
A plataforma Jetson AGX Orin foi lançada no final de março. De acordo com a NVIDIA, esta é a melhor solução compacta, econômica e de alto desempenho para robótica e veículos autônomos usando soluções modernas de IA. A empresa tem boas razões para isso.
O coração da plataforma é um chip de 7 nm (17 bilhões de transistores), que inclui 12 núcleos Arm Cortex-A78AE, especialmente projetados para aplicações que exigem maior confiabilidade. A parte GPU é representada por 2048 núcleos Ampere e 64 núcleos tensores. Na versão completa, esse chip desenvolve 275 TOPS em cálculos INT8 a uma frequência de 2,2 GHz para a CPU e 1,3 GHz para a GPU, mas a NVIDIA oferece várias soluções baseadas na nova arquitetura.
Imagens: NVIDIA
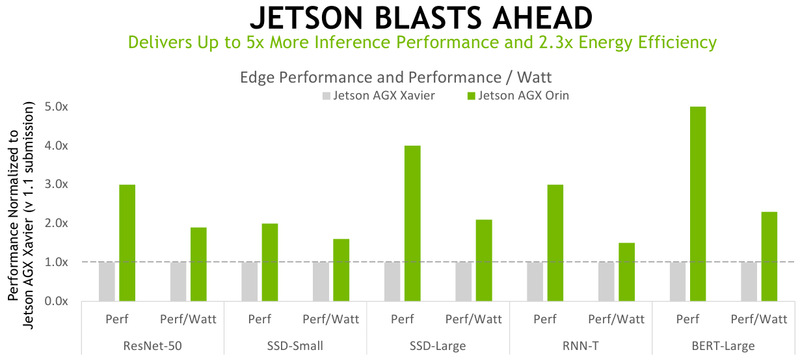
A versão mais antiga é cinco vezes mais rápida e duas vezes mais eficiente em termos de energia do que o Jetson AGX Xavier – a empresa trouxe os resultados dos testes do AGX Orin para o MLPerf Inference V2.0, onde a nova plataforma lidou facilmente com seu antecessor e também não deixou quase nenhuma chance para o pacote Qualcomm Snapdragon 865 e Cloud AI 100 (DM.2). No entanto, a versão de servidor mais antiga do acelerador ainda se mostrou mais eficiente em termos de energia em comparação com o NVIDIA A100 em alguns outros testes.
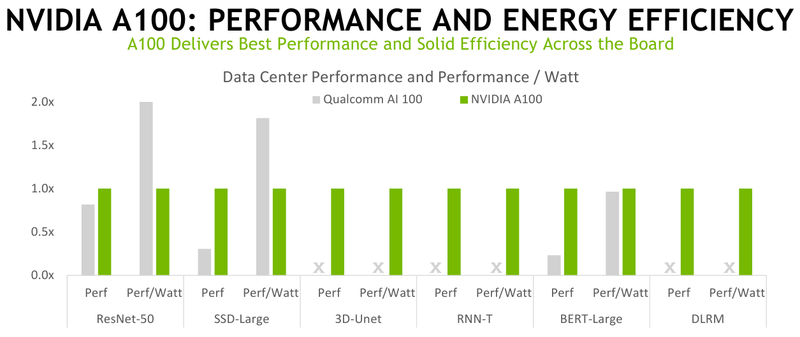
Além disso, a NVIDIA publicou resultados de testes para o acelerador A30. A empresa enfatiza especificamente vários pontos. Assim, o desempenho do A100 nas plataformas Arm e x86-64 acabou sendo quase idêntico – o esforço de três anos para portar o software para o Arm não foi em vão. Além disso, a otimização de software por si só teve um aumento de até 50% no ano passado. Ao mesmo tempo, a NVIDIA anunciou que agora a plataforma de inferência Triton só pode rodar na CPU, sem exigir a presença obrigatória de uma GPU.
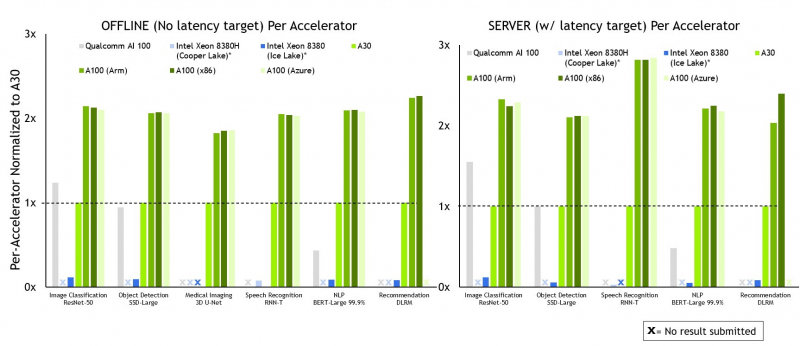
Além disso, a NVIDIA, em conjunto com a Microsoft, mostrou que o desempenho do A100 em instâncias do Azure difere um pouco do que pode ser obtido usando hardware bare-metal. Por fim, a empresa demonstrou o desempenho do Multi-Instance GPU (MIG) – ao usar todas as sete instâncias, o desempenho de cada uma é cerca de 98% do que está disponível ao usar apenas uma instância.
Infelizmente, o próprio pacote MLPerf ainda está amplamente focado em soluções de hardware NVIDIA – na nova série de testes há muito poucos resultados de outros grandes players, embora mais de 3900 medições tenham sido feitas no total, das quais 2200 também incluíram dados de consumo de energia. A mesma Qualcomm não teve desempenho em todas as disciplinas, e o Google realmente se recusou a participar desta rodada.