
A Intel anunciou que seu acelerador Habana Gaudi2 AI continua sendo a única alternativa ao NVIDIA H100 testado no benchmark MLPerf Inference 4.0. Ao mesmo tempo, diz-se que Gaudi2 oferece alto desempenho por dólar, embora sejam os chips NVIDIA os líderes indiscutíveis.
Observa-se que para a plataforma Gaudi2, a Intel continua a expandir o suporte para modelos populares de linguagem grande (LLM) e modelos multimodais. Em particular, para MLPerf Inference v4.0, a corporação apresentou resultados para Stable Diffusion XL e Llama v2-70B.
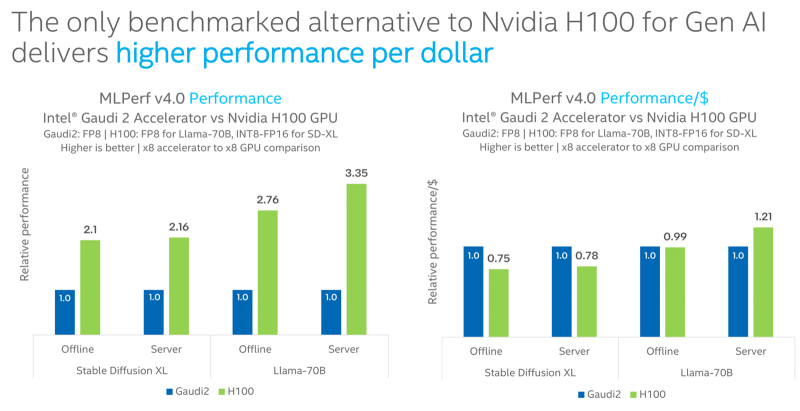
De acordo com os resultados dos testes, no caso do Stable Diffusion XL, o acelerador H100 supera o Gaudi2 em 2,1 vezes no modo offline e 2,16 vezes no modo servidor. Ao processar o Llama v2-70B, o ganho é mais significativo – 2,76 vezes e 3,35 vezes, respectivamente. No entanto, na maioria dessas tarefas (exceto no modo de servidor Llama v2-70B), a solução Gaudi2 supera o H100 em termos de desempenho por dólar.

Fonte da imagem: Intel
No geral, o acelerador Gaudi2 AI em Stable Diffusion XL alcançou 6,26 e 6,25 amostras por segundo para modo offline e modo servidor, respectivamente. No caso do Llama v2-70B, foram alcançados 8.035,0 e 6.287,5 tokens por segundo, respectivamente.
Afirma-se também que os processadores de servidor Intel Xeon Emerald Rapids, graças a melhorias nos componentes de hardware e software no benchmark MLPerf Inference v3.1, demonstram em média valores 1,42 vezes maiores em comparação aos chips Xeon Sapphire Rapids. Por exemplo, para GPT-J com otimização de software e para DLRMv2, foi registrado um aumento no desempenho de aproximadamente 1,8 vezes.