

Por muito tempo, a NVIDIA tem sido a líder no campo do uso de arquiteturas gráficas para computação, no entanto, a antiga rival AMD não vai desistir de suas posições. Em resposta ao anúncio da arquitetura Ampere e dos aceleradores A100 de próxima geração baseados nela, a AMD respondeu hoje com o anúncio do primeiro acelerador do mundo baseado na arquitetura CDNA – o ultra-poderoso processador Instinct MI100.
Por muito tempo, a abordagem para projetar chips gráficos permaneceu unificada, mas rapidamente ficou claro que o que é bom para jogos nem sempre é bom para computação, e algumas possibilidades para aplicativos não relacionados à renderização de gráficos 3D são simplesmente redundantes. Exemplos são módulos de operações raster (RBE / ROP) ou mapeamento de textura. O que tinha que acontecer aconteceu: os ramos da evolução dos processadores “gráficos” e “computacionais”, que haviam se fundido por um tempo, começaram a divergir novamente. E o novo processador AMD Instinct MI100 pertence ao ramo puramente computacional do desenvolvimento deste tipo de chips.
A AMD agora tem duas arquiteturas principais à sua disposição, RDNA e CDNA, que representam os ramos mencionados do desenvolvimento de GPU. Naturalmente, o novo processador Instinct MI100 herdou muito de seus irmãos evolucionários – em particular, as unidades de execução para instruções escalares e vetoriais: no final, não importa se elas funcionam para calcular gráficos ou para computar outra coisa. No entanto, a novidade também contém uma série de diferenças que permitem reivindicar o título de acelerador baseado em GPU mais poderoso e versátil do mundo.
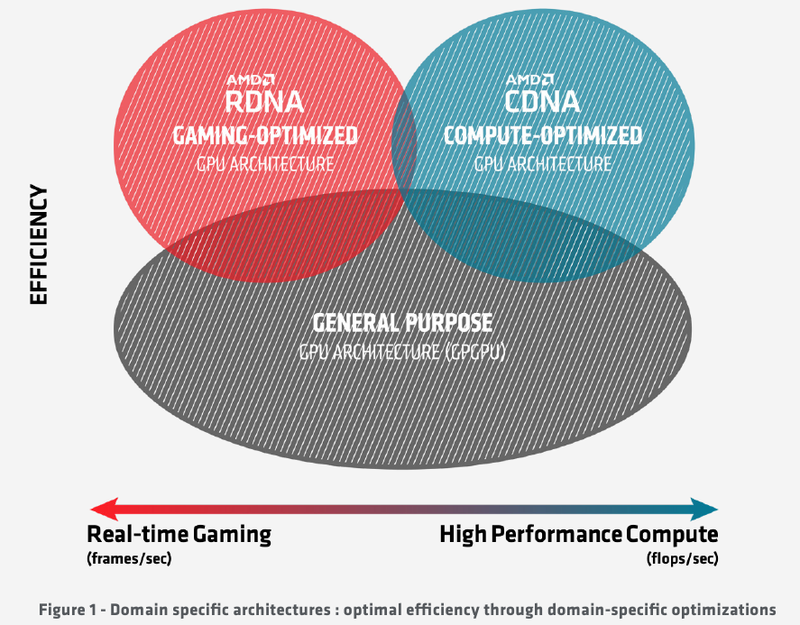
Um diagrama da evolução das GPUs: há uma divergência de sinais
A AMD fortaleceu significativamente sua posição nos últimos anos, e isso se reflete na criação de sua própria infraestrutura IP unificada: o novo chip é feito usando uma tecnologia de processo de 7nm e todos os sistemas de interconexão, internos e externos, no MI100 são baseados no barramento AMD Infinity de segunda geração … Os canais externos têm 16 bits de largura e operam a uma velocidade de 23 Gt / s, mas se nos modelos anteriores do Instinct havia no máximo dois, agora o número de canais do Infinity Fabric foi aumentado para três. Isso facilita a organização de sistemas baseados em quatro MI100s com a organização da comunicação entre processadores de acordo com o esquema “todos com todos”, o que minimiza atrasos.

Aceleradores Instinct MI100 obtêm terceiro canal Infinity Fabric
O processador MI100 herdou a organização geral da arquitetura interna da arquitetura GCN; é baseado em 120 unidades de computação (CU). Com as 64 unidades de sombreador por esquema de 1 CU adotado pela AMD, isso nos permite falar sobre 7680 processadores. No entanto, no nível da unidade de computação, a arquitetura foi significativamente reprojetada para melhor atender aos requisitos de um acelerador de computação moderno.
Além dos blocos padrão para executar instruções escalares e vetoriais, um novo módulo de matemática de matriz, o chamado Matrix Core Engine, foi adicionado, mas todos os blocos de função fixos foram removidos do silício MI100: rasterização, mosaico, caches gráficos e, claro, saída de exibição. O mecanismo universal para codificação e decodificação de formatos de vídeo, no entanto, foi preservado – é frequentemente usado em cargas de trabalho computacionais associadas ao processamento de dados multimídia.
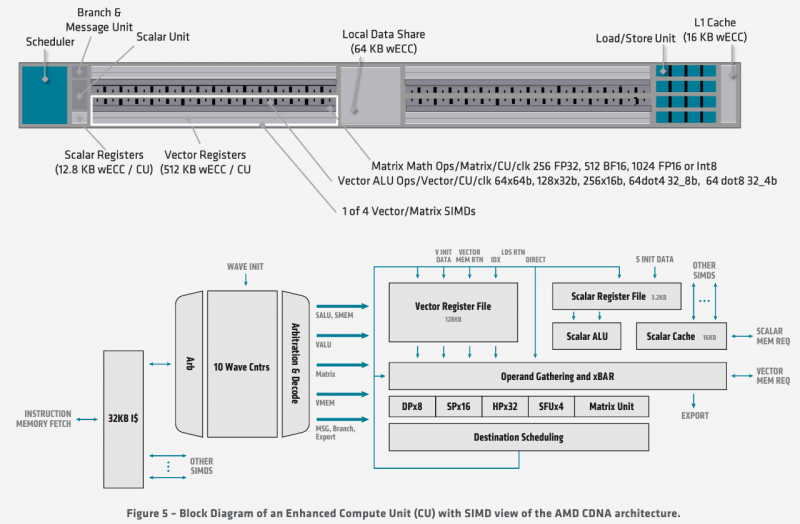
Diagrama de blocos de módulos computacionais em MI100
Cada CU contém um bloco de instruções escalares com seu próprio arquivo de registro e cache de dados, e quatro blocos de instruções vetoriais, otimizadas para cálculos no formato FP32 por blocos análogos. Os módulos vetoriais têm 16 threads de largura e processam 64 threads (a chamada frente de onda na terminologia da AMD) em quatro ciclos de clock. Mas o mais importante na arquitetura do novo processador são os novos blocos de operações de matriz.
A presença de Matrix Core Engines permite que o MI100 funcione com um novo tipo de instruções – MFMA (Matrix Fused Multiply-Add). As operações em matrizes de tamanho KxN podem conter vários tipos de dados de entrada: os modos INT4, INT8, FP16, FP32 são suportados, bem como o novo tipo Bfloat16 (bf16); o resultado, entretanto, é produzido apenas no formato INT32 ou FP32. O suporte para tantos tipos de dados foi introduzido para versatilidade e o MI100 será capaz de mostrar alto desempenho em vários tipos de cenários computacionais.
Infinity Fabric 2.0 aprimora ainda mais o desempenho do MI100
Cada CU tem seu próprio planejador, unidade de filial, 16 módulos de carregamento-armazenamento, bem como caches L1 e de compartilhamento de dados de 16 e 64 KB, respectivamente. Mas o cache de segundo nível é comum para todo o chip, tem uma associatividade de 16 e um volume de 8 MB. A taxa de transferência agregada do cache L2 atinge 6 TB / s.
Quantidades mais sérias de dados já caem no subsistema de memória externa. No MI100, é o HBM2 – o novo processador suporta a instalação de quatro ou oito conjuntos HBM2, operando a uma velocidade de 2,4 Gt / s. A largura de banda total do subsistema de memória pode chegar a 1,23 TB / s, o que é 20% mais rápido do que os aceleradores de computação AMD anteriores. A memória tem capacidade para 32 GB e suporta correção de erros.
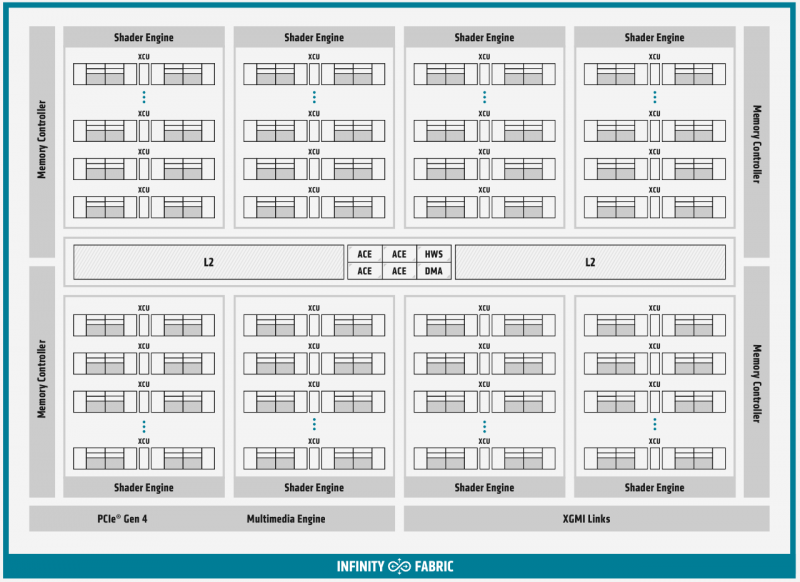
Diagrama de blocos geral do Instinct MI100
«O cérebro do chip Instinct MI100 é composto por quatro processadores de comando (ACE no diagrama de blocos). Sua tarefa é aceitar o fluxo de comandos da API e distribuir ordens de serviço para módulos computacionais separados. Para se conectar ao processador host do sistema, o MI100 tem um controlador PCI Express 4.0, que fornece uma taxa de transferência de 32 GB / s em cada direção. Assim, o acelerador Instinct MI100 se sentirá “mais confortável” com a CPU EPYC AMD de segunda geração ou em sistemas baseados no IBM POWER9 / 10.
Livrar-se de blocos arquitetônicos desnecessários e otimizar a arquitetura para computação no maior número possível de formatos permite que o Instinct MI100 reivindique universalidade. Aceleradores com tais recursos, a AMD corretamente acredita, se tornarão um bloco de construção importante no ecossistema de máquinas HPC de próxima geração pertencentes à classe exascale. A AMD afirma que este é o primeiro acelerador capaz de desenvolver mais de 10 teraflops no modo de dupla precisão FP64 – o valor máximo é de 11,5 teraflops.
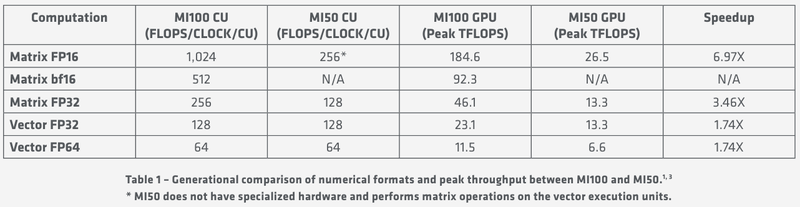
Indicadores de desempenho específicos e de pico MI100
Em formatos menos precisos, o novo produto é proporcionalmente mais rápido, e os cálculos matriciais são especialmente bons nisso: para FP32, o desempenho chega a 46,1 teraflops, e no novo, otimizado para tarefas de aprendizado de máquina bf16 – até 92,3 teraflops e, além disso, aceleradores Instinct da geração anterior eles não podem realizar tais cálculos. Dependendo dos tipos de dados, a superioridade do MI100 sobre o MI50 varia de 1,74x a 6,97x. No entanto, o NVIDIA A100 ainda é visivelmente mais rápido nessas tarefas, mas no FP64 / FP32 eles perdem.