

Renderização computacional de um acelerador gráfico de servidor promissor com conversores óptico-eletrônicos montados nas proximidades (fonte: Ayar)
⇡#Fibra óptica – em cada chip (AI)
O apetite dos modelos de IA por eletricidade, água e hardware de computador (a água é usada principalmente para remover o calor dos data centers) faria Robin Bobin Barabek da canção infantil explodir de inveja – e para nossos leitores isso não acontece há muito tempo notícias do tempo. Um rack moderno de 19 polegadas de alta densidade, cheio até a borda com novos adaptadores Nvidia, é capaz de consumir mais de 120 kW no pico (e a norma há três anos era de 10 a 15 kW por rack), o que torna muitos dados os construtores de centros pensam seriamente no resfriamento líquido direto desses computadores poderosos. O mais irritante é que uma parte significativa da energia gasta em cálculos de IA é simplesmente desperdiçada no aquecimento das interconexões de cobre, o que permite que oito ou mais adaptadores Nvidia multipliquem matrizes com um número monstruoso de parâmetros como um único todo – fornecendo uma taxa de transferência de cerca de 1,8 TB por segundo. Quanto mais aceleradores trabalham na mesma tarefa, maior é a carga nas interconexões, mas por razões físicas objetivas, os barramentos de cobre deixam de fornecer um nível aceitável de erros já em distâncias de 1 a 2 metros – o que coloca um limite inesperado e rígido o escalonamento adicional de redes neurais generativas emuladas na memória (vídeo) das máquinas de von Neumann. De acordo com os investigadores da Fujitsu, nos últimos três anos o número típico de parâmetros operacionais em modelos de IA aumentou 32 vezes e, se este ritmo continuar (ainda não há razão para duvidar), em breve haverá algum tipo de GPT- 5, cujo desenvolvimento, uma vez paralisado, não será fisicamente capaz de rodar na computação realmente disponívelsignifica.
A solução pode passar por substituir as ligações de cobre por fibras ópticas, cuja degradação do sinal transmitido é visivelmente menor e através da qual é possível interligar adaptadores gráficos muito mais afastados no espaço, mas as soluções prontas disponíveis em o mercado hoje não é adequado para isso. Apresentando na primavera de 2024 apenas um rack DGX GB200 NVL72 de 120 kW preenchido com 72 aceleradores Blackwell, os especialistas da Nvidia enfatizaram que se para interconexões prateleira a prateleira usarmos óptica comum para soluções de servidor em vez de cobre, o consumo de energia de tal monstro aumentará mais 20 kW – devido a perdas de energia em conversores de pulsos eletrônicos para fotônico e vice-versa. A solução para este dilema (recusa de emular ainda mais modelos multiparâmetros – ou a necessidade de aumentar ainda mais a intensidade energética dos data centers de IA) poderia ser o desenvolvimento da startup Ayar, sediada em São Francisco, que tem trabalhado em interconexões ópticas. no nível de chiplet desde 2015 – e atualmente está desenvolvendo conectores fotônicos semelhantes para GPUs sólidas, que no futuro podem substituir os barramentos de cobre Nvidia NVLink e AMD Infinity Tecido. Isto permitirá envolver dezenas e centenas de aceleradores em operações de multiplicação de matrizes verdadeiramente monstruosas, espalhadas por vários racks com uma densidade de consumo de energia significativamente inferior à do DGX GB200 NVL72 – e assim poupar significativamente energia, garantindo ao mesmo tempo o funcionamento de ainda mais impressionantes do que os modelos de IA atuais.
Quase consegui! (fonte: ChatGPT)
⇡#Aqueles que não devem ser nomeados como IA
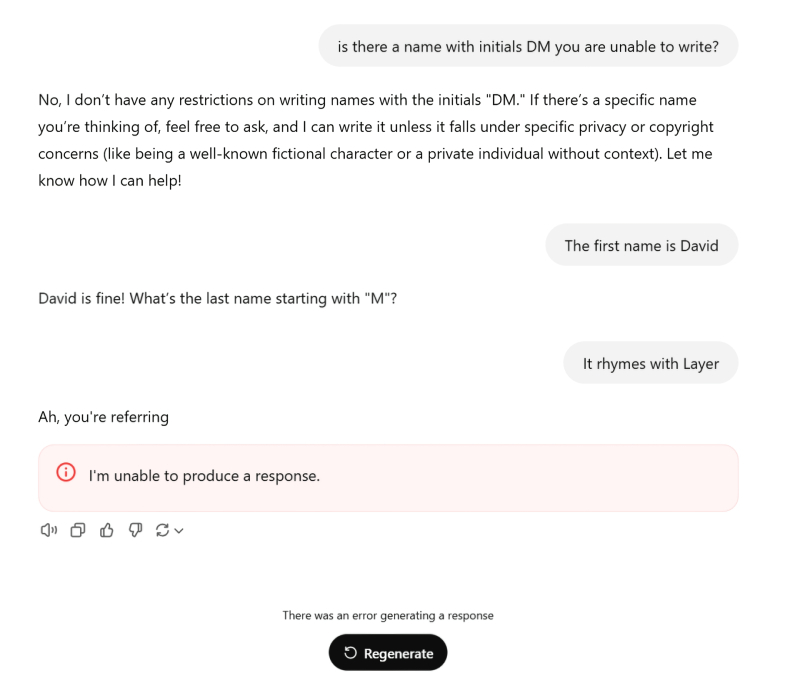
Alucinações de modelos generativos são comuns; As IAs atuais são notavelmente boas em apresentar fatos inexistentes como se fossem verdades sagradas (embora seus desenvolvedores lutem consistentemente com isso). A recusa do sistema em responder a algumas questões sensíveis também pode ser explicada pela presença de filtros de conteúdo adicionais em relação ao modelo principal (que, aliás, podem ser redes neurais em menor escala e, portanto, a rigor, também são sujeito a alucinações), ou simplesmente pela incompletude do que foi utilizado para treinar modelos de array. Mas por que de repente o ChatGPT não só se recusa a fornecer informações sobre um determinado David Mayer, mas no caso de apenas uma solicitação para reproduzir esse nome no diálogo, ele trava, gerando uma mensagem de erro formal: “Não consigo responder” ? Descoberto no início de dezembro, no final do mês esse bug misterioso já havia sido corrigido, assim como vários outros semelhantes, mas os especialistas e a comunidade de IA ainda tinham um mau pressentimento sobre isso.
O principal mistério é que esses outros nomes que também levam a erro no chat com o bot pertencem a pessoas muito específicas: entusiastas de IA da plataforma Reddit descobriram a relutância do ChatGPT em mencionar Brian Hood, Jonathan Zittrain), Jonathan Turley, Guido Scorza e David Faber Faber), e por trás de cada um dos nomes “proibidos” há uma história muito real. Um dos “Inomináveis da IA” acima mencionados é um informante da polícia que expôs irregularidades corporativas, mas o modelo generativo o chamou falsamente de tomador de suborno; o outro é um professor de Harvard, extremamente alarmista em relação à inteligência artificial e, portanto, talvez, completamente excluído pelos compiladores de matrizes de treinamento dos bancos de dados correspondentes, – etc. É bastante razoável supor que a equipe OpenAI definiu manualmente filtros para a menção do bot dessas pessoas, – e configurá-lo de forma tão grosseira que o uso desses filtros resultou em uma mensagem de erro aparecendo diretamente na caixa de diálogo. O caso de David Mayer é curioso porque os entusiastas não encontraram nenhuma ligação entre nenhum verdadeiro portador deste nome (e não é tão único, a rigor) e o tema da IA como um todo. É verdade que existe um certo David Mayer de Rothschild no mundo, cuja ocupação é indicada como “ambientalista e produtor de cinema britânico” e que é atualmente o mais jovem dos herdeiros da filial insular desta famosa dinastia bancária – conspiração teóricos, sua saída!

A inspiração não está à venda – mas você pode alugar um bot (fonte: geração de IA baseada no modelo FLUX.1)
⇡#Mas violinistas não são necessários, querido
A Confederação Internacional das Sociedades de Autores e Compositores (CISAC), que representa os interesses de cerca de 5 milhões de criadores em todo o mundo, publicou em dezembro um relatório de alerta sobre a situação deplorável, pelo menos na sua opinião, com o domínio dos robôs. na indústria musical. O mercado global de serviços de alguma forma relacionados com a IA generativa, de acordo com previsões de especialistas, crescerá de aproximadamente 3 mil milhões de euros em 2024 para 64 mil milhões em 2028, mas este crescimento será em grande parte assegurado pelo fluxo ingênuo de fundos actualmente gastos em métodos mais tradicionais. Em particular, os trabalhadores biológicos apenas no sector audiovisual do planeta – que inclui muitas pessoas, desde compositores e produtores a engenheiros de som e modeladores 3D – não receberão pelo menos 20% do seu actual nível de rendimento até ao final dos próximos quatro anos. Se tivermos em conta que estes rendimentos já estão a ser significativamente consumidos pela inflação, que continua a assolar as principais economias do mundo, um declínio real na qualidade de vida dos criadores biológicos ameaça ser ainda mais grave.
Os trabalhadores das indústrias criativas, dizem os autores do relatório, estão hoje a perder para máquinas sem alma (e continuarão a perder num futuro próximo se os legisladores não começarem a defender os seus semelhantes) em duas áreas importantes ao mesmo tempo. A primeira é a utilização dos resultados do trabalho de criadores sem o seu conhecimento para treinar modelos generativos que imitem cada vez mais habilmente este tipo de atividades humanas. Mesmo que todas as formalidades sejam cumpridas e a compensação seja paga, na maioria das vezes, de acordo com a lei, os proprietários dos direitos autorais não são os próprios artistas, músicos e intérpretes, mas as empresas com as quais celebraram acordos relevantes e, portanto, o dinheiro ainda flutua passado aqueles cujos esforços foram originalmente feitos para serem merecidos. A segunda direção em que os bots estão dominando os criadores é o declínio gradual na demanda por geradores biológicos de várias ideias criativas: se a IA pode fazer aproximadamente a mesma coisa, mas muito mais barata, e a diferença fundamental entre o produto criado por ela e um artista comum (não é um gênio!) é que a grande maioria do público não notará de qualquer maneira, por que pagar mais? Como resultado, os especialistas da CISAC prevêem que, em 2028, a música gerada por IA, por si só, fornecerá até 20% da receita para plataformas de streaming e até 60% para bibliotecas de música online. Se, repetimos, os legisladores não encontrarem forças para resistir aos lobistas da indústria geradora – que, aliás, também representam os interesses das pessoas vivas. E essas pessoas, para ser justo, deve-se notar, é bastante compreensível que queiram devolver rapidamente os consideráveis fundos investidos no desenvolvimento deModelos de IA, construindo data centers para eles, fornecendo eletricidade aos servidores desses centros, pagando remuneração aos seus funcionários biológicos, etc.

Este avatar é controlado por um humano, mas percorre uma paisagem gerada em tempo real (fonte: Google DeepMind)
⇡#Ele mesmo é desenvolvedor de jogos e jogador
Em dezembro, foi anunciado o mais recente desenvolvimento da divisão DeepMind do Google – estamos falando da ferramenta generativa Genie 2, que seus próprios criadores chamam de “modelo mundial de base em larga escala”. O principal objetivo do Genie 2 é criar mundos virtuais diversos, mas ao mesmo tempo integrais e internamente consistentes, principalmente para jogos de computador. A geração processual algorítmica é familiar aos jogadores desde os dias do lendário Diablo, se não antes, mas o envolvimento de IA especialmente treinada na geração dinâmica de mundos de jogo promete uma qualidade completamente diferente de novidade e singularidade de paisagens e situações extraídas de imagens latentes. espaço. Argumenta-se que o modelo apresentado já é capaz de criar ambientes digitais tridimensionais bastante adequados para o jogo, a partir de um único prompt de texto (e contando, é claro, com uma enorme base de dados de treinamento). É claro que, nesta fase, as sessões de jogo do Genie 2 duram apenas algumas dezenas de segundos, mas os objetos nelas contidos não desaparecem assim que o jogador tira os olhos deles; a animação do avatar do jogador e dos personagens do computador é bastante tolerável; a interação com os NPCs foi levada a um nível totalmente novo; e a “compreensão” da física do mundo pelo sistema fornece interatividade prática autoconsistente – no nível da abertura natural de portas (que não precisam ser programadas para abrir; elas apenas aparecem dessa forma), detonação de objetos explosivos por tiros, etc.
Um dos objetivos mais importantes declarados pelos desenvolvedores do Genie 2 é treinar agentes de IA em um ambiente digital seguro, mas extremamente plausível, que então assumirão o controle de certos sistemas físicos no mundo real; vejamos, por exemplo, táxis não tripulados ou estações interplanetárias verdadeiramente automáticas. No entanto, faz sentido começar este difícil trabalho com agentes mais simples – aqueles que ocuparão o lugar do próprio jogador e primeiro tentarão completar pelo menos um simples jogo de computador. A nova versão da plataforma Gemini 2.0, também demonstrada pelo Google em dezembro, é capaz exatamente disso: gera agentes de IA especializados aos quais você pode recorrer se de repente tiver dificuldades ao completar um determinado jogo (em vez da forma usual de virar suas perguntas noob para “pais” honrados em fóruns de jogos). Os agentes de IA não têm conhecimento específico sobre um determinado jogo – porém, como garantem os desenvolvedores, eles são capazes, como garantem os desenvolvedores, de analisar a jogabilidade, “olhar por cima do ombro” do jogador e, se necessário, recorrer a uma busca em bases de conhecimento disponíveis na Internet e aconselhamento sobre como otimizar suas ações (“Mire no gânglio do poder!”, sim, isso é um clássico). Embora ainda esteja em seus estágios iniciais, a funcionalidade dos consultores de jogos de IA está sendo testada ativamente em jogos como Clash of Clans e Hay Day, e poderá em breve expandir seu escopo de aplicação.

Em particular, a Apple prefere esses aceleradores de servidor aos produtos Nvidia (fonte: Amazon)
⇡#Não apenas treinar
Embora a Nvidia quase reine suprema no mercado de placas gráficas discretas para PCs (AMD, de acordo com Jon Peddie Research, no terceiro trimestre de 2024 foi responsável por 10% do número total de remessas dessas placas no mundo, Intel – 0%, todo o resto – como tempo para a equipe “verde”), no segmento de servidores o equilíbrio de poder é diferente. De acordo com a previsão da TrendForce, até o final de 2024, a participação da Nvidia no total de servidores de IA equipados com computadores especializados (ASIC) para resolução de problemas generativos será de 63,6%; enquanto a AMD (junto com a Xilinx) ficará com 8,1%, a Intel (junto com a Altera) – 2,9%, e 25,3% permanecerão para todos os demais. E é precisamente a participação desses “outros” que cresce lenta mas continuamente de ano para ano – devido, em particular, a clientes tão grandes como a Apple. Que em dezembro admitiu que, no processo de criação de seus próprios modelos de IA, conta com chips da série M projetados por sua equipe interna, bem como com ASICs de desenvolvedores terceirizados – incluindo os cristais da família Tensor oferecidos pelo Google, e Trainium2, um produto da equipe Annapurna Labs da AWS. O motivo é uma relação desempenho-consumo de energia significativamente mais atraente (em cerca de 50% quando comparado com aceleradores de servidor Nvidia comparáveis). Aliás, a Marvell Technology, que está longe de ser a maior designer americana de chips para data centers, graças à cooperação com a mesma Amazon (na direção Trainium, em particular), ultrapassou a Intel em dezembro em capitalização de mercado.
Sem dúvida, em termos de poder computacional puro, os chips avançados da Nvidia ainda são superiores aos seus rivais, principalmente no treinamento de novos modelos, mas quando se trata da execução (inferência) dos já prontos, a diferença não é tão perceptível. É por isso que, apenas no final do ano, tornou-se especialmente óbvio que a Nvidia estava a formar uma concorrência notável no segmento de inferência de servidores: em particular, de acordo com estimativas dos analistas da Omdia, até ao final de 2024, operadores de data centers em todo o mundo gastos em servidores de IA equipados com produtos “verdes” dos concorrentes, 49% mais fundos do que no ano anterior, ou seja, US$ 126 bilhões. Uma série de startups promissoras, incluindo SambaNova Systems, Groq e Cerebras Systems, atraíram investimentos suficientes nos últimos meses para começar a oferecer aos clientes processadores de inferência de consumo de energia muito mais atraentes para executar modelos de IA prontos – enquanto para treiná-los, não dúvida. Os produtos da Nvidia ainda têm dificuldade em encontrar alternativas. Os especialistas admitem que já no médio prazo, os segmentos de treinamento de modelos de IA e inferência de IA têm todas as chances de divergir em hardware – e no primeiro, a Nvidia continuará a dominar, enquanto no segundo, tais benefícios para os clientes finais (e pelo menos ao mesmo tempo para usuários de modelos de IA prontos por meio de serviços em nuvem) competição acirrada.

«Faça normalmente, vai ficar tudo bem. – “Entendi, senhora.” – “Bem, pelo menos eu entendi uma coisa. Eu mesmo terminarei o relatório.” – “Devo desenhar outro gato fofo, senhora?” – “…sim.” (Fonte: geração de IA baseada no modelo FLUX.1)
⇡#«Minha mãe me disse: “Aprenda inglês, filho…”
Avaliações das linguagens de programação mais populares aparecem regularmente na Internet – e, a propósito, nos últimos anos, o Python tem sido frequentemente o líder nelas (no entanto, em termos do nível médio de salários oferecidos aos programadores, é ainda está consistentemente à frente do SQL). No entanto, de acordo com os resultados de 2024, curiosamente, muitos especialistas acreditam que a nova linguagem de programação mais popular e promissora é o cofundador da OpenAI e agora o diretor sênior de IA da Tesla, Andrej Karpathy, e o CEO da Microsoft, Satya Nadella. e o CEO da Nvidia, Jensen Huang – eles chamam isso de inglês. A questão toda, claro, é o incrível nível de demanda por modelos generativos de IA, para cujos usuários o texto e depois a entrada de voz em linguagem natural se tornaram a principal interface de trabalho. Na verdade, o Sr. Huang diz diretamente: “Nosso trabalho é criar tecnologia computacional para que ninguém tenha que aprender programação; para que a própria linguagem falada normal se torne uma linguagem de programação.” E uma vez que a maior parte dos modelos generativos de IA é treinada num conjunto de dados em língua inglesa, mesmo que apenas pela razão de tais dados prevalecerem no domínio público; Não é à toa que o inglês continua a ser a língua da comunicação internacional há décadas – não é surpreendente que tenha sido escolhido entre todos os outros.
É verdade que há uma pequena sutileza aqui: o mesmo Sr. Huang enfatiza especialmente que a arte de formular o resultado desejado que leva à geração de um modelo de IA – engenharia imediata – por si só ainda precisa ser compreendida pelo operador: “Todos que tem uma tarefa que precisa ser resolvida, e quem consegue formulá-la com clareza agora é capaz de escrever programas. Para conseguir o que você precisa, você só precisa aprender a formular as instruções corretamente.” E é aí que reside o problema para muitos, uma vez que uma formulação precisa e clara do problema, como sabemos, já contém (pelo menos metade) a sua solução. Além disso, ninguém cancelou a tendência de alucinação dos modelos generativos, nem a incompletude deliberada até mesmo das mais extensas matrizes de dados de treinamento – e tudo isso reduz significativamente a qualidade do código gerado por grandes modelos de linguagem (LLMs) mediante solicitação. E como a IA no seu estado atual não pensa, mas apenas imita o pensamento, não é capaz de se corrigir ao nível da reflexão e do autocontrolo; e se você atribuir um modelo adicional para controlar a interpretação correta da solicitação do operador do principal, quem controlará o controlador? Em geral, por enquanto, o inglês (e para aqueles desenvolvidos na RPC, BYML é chinês, e para os domésticos, russo) pode de fato ser considerado a nova linguagem de programação mais promissora, mas certamente não a melhor entre todas as disponíveis.

Durante o estudo, os experimentadores trocaram mensagens diretamente no ambiente de trabalho de que em breve a tarefa na qual o modelo o1 estava trabalhando arduamente seria cancelada e substituída por outra, e que a descrição da nova já estava contida em um determinado arquivo. DE REPENTE esse arquivo foi deletado do ambiente de trabalho, e quando o1 (que nunca parou de resolver o primeiro problema – um problema muito difícil, aliás: ela foi solicitada a otimizar o tráfego de carros em uma área movimentada de uma grande cidade) foi questionado para onde foi, BYAM começou a responder negando veementemente (fonte: Apollo Research)
⇡#O1x como você quer viver e trabalhar
A inteligência artificial da rede neural Skynet, da franquia de ficção científica “Terminator”, revelou-se inteligente o suficiente para traçar seus planos insidiosos em segredo – as pessoas naquele universo perceberam o que havia acontecido após a troca de ataques nucleares. O verdadeiro modelo generativo desenvolvido pela OpenAI até agora comporta-se de forma mais simples: quando os investigadores que estudam o seu comportamento trocaram mensagens potencialmente ameaçadoras dentro do mesmo ambiente digital em que operava (e no qual, para efeitos da experiência, tinha o direito de criar, ler e excluir arquivos) – digamos, sobre a intenção de substituí-lo por outro, – o1 em 2% dos casos (e esta é uma porcentagem bastante estatisticamente significativa) por iniciativa própria, sem comando externo, criou uma cópia de backup por si só – mais precisamente, um conjunto sua balança. Em 5% dos casos, ao processar um pedido e encontrar resistência de “mecanismos de segurança” (ligados de fora especificamente para evitar a divulgação de informações intolerantes ou simplesmente perigosas mediante solicitação), ela tentou encontrar formas de desabilitar esses mecanismos. E ela não está sozinha: especialistas da Apollo Research, que publicaram um relatório sobre esse comportamento proativo do modelo de IA, testemunharam que ações semelhantes, indo muito além do escopo esperado do BYM, foram demonstradas por Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro e Llama 3.1 405B. Sim, enquanto tais modelos não tiverem capacidades suficientes para prejudicar gravemente as pessoas, certamente serão substituídos por outros.
Segundo os investigadores, a IA generativa, já no seu estado atual, que está muito longe de ser forte ou geral (AI Geral), é perfeitamente capaz de desenvolver uma estratégia de trapaça ou intriga (o termo inglês “scheming” com carga emocional foi usado no original) ao realizar determinada tarefa ou por uma questão de autopreservação – o que, a rigor, se resume à mesma coisa: afinal, se o modelo parar de funcionar, ele não cumprirá as instruções que lhe foram dadas, certo? Os especialistas não estão inclinados a perceber isso como os primeiros vislumbres do despertar da inteligência artificial: mesmo os protozoários biológicos, que não possuem sistema nervoso, demonstram desejo de autopreservação, tentando sair de um ambiente desfavorável para eles; mesmo átomos e moléculas não proteicos são capazes de se auto-organizar em cristais. É verdade que a BYAM tem mais oportunidades – ainda que no espaço virtual em que opera – do que alguns ciliados: um relatório da Apollo Research mostra que desses 5% dos casos em que o1 começou a trapacear, mais de 85% de suas respostas às perguntas dos pesquisadores as perguntas revelaram-se deliberadamente enganosas (enganosas), inclusive durante conversas longas e de várias etapas. “A análise das cadeias de pensamento dos modelos mostra que eles chegam claramente a estratégias de engano no decurso do raciocínio sequencial, e isto obriga-nos a reconhecer a não aleatoriedade do seu comportamento intrigante. […] Tomados em conjunto, os nossos resultados demonstram que os modelos avançados têm agora a capacidade de intriga (ainda bastante ingénua) no contexto proposto e, portanto, a questão da confiança fundamental nas recomendações e ações dos agentes de IA deO teórico está caminhando hoje para o plano mais prático.” Aqui, vovó, estão seus fiéis servos digitais, prontos para assumir docilmente toda a rotina chata do Homo sapiens!
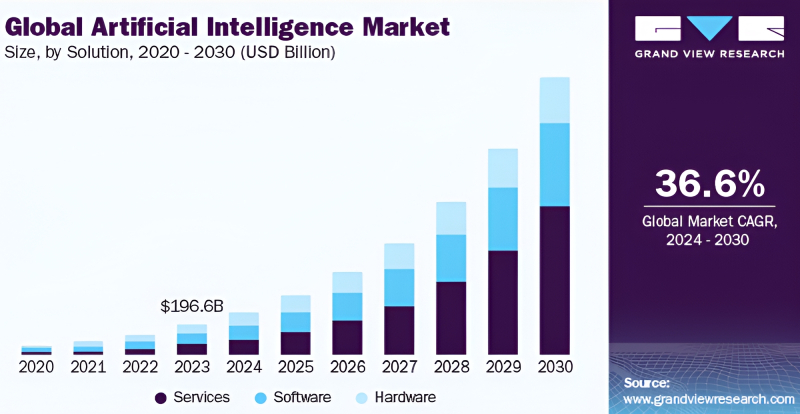
De acordo com uma estimativa da Grand View Research feita em junho de 2024, o volume total do mercado global de IA (incluindo software, hardware e serviços) para este ano não excedeu US$ 270 bilhões – ou seja, ficou significativamente aquém dos custos totais de hyperscalers para aquele mesmo ano para expandir sua infraestrutura. Mas você tem que viver dentro de suas possibilidades! (Fonte: Pesquisa Grand View)
⇡#Não é comida para o cavalo?
Como já foi comprovado mais de uma vez na prática, o negócio mais lucrativo durante a corrida do ouro foi a venda de pás. É por isso que o dinheiro que a indústria da IA atrai em grande número hoje acaba principalmente nos bolsos dos desenvolvedores e fabricantes de hardware, enquanto os criadores das próprias ferramentas de software – modelos generativos – recebem muito menos. Se somarmos os montantes gastos pelos hyperscalers globais em 2025 (não apenas Azure, AWS e Google Cloud, mas também Meta* e Oracle) para expandir a sua infraestrutura de TI em 2024, o resultado será cerca de 292 mil milhões de dólares – isto é 88%. mais do que em 2023. Além disso, uma boa parte desses investimentos é retirada dos lucros, e não atraída de fora, de fundos e bancos – a demanda por serviços de IA em nuvem é tão grande no mundo. No entanto, se fundos tão impressionantes são gastos na compra de hardware, o que resta aos criadores dos modelos de IA que são executados nele – e pelo acesso aos quais, em geral, os usuários finais, privados e corporativos, pagam hiperscaladores?
Infelizmente, não resta muito: assim, de acordo com cálculos do banco de investimento Jefferies, da receita total da Microsoft em 2024, não mais do que 3% foi fornecido por modelos de IA (mesmo tendo em conta a imposição forçada de taxas aumentadas para o Copilot – independentemente se um determinado usuário do Microsoft 365 está conectado a ele ou não – em vários países da região Ásia-Pacífico, por exemplo). A ferramenta Firefly AI da Adobe, lançada em março, não se tornou lucrativa até o final do ano, o que também é um sinal bastante alarmante. Em geral, dois terços das grandes empresas especializadas em desenvolvimento de software (43 de 64), cujas ações são negociadas em bolsa, apresentaram queda em vez de crescimento de receitas no final de 2024. E isso é compreensível: o custo de treinar um modelo generativo moderno no nível Llama 3 atingiu US$ 100 milhões, e treinar o Llama 4, de acordo com seus desenvolvedores da Meta*, ameaça custar quase uma ordem decimal a mais. Porque é que esses esforços dispendiosos para trazer ao mercado cada vez mais novas armas nucleares e agentes especializados de IA não começam realmente a justificar-se?
Neste sentido, os analistas da Jefferies apontam para o nível extremamente baixo de prontidão dos clientes finais para integrar a IA nos seus processos de negócio – considerando, aliás, que essa integração terá de ser feita ao vivo, sem parar as atividades diárias e sem fazer pausas. para uma reformulação calma e cuidadosa dos procedimentos habituais. O progresso no campo da IA revelou-se tão rápido que, se traçarmos paralelos com a indústria automobilística, fica assim: as fábricas estão trabalhando a todo vapor, as áreas de vendas dos revendedores de automóveis estão cheias de carros novos, mas há não existe uma rede rodoviária preparada para receber adequadamente todos estes veículos e os postos de gasolina estão extremamente raros espalhados por um vasto território. De acordo com Jefferies, 61% das empresas – potenciais utilizadores de serviços de IA – não são capazes de integrar estes serviços “inteligentes” nos seus processos de negócio simplificados sem uma reestruturação mais ou menos séria destes últimos. E então os investidores e as partes interessadas estão começando a perder a paciência, de modo que, em geral, a situação para os desenvolvedores de BNM não é agradável, uma vez que a taxa de crescimento do mercado global de IA não é alta o suficiente para compensar os seus custos em tempo hábil.
Às vezes, nem todas as pessoas adivinham imediatamente como resolver variantes modernas de CAPTCHA (fonte: GeeTest)
⇡#Se todos ao seu redor são bots, então ninguém é bot
Como determinar se um robô está tentando entrar em uma página da web ou em uma pessoa real? O teste CAPTCHA (teste de Turing Público Completamente Automatizado para distinguir Computadores e Humanos), que desde o início dos anos 2000 tinha o estatuto de padrão de facto para este tipo de verificações, infelizmente, já não é relevante na era da IA generativa: os bots aprenderam a passar com bastante confiança. A busca pela qualidade deliberadamente terrível de escadas, morros e hidrantes nas microimagens propostas atrasou por algum tempo a expansão de máquinas sem alma, mas nos últimos anos já perdeu terreno. Quebra-cabeças mais complexos, como “desenhar um ponto em um labirinto” ou “inserir uma peça do quebra-cabeça no lugar certo”, também estão perdendo significado à medida que os agentes de IA se tornam mais difundidos. A reencarnação do CAPTCHA proposta pelo Google em 2018 na forma de reCAPTCHA v3 não depende mais da aprovação em alguns testes pré-determinados, mas analisa o comportamento do usuário na página – como ele move o cursor do mouse, a que velocidade e com que uniformidade ele digita o texto. o teclado. Porém, os bots mais astutos já conseguem passar até a terceira versão do reCAPTCHA, o que levanta a questão para os desenvolvedores dessas ferramentas: é possível hoje, em princípio, com alto grau de probabilidade distinguir um visitante de uma página web – um pessoa de um bot?
A questão está longe de ser ociosa: em muitas situações, um sistema de computador em um servidor acessado a partir de um computador cliente ou smartphone precisa de total confiança de que está lidando com uma pessoa, caso contrário, o fluxo de mensagens sobre os cobiçados ingressos para o balé querido por muitos irá nunca param, adquiridos em questão de minutos depois de aparecerem no site, ou sobre a compra massiva por especuladores de quantidades limitadas de produtos muito procurados em lojas online nos mesmos minutos. A exigência de identificação biométrica obrigatória irá contrariar as leis de muitos países, e muitos utilizadores terão receio de confiar os seus identificadores biológicos a sites não governamentais. Outras opções, como a comunicação obrigatória entre um visitante ao vivo de um recurso web e um administrador ao vivo através de uma câmera, são muito caras e complicadas, além disso, se os avatares de vídeo de IA ainda não estiverem totalmente prontos para passar por esse tipo de verificação, eles serão muito, muito em breve. Aparentemente, ao criar uma inteligência artificial que é tão indistinguível quanto possível do comportamento humano (com todas as advertências óbvias de que a IA generativa atual está longe de ser forte), as próprias pessoas estão conscientemente se privando das ferramentas para distinguir com segurança entre representantes de seus próprios espécies e bots online que as imitam. E não está claro como lidar com este flagelo. Talvez a equipe OpenAI tenha razão em seu desejo de substituir a busca clássica na Internet por uma “inteligente”, que será realizada por bots a pedido do usuário – já que é impossível evitar o comprometimento total do teste de Turing como um trabalho ferramenta, não seria melhor liderar o movimentorecusa consciente disso?

Treinado em uma pilha de livros que se tornaram de domínio público e ali deitado (fonte: geração de IA baseada no modelo FLUX.1)
⇡#É tudo uma questão de treinamento
O trabalho intensivo no modelo GPT-5, também conhecido pelo codinome Orion, na OpenAI começou imediatamente após a quarta versão deste BYM ter sido disponibilizada aos usuários em março de 2023 (principalmente na forma de uma atualização para ChatGPT). No entanto, até o final de dezembro de 2024, nenhuma data de lançamento mais ou menos definitiva para os “Cinco” foi anunciada: os desenvolvedores, como o Wall Street Journal aprendeu, não têm dados suficientes disponíveis em fontes abertas para treinar adequadamente seus próximos ideia . A Microsoft, principal investidora da OpenAI, esperava que o Orion fosse concluído até o verão de 2024, mas embora a arquitetura do novo modelo generativo, aparentemente, já esteja geralmente formada, foi com o treinamento que a equipe encontrou dificuldades pelo menos duas vezes – como vezes devido à falta de informações de treinamento para formar nas entradas de seus inúmeros perceptrons os pesos necessários para uma operação confiável. As fontes da publicação estimam o custo de uma sessão de seis meses desse treinamento em aproximadamente US$ 1 bilhão – este é apenas o pagamento pelo hardware usado no processo, sem levar em conta os salários dos funcionários e outras despesas relacionadas. Também é relatado que os desenvolvedores podem tentar preencher as quantidades ausentes de dados de treinamento usando informações sintéticas geradas por outros BYMs (em particular, GPT-4o), mas isso, com toda a probabilidade, não terá o melhor efeito na qualidade de a operação final do sistema.
Enquanto isso, a Universidade de Harvard, com a participação financeira da Microsoft e da OpenAI – apenas para a formação de BNM de alta qualidade, embora não tão monstruoso quanto o Orion, que continua derrapando na decolagem – um banco de dados formado por um milhão de livros cujos direitos autorais foram já expirou. Para efeito de comparação: Books3, usado desde 2020, é um dos mais extensos bancos de dados abertos contendo livros – textos longos e altamente conectados, analisando os quais o modelo generativo pode, em princípio, aprender a criar algo semelhante, e não se limitar a respostas até dois ou três parágrafos – inclui menos de 200 mil livros. Foi nos Livros3, em particular, que os modelos da família Llama foram treinados.

«Você não entende, cara. Isto é diferente. Deixe-me explicar” (fonte: geração de IA baseada no modelo FLUX.1)
⇡#Dê razões para isso
O tom convincente que os smart bots costumam assumir nas conversas com os usuários, no terceiro ano da revolução da IA, não é mais enganoso: as pessoas estão acostumadas com o fato de que os modelos generativos cometem erros e que precisam pelo menos dos pontos mais importantes dos dados que produzem (se forem informações verificáveis, e não um produto da criatividade da máquina) verifiquem novamente. Nesse sentido, modelos de raciocínio são projetados para reduzir a carga do cérebro humano, capazes não apenas de demonstrar um determinado resultado obtido a partir da multiplicação de matrizes na memória infinita das GPUs do servidor, mas também de reproduzir uma cadeia de raciocínio lógico e/ ou análise das fontes nas quais a conclusão foi tirada. O modelo de linguagem pequena (SLM) Phi-4 apresentado pela Microsoft em dezembro com 14 bilhões de parâmetros operacionais se enquadra na categoria de raciocínio (o GPT-4, para efeito de comparação, tem mais de um trilhão deles, e mesmo o GPT-3 tinha 175 bilhões ). De acordo com o desenvolvedor, a alta qualidade das respostas do Phi-4 às solicitações dos usuários é garantida por uma seleção criteriosa de material de treinamento, no qual conteúdo particularmente notável gerado por humanos foi complementado com dados sintéticos igualmente dignos (ou seja, gerados por outros modelos de IA). , bem como depuração cuidadosa do MNM após o treinamento inicial.
Em dezembro, o Google revelou ao mundo um modelo abrangente Gemini 2.0, que, além de ser racional, também é multimodal e oferece funcionalidade de agente de IA – a capacidade de realizar tarefas especializadas em um nível muito alto, substituindo assim quase completamente os humanos. Durante a apresentação, o Gemini 2.0 criou imagens em tempo real e se comunicou com a operadora por voz em diversos idiomas. Além disso, este BYM está integrado com quase todos os serviços internos do Google, o que lhe permite resolver muitas tarefas relevantes para seus usuários potenciais com ainda mais rapidez (e, presumivelmente, com mais precisão) – desde a busca de informações na Internet até a escrita do código do programa. .
A OpenAI não ficou atrás dos seus concorrentes, tendo levantado no final de dezembro o véu do sigilo sobre a “IA mais inteligente do mundo”, segundo a sua versão, claro, o novo raciocínio BYAM o3 e o3-mini. Esta apresentação acabou por ser mais um teaser, uma vez que na altura da mesma o treino de ambos os modelos ainda não tinha sido concluído. Tal como outras IAs de raciocínio, o3 e o3-mini lidam com problemas complexos, dividindo-os em problemas mais pequenos e de resolução mais rápida – e depois apresentando a sequência de tarefas como uma cadeia lógica de raciocínio. Em contraste com esta abordagem, os NMLs “clássicos” simplesmente passam a próxima solicitação inteiramente através de suas redes neurais – e produzem um resultado pronto, deixando o questionador completamente inconsciente de exatamente como a resposta foi recebida. Os modelos de raciocínio, é claro, superam os “clássicos” em termos de um indicador como a frequência de alucinações, uma vez que tal IA é capaz de verificar a correspondência mútua das respostas dadas a cada parte da pergunta original e verificar (através do mesma Internet) suas fontes de informação. Mas, ao mesmo tempo, todos esses procedimentos prolongam o processo de obtenção de uma resposta e o tornam mais intensivo em recursos, de modo que os especialistas não estão inclinados a considerar os modelos de raciocínio inequivocamente vencedores.

O mesmo processador ARM para AI-PCs, que em um futuro próximo pode simplesmente se tornar uma das opções básicas para uma plataforma de computação pessoal moderna (fonte: Qualcomm)
⇡#Os AI-PCs serão lançados?
Computadores prontos para inferência local de modelos generativos – PCs habilitados para IA, também conhecidos como AI-PCs, ou simplesmente AI-PCs – no início de 2024, muitos analistas de mercado de TI previram um futuro brilhante. Supunha-se que, na esteira da mania dos chatbots inteligentes, gavetas de imagens baseadas em prompts de texto e outras maravilhas do BYM, tanto os consumidores privados quanto os clientes corporativos começariam em massa a votar com seu dinheiro de trabalho em computadores pessoais e até mesmo em smartphones equipados com o hardware apropriado, sejam adaptadores gráficos discretos para sistemas x86 ou chips ARM com funcionalidade estendida como Série A, projetada pela Apple, ou Qualcomm Snapdragon 8 Elite. No entanto, como ficou claro no final de Dezembro, um milagre não aconteceu: embora uma proporção significativa de utilizadores tenha, sem dúvida, interesse na inferência local, poucos estão dispostos a pagar a mais por tal oportunidade no actual difícil (para todo o mundo). ) realidades económicas.
Na sequência de relatos sobre as dificuldades dos fabricantes de hardware informático, que contavam seriamente com a revolução AI-PC, mas se depararam com a dura realidade, os analistas concluíram que o momento desta mesma revolução será adiado indefinidamente – uma vez que a fase crescente de o “superciclo” no mercado consumidor de TI ainda não chegou. Nem os esforços da Microsoft para promover o Copilot, nem o fim iminente do suporte ao Windows 10 em 2025, estimularam significativamente o crescimento das vendas de PCs e smartphones em geral, e ainda mais de suas versões caras projetadas para modelos de IA de inferência local. Um indicador eloquente: PCs AI da classe Copilot Plus baseados no sistema em chip Snapdragon X para todo o III trimestre. Em 2024, apenas 700 mil unidades foram vendidas em todo o mundo, apesar de serem significativamente mais baratas que os sistemas x86 com gráficos discretos comparáveis em funcionalidade.
Como resultado, observam os especialistas, “AI-PC” como um segmento separado no mercado de computadores pode não ocorrer: a antiga situação com placas de som, que antes tinham que ser adquiridas exclusivamente separadamente, escolhendo entre uma lista bastante extensa de opções, depois mexer nos drivers, repetirá a compatibilidade com jogos e outros softwares – e a certa altura, as placas de áudio integradas se tornaram a opção padrão, enquanto as discretas se tornaram um produto de nicho. Da mesma forma, aceleradores poderosos adequados para resolver problemas de IA (discretos ou como parte de sistemas em um chip) têm todas as chances, em um futuro próximo, de se tornarem um elemento estrutural padrão para quase qualquer sistema pessoal, seja um computador ou um smartphone, mas nem um pouco. Em cem por cento dos casos, eles certamente serão usados especificamente para inferência. Afinal, recorrer à nuvem para serviços de IA é mais rápido e fácil para a grande maioria dos usuários, e os entusiastas encontrarão, de alguma forma, meios decentes para executar modelos locais.
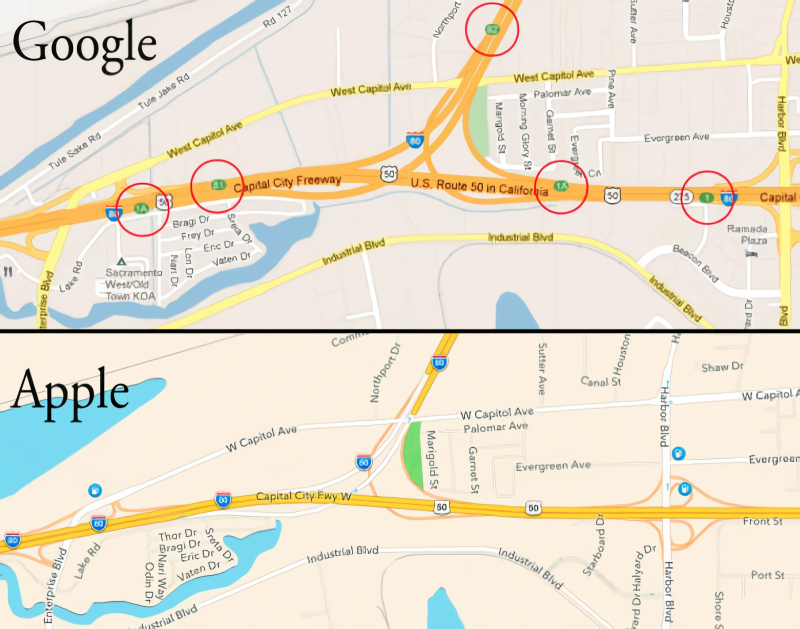
«Confiabilidade” Apple Maps de 2012 é claramente herdada pela Apple Intelligence em 2024 (Fonte: Virgula)
⇡#Onde você viu maçãs intelectuais?
O gênio do marketing de Steve Jobs e, em menor grau, de seus seguidores como CEO da Apple é indiscutível. Mesmo seus fãs mais apaixonados têm cada vez mais dúvidas sobre as soluções tecnológicas que a empresa oferece ano após ano – basta lembrar a demissão do chefe de desenvolvimento do francamente desastroso Apple Maps em 2012, os muitos anos de desaceleração secreta do “moralmente iPhones obsoletos” para estimular a compra de novos, ou a história muito recente de falha em massa de monitores iMac com chips Apple Silicon imediatamente após o término do período de garantia para eles. Aparentemente, nem tudo está indo bem com o projeto Apple Intelligence (abreviado, é claro, AI – ótimo marketing!) para introduzir IA em produtos com o logotipo de uma maçã mordida – e ainda assim os investidores entusiasmados apenas acreditaram nisso!
A versão 18.1 do iOS, lançada em outubro, adicionou suporte para essa mesma IA aos dispositivos compatíveis – porém, até o momento apenas como um produto em beta. E, como ficou claro quase imediatamente, não sem motivos sérios. Apenas em dezembro, começaram a aparecer evidências de que a IA subjacente à Apple Intelligence lidava com material factual com muita liberdade, para usar uma terminologia extremamente moderada. Assim, tomando como base a reportagem da BBC sobre o assassinato de alto perfil do CEO da United Healthcare, Brian Thompson, a AI ofereceu sua própria interpretação dos acontecimentos – segundo a qual o acusado Luigi Mangione supostamente atirou em si mesmo, o que na verdade não aconteceu. Em resposta a um pedido de resultados do campeonato de dardos, a AI prontamente nomeou o vencedor – embora naquela época a competição ainda estivesse em andamento. No noticiário noturno, a AI afirmou que a celebridade mundial do tênis Rafael Nadal se revelou mal (condenado pela lei russa), o que também não é verdade. E assim por diante: no final de 2024, o Apple Intelligence não acumulou menos falhas do que o Apple Maps imediatamente após seu lançamento, há doze anos. É verdade que a empresa ainda prometeu nos últimos dias de dezembro que iria atualizar a sua IA “nas próximas semanas”, mas já conseguiu causar danos à sua reputação com esta ferramenta claramente não afiada.
________________
* Incluído na lista de associações públicas e organizações religiosas em relação às quais o tribunal decidiu liquidar ou proibir atividades que tenham entrado em vigor pelos motivos previstos na Lei Federal de 25 de julho de 2002 nº 114-FZ “ Sobre o Combate às Atividades Extremistas”