
Após analisar as limitações da emulação FP64 usando o esquema Ozaki, os desenvolvedores da AMD concluíram que atualmente não existe substituto para o desempenho bruto do FP64. Como Nicholas Malaya, pesquisador da AMD, disse ao HPCwire, para garantir a precisão das tarefas tradicionais de modelagem e simulação, a empresa pretende aumentar o desempenho nativo em FP64 do acelerador Instinct MI430X. O acelerador será a base do supercomputador Discovery, que será instalado no Laboratório Nacional de Oak Ridge (ORNL) em 2028.
Como observado por Katsuhisa Ozaki e outros dois pesquisadores japoneses, o esquema Ozaki é uma nova e promissora técnica de emulação projetada para permitir que cientistas realizem multiplicações de matrizes de alta precisão em hardware compatível com INT8/FP8, incluindo aceleradores de IA modernos, realizando repetidamente cálculos de menor precisão.
As implementações atuais de Ozaki-I e Ozaki-II apresentam limitações que impedem seu uso em condições reais, afirmou Malaya. Ele apontou dois problemas principais. Primeiro, o software não está em conformidade com o padrão IEEE e não produz os mesmos resultados que a execução do código em hardware real compatível com FP64. “Em alguns casos, isso não é um problema”, disse ele. “Mas para muitas matrizes comuns que observamos, o impacto na precisão é bastante significativo.” Segundo, o esquema de Ozaki é voltado para matrizes quadradas. Se estas não forem usadas nos cálculos, o desempenho resultante é inferior ao de uma implementação nativa em FP64, disse Malaya.

Fonte da imagem: AMD
Além disso, as aplicações de HPC tradicionalmente dependem de computação vetorial, em vez da computação de tensores ou matrizes típica de cargas de trabalho de IA. Na verdade, a situação é ainda pior: menos de 10% das aplicações de HPC do mundo real implementaram alterações em seu código DGEMM que aproveitam o Ozaki. “Pelo que sei, Ozaki-I, Ozaki-II ou qualquer outro método existente não pode ser aplicado a instruções vetoriais”, diz Malaya. “Essa é uma nuance fundamental que acredito estar sendo ignorada.” O DGEMM consome uma quantidade significativa de recursos computacionais, o que possibilita o uso do Ozaki, “mas não resolve 90% das cargas de trabalho de HPC”.
A AMD planeja oferecer suporte à emulação de Ozaki em seus chips, disse Malaya. “Não há motivo para não fazê-lo. É software.” “E você poderia ter bibliotecas que permitem alternar dinamicamente entre cálculos nativos e Ozaki, e talvez até avaliá-los”, disse ele, acrescentando que a emulação por software poderia ser considerada uma opção alternativa para computação FP64. No entanto, em última análise, Ozaki não é uma alternativa viável ao hardware FP64, afirmou Malaya, esclarecendo que não está sozinho nessa opinião.
Fonte da imagem: AMD
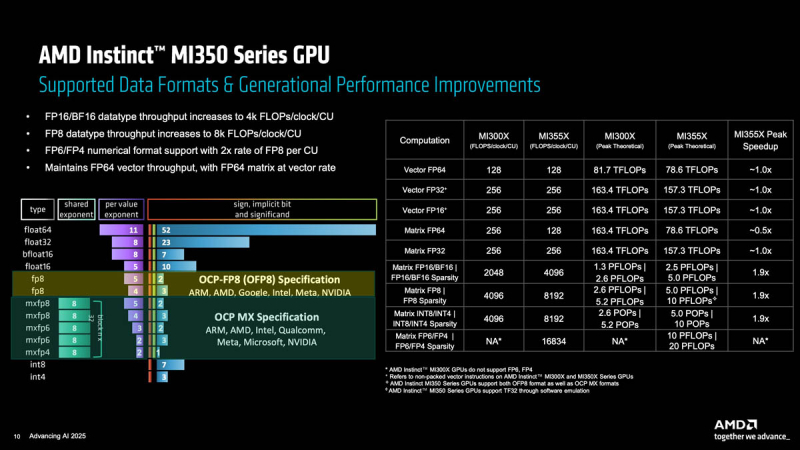
A empresa está atualmente desenvolvendo o MI430X, uma versão especializada do acelerador MI450 de próxima geração, que apresentará um desempenho FP64 significativo. Segundo Malaya, esse desempenho será consideravelmente superior ao do acelerador MI355X, que oferece 78,6 teraflops. Na verdade, é inferior ao do modelo anterior, o MI325X, que oferecia 81,7 teraflops — tanto para cálculos vetoriais quanto matriciais em FP64.
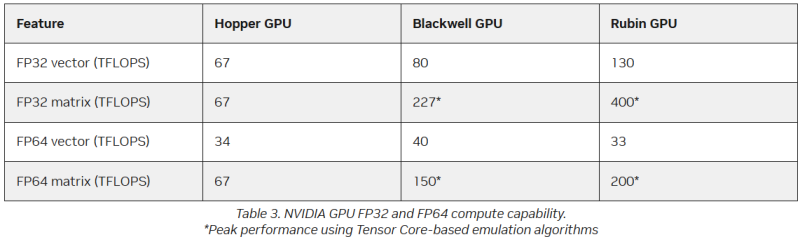
De qualquer forma, todos esses chips — do MI325 ao MI430 — oferecem desempenho superior aos chips da NVIDIA. Tanto o Hopper (34 TFLOPS) quanto o Blackwell (40 TFLOPS) já eram mais lentos em cálculos vetoriais FP64, mas o Hopper ao menos tinha 67 TFLOPS nativos em cálculos matriciais, enquanto o Blackwell, nesse caso, já havia migrado para o esquema Ozaki com 150 TFLOPS “não nativos”. A NVIDIA nem sequer menciona o Blackwell Ultra, onde o desempenho em FP64 caiu para 1,3 TFLOPS, neste contexto, mas promete que o Rubin terá 33 TFLOPS em cálculos vetoriais FP64 e 200 TFLOPS em cálculos matriciais (também com Ozaki).
Fonte da imagem: NVIDIA
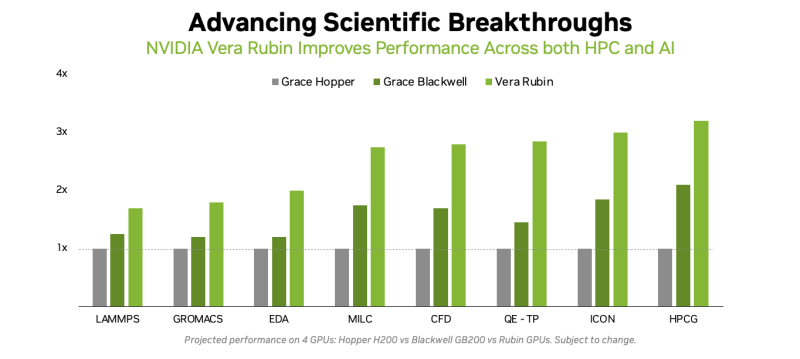
A NVIDIA justifica sua decisão de abandonar o desenvolvimento de unidades FP64 de hardware alegando que o aumento da capacidade bruta de computação FP64 não acelerará, de fato, as aplicações científicas, já que estas serão limitadas na prática por registradores, caches e HBM. O Rubin oferecerá até 22 TB/s de throughput HBM, 2,8 vezes maior que o Blackwell. O Instinct MI325X oferece 6 TB/s, o MI355X 8 TB/s e o MI430X atingirá 19,6 TB/s, segundo Malaya.
De acordo com Malaya, o ideal é investir simultaneamente em HBM e em operações de ponto flutuante. “O que realmente importa é a relação byte/flop.” “Do nosso ponto de vista, precisamos manter uma relação muito mais próxima da que vemos em produtos modernos”, disse ele. “Precisamos nos aproximar muito dessa relação em termos de aumento do desempenho FP64 para manter o mesmo nível do que chamamos de intensidade aritmética.”
Fonte da imagem: NVIDIA
Como a AMD oferecerá um aumento de 2,5 vezes na largura de banda da memória HBM do MI355 para o MI430X, um aumento similar de 2,5 vezes no desempenho FP64 também será justificado. Portanto, é possível estimar que o MI430X poderá oferecer desempenho FP64 entre 192 e 204 teraflops, dependendo se o modelo base for o MI355 (mais recente) ou o MI325 (mais rápido), conforme relatado pela HPCwire. A empresa acrescentou que isso é apenas uma estimativa, já que ainda não divulgou as especificações exatas dos próximos chips. Além disso, não está totalmente claro se o desempenho FP64 será o mesmo para cálculos vetoriais e matriciais.
A computação FP64 é “muito importante” para a Missão Genesis, afirmou anteriormente Dario Gil, Subsecretário de Energia (DoE) para Ciência e Inovação. Ele observou que tanto a CEO da AMD, Lisa Su, quanto o CEO da NVIDIA, Jensen Huang, expressaram forte compromisso com o FP64, confirmando que o suporte ao formato continuará. “O FP64 é fundamental para dar suporte às cargas de trabalho de modelagem e simulação, não apenas para impulsionar ainda mais a pesquisa científica tradicional, mas também para fornecer os dados básicos para o treinamento de novos modelos de IA”, acrescentou Gil.
Fonte da imagem: AMD
“Há sempre um equilíbrio entre a quantidade de computação FP64 e FP16 necessária”, disse Malaya. “A AMD afirma que precisamos oferecer suporte a uma ampla gama de tipos de dados, dependendo de suas necessidades. Não será o caso de que todos precisarão de FP64 e isso será suficiente para tudo”, observou. Malaya ressaltou que sempre há exceções. Por exemplo, simulações de IA de dobramento de proteínas, como AlphaFold e Openfold, usam FP32. E algumas tarefas tradicionais de HPC, como dinâmica molecular, não exigem precisão FP64.
No entanto, existe atualmente uma demanda significativa não atendida por FP64, afirma o cientista. “Quanto à computação de alto desempenho, acreditamos que ainda será necessário muito FP64”, disse ele. “Haverá alguns códigos que são totalmente dependentes de memória e não precisam de tanto.” Mas existem, por exemplo, códigos de química computacional e outros que realmente possuem alta intensidade aritmética, e eles usarão FP64.”
Se você notar um erro, selecione-o com o mouse e pressione CTRL+ENTER. | Você consegue escrever uma versão melhor? Ficaremos felizes em receber sua sugestão.
Fonte: