
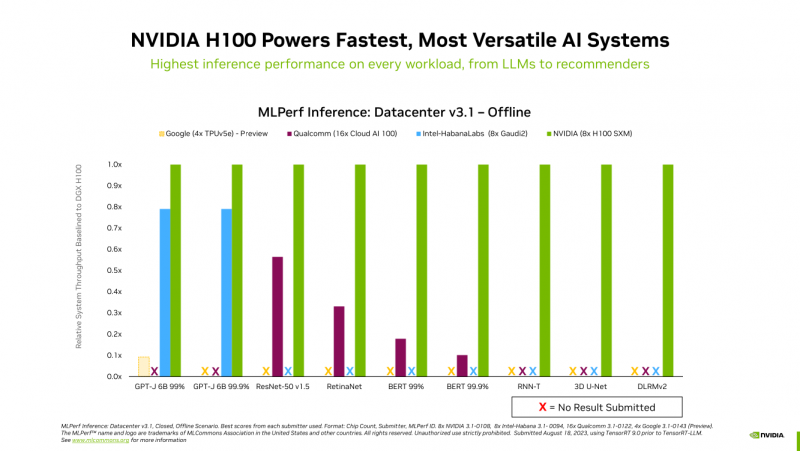
A NVIDIA anunciou que o superchip NVIDIA GH200 Grace Hopper e o acelerador H100 lideram todos os testes de desempenho do data center no benchmark de IA generativa MLPerf Inference v3.1, que inclui tarefas de inferência em visão computacional, reconhecimento de fala, processamento de imagens médicas e também trabalho com linguagem grande modelos (LLM).
A NVIDIA anunciou anteriormente os recordes H100 no novo benchmark MLPerf. Agora diz-se que o superchip GH200 Grace Hopper passou em todos os testes MLPerf pela primeira vez. No entanto, os sistemas equipados com oito aceleradores H100 forneceram o maior rendimento em todos os testes de inferência MLPerf. As soluções NVIDIA concluíram o teste de recomendação atualizado (DLRM-DCNv2) e também concluíram o primeiro benchmark GPT-J – LLM com 6 bilhões de parâmetros.
Vale ressaltar que o GH200 acabou sendo até 17% mais rápido que o H100, embora o chip acelerador em ambos os produtos seja o mesmo. A NVIDIA atribui isso a vários fatores. Em primeiro lugar, o GH200 tem mais memória interna – 96 GB versus GB. Em segundo lugar, a largura de banda da memória é de 4 TB/s e o chip em si é híbrido, portanto o PCIe não é usado para transferir dados entre LPDDR5x e HBM3. Em terceiro lugar, o GH200, com baixa carga de CPU, é capaz de transferir parte da energia para o acelerador, permanecendo dentro dos limites especificados de consumo de energia. É verdade que nos testes o GH200 funcionou com potência máxima, ou seja, com TDP de 1 kW.

Fonte da imagem: NVIDIA
Atenção especial é dada à otimização de software – recentemente a NVIDIA anunciou uma ferramenta de software aberta TensorRT-LLM, projetada para acelerar a execução de LLM em produtos NVIDIA. Este software permite dobrar o desempenho do acelerador H100 no teste GPT-J 6B (parte do MLPerf Inference v3.1). A NVIDIA observa que as melhorias de software permitem que os clientes melhorem o desempenho dos sistemas de IA ao longo do tempo, sem custos adicionais.
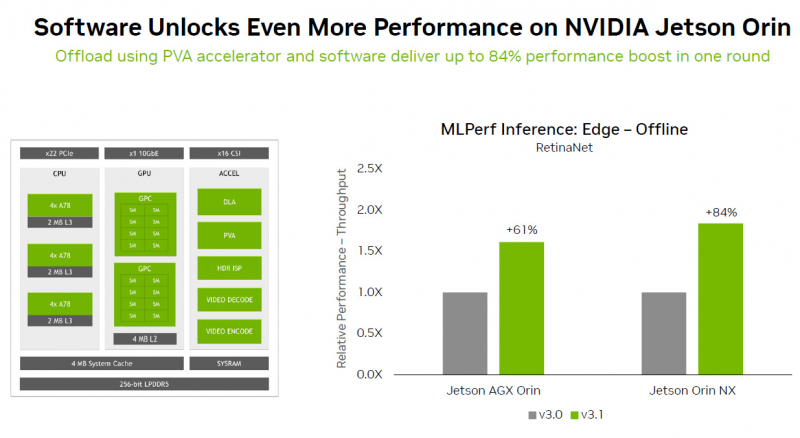
Observa-se também que os módulos NVIDIA Jetson Orin, graças ao novo software, apresentaram um aumento de desempenho de até 84% em tarefas de detecção de objetos em comparação com a rodada anterior de testes MLPerf. A aceleração ocorreu graças ao uso do Programmable Vision Accelerator (PVA), um mecanismo separado para processamento de imagens e algoritmos de visão computacional operando independentemente da CPU e GPU.
Também é relatado que o acelerador NVIDIA L4 executou toda a gama de cargas de trabalho nos últimos testes MLPerf, mostrando excelente desempenho. Assim, como parte de um adaptador com consumo de energia de 72 W, este acelerador apresenta desempenho seis vezes superior ao das CPUs, cujo TDP é quase cinco vezes maior. Além disso, a NVIDIA implementou uma nova tecnologia de compressão de modelo para demonstrar uma melhoria de desempenho de 4,4x ao usar BERT LLM no acelerador L4. Espera-se que essa técnica chegue a todas as cargas de trabalho de IA.
Os parceiros de teste da MLPerf incluíram provedores de serviços em nuvem Microsoft Azure e Oracle Cloud Infrastructure, bem como ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT e Supermicro. No geral, o MLPerf é apoiado por mais de 70 empresas e organizações, incluindo Alibaba, Arm, Cisco, Google, Universidade de Harvard, Intel, Meta✴, Microsoft e Universidade de Toronto.