
O sucesso da Cerebras Systems com seus descendentes incomuns, processadores Cerebras supergrandes que ocupam todo um substrato de silício, é no mínimo interessante de se observar. Seus sistemas são incomuns, mas no campo de aprendizado de máquina eles parecem não ter igual – uma única plataforma Cerebras CS-2 pode substituir quase um cluster inteiro ao treinar um modelo grande. E a empresa provou isso por ação, estabelecendo um novo recorde.
A essência do registro é que o maior modelo de IA do mundo já treinado em um único dispositivo foi treinado no Cerebras CS-2 (sistemas de cluster não contam). É claro que a “singleness” do CS-2 é um tanto arbitrária, mas ainda pode ser considerada como tal, pois um gabinete de equipamento CS-2 contém exatamente um chip WSE-2 e o complexo HPE Superdome Flex, que “alimenta” dados a ele, é considerado auxiliar.
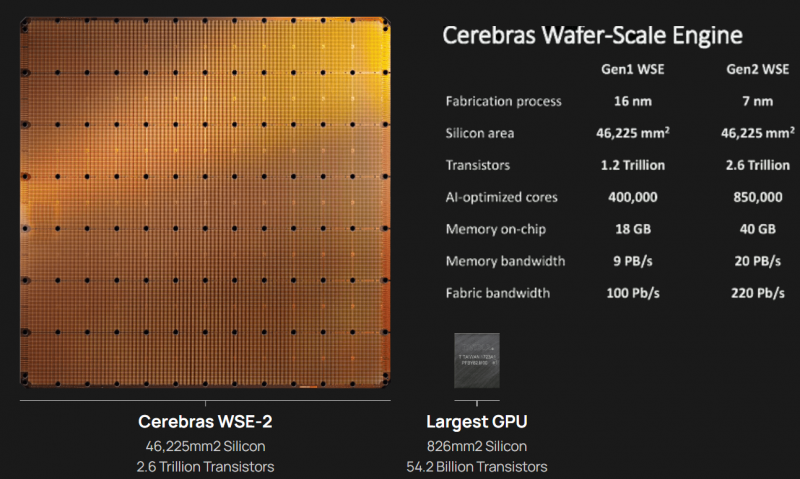
Características comparativas de WSE-1 e WSE-2. Fonte: Cerebras Systems
Estamos falando de treinar um modelo com 20 bilhões de parâmetros, o que nenhum outro sistema no mundo pode fazer. Ao abrir o acesso ao treinamento de redes neurais tão complexas, o Cerebras está atendendo pesquisadores de máquinas de linguagem natural, pois o tempo de treinamento para um modelo sério pode ser reduzido de meses para minutos, eliminando a necessidade de particionamento demorado do modelo entre os nós de um sistema de cluster tradicional – tudo isso é executado no modo “monolítico”.

Projeto do CS-2 e alguns de seus parâmetros técnicos. Fonte: Cerebras Systems
Além disso, modelos desse tamanho exigem muito dinheiro – nem todo pesquisador tem orçamento suficiente para alugar um cluster. Mas o CS-2 democratizará até modelos enormes como GPT-3 1.3B, GPT-J 6B, GPT-3 13B e GPT-NeoX 20B. Seu lançamento tornou-se possível com a última atualização do software proprietário Cerebras Software Platform. Os geneticistas da GSK também estão entusiasmados com a nova oportunidade, usando enormes conjuntos de dados.
Lembre-se que o coração do CS-2, o processador WSE-2, é legitimamente considerado o maior do mundo – contém 850 mil núcleos otimizados para tarefas específicas de aprendizado de máquina. Para “alimentar” esse neuroprocessador com dados e eliminar o tempo de inatividade, são usados 12 canais de uma só vez a uma velocidade de 100 Gb / s. Um superservidor HPE Superdome Flex 280 separado é responsável pelo fornecimento de dados, que por si só tem características muito impressionantes.