de entrada de texto – as próprias imagens de saída têm valor.
Observe também que depois de descobrir uma geração realmente interessante, faz sentido interromper o loop infinito (clique com o botão direito em “Interromper” e selecione “Cancelar geração para sempre”), carregue o arquivo desejado na aba “Informações PNG”, copie o dica positiva correspondente e prosseguir com a geração novamente – desativando, é claro, a extensão “Dynamic Prompts”. Seria aconselhável dimensionar imediatamente a imagem para aumentar os detalhes – usando as já familiares ferramentas do Hires. corrigir e ADetaler. Além disso, para este último, se houver muitas figuras humanas pequenas na imagem, é aconselhável usar o parâmetro “Força de redução de ruído” maior, 0,4-0,5, e no caso de um único rosto retratado grande (e esteticamente bem sucedido), limite-o a valores de 0,15-0,25.

Rato paradoxal nos levou a uma floresta skeuomórfica ao entardecer, no estilo de Bodikon, mistura, obra-prima de Joan Miró, d&d, fantasia, intricado, elegante, altamente detalhado, pintura digital, arte conceitual, foco suave e nítido, ilustração (fonte: AI -geração baseada no modelo SD 1.5)
E ainda, voltando à questão colocada no início deste “Workshop”: o que se deve fazer se o operador de um modelo generativo de IA quiser desesperadamente obter uma imagem de um panda a lutar com uma águia – afinal, dicas dinâmicas, por todas as suas vantagens, será que não estão resolvendo o problema? Eles não decidem, certo; mas neste caso, existem outras extensões para o ambiente de trabalho AUTOMATIC1111 – e este não é apenas ControlNet e não Tiled Diffusion, de que falamos anteriormente. Uma ferramenta poderosa para regionalizar dicas de ferramentas abre horizontes completamente novos para os entusiastas do desenho de IA, mas falaremos sobre isso em outro momento.