

Os aceleradores para trabalhar com redes neurais são divididos, grosso modo, em duas categorias: para treinamento e para execução (inferência). É neste último caso que não é tanto o desempenho “puro” que é importante quanto a combinação de desempenho com economia, uma vez que tais dispositivos freqüentemente funcionam em condições restritas em termos de fornecimento de energia. A Qualcomm está oferecendo novos aceleradores Cloud AI 100 que combinam os dois.
O próprio neuroprocessador Cloud AI 100 foi anunciado pela primeira vez na primavera do ano passado, e a Qualcomm anunciou que esse chip foi projetado desde o início e oferece dez vezes o nível de desempenho por watt em comparação com as soluções existentes na época. O início das entregas estava planejado para o segundo semestre de 2019, mas como podemos ver, os aceleradores baseados neste chip só apareceram no mercado agora, e estamos falando de volumes de entregas bastante limitados e “experimentais”.
Ao contrário dos processadores gráficos e aceleradores FPGA, que são frequentemente usados no treinamento de redes neurais e, sendo universais, consomem grandes quantidades de energia, os chips de inferência são geralmente ASICs especializados. Por exemplo, Google TPU Edge e Cloud AI 100 pertencem à mesma classe. A especialização estreita permite que você se concentre em alcançar o desempenho máximo em certas tarefas, e o Cloud AI 100 é mais de 50 vezes superior ao bloco de processador de inferência, que faz parte do popular SoC Qualcomm Snapdragon 855.
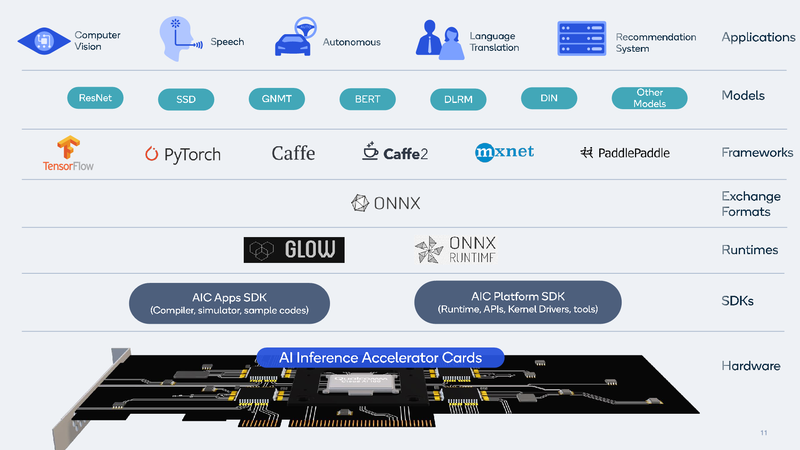
Nos slides apresentados pela Qualcomm, a arquitetura Cloud AI 100 parece bastante simples: o chip é um conjunto de blocos inteligentes especializados (IP, até 16 unidades, dependendo do modelo), complementados com controladores LPDDR (4 canais, até 32 GB, 134 GB / s), PCI Express (até 8 linhas 4.0), bem como um módulo de controle. Há alguma SRAM integrada rápida (até 144 MB). Em termos de formatos de computação suportados, tudo é bastante universal: INT8, INT16, FP16 e FP32 são implementados. É verdade que bfloat16 não foi “relatado”.
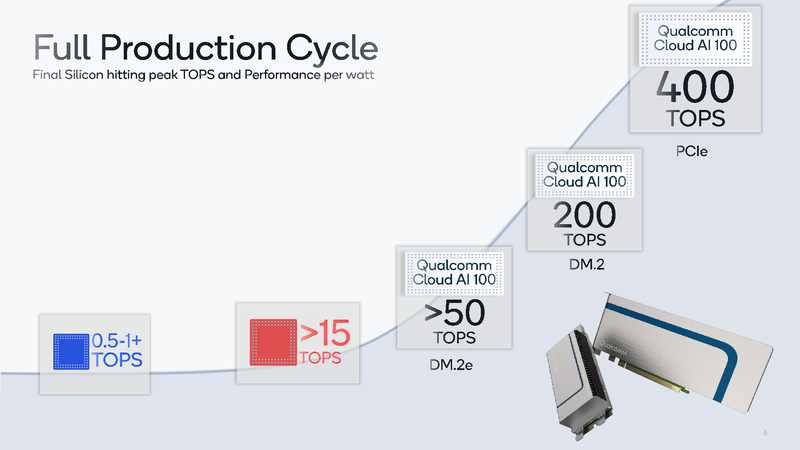
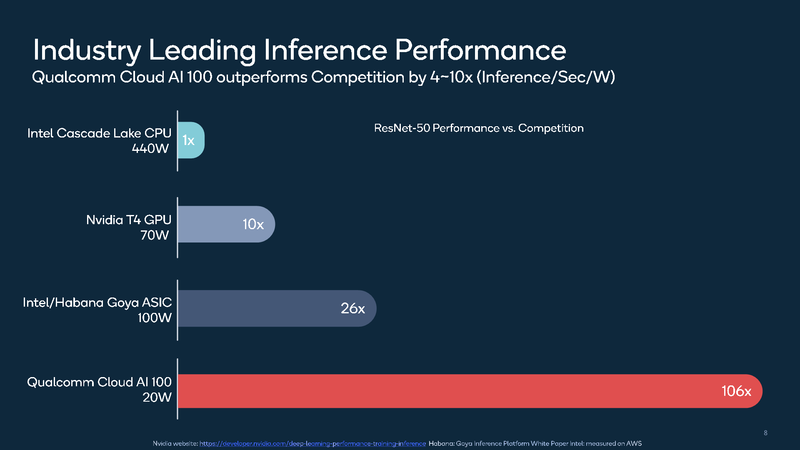
Os dados fornecidos pela própria Qualcomm falam da eficácia da novidade: se considerarmos um sistema baseado nos processadores Intel Cascade Lake com um consumo de 440 watts como nível básico, o Qualcomm Cloud AI 100 no teste ResNet-50 será duas ordens de magnitude mais rápido com um consumo de apenas 20 watts. Isso, claro, não é o limite: o novo acelerador de inferência pode ser fornecido ao mercado em três versões diferentes, duas das quais são compactas, fator de forma M.2 e M.2e com pacotes térmicos de 25 e 15 W, respectivamente. Mesmo nessas variantes, o desempenho é de 200 e cerca de 500 Tops (trilhões de operações por segundo), e também há uma placa PCIe de 75 Watts no formato HHHL com desempenho de 400 Tops; em todos os casos, estamos falando sobre o modo INT8.
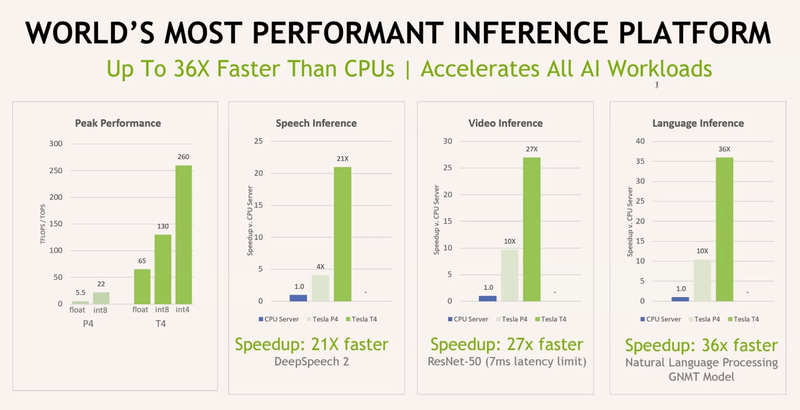
Os dados para NVIDIA Tesla T4 e P4 são para comparação
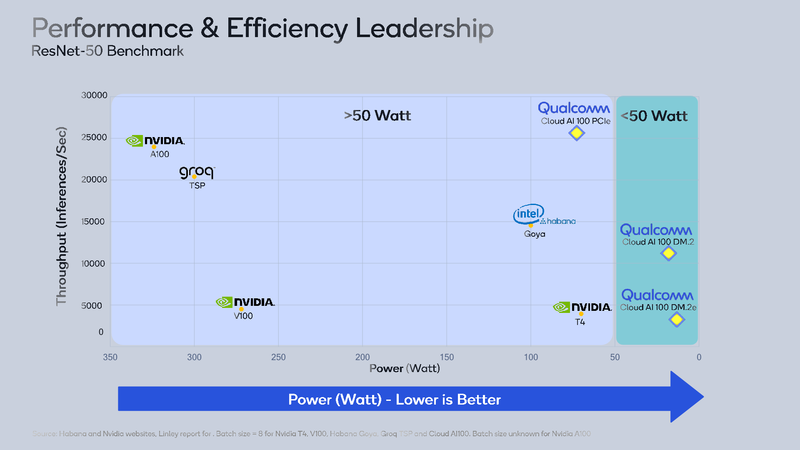
Os principais concorrentes do Cloud AI 100 são Intel / Habana Gaia e NVIDIA Tesla T4. Ambos os processadores também são projetados para sistemas de inferência, eles são arquitetonicamente mais flexíveis – especialmente T4, que, na verdade, é baseado na arquitetura de Turing – mas você tem que pagar por isso tanto no preço quanto no aumento do consumo de energia – 100 e 70 watts, respectivamente. Enquanto estamos falando sobre reconhecimento de imagem usando a popular rede ResNet-50, a solução da Qualcomm parece ótima, está muito acima de seus principais concorrentes. No entanto, em outros casos, nem tudo pode ser tão simples.

Os novos aceleradores da Qualcomm estarão disponíveis em diferentes formatos
Tanto o T4 quanto o Gaia, bem como algumas outras soluções, como o Groq TSP, devido à sua flexibilidade, podem ser uma escolha mais adequada fora do ResNet em particular e do INT8 em geral. De acordo com a Qualcomm, a empresa está atualmente conduzindo testes detalhados do Cloud AI 100 em outros cenários do MLPerf, mas os resultados ainda não estão disponíveis publicamente. Os desenvolvedores estão focados em atender às necessidades específicas do cliente. Também é afirmado que o alto desempenho em grandes conjuntos de dados pode ser obtido por escalonamento – usando vários aceleradores Cloud AI 100 no sistema.
Um kit de desenvolvimento baseado em Cloud Edge AI 100 está atualmente disponível para encomenda e seu objetivo principal é criar e testar dispositivos AI edge. O sistema é poderoso o suficiente, inclui um processador Snapdragon 865, um modem Snapdragon X55 5G e um coprocessador AI Cloud AI 100. O dispositivo é feito em uma caixa de metal protegida com quatro antenas externas. As entregas comerciais em grande escala estão previstas para começar no primeiro semestre do próximo ano.