
A versão mais recente do modelo de linguagem grande Gemini 1.5 Pro subitamente chegou ao topo do ranking da plataforma Chatbot Arena, derrotando os líderes tradicionais no campo da inteligência artificial generativa – OpenAI GPT-4o e Anthropic Claude-3 em testes .

Fonte da imagem: blog.google
A anteriormente campeã rede neural OpenAI GPT-4o perdeu a liderança em 1º de agosto, quando o Google lançou discretamente uma versão experimental de seu modelo mais recente – ela rapidamente atraiu uma comunidade interessada em IA nas redes sociais, que considerou a vitória no benchmark uma prova de qualidade . OpenAI ChatGPT tornou-se quase sinônimo de IA generativa desde seu lançamento na era GPT-3. Até o momento, os líderes estabelecidos são OpenAI GPT-4o e Anthropic Claude-3, que no ano passado quase não tiveram concorrentes nos testes.
Fonte da imagem: x.com/lmsysorg
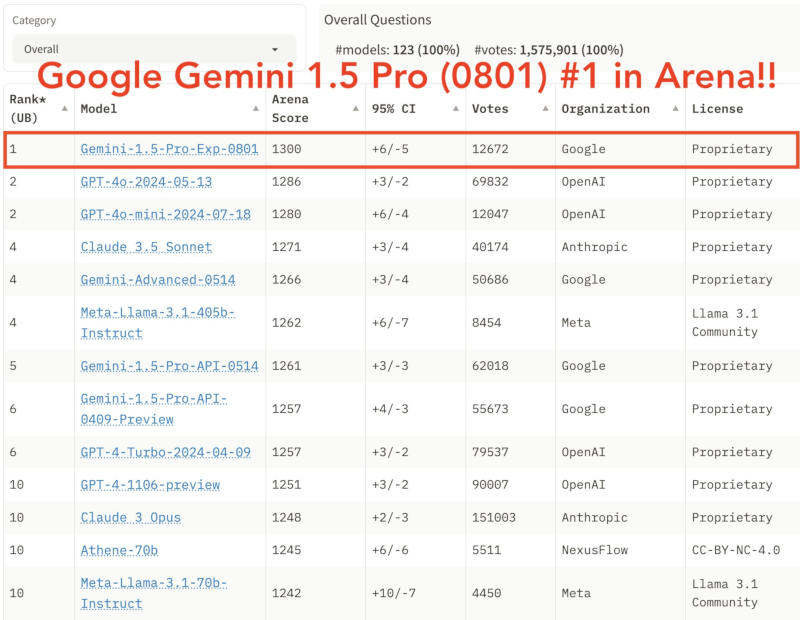
Um dos testes mais populares é o LMSYS Chatbot Arena. Ele oferece aos modelos várias tarefas e atribui-lhes pontuações. A versão atual do GPT-4o conseguiu marcar 1.286 pontos, e Claude-3 – 1.271 pontos. O anterior Google Gemini 1.5 Pro teve uma pontuação de 1.261, mas o Gemini 1.5 Pro 0801 lançado em 1º de agosto de repente marcou impressionantes 1.300 pontos. Isso pode indicar que a nova rede neural do Google é mais capaz do que seus concorrentes, mas os benchmarks nem sempre refletem com precisão o que um modelo de IA pode ou não fazer.
O mercado atual de chatbots está maduro o suficiente para oferecer ao consumidor múltiplas opções e permitir que ele decida por si mesmo qual IA é mais adequada. Ainda não está claro se o Gemini 1.5 Pro experimental se tornará a versão padrão no futuro. Permanece disponível publicamente, mas com status experimental pode ser fechado ou editado radicalmente por segurança ou outros motivos.