
A Ericsson apresentou seu primeiro conjunto de produtos AI-RAN, enfatizando seu compromisso com uma estratégia baseada em ASICs proprietários para melhorar o desempenho da rede de acesso de rádio (RAN). Enquanto o setor de telecomunicações sem fio se volta cada vez mais para RANs virtualizadas/baseadas em nuvem usando processadores de uso geral (GPPs) da Intel, a Ericsson defende seu investimento contínuo em silício personalizado para aplicações de alto desempenho, de acordo com o blog de tecnologia da IEEE ComSoc. A Intel continua sendo um parceiro fundamental para a Ericsson, enquanto o relacionamento da empresa com a AMD e a NVIDIA tem sido tenso.
A Ericsson considerou usar processadores ARM NVIDIA Grace em vez de GPUs Hopper, mas acabou optando por chips de silício personalizados (ASICs). Ao mesmo tempo, a empresa demonstra seu compromisso com a flexibilidade de sistemas definidos por software, garantindo a portabilidade de seus algoritmos RAN proprietários e software específico para IA em diversas plataformas de silício abertas.
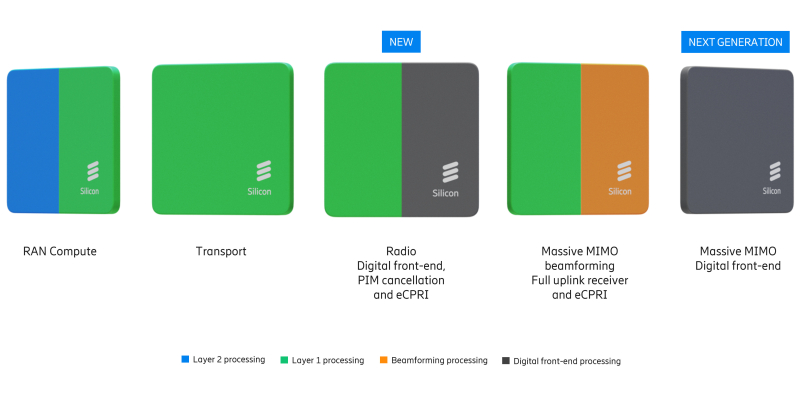
O portfólio de soluções RAN da Ericsson é baseado em duas arquiteturas principais. A maior parte é baseada em ASICs desenvolvidos internamente e em parceria com a Intel. O portfólio também inclui o Cloud RAN, que combina a pilha de software da Ericsson com os processadores Intel Xeon EE. Apesar das expectativas do setor de que a virtualização permita a separação entre hardware e software, a Intel continua sendo a única parceira da Ericsson no fornecimento de chips para implantação em massa, o que apresenta alguns riscos.

Fonte da imagem: Ericsson
A Ericsson confirmou, essencialmente, o “suporte comercial” exclusivo para soluções Intel, enquanto AMD, Arm e NVIDIA permanecem limitados ao “suporte a protótipos”. Apesar de anos de declarações da indústria sobre a necessidade de diversidade de silício no ecossistema vRAN, o progresso parece ter estagnado. Além disso, a integração de IA ao software RAN adiciona novas camadas de complexidade que podem consolidar ainda mais a dependência da empresa em hardware de um único fornecedor.
Observadores da indústria permanecem céticos quanto ao compromisso da Ericsson com uma “pilha de software única” para plataformas de hardware heterogêneas. Embora a desagregação de hardware e software seja possível em camadas superiores (L2/L3), a camada física L1 — a parte mais intensiva em recursos da pilha — permanece fortemente otimizada para um silício específico. Inicialmente, a Ericsson contou com a portabilidade do código L1 entre x86 (incluindo AMD) e Arm SVE2 (NVIDIA Grace) para igualar os recursos do Intel AVX-512. No entanto, alcançar alto desempenho nessas plataformas sem refatoração significativa continua sendo um desafio de engenharia considerável.
Um gargalo crítico no processamento de tráfego da camada 1 é a correção de erros (FEC), que tradicionalmente exige aceleração de hardware dedicada. Inicialmente, a Ericsson dependia da transferência das tarefas de FEC para aceleradores PCIe discretos da Intel. Posteriormente, a Intel implementou a aceleração de FEC no Xeon EE como parte do vRAN Boost. As tentativas de usar FPGAs da AMD demonstraram baixa eficiência energética, e as GPUs da NVIDIA se mostraram muito caras para essa tarefa.
No entanto, o desenvolvimento do AI-RAN mudou o cenário econômico, já que os aceleradores agora podem ser usados tanto para cargas de trabalho de RAN quanto de IA. A Ericsson demonstrou interesse nas Unidades de Processamento Tensorial (TPUs) do Google. Contudo, apesar de seu compromisso com a criação de um “software unificado”, os planos da Ericsson reconhecem os desafios de implementar essa ideia. Enquanto a camada 2 e superiores utilizam uma base de código universal em todas as plataformas de hardware, a camada 1 requer adaptação a plataformas específicas.
Para evitar a dependência de um único fornecedor de chips, a empresa prioriza o uso de HALs (Camadas de Abstração de Hardware), que permitirão a portabilidade do software para diferentes plataformas de hardware com alterações mínimas. Entre as principais iniciativas, destaca-se a implementação da interface BBDev (Baseband Device) para separar o software da RAN do hardware subjacente. A integração com o NVIDIA CUDA está sendo considerada, mas depende muito da padronização mais ampla do setor.
Para comunicações de rádio, que são menos suscetíveis à virtualização completa, a Ericsson incorpora processadores de Aceleradores de Redes Neurais (NNA) diretamente nos módulos de rádio.Esses núcleos de matriz programáveis são otimizados para processamento de dados em sistemas Massive MIMO, fornecendo formação de feixe e estimativa de canal.Em frações de milissegundo, respeitando rigorosas restrições de consumo de energia. Os novos módulos de rádio com IA são equipados com ASICs da Ericsson com NNA. Alega-se que eles expandem as capacidades de inferência local dos sistemas de rádio Massive MIMO, permitindo a otimização em tempo real.
Se você notar algum erro, selecione-o com o mouse e pressione CTRL+ENTER. | Você consegue escrever uma versão melhor? Ficaremos felizes em receber seu feedback.
Fonte: