
Stability AI, desenvolvedora do popular modelo generativo de IA Stable Diffusion, comparou o desempenho do modelo Stable Diffusion 3 em aceleradores populares de data center, incluindo Nvidia H100 Hopper, A100 Ampere e Intel Gaudi2. De acordo com a Stability AI, o Intel Gaudi2 apresentou desempenho aproximadamente 56% melhor que o Nvidia H100.

Fonte da imagem: Intel
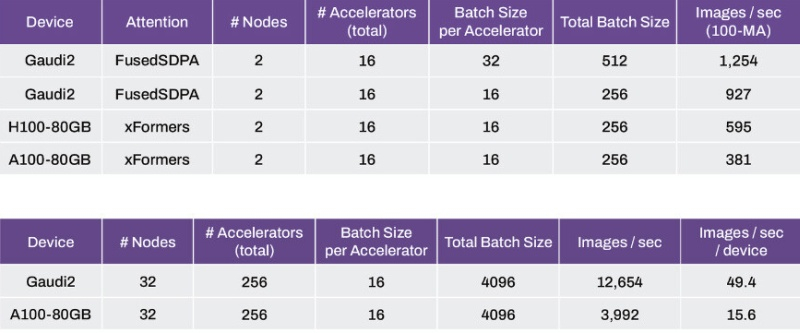
Ao contrário do H100, que é uma GPU superescalar com núcleos tensores CUDA, o Gaudi2 foi projetado especificamente para acelerar IA generativa e modelos de linguagem grande (LLMs). Os testes envolveram pares de clusters, que no total forneceram 16 aceleradores, e os testes foram realizados com um tamanho de lote constante (número de objetos de treinamento) de 16 para cada acelerador (256 no total). Os sistemas Intel Gaudi2 foram capazes de gerar 927 imagens por segundo, em comparação com 595 imagens por segundo para os aceleradores H100 e 381 imagens por segundo para o array A100.
Fonte da imagem: Estabilidade AI
Ao aumentar o número de clusters para 32, o número de aceleradores para 256 e um tamanho de lote de 16 por acelerador (tamanho total 4.096), a matriz Gaudi2 gera 12.654 imagens por segundo ou 49,4 imagens por segundo por acelerador, em comparação com 3.992 imagens. por segundo ou 15,6 imagens por segundo por dispositivo para o array A100 Ampere.

Fonte da imagem: NVIDIA
Deve-se notar que o desempenho dos aceleradores de IA foi medido usando a estrutura PyTorch, e quando a otimização TensorRT é aplicada, os chips A100 produzem imagens até 40% mais rápido que Gaudi2. No entanto, os pesquisadores do Stability AI esperam que, com maior otimização, o Gaudi2 supere o A100. A empresa acredita que interconexão mais rápida e maior capacidade de memória (96 GB) tornam as soluções da Intel bastante competitivas e planeja usar aceleradores Gaudi2 no Stability Cloud.

Fonte da imagem: techpowerup.com
De acordo com Stability AI, em testes anteriores do modelo Stable Diffusion XL usando a estrutura PyTorch, o acelerador Intel Gaudi2 gerou em 30 etapas uma imagem 1024 × 1024 em 3,2 segundos, em comparação com 3,6 segundos para PyTorch na Nvidia A100 e 2,7 segundos ao usar Otimização do TensorRT na Nvidia A100.