

A era dos processadores completamente monolíticos está chegando ao fim gradualmente, pois a capacidade da tecnologia de silício de criar chips gigantescos também atingiu seu limite. Na Conferência Internacional de Circuitos de Estado Sólido (ISSCC 2022), tanto a AMD quanto a Intel revelaram alguns detalhes internos sobre seus novos processadores de servidor: Milan-X e Sapphire Rapids. E o portal alemão Hardwareluxx falou sobre as reportagens tanto do primeiro quanto do segundo.
E se a AMD mudou para um layout de chiplet há muito tempo, então para a Intel essa abordagem é nova e, em geral, forçada – Sapphire Rapids na implementação clássica exigiria um cristal monolítico de tamanho impensável, o que reduziria drasticamente o rendimento de produtos adequados. No entanto, o novo Xeon já é composto por quatro cristais básicos com área de cerca de 400 mm2.
Imagem: Twitter/Locuza_
Eles são fabricados usando o processo Intel 7 (variação de 10 nm), o que permitiu principalmente aumentar a densidade da interconexão, o que é fundamental para atingir o mínimo de latência entre os blocos na montagem. Ecos com problemas de processo ainda se fazem sentir: embora o die base do Sapphire Rapids seja relativamente pequeno, a Intel decidiu jogar pelo seguro e aumentar o grau de redundância para alguns blocos.
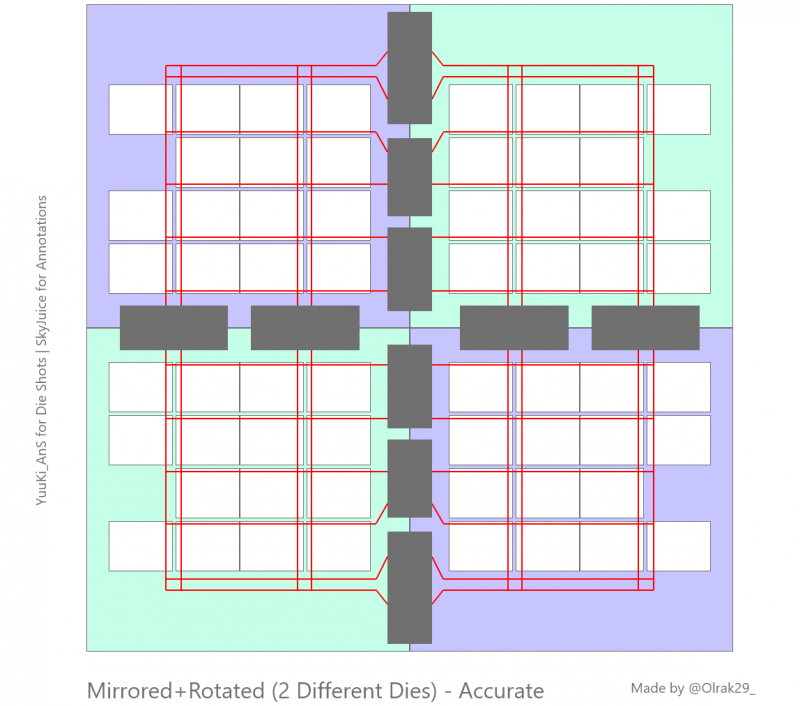
Imagem: Twitter/Olrak29_
Na verdade, a empresa produz dois cristais espelhados que são conectados por dez interfaces EMIB – pares (verticalmente) ou triplos (horizontal) de conexões com a fábrica Multi-Die Fabric IO. O consumo mínimo dessa tecnologia é de apenas 0,5 J/byte, e a frequência de fábrica pode variar dinamicamente de 800 a 2500 MHz. A taxa de transferência total é de 10 TB/s (20 × 500 GB/s), a latência não excede 10 ns.
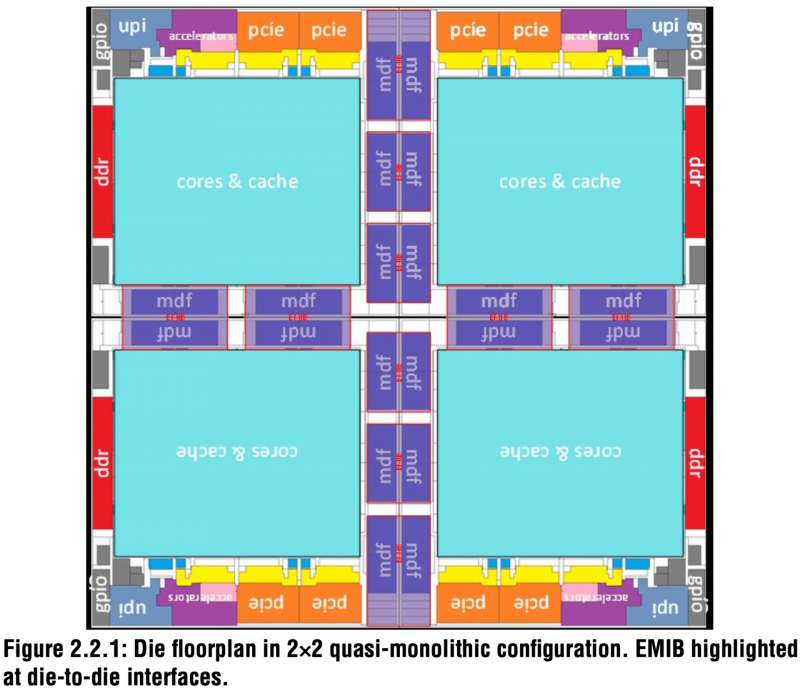
Imagens: Hardwareluxx
A AMD, por outro lado, não apenas abandonou os cristais monolíticos, mas também mudou para um layout de chiplet assimétrico da segunda geração, no qual o cristal de E / S não é apenas separado dos cristais com núcleos, mas também é produzido usando uma fabricação diferente processo (14 nm versus 7 nm). E no Zen 3, os caches também foram compactados – 32 MB L3 para oito núcleos. Os núcleos e o cache são conectados por um barramento em anel bidirecional com largura de banda de 2 TB/s.

E os próprios caches passaram a usar células mais compactas e adquiriram duas fileiras de conexões TSV para instalação de outro chip SRAM de 41 mm2 usando tecnologia TSMC SoIC, ou seja, o mesmo 3D V-Cache que permite aumentar a capacidade L3 de 32 para 96 MB. Curiosamente, a conexão com o chip inferior é realizada apenas devido à adesão dos pilares-condutores de cobre, não é necessária solda. Na verdade, a matriz CCD já acabada é simplesmente polida para expor os condutores TSV, após o que a matriz SRAM superior é colocada sobre ela.
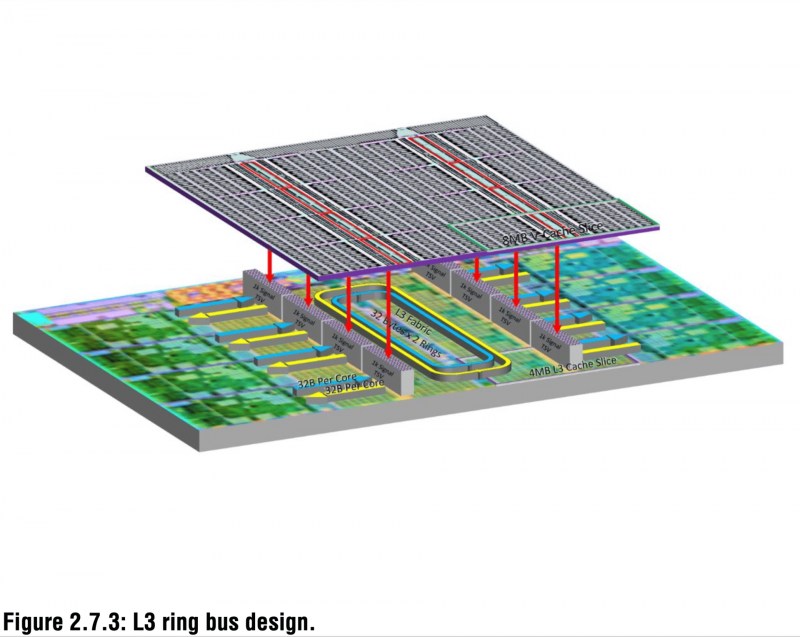
Ao mesmo tempo, os próprios CCDs também receberam uma série de otimizações de “silício” e algumas transformações na estrutura. Eles são mais finos e onde SRAM adicional não é necessária, agora são usados calços para equalizar a altura. E os mesmos condutores TSV também são usados para alimentar o chip SRAM externo. A largura de banda total de conexão do 3D V-Cache é igual a 2 TB/s, e dentro dele é organizado em blocos de 512 × 128 KB. Mas o principal é que a “penalidade” por acessar a memória cache estendida não deve exceder quatro ciclos.
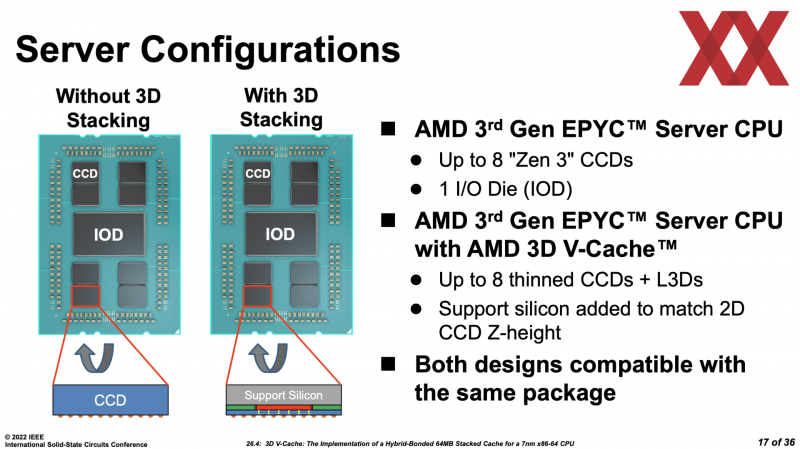
Ambas as empresas buscam soluções originais ao criar novos processadores. Mas se a Intel recusa a solidez com alguma dificuldade e em Sapphire Rapids o desejo de manter o nível mais alto possível de conectividade dentro da CPU é claramente visível, então a AMD parece estar jogando LEGO. Com acesso aos processos avançados de fabricação da TSMC, os Reds têm a capacidade de vasculhar combinações de dados em busca do design que melhor corresponda à visão da empresa do processador ideal.