
Todos os dias, um morador urbano moderno consome cerca de 2 mil quilocalorias com alimentos – se não comer demais e não passar fome – e consome aproximadamente a mesma quantidade. Em termos de potência, isso corresponde a uma média de cerca de 100 W, dos quais pelo menos 20 W são gastos para garantir o funcionamento do cérebro: mais durante a vigília ativa, menos durante o sono.
Para efeito de comparação: o consumo de energia de um processador de servidor completamente moderno (somente a CPU, sem levar em conta a alimentação do subsistema de memória, barramento de dados interno, etc.) como o EPYC 7551P em plena carga excede 300 watts. Mas para resolver tarefas com as quais o cérebro humano lida facilmente quase a cada segundo (digamos, reconhecimento confiável de imagens em tempo real), são necessários grandes data centers com dezenas de racks cheios de servidores com essas CPUs. A diferença na eficiência energética é óbvia – e não é a favor de máquinas inteligentes.

O conceito de IA implica a criação de um análogo do cérebro biológico (fonte: Pixabay)
Avançando no desenvolvimento de sistemas de inteligência artificial (IA) na base de hardware atual, programadores, cientistas e engenheiros estão percebendo cada vez mais: os sistemas de computação usuais para nós, que são baseados na arquitetura von Neumann, em princípio, não são capazes de alcançar o mesmo que o do cérebro biológico, a eficiência energética. Pode haver várias maneiras de sair desse impasse, incluindo computadores quânticos extremamente promissores – cujo desenvolvimento, no entanto, enfrenta várias dificuldades.
Muito mais alcançável é o objetivo de construir IA com base – mais precisamente, com uso ativo – de computadores analógicos.
⇡#Existem análogos
Não apenas as pessoas, mas também os animais com um sistema nervoso um pouco desenvolvido são capazes de traçar paralelos entre eventos formalmente não relacionados – é esse fenômeno que é conhecido desde a época de Pavlov como um reflexo condicionado. Em algum verme ou molusco, os neurocientistas formam com sucesso e depois estudam estereótipos comportamentais – manifestações de como um animal, por analogia, de maneira típica, reage a uma situação já vivida antes.

Um bisão morto em um desenho será morto durante a caça (pintura rupestre da Caverna de Altamira; fonte: Pixabay)
As pessoas muitas vezes usam analogias no curso de compreensão da realidade objetiva – pegue pelo menos as imagens simbólicas da caça, registradas em pinturas rupestres. Com base no estudo das tribos modernas, não afetadas pela influência da civilização (aqui – novamente uma analogia!), os antropólogos argumentam que os ancestrais antigos retratavam muitas cenas de caça não após o fato, mas imediatamente antes de partir para a presa. Supondo que um cervo pintado perfurado por uma lança pintada corresponderá a um troféu de caça não menos bem-sucedido na realidade.
Formas mais sofisticadas de formar analogias artificiais com eventos reais datam dos últimos séculos aC, quando os primeiros computadores analógicos conhecidos por nós começaram a aparecer nas antigas cidades-estados gregas. O único representante existente desta classe de dispositivos, o mecanismo de Antikythera, é datado do século II aC. BC e. Mas em textos antigos, referências a tais sistemas de engrenagens também são encontradas em épocas anteriores.

O maior fragmento sobrevivente do mecanismo Antikythera: o diâmetro da engrenagem principal é de cerca de 13 cm (fonte: Wikimedia Commons)
⇡#Você pode me dizer qual saros é agora?
Na virada dos séculos 19 e 20, os restos de um antigo navio romano que afundou há mais de dois mil anos foram descobertos perto da ilha de Antikythera, no Mar Egeu. O navio transportava (provavelmente para demonstração durante o triunfo de César por ocasião da captura de Rodes) uma extensa coleção de objetos de arte e outras raridades: mergulhadores gregos ergueram várias estátuas de mármore e bronze, restos de móveis luxuosos, cerâmica e produtos de vidro, moedas para a superfície.

Reconstrução (Tony Freeth et al., 2021) do mostrador principal do mecanismo Antikythera: a cúpula de bronze no centro é a Terra, a bola preta mais próxima é a Lua, depois o anel do zodíaco, o Sol e os planetas (fonte : Natureza)
Não é de surpreender que os funcionários do Museu Arqueológico de Atenas, para onde os achados foram movidos, estivessem primeiro empenhados na restauração dos artefatos mais cativantes e atraentes, não prestando muita atenção aos fragmentos de bronze indistintos extraídos do fundo, fortemente corroída e abundantemente coberta de sedimentos marinhos. Apenas alguns anos depois, o arqueólogo Valerios Stais notou que em um desses fragmentos, sob camadas de cal, era claramente visível uma grande roda de bronze, com cerca de 13 cm de diâmetro, com muitas dezenas de dentes. Um exame mais detalhado do artefato revelou outros elementos do design, que lembram um relógio.
O cientista sugeriu que a descoberta feita em Antikythera foi o primeiro exemplo de um dispositivo mecânico descoberto para prever os movimentos dos corpos celestes – mas foi imediatamente ridicularizado por seus colegas mais céticos. Veneráveis arqueólogos afirmaram com autoridade que as tecnologias necessárias para a produção de obras tão delicadas não estavam disponíveis em tempos antigos e que, provavelmente, o procronismo ocorre aqui – uma espécie de anacronismo, quando um certo fenômeno remonta a uma época anterior à realmente aconteceu. Tipo, sobre o local de um antigo naufrágio, um cronômetro marinho mais ou menos moderno foi jogado de uma placa de um navio que passava – apenas alguma coisa.

Quadro de um vídeo mostrando o modelo reconstruído (Tony Freeth et al., 2021) do mecanismo de Antikythera em movimento (fonte: Nature)
A autoridade de luminares desconfiados ousou questionar – apenas meio século depois – o historiador britânico Derek J. de Solla Price. O cientista levou mais de vinte anos para meticulosamente radiografar em várias projeções 82 fragmentos preservados de um dispositivo desconhecido do tesouro de Antikythera em cooperação com especialistas em física nuclear. A coroação de seu trabalho foi a primeira publicação de um antigo computador analógico, um mecanismo para prever saros e movimentos planetários.
Os astrônomos chamam Saros de um período de pouco mais de 18 anos, durante o qual o arranjo mútuo de seus elementos em movimento contínuo se repete no sistema Sol-Terra-Lua. Para um observador terrestre, isso se manifesta no fato de que exatamente todos os saros em uma determinada área são reproduzidos na mesma ordem, nos mesmos intervalos de antes, um ciclo completo de eclipses: 41 solares (dos quais cerca de 10 podem ser totais) e 29 lunares.

Os eclipses solares são um dos fenômenos celestes mais fascinantes e formidáveis, e as pessoas aprenderam a prever seu início muito antes da nossa era (fonte: Pexels)
Esse padrão tornou-se conhecido dos antigos babilônios, e foi ela quem foi incorporada nas engrenagens principais do mecanismo de Anticítera. Estritamente falando, saros (como o ano astronômico) é um número não inteiro de dias, ou seja, 6585 e ⅓. Portanto, por conveniência, os astrônomos antigos preferiam calcular exeligmos – um período igual a três saros. No início dos anos 2000, pesquisadores mostraram que era o exeligmos que era reproduzido pelas 37 rodas principais do mecanismo Antikythecra.
Mais tarde, os cientistas começaram a argumentar que 82 detalhes encontrados na parte inferior representam apenas cerca de um terço do número total de elementos do mecanismo original – e que, além de prever eclipses solares e lunares em determinado ponto da superfície terrestre (a maioria provavelmente em Rodes), tornou possível reproduzir movimentos na esfera celeste de todos os cinco planetas conhecidos pelos antigos: Mercúrio, Vênus, Marte, Júpiter e Saturno.

Reconstrução (Tony Freeth et al., 2021) da visão geral do mecanismo de Antikythera: no painel frontal há um mostrador mostrando os movimentos do Sol e dos planetas; no verso – calendários de ciclos lunisolares para previsão de eclipses (fonte: Nature)
É interessante que os herdeiros ideológicos, ainda que não diretos, do mecanismo de Antikythera possam ser considerados os dispositivos antiaéreos de controle de fogo de artilharia (PUAZO) usados ativamente no século XX – computadores eletromecânicos que permitem prever a posição de um alvo em movimento no espaço enquanto o artilheiro o segura na mira da mira, e o correspondente como apontar uma arma antiaérea.
⇡#Despeje com mais ousadia, camarada!
Um pouco mais próximo do momento atual, em 1936, o engenheiro soviético Vladimir Lukyanov criou um integrador hidráulico, o primeiro computador do mundo para resolver equações diferenciais parciais. Ele não fez isso por amor à ciência pura: os gigantescos projetos de construção dos primeiros planos de cinco anos exigiam a construção de estruturas de concreto armado enormes e duráveis, o que ditava a necessidade de prever suas características de resistência com alta confiabilidade.

A coroa da evolução dos computadores analógicos soviéticos: o integrador tridimensional (experimental) Lukyanov (fonte: “Ciência e Vida”)
Lukyanov sugeriu que o aparecimento de rachaduras no concreto se deve principalmente não às intrigas dos inimigos da pátria socialista ou à negligência dos trabalhadores, mas às peculiaridades da propagação do calor na alvenaria de concreto. Mas a natureza das transições térmicas dentro de um bloco de concreto também pode depender do regime de temperatura (dia – noite, estação do ano, umidade, força e velocidade do vento etc.), da qualidade e composição da mistura e da tecnologia de execução do trabalho.
Teoricamente, é possível escrever equações para todas essas dependências, mas elas são diferenciais, em derivadas parciais – elas se tornam bastante complicadas para uma solução analítica direta (especialmente na ausência de computadores digitais à mão). Lukyanov voltou-se para os trabalhos de seus antecessores: anteriormente, a possibilidade de substituir um processo físico por outro durante a modelagem por analogia já havia sido provada, se os sistemas de equações que os descrevem fossem idênticos. O engenheiro viu uma correspondência direta entre os padrões de distribuição de calor em um bloco de concreto deliberadamente não homogêneo e os processos físicos de movimento da água através de um sistema complexo de tubos interligados com resistências hidráulicas variáveis.

Integrador hidráulico serial IG-3 (Planta de máquinas de cálculo e análise, Ryazan, 1955) – um computador analógico para resolver equações diferenciais (fonte: Museu Politécnico, Moscou)
O método de analogias hidráulicas proposto por Lukyanov reduziu uma tarefa extremamente difícil do ponto de vista matemático à necessidade de construir um sistema de vasos conectados por tubos de vários diâmetros, e então observar como um fluxo laminar de água passa por esse sistema. Para entender exatamente como isso é realizado, será útil considerar o caso mais simples – a dissipação de calor unidimensional em uma parede densa, cujos lados são aquecidos uniformemente.
A parede é dividida em camadas (por exemplo, três: externa, média e interna), cada uma das quais é modelada por um tubo com líquido derramado nele e uma válvula de fechamento por baixo: quanto maior a coluna de líquido, maior a temperatura ( mais precisamente, a quantidade de energia térmica nesta camada). Se as camadas da parede modeladas por analogia tiverem diferentes capacidades térmicas – por exemplo, revestimento, isolamento, parede de suporte – os tubos são selecionados com a proporção apropriada de diâmetros. A largura do canal de saída de cada tubo (estritamente falando, sua impedância hidráulica) corresponde à resistência térmica da camada dada.
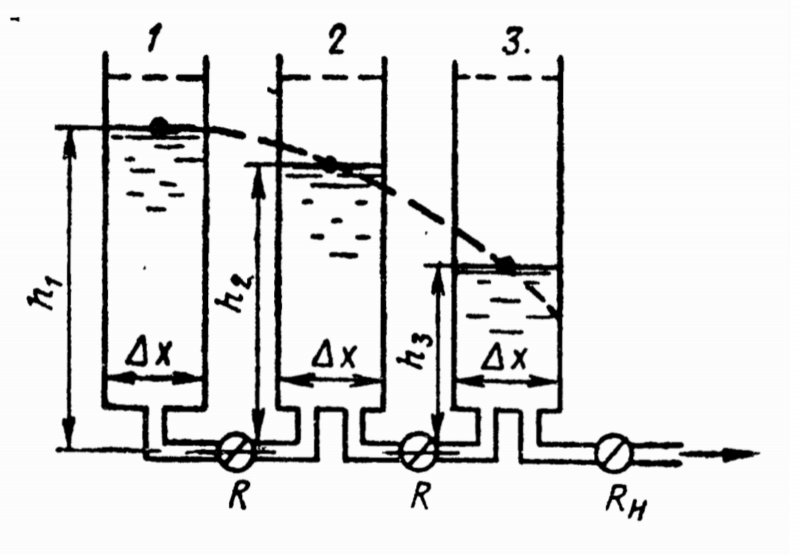
Diagrama esquemático do integrador hidráulico Lukyanov para resolver o problema unidimensional de dissipação de calor em uma parede representada por três camadas (fonte: publicação original 1934)
Definidas as condições iniciais (os vasos estão devidamente conectados por tubos com a resistência hidráulica correta e preenchidos com os volumes de água necessários), basta abrir todas as torneiras ao mesmo tempo – e basta observar com que rapidez e onde exatamente os níveis do líquido mudam. A qualquer momento, as torneiras podem ser fechadas para estudar a situação em um determinado estágio. Para registrar objetivamente os resultados, gravadores de tambor foram posteriormente adicionados ao projeto e, em 1941, Lukyanov também propôs um integrador hidráulico bidimensional composto por seções separadas.
⇡#Digital bate analógico, analógico bate digital
A invenção da engenharia analógica foi tão bem-sucedida que os computadores mainframe digitais foram capazes de competir com os computadores analógicos hidráulicos produzidos em massa no campo da resolução de equações diferenciais parciais não antes do início da década de 1980.
Como as leis de mudança de funções de muitas variáveis em muitas áreas são descritas por equações idênticas às hidrodinâmicas, calculadoras baseadas em elementos hidráulicos começaram a aparecer em todo o mundo – basta lembrar o MONIAC da Nova Zelândia, usado para modelar processos econômicos nos mercados dos países. Sim, isso mesmo: vários modelos dos processos macroeconômicos mais importantes são construídos usando equações diferenciais parciais.

Computador hidráulico MONIAC no Museu da Ciência em Londres (Fonte: Wikimedia Commons)
Hoje, o poder de computação dos computadores da arquitetura von Neumann é muitas ordens de magnitude maior do que as capacidades desses computadores há quase meio século – no entanto, eles também precisam resolver problemas fundamentalmente diferentes. Ou seja, aqueles em que, ao longo de bilhões de anos de evolução, as estruturas neurais biológicas se especializaram: reconhecimento de padrões, operações dentro da estrutura da lógica difusa, tomada de decisões críticas com base em dados incompletos.
As tentativas de criar análogos artificiais diretos de estruturas biológicas de “pensamento” ainda estão longe de uma implementação real. Parece lógico simular as características do trabalho dos neurônios vivos na RAM dos sistemas von Neumann, e isso já está sendo feito com sucesso. Mas o principal obstáculo aqui é o consumo de energia excessivamente alto dos cálculos realizados pelos dispositivos semicondutores clássicos, já mencionados no início.

Computadores digitais modernos não são ideais para resolver problemas de IA (fonte: Pixabay)
E apenas para melhorar a eficiência energética das máquinas digitais envolvidas na modelagem do trabalho dos neurônios, propõe-se o uso de computadores analógicos. Mas agora será – e já é – não unidades mecânicas (como o mecanismo Antikythera) ou hidráulicas (como o integrador Lukyanov), mas dispositivos que dependem, como os processadores usuais em PCs ou smartphones, de memória semicondutora. Isso é apenas para semipermanentes, não voláteis, – e não para operacionais, cujas informações desaparecem quase instantaneamente depois que a tensão de alimentação é desligada.
O que há de errado com Von Neumann? Melhor que cache. Resumir
⇡#O que há de errado com Von Neumann?
O esquema tradicional de hoje para organizar um dispositivo semicondutor de computação implica a separação física do processador da memória. Programas e dados, de acordo com os princípios de von Neumann, são colocados apenas na memória (geralmente é uma RAM volátil de alta velocidade), e o processador os acessa através do barramento de dados que conecta esses dois nós tanto para informações iniciais para cálculos quanto para emitindo os resultados de sua própria computação.
Obviamente, o gargalo, que às vezes é chamado de “gap de von Neumann”, aqui é a taxa de transferência do barramento de dados intracomputador. Ao longo das décadas, a indústria de TI se acostumou a superar esse desfiladeiro – devido ao aumento constante da frequência do clock do processador e à paralelização das operações realizadas por ele, além de aumentar a profundidade de bits e a velocidade do próprio barramento – é perfeito para resolver com confiança uma enorme variedade de tarefas. Mas o aprendizado de máquina, no qual todo o conceito atual de IA é construído, infelizmente não se encaixa nesse círculo.
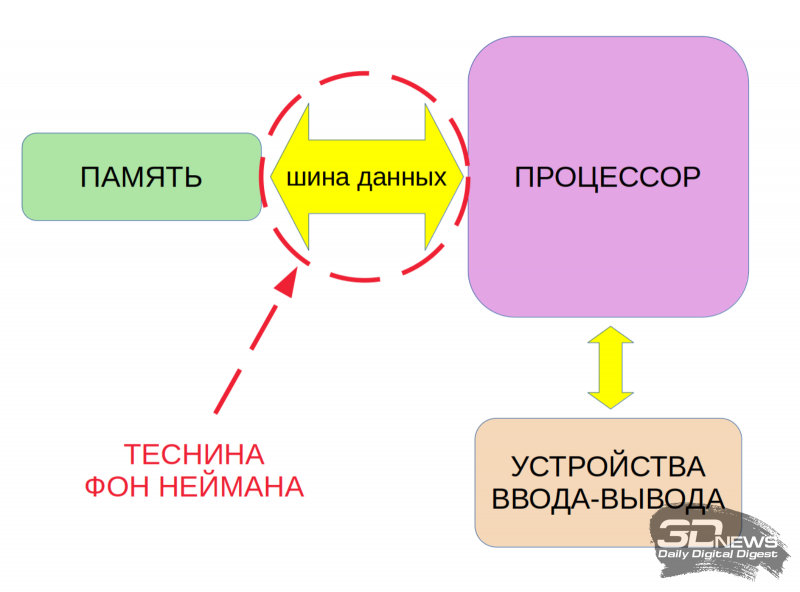
«O gargalo de von Neumann dificulta a solução eficaz de problemas de IA em computadores da arquitetura clássica atual
A conclusão é que o princípio básico da organização do aprendizado de máquina é a modelagem de uma rede neural biológica, que se resume essencialmente à soma ponderada. Neurônios virtuais com muitas entradas são formados na memória do computador. Os sinais de entrada chegam a cada neurônio por meio de diferentes entradas com diferentes pesos – ou seja, com diferentes significados. Grosso modo, se for necessário determinar se um gato é mostrado na imagem, os pesos dos recursos “ter cauda”, “ter bigode”, “ter patas com garras retráteis” serão moderadamente positivos, enquanto o sinal “ter chifres” sem dúvida terá um enorme peso negativo.
Considere o processo de operação de uma pequena seção da rede neural com mais detalhes. Em teoria (e em um modelo digital), tal região age de forma semelhante à forma como uma rede de neurônios funciona em um cérebro biológico. Aqui estamos falando de semelhança, não de cópia exata (em particular, as comunicações químicas entre as células nervosas são ignoradas, apenas as comunicações elétricas são levadas em consideração), mas de acordo com o nível de desenvolvimento até mesmo dos melhores exemplos atuais de IA, é já é óbvio o quão produtivo é esse caminho.
Assim, grosso modo, podemos supor que os sinais elétricos dos receptores (órgãos dos sentidos) entram em uma rede multicamada de neurônios e, após o processamento, são emitidos para efetores – conversores de sinal em ações físicas. Ou seja, os receptores visuais registraram o semáforo mudando para vermelho – a rede neural comparou os riscos de perda de tempo devido a um minuto de atraso e lesões em consequência de um acidente – os efetores emitiram um comando ao sistema motor para desacelerar em a transição.
Biologicamente, os neurônios são bastante complexos, e a estrutura de conexões entre eles é ainda mais complexa (fonte: Pixabay)
A rede neural é representada no modelo em consideração por uma estrutura composta por camadas neurais unidimensionais; cada camada é um conjunto de neurônios independentes. Um neurônio tem muitos receptores (receptores) do sinal, chamados axônios, e o único dendrito é o canal para emitir o impulso resultante. A área de contato entre dois neurônios é chamada de sinapse, e o sinal que passa por essa sinapse é modulado de uma certa maneira com base no aprendizado – aumenta ou, inversamente, enfraquece.
O modelo descrito de conexões sinápticas, portanto, representa cada neurônio como uma calculadora de somas ponderadas de sinais vindos de outros neurônios. O cérebro biológico é muito mais complicado, mas no modelo matemático essa complexidade é compensada por uma importante modificação do neurônio básico: em vez de estritamente um axônio, ele tem várias saídas. Como resultado, torna-se possível combinar camada por camada, em cada uma das quais vários somadores somam os sinais ponderados (com pesos sinápticos atribuídos) recebidos de cada um dos neurônios da camada anterior e, em seguida, transmitem os resultados dessa somatório – também com pesos, mas já diferentes – para a próxima camada.
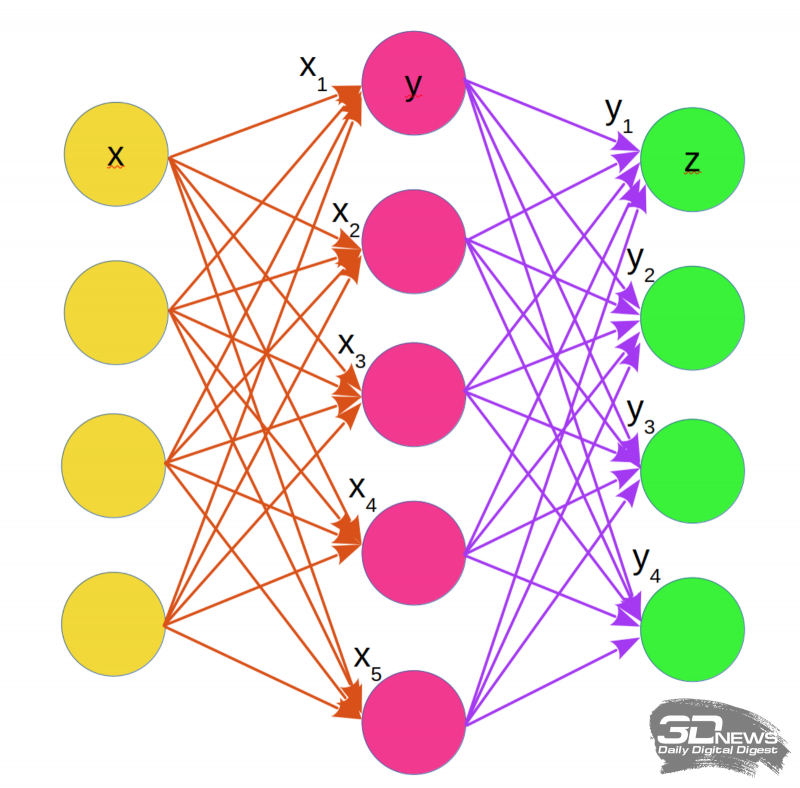
Um esquema simplificado para organizar a soma ponderada em uma rede neural de camada única com conexões sinápticas. Amarelo indica receptores, cada um dos quais fornece sinais ponderados (setas laranja) aos neurônios (carmesim). Os neurônios realizam a soma ponderada, após a qual, com novos pesos (setas roxas), transmitem sinais aos efetores (verde). Letras com subscritos indicam os pesos das conexões sinápticas correspondentes às células individuais (nesta figura – superior) das camadas de receptores (x) e neurônios (y)
Um modelo de aprendizado com uma camada de neurônios virtuais é, na verdade, uma lista de verificação com uma lista de recursos-chave. Somando em uma coluna todos os critérios indicados, multiplicados pelos seus pesos correspondentes, o sistema obterá numericamente a probabilidade de que um gato esteja representado na imagem considerada ou não. Mas, na prática, o assunto não se limita a uma camada: quanto mais complexo o resultado desejado, mais iterações intermediárias são necessárias.
Tal rede neural é treinada pela seleção sucessiva de pesos sinápticos para cada camada de neurônios. Mesmo para uma rede básica de camada única, é óbvio como essa tarefa é demorada: inicialmente, os pesos são definidos para um determinado valor inicial, os sinais passam por toda a rede, forma um determinado resultado nos efetores – e ele é combinado com o modelo. Se houver diferença (e certamente será desde o início), os valores dos pesos mudam e o ciclo completo de somatórias ponderadas se repete. Por qual princípio alterar os pesos em cada camada para uma nova iteração é uma questão separada; o principal é que cada uma dessas etapas requer um número significativo de operações de multiplicação e adição.

Um dos dois gabinetes que compunham o computador de xadrez IBM Deep Blue, no California Computer History Museum (Fonte: Wikimedia Commons)
Como resultado, um sistema de IA profundamente desenvolvido opera com centenas de camadas interconectadas e, para cada combinação de conexões, realiza uma soma ponderada repetidas vezes. E tudo isso – bombeando continuamente enormes fluxos de dados no barramento interno: da RAM para a CPU e vice-versa. Computadores genuinamente “inteligentes” como o Deep Blue, que derrotou um humano pela primeira vez no xadrez, ou o AlphaGo, que derrotou o campeão mundial no jogo de Go, consomem 200-300 kW, enquanto seus oponentes ainda usam o mesmo bom e velho sistema biológico. Cérebro de 20 Watts. Se a humanidade realmente planeja usar cada vez mais a inteligência artificial para resolver seus problemas diários, métodos muito menos intensivos em energia de soma ponderada terão que ser inventados.
⇡#Melhor que cache
A rigor, os processadores modernos (e nem mesmo os mais modernos) já têm acesso direto a quantidades limitadas de memória que não envolvem o barramento de dados interno. Estamos falando do cache do processador – no momento já é multinível e bastante extenso. A propósito, os adaptadores gráficos são tão adequados para resolver problemas de IA porque há muitos núcleos de computação em sua composição e estão associados quase diretamente a uma quantidade impressionante de RAM. É verdade que, na prática, para o aprendizado de máquina voltado para tarefas realmente complexas, isso não é suficiente.

Chip analógico desenvolvido pela IBM (Analog AI Chip v1.0) – um quadrado dourado no centro do tabuleiro; ao redor – um chicote de controle para monitorar o estado de cada um dos elementos que compõem o chip com resistência variável baseada em uma transição de fase (fonte: IBM)
Hoje, a maneira mais adequada de superar a “lacuna de von Neumann” para vários engenheiros de TI praticantes é realizar cálculos diretamente na memória (computar na memória, CIM), sem a necessidade de direcionar fluxos de dados entre a CPU e a RAM por meio de o ônibus interno. Neste caso, estamos falando de memória não volátil (memória não volátil, NVM), e não de vários tipos de DRAM – em grande medida apenas porque a energia não será gasta no armazenamento de dados intermediários no NVM. Ou seja, de fato, os CIMs neste caso são implementados na base de hardware de um processador especializado com um cache de primeiro nível hipertrofiado.
Bom; mas o que a computação analógica tem a ver com isso, se estamos falando apenas de mover os dados processados da DRAM para a memória não volátil? O fato é que o módulo NVM é, no caso geral, uma matriz retangular de células – armazenamentos de carga elétrica, que permite modelar diretamente nós, conexões e, o mais importante, pesos para soma ponderada. E as operações realizadas nessa matriz são de fato uma semelhança – um análogo – do trabalho de uma rede neural biológica. Não sua simulação virtual no nível do software, mas uma analogia física direta – isso é extremamente importante.

Placa de expansão Mythic MP10304 Quad-AMP PCIe com quatro processadores de matriz analógica: até 100 TFPS potencial de desempenho AI, até 25W de consumo de energia (fonte: Mythic)
Uma das empresas que já implementa essa abordagem hoje, a Mythic, utiliza um módulo NVM, integrado diretamente ao núcleo computacional do processador, para armazenar a matriz de pesos da camada atual de operações de aprendizado de máquina – ou várias camadas, se a capacidade disponível permitir. A IBM conta com células de memória com transição de fase (de um estado cristalino para um estado amorfo e vice-versa). Mas em qualquer caso, o cálculo da soma ponderada para CIM com NVM é realizado multiplicando diretamente o vetor de distúrbios de entrada (conjunto de dados para cada um dos parâmetros) pela matriz de pesos.
No nível do assunto, o CIM pode ser implementado em uma variedade de bases de elementos, incluindo memória magnetoresistiva (MRAM) e resistiva (RRAM), memória de efeito de mudança de fase (PCM) e até memória flash (NAND). O alto desempenho da estrutura analógica torna possível implementar tarefas complexas de IA, como reconhecimento de padrões, literalmente em tempo real e com consumo de energia mínimo (comparado aos computadores von Neumann), o que é especialmente importante para aplicações da Internet de desenvolvimento rápido. coisas hoje.

O princípio de operação de uma célula de resistência variável de memória PCM: em valores baixos da tensão de entrada, a substância dentro da célula cristaliza, quando a tensão aumenta, ela passa para um estado amorfo – e, de acordo com isso, a resistência elétrica alterações de valor (fonte: IBM)
⇡#Resumir
E agora – a coisa mais importante: como exatamente essa multiplicação é implementada. Em suma, o vetor de distúrbios de entrada é dado por um conjunto de níveis de tensão para cada um dos canais de entrada. A matriz de peso é uma microestrutura elétrica com uma distribuição correspondente de resistências sobre os nós da célula. E agora, de forma completamente natural, como é típico de um computador analógico, o cálculo se resume à implementação de leis objetivas – neste caso, a lei de Ohm (corrente = tensão * resistência) para cada uma das perturbações que passam pela matriz estrutura de resistores. A soma dos sinais ponderados ocorre de acordo com as regras de Kirchhoff para a soma das correntes em circuitos complexos.
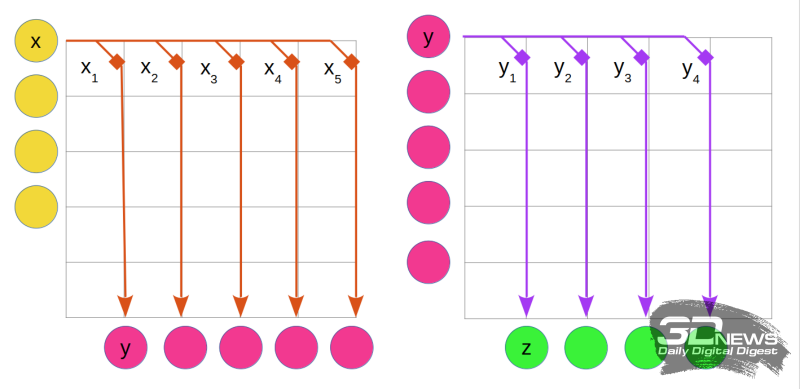
É assim que a soma ponderada analógica é implementada para uma rede neural de camada única em uma matriz de memória de mudança de fase (PCM). O código de cores corresponde à ilustração “Esquema simplificado para organizar a soma ponderada”
A figura da esquerda mostra a primeira etapa do processamento: a transmissão de sinais de cada receptor para os neurônios é representada pela aplicação de tensão no barramento horizontal correspondente do módulo NVM. Os pesos x1, x2, etc. para cada sinapse são codificados pelo valor de resistência de um elemento PCM individual na matriz (marcado com quadrados; os mesmos quadrados estão localizados em outras células da matriz – eles não são mostrados na figura) . As correntes resultantes ao longo dos barramentos verticais chegam, somando-se de acordo com as regras de Kirchhoff, às células receptoras – isso corresponde a uma soma ponderada nos neurônios.
Os valores das cargas obtidas são fixados em capacitores (não mostrados no diagrama), após o que a matriz NVM vizinha ou mesma pode ser usada para o segundo estágio dos cálculos neuromórficos (lado direito da figura). Agora, os sinais sinápticos dos neurônios são alimentados nas entradas à esquerda dos capacitores mencionados e novos valores de resistência são atribuídos aos elementos PCM correspondentes aos pesos y1, y2, etc. quaisquer operações numéricas – os valores finais de carga para os efetores são obtidos.

Processador de matriz analógica Mythic M1076 na placa de expansão M.2 (Fonte: Mythic)
Do ponto de vista técnico, um computador NVM é um dispositivo de complexidade intermediária entre um módulo de memória e um processador universal. Por exemplo, o processador de matriz analógica M1076 da Mythic, construído para padrões de fabricação de 40 nm, contém 76 matrizes CMOS (lógica complementar com transistores semicondutores de óxido metálico), o que permite realizar cálculos neuromórficos usando até 80 milhões de pesos em um consumo de energia típico em o nível de 3 W, realizando até 35 trilhões de operações por segundo (TOPS) – e toda essa magnificência cabe no formato de cartão de expansão M.2.
O uso de tal chip em conjunto com o módulo NVIDIA Jetson Xavier NX, uma escolha típica na construção de uma rede neural digital moderna, possibilita, segundo representantes da empresa desenvolvedora, aumentar o desempenho efetivo da unidade de computação NVIDIA 2-3 vezes. Uma placa PCIe de tamanho normal com 15 processadores de matriz analógica integrados promete desempenho de até 400 TOPS com a capacidade de atribuir até 1,28 bilhão de pesos sinápticos enquanto consome não mais que 75 watts. A IBM está se movendo em uma direção semelhante: já está testando um computador NVM analógico baseado em elementos de memória de mudança de fase, cujas dimensões da matriz de trabalho são 784 × 250 elementos, e você já pode executar sua tarefa de IA diretamente neste dispositivo conectados.

Raridades como este computador analógico polonês AKAT-1 de 1959 devem em breve ser substituídos por máquinas muito mais poderosas (Fonte: Britannica)
A IA com eficiência energética baseada em hardware analógico poderá literalmente reviver muitos elementos da Internet das coisas, industrial e doméstica, que precisam urgentemente da capacidade de analisar o que está acontecendo em tempo real e formar uma resposta adequada: de câmeras de CFTV a câmeras autônomas veículos e drones. De acordo com especialistas, os computadores analógicos disponíveis em um futuro próximo permitirão reduzir dez vezes o consumo de energia durante os cálculos neuromórficos. Do ponto de vista do estado atual da indústria de TI, seu foco em processos tecnológicos maduros (cerca de 40 nm) é especialmente atraente neles, o que torna possível não restringir a produção de microprocessadores convencionais baseados em lógica booleana para eles, e, como resultado, criar sistemas de computação analógico-digital que se destacam em uma ampla gama de parâmetros.