
O CEO do Google, Sundar Pichai, discutiu o volume de processamento de IA que a empresa realiza em sua conferência I/O 2026 e propôs uma maneira de economizar significativamente dinheiro nesse aspecto: a mudança para o novo modelo Gemini 3.5 Flash.
Fonte da imagem: blog.google
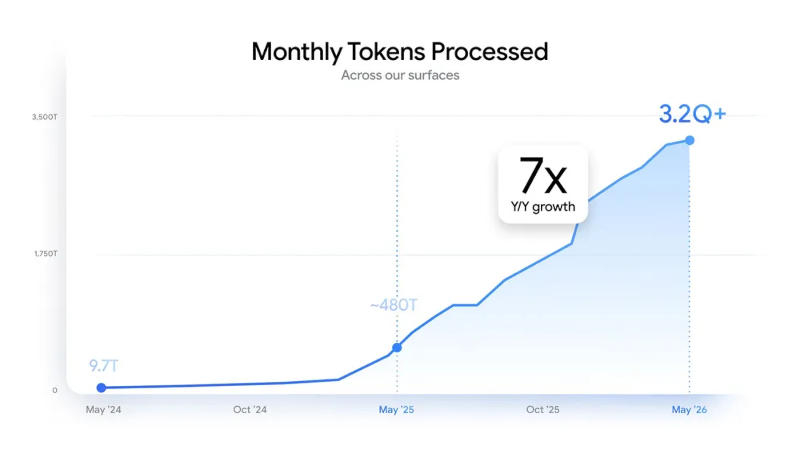
Há dois anos, a infraestrutura do Google processava 9,7 trilhões de tokens por mês. No ano passado, esse número cresceu para 480 trilhões e, atualmente, a empresa processa 3,2 quatrilhões de tokens por mês. Mensalmente, 8,5 milhões de desenvolvedores criam aplicativos usando os modelos do Google Gemini, gastando 19 bilhões de tokens por minuto em chamadas de API. Nos últimos 12 meses, mais de 375 clientes gastaram mais de 1 trilhão de tokens cada — a demanda por IA por parte das empresas permanece alta. O processamento de tais algoritmos em volumes tão expressivos é possível graças aos investimentos maciços do Google em data centers, poder computacional e seus próprios aceleradores TPU. Em 2022, os investimentos de capital da empresa totalizaram US$ 31 bilhões por ano. Até o final deste ano, esse valor deverá chegar a entre US$ 180 bilhões e US$ 190 bilhões.
Demi Hassabis, chefe do Google DeepMind, substituiu o CEO da empresa na apresentação. Ele explicou que o novo modelo Gemini Omni é um passo importante rumo à Inteligência Artificial Geral Avançada (IAGA). A plataforma combina as capacidades do gerador de imagens Nano Banana, do gerador de vídeos Veo, do gerador de mundos Genie e de um sistema de simulação física, descrevendo com precisão os mecanismos de interação entre objetos, levando em consideração a energia cinética e a gravidade. Pichai então falou sobre a expansão da tecnologia SynthID — a rotulagem de materiais gerados por IA. O Google decidiu dar suporte à tecnologia C2PA: na busca ou no Chrome, os usuários podem circular materiais e perguntar se foram criados por IA. OpenAI, Kakao e ElevenLabs anunciaram suporte ao SynthID.

O CEO do Google também discutiu as vantagens do novo modelo Gemini 3.5 Flash. Ele supera o Gemini 3.1 Pro em termos de recursos, mas é quatro vezes mais rápido (289 tokens por segundo) e 12 vezes mais rápido em aplicações de geração de código Antigravity. Os maiores clientes do Google Cloud processam aproximadamente 1 trilhão de tokens por dia — transferir 80% de suas cargas de trabalho para o Gemini 3.5 Flash representará uma economia de mais de US$ 41 bilhões anualmente. O novo modelo de IA também alimenta com eficiência o agente Gemini Spark, que pode executar tarefas em segundo plano 24 horas por dia, 7 dias por semana, consumindo relativamente poucos tokens. Até o final do verão (do hemisfério norte), o aplicativo estará integrado ao navegador Chrome.
Por fim, o vice-presidente de buscas discutiu os recursos do Gemini 3.5 Flash em buscas: o serviço agora pode aceitar dados de qualquer formato como consultas, iniciar agentes de busca que podem monitorar atualizações e até mesmo gerar miniaplicativos diretamente nos resultados de busca usando o serviço Antigravity.