

Ao construir e manter uma infraestrutura dessa escala, é necessário levar em consideração uma série de parâmetros, entre os quais mesmo o menor à primeira vista pode afetar drasticamente o custo total de propriedade (TCO), que todos os hiperscalers se esforçam para minimizar. Stanislav Zakirov, Diretor de Desenvolvimento de Infraestrutura da VK, nos contou como ocorre o processo de escolha dos equipamentos e porque decidimos tentar um sistema de refrigeração líquida (LSS) em servidores.
No caso do VK – e este não é apenas o VKontakte, mas também uma série de outros serviços, incluindo Odnoklassniki, Mail.RU, Citymobil, Delivery Club, etc. – a abordagem para construir infraestrutura mudou significativamente nos últimos anos. Um laboratório de testes separado é responsável pela escolha da plataforma de hardware, que estuda a massa do hardware, incluindo aqueles que ainda não foram lançados. O desempenho por watt é um dos parâmetros mais importantes na seleção, pois esse parâmetro tem um efeito dramático nos custos operacionais futuros e, portanto, na estimativa de TCO.
A seleção inicial é baseada em testes sintéticos, mas então os candidatos caem nas mãos de engenheiros que observam como eles lidam com carga real, dados e em um ambiente real. Muitas métricas são removidas da CPU, incluindo, por exemplo, nível de carga, tempo de resposta, perda de cache, etc. O principal requisito é que o novo sistema lide com as tarefas dos clientes internos mais exigentes e grandes da forma mais eficiente possível em termos de custo por unidade de desempenho útil.
O poder que é desnecessário para tarefas menos exigentes ainda é utilizado em certa medida, o que é facilitado pela transição para o modelo de nuvem (em particular, conteinerização e virtualização) e soluções definidas por software, aliadas a uma orquestração competente. Na verdade, neste estágio de desenvolvimento, VK chegou a um fim lógico – todas as novas máquinas têm uma plataforma unificada com uma opção de processador único, na qual nós de CPU, nós de GPU e sistemas de armazenamento são construídos.
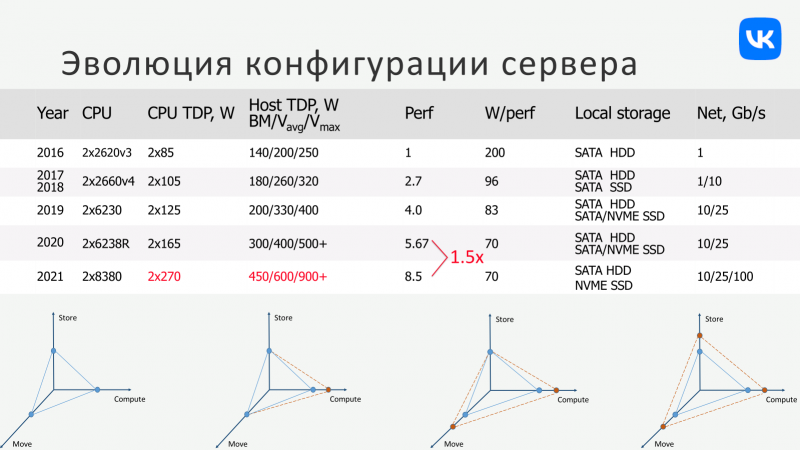
Imagem: VK
A geração atual de servidores é baseada em plataformas de soquete duplo com Intel Xeon Platinum 8380 (40C / 80T, 2,3 / 3,40 GHz, 60 MB de cache L3, TDP 270 W). Simplificando, ele usa o processador Intel mais antigo do momento. Agora existe apenas uma CPU e a plataforma também é uma. Eles estão sendo adquiridos cada vez mais em grandes volumes, o que é muito mais conveniente e lucrativo em termos de serviço e permite que você obtenha um ganho de preço significativo. Tão significativo que mesmo o uso de duas ou três plataformas com CPUs e periféricos diferentes nas condições atuais e com as solicitações VK atuais acaba sendo, em média, mais caro.
E isso mesmo sem levar em consideração fatores adicionais, como compras adicionais de CPUs e outros componentes no futuro, porque quanto maior o alcance usado, mais difícil será fazer isso. Mas cada hiperscaler tem sua própria matemática muito interessante. Você pode olhar, por exemplo, no design dos servidores Meta (Facebook) OCP, ou ainda melhor, nas novas plataformas AWS, que “chegaram ao topo”. A AWS usa principalmente seus próprios data centers e está mudando ativamente para uma plataforma com suas próprias CPUs Graviton3. O que nos traz à questão dos custos operacionais, ou melhor, do equilíbrio entre CAPEX e OPEX.

Imagem: VK
A VK agora tem apenas dois centros de dados próprios – em Moscou e São Petersburgo, e todo o resto cai em sites alugados em outros centros de dados, e nem sempre os mais novos. Isso tem suas consequências. O aumento da densidade da capacidade de computação em um único nó leva à necessidade de cálculos mais complexos para energia e resfriamento no rack e, ainda, no data center. Assim, para a nova plataforma, optou-se por um chassi 2U simplesmente porque é possível instalar ventiladores maiores nele, reduzindo a velocidade de rotação e o consumo de energia, que cresce rapidamente conforme aumenta a carga no hardware.
Aliás, em plataformas modernas com um par de CPUs, cujo TDP se aproxima de 300 W (ainda maior no pico), e outros componentes (mesmo até 200 W), apenas os ventiladores podem consumir outro terço do nível de consumo do próprio hardware. Ao mesmo tempo, ainda é relativamente fácil dimensionar a energia de 5 a 7 kW por rack, típico para data centers comerciais (com sua carga de energia média real, grosso modo, no nível de dois terços). Mas o resfriamento nem sempre é o caso. E ainda não falamos sobre sistemas com aceleradores, onde apenas o “silício” consome 3 kW ou mais.
Saída? A primeira maneira é reduzir drasticamente a densidade de colocação de equipamentos em racks, que na maioria das vezes não é lucrativa do ponto de vista do TCO, tanto em seu data center quanto para proprietários alugados, especialmente quando eles estão localizados onde o custo do terreno é um custo significativo item ao construir um data center. Além disso, complica a manutenção da conectividade e aumenta o custo da infraestrutura de rede. A segunda é criar seus próprios nós e data centers otimizados, onde você já pode economizar na escala de implantação, como fazem os grandes hiperescaladores. O terceiro é melhorar a eficiência do resfriamento. Mas como exatamente é uma questão separada.
Pode ser caro aumentar a produção de frio para o resfriamento de ar tradicional e nem sempre é possível persuadir o operador do data center (o seu ou de outra pessoa, novo ou antigo) a instalar, digamos, mais alguns chillers (e isso não é apenas espaço extra, mas também eletricidade)., e muitas vezes nem mesmo é tecnicamente viável. Uma opção de compromisso é o LSS, que tem uma eficiência maior, mas que, se não for um sistema de imersão, pode ser implementado com relativa facilidade mesmo na infraestrutura existente. Sim, nem sempre e nem em todos os lugares. Sim, as despesas de capital serão ligeiramente maiores do que as do “ar” clássico, mas, a longo prazo, você pode economizar significativamente em salas de cirurgia.

De um modo geral, para cada caso individual é necessário fazer cálculos separados, mas se houver uma oportunidade de testar o LSS nas instalações existentes e houver planos para expandir ainda mais a infraestrutura, onde sistemas poderosos com aceleradores não podem ser dispensados, então tal uma chance não deve ser perdida. A mesma situação ocorre agora com a VK, que, em particular, se prepara para a construção de seu terceiro data center próprio, que ficará localizado em Domodedovo, próximo a Moscou. Para estudar as possibilidades de aplicação prática do LSS, a VK recorreu à empresa RSK, que criou um sistema chave na mão, componentes de projeto próprio: unidades de bombeamento, sistema de distribuição de líquido em rack e blocos de água para CPU com TDP de 270 + W.
No início do verão de 2020, o sistema de teste foi implantado no data center de Moscou VK (longe de ser o mais novo) – dois racks com diferentes tipos de nós para 30 kW no total, cada um dos quais tinha 5 kW para ar e 10 kW para “Água”. Demorou meio dia para trocar os sistemas e o LSS estava na versão mínima, ou seja, sem redundância. Em seguida, essas máquinas foram incluídas no pool geral e estavam executando (e ainda executando) cargas normais de produto. Depois de examinar o comportamento e a operação de máquinas e LSS, encontrar e eliminar todas as áreas problemáticas, bem como depurar todo o conjunto de software e hardware, a empresa decidiu expandir a gama de testes – agora há 60 carros em Moscou e mais 40 em St Petersburgo.

No verão de 2021, vários outros racks com LSS em servidores apareceram em Moscou. Incluindo duas dúzias de nós de GPU: as mesmas duas CPUs de topo + oito aceleradores PCIe de 300 W cada. Neste caso, todos os componentes quentes em tais conjuntos são resfriados com líquido. O próprio circuito aumentou sua capacidade em cinco vezes e recebeu redundância: duas torres de resfriamento foram instaladas para resfriar o líquido e duas unidades de bombeamento foram instaladas para criar a circulação do refrigerante. Além disso, as unidades de bombeamento RSK são únicas – esta é a única solução que combina as bombas dos circuitos interno e externo em uma unidade, juntamente com um esquema de controle de eficiência energética. Todo o sistema de resfriamento, incluindo as torres de resfriamento e bombas de ambos os circuitos, consome na proporção do número de servidores LSS instalados e da carga de calor real.
Após a atualização, os engenheiros do laboratório de teste novamente tiveram que sofrer com a depuração de todo o sistema em diferentes níveis. A começar pelo facto de a transferência de GPU para LSS ser muito mais difícil do que CPU, e terminar com a criação de um sistema de monitorização avançado, que permitiu perceber porque é que tudo corria bem nos testes sintéticos e surgiam problemas com cargas reais. Isso é importante porque os aceleradores estão envolvidos no aprendizado de máquina distribuído, e perder até mesmo um deles é frustrante.

Ao mesmo tempo, foi confirmado que com o crescimento da escala de implementação do LSS, eles estão se tornando cada vez mais uma solução lucrativa – cada quilowatt no novo sistema de teste de 100 kW com redundância é muito mais barato do que no antigo 20- sistema kW sem ele. E uma unidade com refrigeração exclusivamente a ar, de acordo com os testes, na verdade não consome menos do que com LSS (incluindo componentes internos e externos), e é muito mais caro dimensionar apenas “ar”.
Tal abordagem híbrida com a extração de calor usando LSS dos componentes mais quentes específicos (em média, eles respondem por 85% da fonte de alimentação e, consequentemente, resfriamento em um sistema específico) torna, por exemplo, muito mais fácil mudar para gratuito resfriamento (inclusive com adiabáticos) … O PUE resultante é de aproximadamente 1,1 versus o tradicional 1,35-1,5. Portanto, mesmo que o CAPEX para LSS seja maior, o CAPEX para o data center como um todo (especialmente levando em consideração os componentes de TI) pode ser menor, e a economia em OPEX por um período de 3 a 5 anos pode recuperar completamente o aumento dos custos de capital.

E, por si só, a redução no consumo específico de energia de pico permite menos gastos com a compra de capacidades garantidas, UPS e geradores. Além disso, há uma série de fatores adicionais nas despesas de capital. Por exemplo, para “água” é pelo menos todo o “encanamento”, equipamento adicional de nós e racks, etc. No caso de “ar” apenas, estes são radiadores e ventiladores muito caros para altos níveis de TDP e uma densidade mais baixa de equipamentos nos racks.
No caso do VK, os cálculos mostram que a introdução do LSS é uma solução eficaz em termos de parâmetros-chave. Isso não significa que todos os outros serão exatamente iguais. Até mesmo a plataforma atual pode ser usada com bastante conforto em data centers antigos. Mas a VK já tem planos para a próxima geração de hardware, cujo TDP está crescendo (CPU 300+ W, GPU 500+ W), mas a temperatura crítica está caindo. E precisamos nos preparar para seu aparecimento agora, e a transição para o LSS para eles será ainda mais eficaz do que na geração atual.

E a capacidade de usar exatamente o equipamento certo (e de última geração) é importante para o desenvolvimento do negócio como um todo. Como realmente vai acabar, agora ninguém está pronto para dizer. Até o momento, os planos são equipar o LSS com uma parte do futuro data center, tendo adquirido experiência em implantação realmente em massa e operação de nós com “água”, bem como o resto da infraestrutura – por exemplo, sistemas de armazenamento e os rede não deve ser esquecida também. O principal é que não há mais medo de usar LSS no data center. Há uma compreensão das fraquezas e pontos comuns de falha, há uma compreensão de como resolver problemas.