
Em outubro, a Apple, com o apoio de cientistas da Universidade Cornell, disponibilizou publicamente seu próprio modelo multimodal de linguagem grande, Ferret, que pode aceitar fragmentos de imagem como consultas.

Fonte da imagem: Laurenz Heymann/unsplash.com
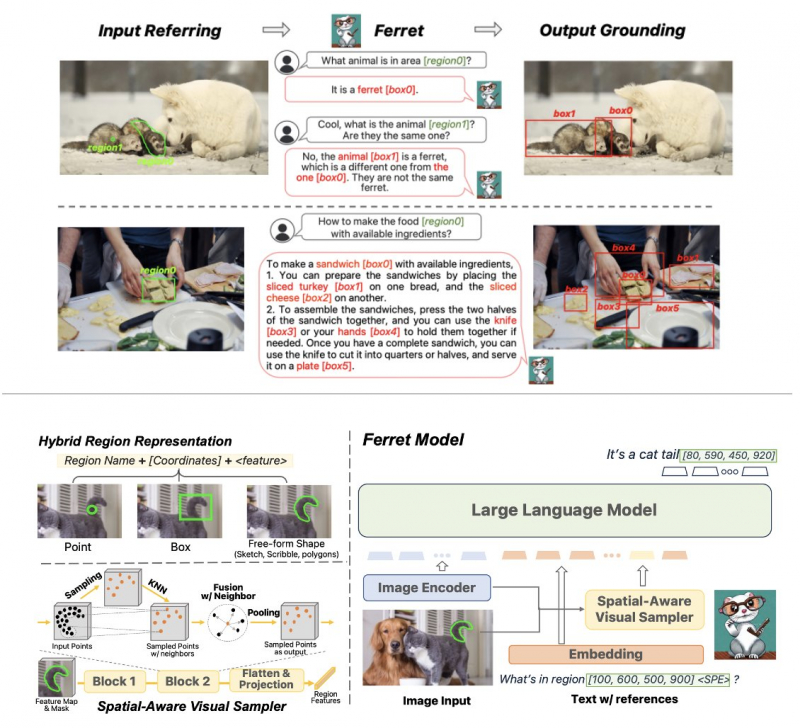
O lançamento de Ferret no GitHub em outubro não foi acompanhado de grandes anúncios da Apple, mas o projeto posteriormente atraiu a participação de especialistas do setor. O princípio de funcionamento do Ferret é que o modelo estude um determinado fragmento da imagem, identifique os objetos nesta área e os contorne com uma moldura. O sistema percebe objetos reconhecidos em um fragmento de imagem como parte de uma solicitação, cuja resposta é fornecida em formato de texto. Por exemplo, um usuário pode destacar um animal em uma imagem e pedir que Ferret o reconheça. O modelo responderá a que espécie o animal pertence, e será possível fazer perguntas adicionais contextualizadas, esclarecendo informações sobre outros objetos ou ações.
Fonte da imagem: twitter.com/zhegan4
O modelo aberto de Ferret é um sistema que pode “referenciar e justificar qualquer coisa, em qualquer lugar, com qualquer detalhe”, explicou o pesquisador de IA da Apple, Zhe Gan. Especialistas do setor destacam a importância de lançar o projeto neste formato – demonstra a abertura de uma empresa tradicionalmente fechada. Segundo uma versão, a Apple decidiu dar esse passo porque busca competir com a Microsoft e o Google, mas não possui recursos computacionais comparáveis. Por conta disso, não pôde contar com o lançamento de seu próprio concorrente ao ChatGPT e foi obrigada a escolher entre fazer parceria com um hiperescalador de nuvem ou lançar o projeto em formato aberto, como a Meta✴ havia feito anteriormente.