
A NVIDIA divulgou novos dados de desempenho de seus aceleradores H100 AI, comparando-os com os aceleradores Instinct MI300X recentemente introduzidos pela AMD. Com esta comparação, a NVIDIA decidiu mostrar que o H100 realmente oferece melhor desempenho do que seu concorrente se você usar o ambiente de software de computação de IA correto. A AMD não levou isso em consideração na comparação de aceleradores, segundo a NVIDIA.

Fonte da imagem: WCCFTech
Durante a apresentação Advancing AI, a AMD revelou oficialmente os aceleradores de computação AI dedicados Instinct MI300X e os comparou aos aceleradores H100 da NVIDIA em uma variedade de benchmarks e testes. Especificamente, a AMD disse que um único acelerador MI300X oferece desempenho 20% mais rápido do que um único acelerador H100, e um servidor de oito MI300Xs é até 60% mais rápido do que um servidor de oito H100s. A NVIDIA publicou uma nota em seu site afirmando que essas afirmações estão longe da verdade.
Os aceleradores de computação NVIDIA H100 foram lançados em 2022 e receberam vários aprimoramentos de software desde então. Por exemplo, as melhorias mais recentes na estrutura de computação de IA TensorRT-LLM melhoraram ainda mais o desempenho do H100 em cargas de trabalho específicas de IA, bem como otimizações em nível de kernel. Tudo isso, segundo a NVIDIA, permite que os chips H100 funcionem de forma mais eficiente com grandes modelos de linguagem como o Llama 2 com 70 bilhões de parâmetros usando operações FP8.
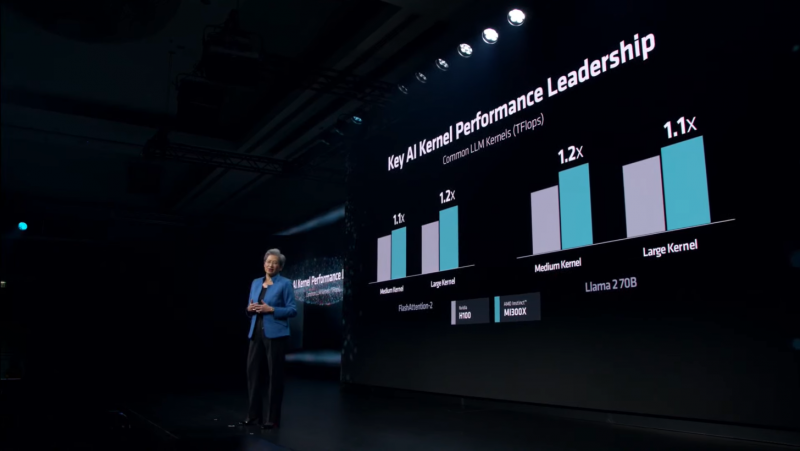
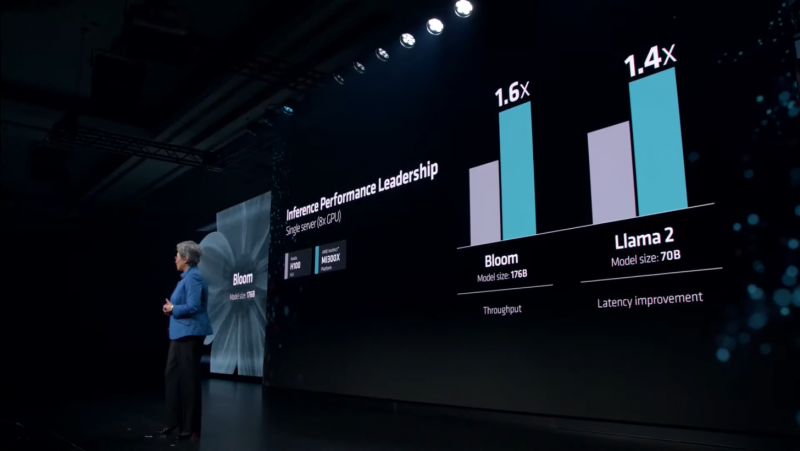
A própria AMD, em sua apresentação, afirmou que o Instinct MI300X é até 20% mais rápido que o H100 no Llama 2 70B, e um sistema de oito aceleradores AMD fornece latência 40% superior em comparação a um sistema com oito NVIDIA H100s no mesmo neural. rede. A superioridade nas operações FP8 e FP16 é de 30% a favor do MI300X.
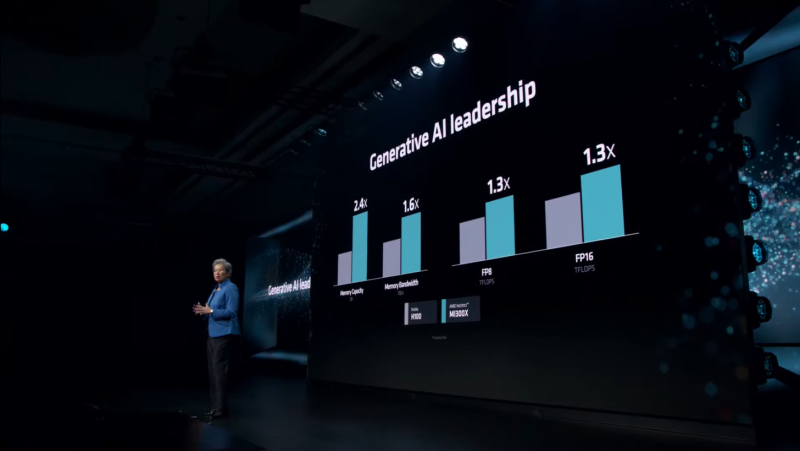
A AMD testou seus aceleradores MI300X usando bibliotecas otimizadas do software de ambiente de computação ROCm 6.0. No entanto, para NVIDIA H100, os dados foram utilizados sem levar em conta o uso da estrutura de software TensorRT-LLM otimizada projetada para essas tarefas. Em um artigo recente, a NVIDIA forneceu dados atuais de desempenho para um servidor DGX de oito H100s no modelo Llama 2 70B, levando em consideração o processamento de um pacote de software (Batch-1).
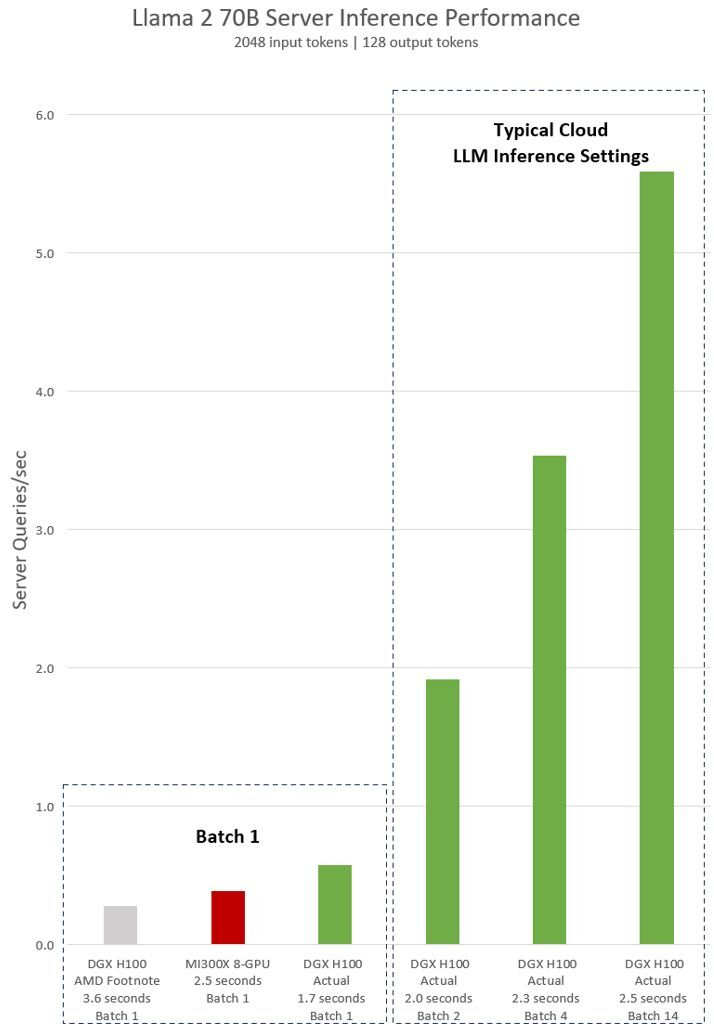
Fonte da imagem: NVIDIA
A NVIDIA explica que as conclusões da AMD (cinza e vermelho no gráfico acima) de superioridade sobre o H100 são baseadas nos dados apresentados na nota de rodapé #MI300-38 da apresentação da AMD. Para obtê-los, usamos o sistema NVIDIA DGX H100, a estrutura vLLM v.02.2.2 e o modelo Llama 2 70B com comprimento de sequência de entrada de 2048 e comprimento de sequência de saída de 128. NVIDIA observa que a AMD comparou um sistema de oito MI300X com um sistema DGX H100 de oito H100.
Por sua vez, os dados da NVIDIA são mostrados em verde no gráfico. Para obtê-los, usamos o sistema DGX H100 de oito NVIDIA H100s com 80 GB de memória HBM3 em cada um, bem como a estrutura NVIDIA TensorRT-LLM v0.5.0 disponível publicamente para cálculo do Lote 1 e versão v0.6.1 para cálculo de latência . A carga de trabalho é a mesma especificada na nota de rodapé #MI300-38 da AMD.
Os resultados fornecidos pela NVIDIA mostram que o servidor DGX H100 é duas vezes mais rápido ao usar estruturas otimizadas do que afirma a AMD. Além disso, um servidor com oito H100s é até 47% mais rápido que um sistema com oito AMD MI300Xs.
«O sistema DGX H100 é capaz de processar uma solicitação de inferência de tamanho Lote 1, ou em outras palavras, uma solicitação de inferência por vez, em 1,7 segundos. A consulta do Lote 1 fornece o tempo de resposta mais rápido possível para o processamento do modelo. Para otimizar o tempo de resposta e o rendimento do data center, os serviços em nuvem definem um tempo de resposta fixo para uma tarefa específica. Isso permite que os operadores de data center combinem diversas solicitações de saída em “lotes” maiores e aumentem a produção geral do servidor por segundo. Benchmarks padrão da indústria, como MLPerf, também medem o desempenho usando essa métrica de tempo de resposta fixo”, continua a NVIDIA.
A NVIDIA explica que pequenas compensações no tempo de resposta do sistema podem resultar em um aumento no número de solicitações de saída que o servidor pode processar em tempo real. Usando um orçamento de tempo de resposta fixo de 2,5 segundos, o servidor DGX H100 de oito GPUs pode lidar com mais de cinco consultas de inferência Llama 2 70B por vez.