

Nas notícias sobre o anúncio de um coprocessador para SSD da Pliops, projetado para descarregar a CPU dessas tarefas, foi mencionado que outros estão desenvolvendo soluções semelhantes. O conceito de uma “unidade de processamento de dados” (DPU) já é bastante maduro, mas ainda não há unidade na abordagem arquitetônica e de software. O que o mercado moderno de DPU tem a oferecer?
A Mellanox experimentou ativamente o processamento de dados na lateral do adaptador de rede – o dispositivo mais periférico em qualquer sistema de servidor. Agora, fazendo parte da NVIDIA, continua seu trabalho. O principal desenvolvimento da NVIDIA / Mellanox nessa área pode ser chamado de chip BlueField-2, por um lado, fornece a funcionalidade de um SmartNIC típico (uma porta Ethernet 200G ou duas portas da classe 100G) e, por outro lado, suporta o NVMe over Fabrics e descarrega CPUs em tudo. com relação às tarefas de E / S.
Esta solução contém uma matriz de núcleos ARM e unidades ASIC especializadas para acelerar várias funções. Isso é complementado pela presença de 16 GB de RAM DDR4 a bordo. A NVIDIA vê DPUs como o BlueField-2 como parte do pacote “CPU + GPU + DPU”. Usando a arquitetura ARM, essa abordagem é universal e é compartilhada, por exemplo, pelos analistas da Wells Fargo.
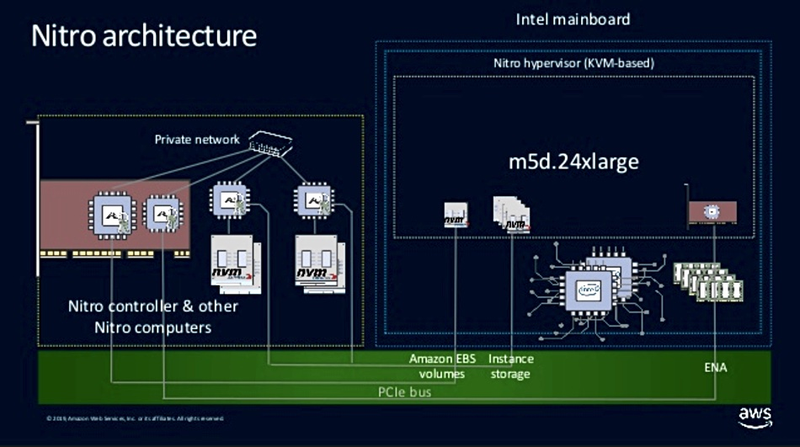
Arquitetura AWS Nitro
Mas existem outros players no mercado que estão implementando ativamente as idéias incorporadas no conceito da DPU. Isso inclui um dos maiores provedores de serviços em nuvem – Amazon Web Services. Ela desenvolveu seu próprio acelerador DPU, a placa Nitro. Em termos gerais, essa solução é semelhante ao NVIDIA / Mellanox BlueField-2, mas o ASIC é usado por outro proprietário da AWS.
As instâncias do Elastic Compute Cloud são executadas usando esses aceleradores PCI Express. A AWS não os limita a uma única oferta, mas fornece uma variedade de versões personalizadas para computação, aprendizado de máquina, armazenamento e processamento de dados e outros cenários. O AWS Nitro também contém implementações NVMe e NVMe-OF; parece que se tornará um local comum para todas as DPUs.

Diamantes de arquitetura
Um projeto semelhante está sendo trabalhado pela Diamanti, que desenvolve uma linha de servidores hiperconvergentes dedicados, otimizados para executar contêineres Kubernetes e executar essa tarefa melhor que os servidores padrão. A série inclui os modelos D10, D20 e G20 e, em geral, não são muito diferentes das máquinas comuns, mas as máquinas Diamanti contêm dois componentes únicos – um controlador NVMe e um controlador Ethernet de 40GbE com suporte Kubernetes CNI e SR-IOV.
As soluções da Diamanti estão interessadas no fato de que usam dois aceleradores separados em vez de um, e isso tem suas vantagens: por exemplo, a velocidade de uma conexão de rede de 40 Gbps pode não ser suficiente no futuro próximo, mas para atender aos requisitos modernos, basta alterar o acelerador de rede no servidor Diamanti, não tocando na placa controladora NVMe, responsável pela comunicação com o subsistema de disco.
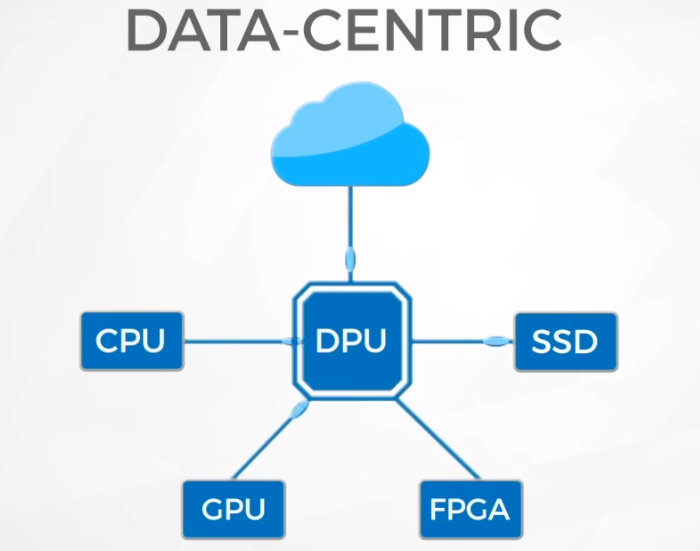
A Fungible propõe fazer da DPU o centro de todo o sistema
Também vale mencionar o Fungible, sobre o qual falamos aos leitores no início deste ano. Foi ela quem foi a primeira a expressar o termo DPU. No momento do primeiro anúncio, em fevereiro de 2020, a Fungible não tinha um acelerador pronto em mãos. Mas o conceito da DPU é sem dúvida o melhor da Fungible: pressupõe que em tais sistemas, todo o tráfego, da rede e do conteúdo enviado da memória à CPU, aos dados enviados à GPU, passará pela DPU.
«Processador de dados “na visualização Fungible se tornará um link que une todos os componentes de um sistema de computação, seja processadores, GPUs, aceleradores FPGA ou matrizes de memória flash. A empresa planeja usar um barramento TrueFabric de baixa latência proprietário como sistema de interconexão. A Fungible deve apresentar uma solução pronta este ano.
Arquitetura Pensando Capri
Finalmente, a Pensando, que iniciou uma parceria com o renomado fornecedor de armazenamento NetApp no final de 2019, já está enviando o Cartão de Serviços Distribuídos, DSC-100. Eles combinam em um único chip e em uma placa as funções que Diamanti resolve com dois cartões separados; Como já mencionado, essa abordagem tem suas desvantagens – todo o acelerador precisará ser substituído, mesmo que a parte “aceleradora” ainda seja capaz de muito, e apenas uma conexão de rede seja necessária para acelerar.
No coração do DSC-100 está o processador Capri, que no lado da rede fornece um par de portas 100GbE com um buffer de pacote comum. Um processador de dados totalmente programável se comunica com esse buffer, mas o chip também contém núcleos clássicos do ARM, além de aceleradores “rígidos”, por exemplo, um criptográfico. As partes programáveis, rígidas e ARM se comunicam através de um sistema de interconexão coerente conectado ao controlador PCIe e ao conjunto de RAM. Em geral, a solução se assemelha ao NVIDIA / Mellanox BlueField-2.

Infelizmente, nenhuma das soluções descritas ainda se tornou padrão do setor. Cada um deles tem suas próprias vantagens e desvantagens e, mais importante, uma parte de software incompatível. Isso torna a implementação de DPUs em estruturas existentes um processo bastante difícil: não se deve confundir a escolha de um fornecedor e desenvolvedor e, além disso, são necessários custos de compra, instalação e manutenção e suporte separados.
Somente gigantes como a AWS podem fornecer totalmente a DPU perfeita para suas tarefas. Em outras palavras, “coprocessadores de dados” ainda são dispositivos de nicho. Para que eles se tornem realmente populares, é necessário um único padrão de arquitetura unificada – o mesmo que proporcionou a versatilidade e a compatibilidade cruzada de processadores gráficos ao mesmo tempo.