
O acelerador híbrido NVIDIA Grace Hopper combina módulos de CPU e GPU, que são conectados por meio da interconexão NVLink C2C. Mas, como relata o HPCWire, existem algumas nuances na estrutura e operação do superchip, que foram descritas por pesquisadores suecos.
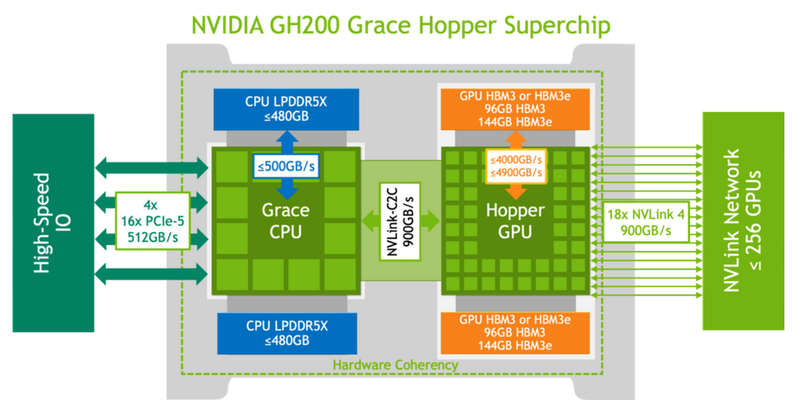
Eles conseguiram medir o desempenho dos subsistemas de memória Grace Hopper e da interconexão NVLink em cenários da vida real para comparar os resultados obtidos com as características declaradas pela NVIDIA. Lembramos que a velocidade de 900 GB/s foi inicialmente declarada para interconexão, o que é sete vezes maior que as capacidades do PCIe 5.0. A memória HBM3 como parte da GPU tem largura de banda de até 4 TB/s, e a versão com HBM3e já oferece até 4,9 TB/s. A parte do processador (Grace) usa LPDDR5x com largura de banda de memória de até 512 GB/s.
Nas mãos dos pesquisadores estava a versão básica do Grace Hopper com 480 GB LPDDR5X e 96 GB HBM3. O sistema executou Red Hat Enterprise Linux 9.3 e usou CUDA 12.4. No benchmark STREAM, os pesquisadores conseguiram obter os seguintes indicadores de largura de banda: 486 GB/s para CPU e 3,4 TB/s para GPU, o que está próximo das características declaradas. No entanto, a velocidade resultante do NVLink-C2C foi de apenas 375 GB/s na direção host-dispositivo e apenas 297 GB/s na direção oposta. O total é de 672 GB/s, o que está longe dos 900 GB/s declarados (75% do máximo teórico).
Fonte: NVIDIA
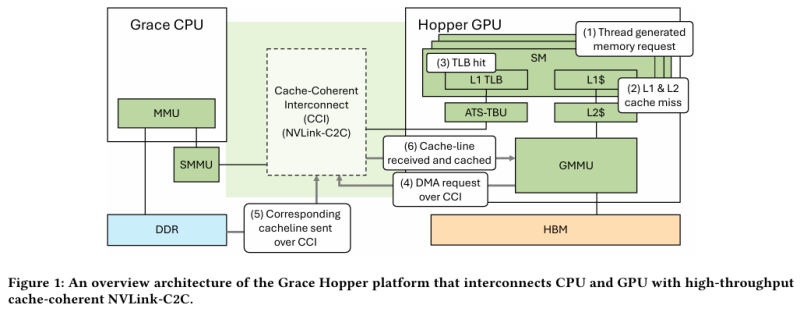
Grace Hopper, por design, oferece dois tipos de tabelas para páginas de memória: uma para todo o sistema (páginas de 4 KB ou 64 KB por padrão), que cobre a CPU e GPU, e uma exclusiva para a parte da GPU (2 MB) . Neste caso, a velocidade de inicialização depende de onde vem a solicitação. Se a inicialização da memória ocorrer no lado da CPU, então os dados são colocados por padrão em LPDDR5x, ao qual a parte da GPU tem acesso direto via NVLink C2C (sem migração), e a tabela de memória fica visível tanto para a GPU quanto para a CPU.
Fonte: arxiv.org
Se a memória não for gerenciada pelo sistema operacional, mas pelo CUDA, a inicialização poderá ser organizada imediatamente no lado da GPU, que geralmente é muito mais rápida, e os dados poderão ser colocados no HBM. Neste caso, é fornecido um único espaço de endereço virtual, mas existem duas tabelas de memória, para CPU e GPU, e o mecanismo de troca de dados entre elas envolve migração de páginas. No entanto, apesar da presença do NVLink C2C, a situação ideal permanece quando o HBM é suficiente para cargas de GPU e o LPDDR5x é suficiente para cargas de CPU.
Fonte: arxiv.org
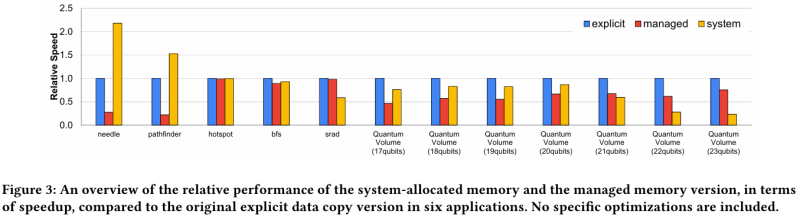
Os pesquisadores também abordaram a questão do desempenho ao usar páginas de memória de tamanhos diferentes. Páginas de 4 KB normalmente são utilizadas pela parte do processador com LPDDR5X, e também nos casos em que a GPU precisa receber dados da CPU via NVLink-C2C. Mas, como regra, em cargas de trabalho de HPC é ideal usar páginas de 64 KB, que exigem menos recursos para serem gerenciadas. Quando o acesso à memória é caótico e inconsistente, as páginas de 4 KB permitem um controle mais preciso dos recursos. Em alguns casos, é possível obter um benefício de desempenho 2x ao não mover dados não utilizados em páginas de 64 KB.
O trabalho publicado observa que serão necessárias mais pesquisas para compreender melhor os mecanismos de memória unificada em soluções heterogêneas como Grace Hopper.