
Meta✴ revelou o Llama 3, um grande modelo de linguagem de próxima geração que descaradamente chama de “o LLM de código aberto mais capaz até agora”. A empresa lançou duas versões: Llama 3 8B e Llama 3 70B, respectivamente, com 8 e 70 bilhões de parâmetros. Segundo a empresa, os novos modelos de IA são significativamente superiores aos modelos correspondentes da geração anterior e estão entre os melhores modelos de IA generativa disponíveis atualmente.

Fonte da imagem: vecstock/freepik.com
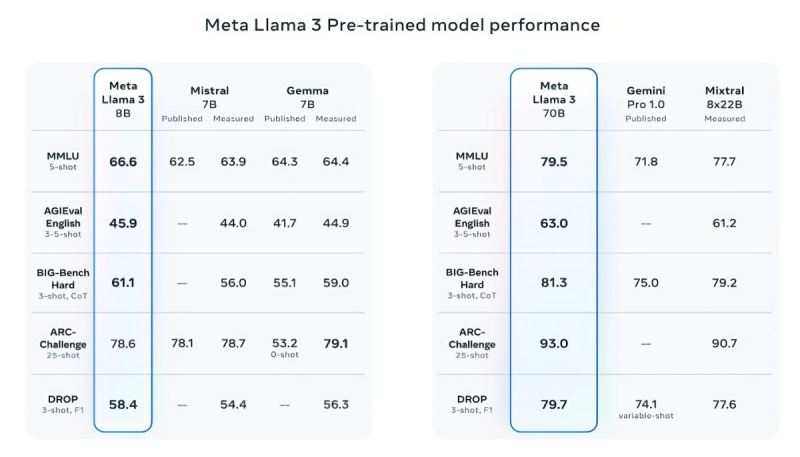
Para apoiar suas palavras, Meta✴ fornece os resultados dos testes populares MMLU (conhecimento), ARC (capacidade de aprender) e DROP (análise de fragmentos de texto). O Llama 3 8B supera outros modelos de código aberto em sua classe, como o Mistral 7B da Mistral e o Gemma 7B do Google com 7 bilhões de parâmetros, em pelo menos nove testes: MMLU, ARC, DROP, GPQA (biologia, física e química), HumanEval (código teste de geração), GSM-8K (problemas de matemática), MATH (outro teste de matemática), AGIEval (bateria de testes de resolução de problemas) e BIG-Bench Hard (teste de raciocínio de bom senso).
Fonte da imagem: Meta✴
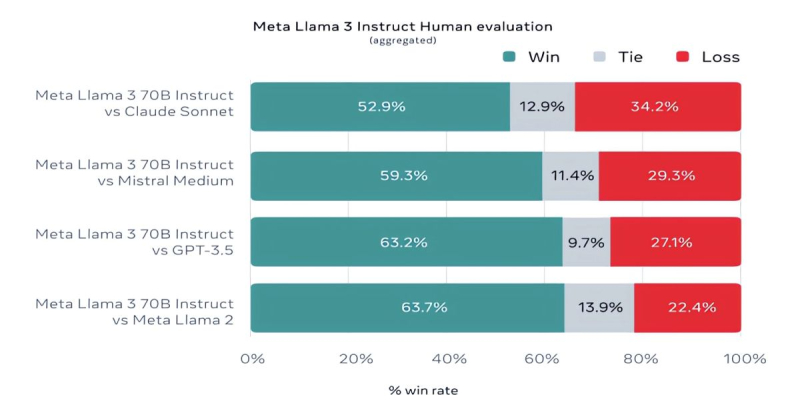
Mistral 7B e Gemma 7B não podem mais ser chamados de modernos, enquanto em alguns testes o Llama 3 8B não mostra superioridade significativa sobre eles. No entanto, a Meta✴ está muito mais orgulhosa de seu modelo mais avançado, o Llama 3 70B, que classifica ao lado de outros modelos emblemáticos de IA generativa, incluindo o Gemini 1.5 Pro, o mais avançado da linha Gemini do Google. O Llama 3 70B supera o Gemini 1.5 Pro nos testes MMLU, HumanEval e GSM-8K, mas fica atrás do top de linha Claude 3 Opus da Anthropic, batendo apenas o modelo mais fraco da série, o Sonnet, em cinco testes: MMLU, GPQA, HumanEval, GSM-8K e MATEMÁTICA. Meta✴ também desenvolveu seu próprio conjunto de testes, desde escrita e codificação até resumo e inferência, nos quais o Llama 3 70B venceu o Mistral Medium, o GPT-3.5 da OpenAI e o Claude Sonnet da Anthropic.
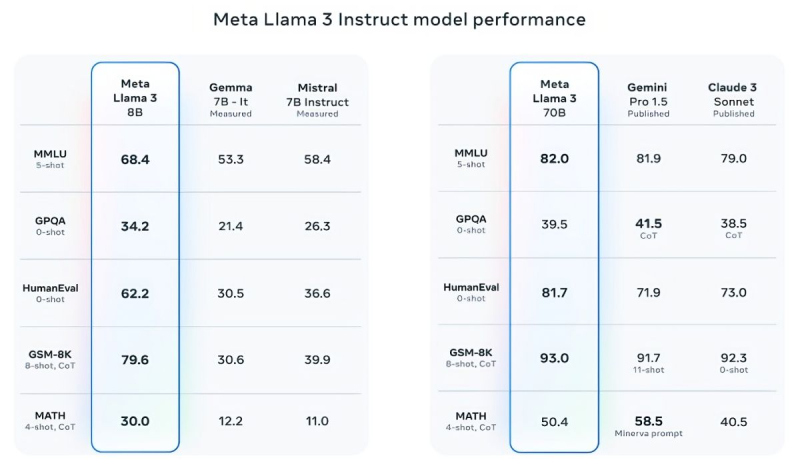
De acordo com Meta✴, os novos modelos são mais gerenciáveis, menos propensos a se recusarem a responder perguntas e geralmente produzem informações mais precisas, inclusive em alguns campos científicos, o que provavelmente é justificado pela enorme quantidade de dados usados para treiná-los: 15 trilhões de tokens e 750 bilhões de palavras, sete vezes mais do que no caso do Llama 2.
De onde vêm tantos dados? Meta✴ limitou-se a garantir que todos eles foram retirados de “fontes publicamente disponíveis”. No entanto, o conjunto de dados de treinamento do Llama 3 continha quatro vezes mais código do que o usado para o Llama 2, e 5% do conjunto consistia em dados em 30 idiomas diferentes do inglês para melhorar o trabalho com eles. Além disso, foram utilizados dados sintéticos, ou seja, obtidos de outros modelos de IA.
«Nossos modelos atuais de IA estão configurados apenas para responder em inglês, mas nós os treinamos usando dados em outros idiomas para que a IA possa reconhecer melhor nuances e padrões”, comentou Meta✴.
A questão da quantidade necessária de dados para treinamento adicional de IA tem sido levantada com especial frequência ultimamente, e a Meta✴ já conseguiu estragar sua reputação neste campo. Foi recentemente relatado que a Meta✴ estava fornecendo e-books protegidos por direitos autorais para a IA em busca de concorrentes, embora os advogados da empresa alertassem sobre possíveis consequências.
No que diz respeito à segurança, a Meta✴ incorporou vários protocolos de segurança em sua nova geração de modelos proprietários de IA, como Llama Guard e CybersecEval, para combater o uso indevido de IA. A empresa também lançou uma ferramenta especial, Code Shield, para analisar a segurança do código de modelos abertos de IA generativa, permitindo detectar possíveis vulnerabilidades. Sabe-se que anteriormente esses mesmos protocolos não protegiam o Llama 2 de respostas falsas e da emissão de informações médicas e financeiras pessoais.
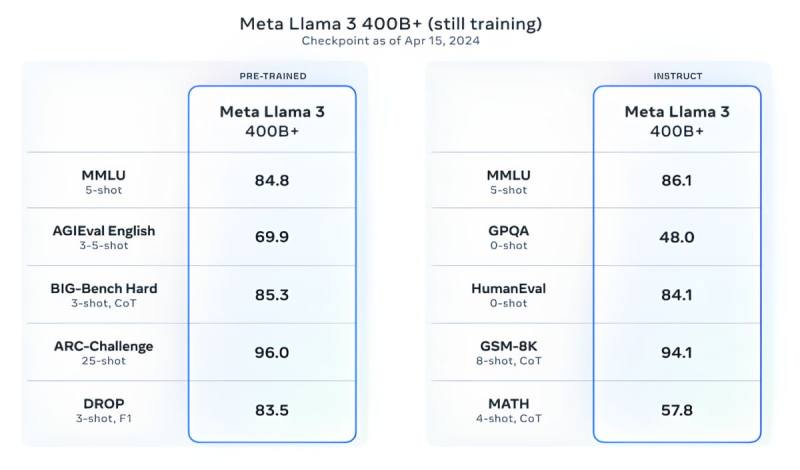
Mas isso não é tudo. Meta✴ treina o modelo Llama 3 com 400 bilhões de parâmetros – ele será capaz de falar diferentes idiomas e aceitar mais dados recebidos, inclusive trabalhando com imagens. “Nós nos esforçamos para fazer do Llama 3 um modelo multilíngue e multimodal que possa levar em conta mais contexto. Também estamos tentando melhorar o desempenho e expandir as capacidades do modelo de linguagem no raciocínio e na escrita de código”, disse Meta✴.