
No evento Intel Vision, foi anunciada a segunda geração de aceleradores Habana AI: Gaudi2 para tarefas de aprendizado profundo e Greco para sistemas de inferência. Ambos os chips agora são fabricados usando um processo de 7 nm em vez de um processo de 16 nm, mas isso está longe de ser a única melhoria.
Gaudi2 vem em um formato OAM e tem um TDP de 600W. Isso é quase o dobro dos 350 watts que Gaudi tinha, mas a segunda geração de chips é bem diferente da primeira. Assim, a quantidade de memória interna triplicou; até 96 GB e agora é HBM2e, portanto, a largura de banda aumentou de 1 para 2,45 TB / s. A quantidade de SRAM dobrou para 48 MB. Complementando a memória estão os mecanismos DMA que podem converter dados no formato desejado em tempo real.

Imagens: Intel/Habana
Existem dois tipos principais de unidades de computação em Gaudi2: Matrix Multiplication Engine (MME) e Tensor Processor Core (TPC). O MME, como o nome indica, é projetado para acelerar a multiplicação de matrizes. TPCs são blocos VLIW programáveis para trabalhar com operações SIMD. Os TPCs suportam todos os formatos de dados populares: FP32, BF16, FP16, FP8, bem como INT32, INT16 e INT8. Há também decodificadores de hardware para HEVC, H.264, VP9 e JPEG.

Uma característica do Gaudi2 é a possibilidade de operação paralela de MME e TPC. Isso, segundo os criadores, acelera significativamente o processo de treinamento de modelos. O software proprietário SynapseAI suporta integração com TensorFlow e PyTorch, e também oferece ferramentas para transferir e otimizar modelos prontos e desenvolver novos, um SDK para TPC, utilitários para monitoramento e orquestração, etc. No entanto, a riqueza do ecossistema de software da mesma NVIDIA ainda está longe.
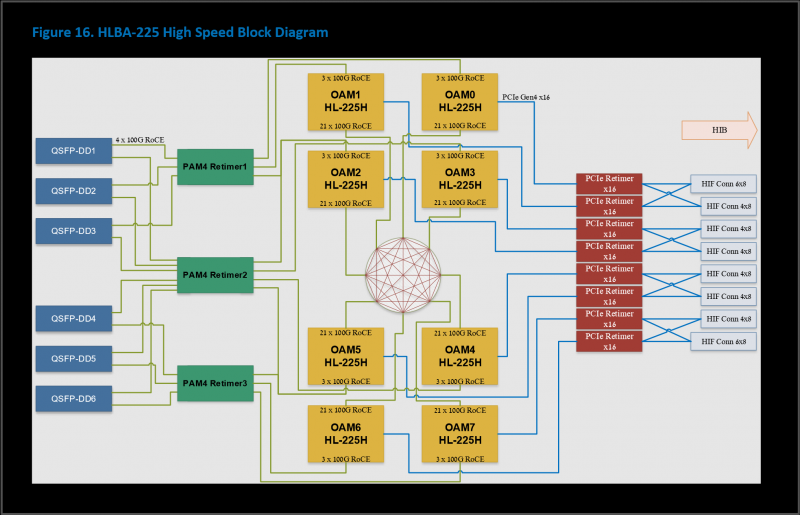
A parte de interface dos novos produtos inclui PCIe 4.0 x16 e imediatamente 24 (anteriormente havia apenas 10) canais de 100 GbE com RDMA ROcE v2, que são usados para conectar aceleradores entre si dentro do mesmo nó (3 canais cada um para cada ) e entre nós. A Intel oferece a placa HLBA-225 (OCP UBB) com oito Gaudi2 a bordo e uma plataforma de IA pronta, ainda baseada em servidores Supermicro X12, mas com novas placas e armazenamento DDN AI400X2.
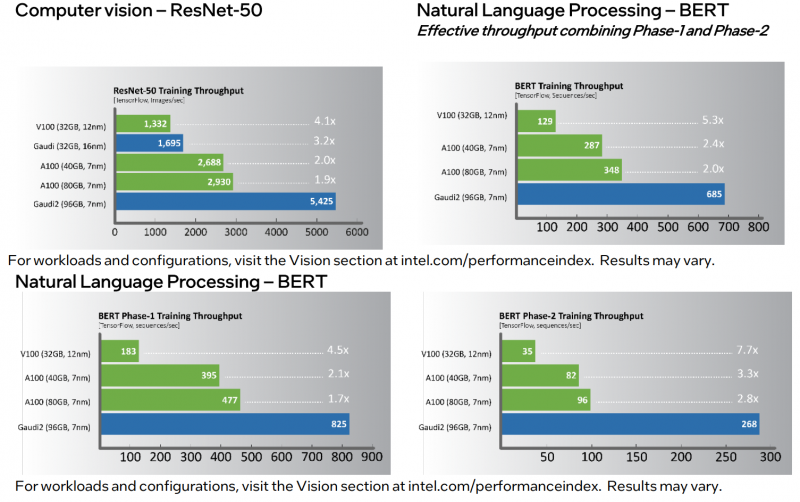
Por fim, o mais interessante é a comparação de desempenho. Em várias cargas de trabalho populares, o novo produto é 1,7 a 2,8 vezes mais rápido que o NVIDIA A100 (80 GB). À primeira vista, o resultado é impressionante. No entanto, os A100 estão longe de ser novos. Além disso, os aceleradores H100 devem ser lançados no terceiro trimestre deste ano, o que, segundo a NVIDIA, será em média três a seis vezes mais rápido que o A100, e graças aos novos recursos, o aumento da velocidade de aprendizado pode ser até nove vezes. Bem, em geral, H100 são soluções mais versáteis.
Gaudi2 já está disponível para clientes Habana, e vários milhares de aceleradores são usados pela própria empresa para otimização de software e desenvolvimento de chips Gaudi3. Greco estará disponível no segundo semestre do ano, e sua produção em massa está prevista para o primeiro trimestre de 2023, então ainda não há muitas informações sobre eles. Por exemplo, é relatado que os aceleradores se tornaram muito menos vorazes em comparação com o Goya e reduziram o TDP de 200 para 75 watts. Isso permitiu que eles fossem empacotados em uma placa de expansão HHHL padrão com uma interface PCIe 4.0 x8.

A quantidade de memória on-board ainda é de 16 GB, mas a transição de DDR4 para LPDDR5 possibilitou aumentar em cinco vezes a largura de banda – de 40 para 204 GB / s. Mas o chip em si agora tem 128 MB de SRAM, e não 40 como o Goya. Ele suporta os formatos BF16, FP16, (U)INT8 e (U)INT4. Existem codecs HEVC, H.264, JPEG e P-JPEG integrados. A mesma pilha SynapseAI é oferecida para trabalhar com Greco. A empresa não forneceu uma comparação do desempenho da novidade com outras soluções de inferência.

No entanto, ambas as decisões de Habana parecem um pouco tardias. O atraso na frente da IA provavelmente é parcialmente “culpado” pela aposta malsucedida nas soluções Nervana – as soluções Habana vieram substituir os aceleradores NNP-T inéditos para treinamento, e novos chips de inferência NNP-I não devem ser esperados. No entanto, o destino da Habana mesmo dentro da Intel não parece sem nuvens, já que suas soluções terão que competir com aceleradores de servidores Xe e, no caso de sistemas de inferência, até com Xeon.