
Três anos após o surgimento dos processadores Alder Lake, a Intel lançou uma grande atualização em sua linha de CPUs para desktop. No final do outono passado, lançou Arrow Lake, novos processadores que têm muito pouco em comum com Alder Lake ou seus parentes próximos Raptor Lake. E formalmente foi uma mudança de gerações muito oportuna. Os processadores Intel Core anteriores de 13ª e 14ª gerações foram desacreditados por um escândalo de degradação, que afetou bastante sua reputação. E os AMD Ryzen 9000 e 9000X3D, lançados no ano passado, aumentaram seu desempenho e, em muitos casos, começaram a parecer visivelmente mais atraentes do que as soluções de seus concorrentes. Nessas condições, foi confiado a Arrow Lake o papel de tábua de salvação, graças à qual a Intel iria melhorar seus negócios no segmento de desktops.
No entanto, como você provavelmente já sabe, nada aconteceu: em alguns casos, Arrow Lake acabou sendo ainda mais lento que seus antecessores, de modo que dificilmente podem reivindicar alta popularidade e ampla distribuição. E é muito estranho. Comparado às gerações anteriores de processadores Alder Lake e Raptor Lake, o novo Arrow Lake deu um grande salto tecnológico. Em primeiro lugar, eles possuem novos núcleos P e E, baseados em arquiteturas mais avançadas. Em segundo lugar, pela primeira vez, a Intel utilizou não a sua própria produção para produzir um produto em massa, mas a capacidade de um contratante terceiro, a TSMC, que pode oferecer uma pilha mais moderna de tecnologias de semicondutores. E em terceiro lugar, a Intel deixou de usar cristais de silício monolíticos em CPUs de desktop, mudando para uma estrutura de processadores em blocos (chiplet).

O nome oficial da nova série de soluções para desktop – Core Ultra 200 – também não foi escolhido por acaso. Os representantes da família Arrow Lake receberam tantas inovações que a Intel decidiu torná-los um novo ponto de partida e não os classificou como Core de 15ª geração. Além disso, mesmo se você olhar superficialmente para Arrow Lake, sua distância em relação ao Lago Raptor na escada evolutiva é igual a dois degraus e meio. Entre essas famílias de processadores não existe apenas um elo intermediário completo – Meteor Lake, mas também um meio-passo na forma do irmão mais novo de Arrow Lake – o processador Lunar Lake. No final das contas, eles não chegaram ao segmento de desktops: Lunar Lake foi projetado exclusivamente como um produto móvel, e o lançamento da versão desktop do Meteor Lake foi restringido pela Intel ao longo do caminho. No entanto, em cada um desses designs, a Intel adicionou e aprimorou certas inovações e melhorias.
TSMC N5
TSMC N5P
Embora os processadores sênior de Arrow Lake mantenham a mesma fórmula nuclear de 8p+16e, que era inerente aos seus antecessores, parecia que eles deveriam dar um salto notável em velocidade. A Intel ostentou repetidamente suas novas arquiteturas Lion Cove (P-JADRA) e Skymont (E-Yadra), que fornecem um aumento sério no IPC (desempenho específico em termos da frequência do tato). A própria empresa deu estimativas de +9 % para p-nuclear e +32 % para o e-yader, que, sujeitos ao nível principal da frequência geral do relógio, podem tornar Arrow Lake pelo menos 15-20 % mais rápido que seus antecessores. Além disso, também foi uma séria melhora na eficiência energética: os materiais de marketing afirmavam que o desempenho do Lago Raptor dos processadores de Arrow Lake requer duas vezes menos energia e, em aplicações reais, elas os superam em termos de economia em até 40 %.
Neste artigo analisaremos como essas expectativas divergiram da realidade e, o mais importante, por que isso aconteceu. O personagem principal hoje será o modelo mais antigo da nova família – o Core Ultra 9 285K de 24 núcleos. Porém, em muitos casos, tudo o que for dito se aplicará não só a ele, mas a todos os seus irmãos. E para tornar a análise o mais fundamentada possível, falaremos não apenas sobre desempenho e consumo de energia em tarefas reais, mas também sobre as características técnicas do Arrow Lake – o design, a arquitetura, a nova plataforma LGA1851 e assim por diante.
⇡#Arrow Lake Linep
A primeira parte da programação de Arrow Lake foi apresentada em 25 de outubro de 2024. Consistia em cinco processadores: o carro-chefe Core Ultra 9 285K e suas modificações simplificadas Core Ultra 7 265K e 265KF, bem como os mais acessíveis Core Ultra 5 245K e 245KF (versões com índice F, como antes, não possuem um -na GPU). Todos esses processadores são baseados no mesmo silício, e as diferenças incorporadas neles são artificiais, mas não insignificantes. Os recursos diferenciadores são o número de núcleos de computação ativados, tamanhos de memória cache, frequência e pacote térmico.
Nos primeiros dias do ano novo, os processadores KF-KF também adicionaram modelos comuns destinados ao mercado de massa. Eles bloquearam fatores, frequências menores e um saco de calor mais modesto. A tabela abaixo são os detalhes.
P-cores, GHzFrequência
E-núcleos, gráficos GHz,
Núcleos xel3-ketsh,
Aqui é imediatamente perceptível que a velocidade máxima do clock dos processadores Arrow Lake é limitada a 5,7 GHz. Isso é significativamente menor do que a frequência que os processadores Raptor Lake conseguiram atingir. Por exemplo, o carro-chefe Core i9-14900KS pode ter overclock em velocidade nominal de até 6,2 GHz, o que não está disponível para novos produtos. Além disso, o atraso na frequência não é exclusivo do carro-chefe. Outros modelos também são inferiores aos seus antecessores em termos de frequências máximas de 100-200 MHz.
Ao mesmo tempo, as restrições do passaporte sobre o consumo máximo de energia para os representantes mais antigos da série Core Ultra 200 permaneceram quase no mesmo nível que para o Raptor Lake. A potência elétrica máxima das versões K do Core Ultra 9 e Ultra 7 é de 250 W (era 253 W). Mas para o Core Ultra 5 245K/KF diminuiu de 181 para 159 W, e para o resto do Core Ultra 5 – de 148-154 para 121 W.
Caso contrário, as características numéricas de Arrow Lake são semelhantes às de Raptor Lake. Neste estágio de evolução do processador, a Intel não alterou o número estabelecido de núcleos do processador nem o tamanho do cache de terceiro nível.
⇡#Arrow Lake – um processador econômico com acelerador de IA
Um dos principais objetivos da Intel ao projetar o Arrow Lake foi reduzir o consumo de energia e a dissipação de calor, indicadores que têm aumentado constantemente nos produtos de desktop da empresa nos últimos anos. Claro, o consumo de qualquer processador pode ser limitado por uma decisão obstinada, mas neste caso o desempenho será prejudicado. Portanto, em Arrow Lake não há diminuição radical no apetite energético – eles são reduzidos exatamente o suficiente para não destruir o aumento de desempenho em comparação com seus antecessores. Porém, os mesmos núcleos P e E do Arrow Lake também são usados no Lunar Lake móvel com TDP na faixa de 17 a 30 W, ou seja, novos processadores de desktop podem ser muito econômicos se necessário.

Outra tarefa que a Intel resolveu com o lançamento do Arrow Lake foi aderir ao boom da IA. A empresa considerou que havia chegado o momento certo para o surgimento de plataformas de massa com um acelerador de rede neural (NPU) integrado e adicionou esse acelerador ao novo processador de desktop. No entanto, a abordagem escolhida revelou-se tímida também aqui. O NPU está formalmente presente em Arrow Lake, mas é muito pequeno para atender aos requisitos formulados pela Microsoft para PCs modernos. Isso significa que os representantes da família Arrow Lake não fornecerão aceleração de hardware para a maior parte dos algoritmos de IA no Windows 11, e o NPU existente só poderá ser usado em algumas tarefas otimizadas individuais, cujo número pode acabar sendo muito pequeno .
No entanto, a lógica da Intel é que, no caso dos processadores para desktop, é mais racional redirecionar o orçamento do transistor para os núcleos x86 tradicionais, e por enquanto o NPU estará lá apenas para exibição. E, a propósito, é por esta razão que a empresa não se concentrou nas capacidades de IA da Arrow Lake em materiais de marketing, acreditando que ainda não estavam suficientemente desenvolvidas para uma promoção activa.
Caso contrário, com o lançamento do Arrow Lake, a empresa simplesmente avançou ao longo do caminho evolutivo. O lema, sob o qual essas CPUs entraram no mercado, são simples: “Processadores de massa frios e eficazes para aplicações e jogos”.

Resumindo, a lista de suas principais características (falaremos sobre cada uma delas com mais detalhes a seguir) é a seguinte:
- Processador multichip montado com tecnologia Intel Foveros. Consiste em quatro cristais ativos (CPU, SoC, GPU, E/S) e dois cristais passivos montados em um único substrato de silício.
- Todos os cristais ativos são fabricados pela TSMC usando processos de litografia EUV e padrões de até 3 nm. Sua área total é de 251 mm². A área do processador no substrato é 302,9 mm2.
- Até 8 núcleos P com arquitetura Lion Cove (+9% IPC em comparação com Raptor Cove de acordo com a Intel) e até 16 núcleos E Skymont (+32% IPC em comparação com Skymont).
- O suporte para a tecnologia Hyper-Threading foi removido do processador no nível do silício pela primeira vez desde 2002.
- O cache de segundo nível de núcleos P é de até 3 MB por núcleo (no Raptor Lake – 2 MB), E-cores – 1 MB por núcleo (o mesmo que Raptor Lake). Cache de nível 3 – máximo 36 MB.
- O TDP dos modelos principais é de 125 W, seu consumo máximo de energia chega a 250 W. Ao mesmo tempo, é prometida uma melhoria de 30% na eficiência energética em comparação com Raptor Lake.
- Gráficos integrados baseados em 4 núcleos Xe com arquitetura Xe-LPG (Alchemist). O número de unidades de execução no núcleo gráfico é duplicado em comparação com Raptor Lake.
- 13 coprocessador de IA de hardware TOPS NPU.
- DDR5 de canal duplo é compatível: até DDR5-5600 (com UDIMMs) ou até DDR5-6400 (com CUDIMMs).
- Controlador de processador PCIe 5.0 com 20 pistas (você pode usar uma placa de vídeo PCIe 5.0 x16 e uma unidade PCIe 5.0 x4 ao mesmo tempo) mais 4 pistas PCIe 4.0 adicionais.
- Portas Thunderbolt 4/USB 4 no processador.
- O novo formato LGA1851: Arrow Lake é exclusivamente compatível com placas-mãe baseadas em chipsets Intel série 800.
- Os processadores pertencem à série Core Ultra 200.
⇡#Para onde foi o Hyper-Threading e o que aconteceu com o Thread Director?
Arrow Lake conta com os novos núcleos P Lion Cove de alto desempenho e os eficientes núcleos E Skymont, que a Intel testou pela primeira vez em Lunar Lake e que estão a dois passos dos núcleos Raptor Cove e Gracemont usados em Raptor Lake. Ao mesmo tempo, o número de núcleos nos representantes mais antigos da família Arrow Lake permaneceu inalterado: novamente não há mais de 24 deles – até 8 produtivos e até 16 eficientes. No entanto, isso não impede a Intel de prometer que Arrow Lake supera Raptor Lake em 9% em cargas de trabalho de thread único e 15-20% em cargas de trabalho multithread devido a melhorias arquitetônicas. E isso é especialmente surpreendente dado o fato de que Arrow Lake não suporta mais a tecnologia multithreading Hyper-Threading, que permitia que núcleos P executassem dois threads ao mesmo tempo. Ou seja, o novo carro-chefe com 24 núcleos suporta apenas 24 threads simultâneos, enquanto o Core i9-14900K é capaz de atender 32 threads.
Degradação de desempenho? Na verdade. A Intel está vendendo a eliminação do Hyper-Threading como se os jogadores pedissem isso à empresa há anos, e agora ela finalmente está ouvindo esses pedidos. Claro, isso é apenas uma desculpa. A verdadeira razão é outra, como o desejo de limitar ainda mais o consumo de energia dos novos processadores e reduzir a área e o orçamento de transistores da matriz. Mas o principal que a Intel chama a atenção é que graças às melhorias na arquitetura, a falta do Hyper-Threading não será um problema em termos de desempenho, mesmo quando se trata de cargas altamente multithread.

E ele explica imediatamente: os novos E-cores devem antes de tudo compensar a falta de Hyper-Threading nos P-cores de Arrow Lake. Ora, este é um recurso muito poderoso com desempenho visivelmente aumentado, que, segundo a Intel, está se aproximando do nível dos núcleos P do Raptor Cove. Além disso, os núcleos E em Arrow Lake receberam peso adicional. Para torná-los mais significativos, a Intel mudou o princípio de distribuição de threads – agora todos os novos threads são enviados primeiro para os E-cores, e somente se sua capacidade não for suficiente e o thread carregar o E-core 100%, sua execução é encaminhado para o P-core.

Isso significa que em Arrow Lake, entre outras coisas, a estratégia do Thread Director, o mecanismo integrado de software e hardware para distribuição de carga, mudou. Junto com os novos núcleos, o Thread Director de terceira geração apareceu em Arrow Lake com diferentes prioridades. Não só inicialmente favorece núcleos eficientes, mas também utiliza algoritmos mais avançados para classificar tarefas e prever suas demandas de recursos computacionais. Por exemplo, uma mudança importante no Thread Director é que ele agora tenta separar automaticamente os aplicativos de jogos de todos os outros, e usar uma estratégia diferente para eles, enviando-os diretamente para os P-cores.

A Intel afirma que a repriorização da alocação de threads melhorou ainda mais a relação custo-benefício do Arrow Lake. Threads que não exigem desempenho máximo serão executados por E-cores, e aplicativos que consomem muitos recursos acabarão de alguma forma sendo executados por P-cores, apenas com um pequeno atraso. Mas o principal aqui é que Arrow Lake tem um perfil de desempenho significativamente diferente – a relação de desempenho entre os núcleos P e E sofreu grandes mudanças. E isso é fácil de ilustrar em um experimento simples envolvendo os carros-chefe Raptor Lake e Arrow Lake: o gráfico abaixo mostra o dimensionamento do resultado no benchmark Cinebench R23 ao aumentar o número de threads envolvidos no trabalho de um para o máximo possível.
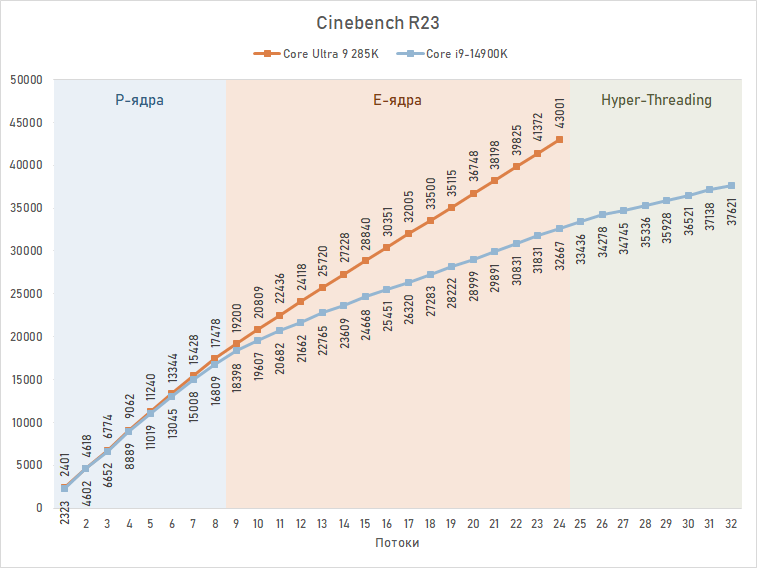
Como a renderização requer mobilização máxima de recursos da CPU, ambos os processadores carregam primeiro os P-cores livres (um thread por núcleo), depois a carga é enviada para os E-cores e, por último, os núcleos virtuais fornecidos pelo Hyper-Threading são usados ( se forem). Assim, na faixa de um a oito threads, as linhas correspondentes ao Core i9-14900K e Core Ultra 9 285K são quase idênticas e, no caso de carga de oito threads, a diferença chega a apenas 4%. Isso mostra que os P-Cores do Lion Cove não superam muito o desempenho do Raptor Cove. Mas o mais interessante acontece a seguir. Quando o número de threads aumenta acima de oito, os E-cores entram em ação. E se no caso de Raptor Lake, uma quebra perceptível é visível neste local do gráfico, associada à menor potência de seus núcleos Gracemont E em comparação com os núcleos P, então na curva de Arrow Lake tal quebra é quase imperceptível . Acontece que os núcleos E do Skymont têm desempenho muito próximo dos núcleos P.
Consequentemente, a parcela do leão do núcleo Ultra 9 285K do Core i9-14900K com base nos resultados do Cinebench R23 é formada com precisão devido ao progresso no e-yadra. Com uma carga de 24 fluxo, a lacuna nos indicadores de teste excede 30 %, e os oito fluxos restantes na reserva do Lago Raptor, fornecidos pelo suporte de hiper-threading, não são suficientes para recuperar um atraso tão grave. Como resultado, com o maior número possível de núcleo múltiplo possível, o Core i9-14900K é de 15 %, o que confirma a Intel de que o poderoso e-jadra é mais útil que o hiper-fibra.
E o gráfico acima mostra como Arrow Lake difere fundamentalmente do habitual Raptor Lake. Portanto, teremos que dedicar parte deste artigo à arquitetura dos novos kernels. Isso ajudará você a entender quão profundas são as diferenças entre os novos processadores.
⇡#Enseada de núcleos produtivos
A falta de suporte Hyper-Threading não é a única grande diferença entre os núcleos Lion Cove e Raptor Cove usados no Raptor Lake. O desejo da Intel de aumentar o desempenho e ao mesmo tempo melhorar a eficiência energética exigiu uma série de mudanças importantes, a mais significativa das quais envolveu a alteração da estrutura da memória cache.
Assim, pela primeira vez no núcleo Lion Cove, apareceu um cache de dados de nível “um e meio”, localizado na hierarquia entre os caches L1 e L2. Esse cache adicional tem 192 KB e, de acordo com a Intel, é um acréscimo ao tradicional cache de dados L1 de 48 KB. Porém, a latência do cache “um e meio” é duas vezes maior que a do L1 e é de 9 ciclos, mas em qualquer caso não será supérflua. Além disso, o cache L1 tradicional no Lion Cove tornou-se mais rápido e sua latência finalmente diminuiu de 5 para 4 ciclos de clock, como nos núcleos Zen 4/Zen 5.
Do lado de aumentar a eficiência do subsistema de cache de dados no Lion Cove está o aumento no volume do cache L2, que no novo P-core cresceu para 3 MB (contra 2 MB no Raptor Cove). Ao mesmo tempo, sua latência permaneceu quase inalterada e é de 17 ciclos. É verdade que para obter este indicador, a Intel teve que reduzir a associatividade de 16 para 10 threads, o que em teoria reduz a eficiência do cache de dados (a probabilidade de acesso bem-sucedido).
Paralelamente ao crescimento da memória cache em Lion Cove, o buffer DTLB, responsável pela conversão rápida de endereços de memória virtual em físicos, também cresceu em tamanho. A sua profundidade aumentou de 96 para 128 páginas, o que deverá ter um efeito positivo na eficiência deste buffer. Mas isso não é tudo. Em um esforço para acelerar o trabalho do núcleo Lion Cove com dados, a Intel adicionou um terceiro dispositivo endereçável adicional a ele, atendendo às operações de upload.
Mas as melhorias não afetam apenas a forma como os dados são processados nos P-cores. O pipeline de execução do Lion Cove também mudou visivelmente em todos os seus estágios para aprimorar a capacidade de processar instruções em paralelo. O carregamento de instruções x86 para execução passou a ocorrer a uma taxa de oito por ciclo de clock (e não seis, como antes), a taxa de decodificação dessas instruções aumentou proporcionalmente, e o cache de microoperação não só ficou maior em um quarto (até 5.250 entradas), mas também ganhou a capacidade de emitir 12 microoperações por ciclo de clock.

O domínio executivo do Lion Cove não apenas adquiriu dispositivos adicionais, mas foi estritamente dividido em partes inteiras e vetoriais com seus próprios agendadores. Esta separação permitirá à Intel, se necessário, simplesmente reequilibrar o núcleo em arquiteturas futuras. Mas o que é mais importante neste estágio é aumentar a velocidade do despachante para processar oito microoperações por ciclo de clock e o buffer de backoff para doze operações por ciclo de clock. Juntamente com o que foi dito no último parágrafo, isso significa que o núcleo do Lion Cove é capaz de realizar oito operações por ciclo de clock, contra seis operações do Raptor Cove em todo o pipeline de execução.
Para suportar o aumento do ritmo de trabalho, a Intel atualizou a unidade de previsão de filiais para aumentar em oito vezes o volume de estatísticas acumuladas e, por isso, tornou-se muito mais precisa. Além disso, a profundidade do buffer de reordenação de instruções foi aumentada em 13% e o número de portas no domínio de execução foi aumentado uma vez e meia (de 12 para 18).
O aumento do poder computacional do novo núcleo pode ser visto claramente pelo aumento no número de atuadores. O número de blocos ALU na parte inteira do domínio executivo aumentou de cinco para seis, o número de blocos de transição de endereço – de dois para três, blocos de deslocamento – de dois para três, blocos de multiplicação – de um para três. Mudanças semelhantes podem ser vistas na parte vetorial. Agora contém quatro blocos SIMD em vez de três, além de dois blocos de multiplicação (FMA) e dois blocos de divisão.

Tudo isso junto permite à Intel falar sobre uma melhoria no IPC (desempenho específico em igual frequência) dos novos núcleos P em 9% em comparação com o Raptor Cove. Em teoria, tal aumento pode compensar apenas parcialmente a falta de suporte à tecnologia Hyper-Threading em P-cores, que permitia que cada núcleo executasse dois threads em paralelo. No entanto, o suporte para Hyper-Threading no nível arquitetônico ainda permanece, mas a Intel decidiu excluí-lo em processadores móveis e desktop para reduzir a dissipação de calor. E isso faz algum sentido, já que o Hyper-Threading proporcionou um aumento de cerca de 15% no desempenho em cargas de trabalho multithread, mas o consumo de energia aumentou em mais de 25%. Ao mesmo tempo, a Intel promete manter o suporte Hyper-Threading para processadores de servidor, uma vez que o multithreading avançado é de fundamental importância neles.
⇡#Núcleos Skymont eficientes
Muitas pessoas consideram os núcleos com eficiência energética (E-cores) uma reflexão tardia no processador que causa mais problemas do que valem. No entanto, esta opinião não se aplica aos E-cores em Arrow Lake. Eles usam a nova arquitetura Skymont, proporcionando um salto notável no desempenho, mantendo baixo consumo de energia. E são esses núcleos que proporcionam a maior parte do aumento no desempenho integrado dos novos processadores como um todo.
Em comparação com os E-cores Gracemont usados em Raptor Lake, os novos núcleos Skymont tornaram-se significativamente “mais largos”: seu decodificador de três seções pode processar até nove instruções simultaneamente, o que é uma vez e meia maior que as capacidades do Gracemont. Esta expansão da parte de entrada do transportador Skymont se reflete em todas as etapas subsequentes.
Em particular, a linha de microoperações decodificadas agora tem uma capacidade de 96 elementos contra 64 elementos anteriormente. Além disso, o decodificador Skymont usa a técnica de nanocódigo, que evita atrasos na interpretação das instruções complexas x86. Cada seção do decodificador está envolvida na decodificação de forma independente e não bloqueiam o acesso um do outro a tabelas de transformação geral. Isso significa que o ritmo de decodificação em Skymont cresceu não apenas devido à expansão do decodificador, mas também devido à minimização do número de tempo de inatividade forçado em um código X86 complexo.

Além disso, o domínio executivo mudou proporcionalmente. Na fase de renomeação de registros e colocação de comandos para execução, oito microoperações podem ser processadas simultaneamente (anteriormente – cinco), e na fase de renúncia e finalização – 16 microoperações por ciclo de clock (anteriormente – oito). Uma expansão semelhante da capacidade também afetou filas e buffers. Por exemplo, o buffer de reordenação de instruções para execução fora de ordem cresceu para 416 entradas (de 256), e mudanças semelhantes também afetam arquivos de registro, uma estação de reserva e outros elementos auxiliares.
Mas o mais impressionante é como a Skymont cresceu em número de atuadores. O número de portas agora aumentou para 26 e, entre outras coisas, oito ALUs inteiras, três processadores de ramificação e três dispositivos de carregamento de dados estão conectados a elas. Quanto a trabalhar com instruções de números reais e vetoriais, para esses fins o Skymont possui quatro ALUs de 128 bits com suporte para FMA (multiplicação-adição). Com base nisso, podemos dizer que as capacidades computacionais do núcleo Skymont literalmente dobraram em comparação com o Gracemont.
Um grande aumento no número de dispositivos de computação exigiu uma revisão das capacidades do kernel para trabalhar com dados. Como resultado, o cache de primeiro nível, embora mantivesse o volume de 32 KB, recebeu largura de banda uma vez e meia maior e aprendeu a atender três cargas de dados de 128 bits por ciclo de clock. Além disso, o rendimento do cache L2 (que em E-cores é comum a quatro núcleos ao mesmo tempo) dobrou para 128 bytes por ciclo de clock. Além disso, o barramento que conecta os caches L2 e L3 também foi expandido. Agora você pode bombear até 32 bytes por ciclo de clock através dele. Junto com o aumento no rendimento, o volume do cache de segundo nível também cresceu – para cada quatro núcleos Skymont não há 2, como antes, mas 4 MB de L2. E na nova versão dos E-cores, cresceu o L2 TLB (tabela de tradução de endereços), que agora pode armazenar até 4 mil entradas, enquanto antes era 25% menor.
É curioso que a própria Intel esteja mais disposta a comparar o Skymont não com os E-cores das gerações anteriores, mas com os P-cores dos processadores Raptor Lake. Segundo a empresa, seus novos E-cores são bastante comparáveis em desempenho específico ao Raptor Cove (na mesma frequência de clock), mas consomem quase 40% menos energia. Ao mesmo tempo, em uma comparação mais tradicional com os E-cores Gracemont, o aumento do IPC é de 32% em cargas de trabalho inteiras e de até 55% em operações de ponto flutuante. Separadamente, a Intel indica que a velocidade de trabalho com algoritmos baseados em instruções AVX e VNNI dobrou. Mas, ao mesmo tempo, o Skymont, como outros E-cores das gerações anteriores, não oferece suporte ao AVX-512.

Porém, falando sobre o desempenho dos E-cores, é preciso entender o seguinte. Embora em muitos aspectos, por exemplo, no número de unidades de execução, os núcleos Skymont eficientes sejam superiores aos núcleos produtivos, eles continuam sendo soluções de classe e finalidade diferentes. O fato é que a arquitetura E-core é projetada tendo em vista a eficiência energética, e muitos blocos importantes que consomem muita energia, como a unidade de previsão de desvio ou o cache de instrução decodificada, são reduzidos ou totalmente eliminados. E isso leva ao fato de que os E-cores fazem um excelente trabalho com algoritmos de contagem simples e diretos, mas perdem muito desempenho em códigos complexos com ramificações. Os núcleos P são muito mais onívoros nesse sentido e, portanto, mantêm o papel de “artilharia pesada” na computação com uso intensivo de recursos e continuam a desempenhar um papel de liderança em Arrow Lake, apesar do papel crescente dos núcleos E.
⇡#E o IPC na prática?
Para ter uma ideia do aumento do IPC dos novos núcleos, realizamos um pequeno teste de desempenho usando microbenchmarks do pacote Aida64. Neste teste, comparamos os resultados produzidos pelo Core i9-14900K e pelo Core Ultra 9 285K alinhando todos os seus núcleos em 4 GHz e ativando exclusivamente os oito núcleos P ou os oito núcleos E.
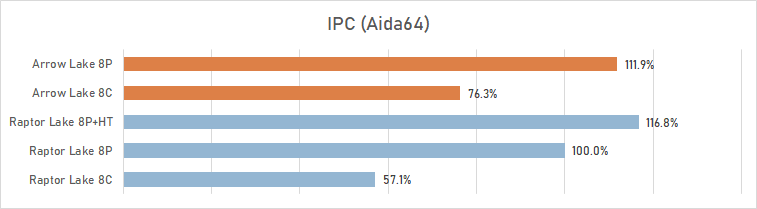
E esse teste geralmente confirma a maioria das estimativas da Intel em relação ao crescimento do IPC. Assim, na frequência do relógio alinhada, o leão Cove P-Jadra é mais rápido que o Raptor Cove P-Jider em quase 12 %-um resultado muito bom. No entanto, é justo apenas se você não levar em consideração a possibilidade de inclusão nos p-IRADES da última tecnologia de hiper-fibra de geração, o que aumenta seu desempenho com vários fluxos em 17 %ao mesmo tempo. Como resultado, em comparação, “Lion Cove contra Raptor Cove com hiper-threading” Os vencedores são mais vantagens antigas de p-Jadra, é de cerca de 4 %.
Nem tudo fica claro com a comparação dos E-cores. A Intel certamente está certa ao dizer que os novos núcleos Skymont E são mais rápidos do que os antigos núcleos Gracemont, e vimos que sua superioridade pode de fato ser estimada em 33%. No entanto, é claramente prematuro colocar os núcleos E de Arrow Lake e os núcleos P de Raptor Lake lado a lado, mesmo na mesma frequência de clock. Em nosso teste de desempenho específico, os novos núcleos Skymont E ficam atrás dos antigos núcleos P Raptor Cove em desempenho em significativos 24%.
O indicador integral apresentado no diagrama acima foi calculado com base em dez benchmarks de natureza diferente, mas você também pode encontrar muitas coisas interessantes nos resultados de testes individuais. Por exemplo, é claramente visto que em algoritmos inteiros mais simples a lacuna entre os núcleos P e os núcleos E na verdade diminui e pode até desaparecer completamente. Mas em casos complexos, onde a proporção de ramificações de código aumenta e as operações são executadas com números de ponto flutuante de dimensão aumentada, pode chegar ao dobro.





Outro ponto interessante é que nem sempre o P-core Lion Cove é melhor que o P-core Raptor Cove mesmo sem levar em conta a tecnologia Hyper-Threading. Existem testes, e não são isolados, onde os núcleos da geração anterior dão resultados melhores que os da nova. Isso se deve em grande parte a mudanças no sistema de cache e no subsistema de memória, e falaremos sobre isso com mais detalhes posteriormente.
⇡#Construção de telhas Arrow Lake
Arrow Lake é o primeiro processador multi-chip para desktop da Intel. Anteriormente, a empresa enviava chips exclusivamente monolíticos, como o Raptor Lake, para o segmento de desktops. No entanto, Arrow Lake herda a abordagem usada no Meteor Lake móvel e no Lunar Lake, onde diferentes blocos funcionais são espalhados por diferentes cristais semicondutores.

Essa distribuição de funções através de vários chips permite que a Intel economize na produção, uma vez que os processos mais avançados são necessários para apenas uma parte do ladrilho de computação da CPU (cristal com núcleos do processador), que possui frequências operacionais máximas e emissão de calor. E no caso de Arrow Lake, esse cristal é produzido de acordo com o processo de 3 nm para o TSMC, que até certo ponto foi uma surpresa, já que inicialmente a Intel planejava liberar esses cristais usando seu próprio processo Intel 20A. No entanto, no último momento, a produção foi transferida para o empreiteiro externo, o que levou a uma situação quando todos os quatro ladrilhos funcionais que compõem Arrow Lake fazem do TSMC.
O cristal SoC ocupa um lugar central em Arrow Lake; um bloco de computação e um cristal de E/S, que implementa interfaces auxiliares (Thunderbolt 4, PCIe 5.0, etc.), estão acoplados a ele em um lado, e um bloco gráfico no outro. outro.

Os blocos são conectados entre si usando a tecnologia Intel Foveros. Isso significa que quatro ladrilhos funcionais são montados em um substrato de cristal, dentro do qual são colocadas todas as conexões entre ladrilhos, bem como conexões entre os cristais e a placa textolite do processador. A própria Intel fabrica o cristal do substrato usando a tecnologia de processo Intel 16 de 22 nm e, como todo o conjunto do processador, possui uma área de 302,9 mm2. Esse número é 20% maior que a área “ativa” do Arrow Lake, obtida pela soma das áreas dos ladrilhos funcionais. Isso se deve ao fato de dois blanks de silício também serem instalados na superfície do substrato de silício, complementando toda a estrutura ao formato retangular usual.

A montagem de um processador multichip em um substrato de silício usando a tecnologia Foveros é fundamentalmente diferente da abordagem de chiplet da AMD, quando os chips são instalados separadamente na placa de circuito impresso do processador e não são conectados em um único e quase monolítico paralelepípedo de silício. A tecnologia de empacotamento da Intel é mais interessante – permite conectar chips com um número significativamente maior de condutores. Como resultado, a empresa conseguiu organizar comunicações entre blocos com rendimento muito alto e, em teoria, eliminar todos os gargalos na transferência de dados entre nós funcionais do Arrow Lake localizados em chips diferentes.
Na verdade, o barramento FDI (Foveros Die Interconnect) que conecta blocos nas novas CPUs fornece uma taxa de transferência de mais de 500 GB/s graças à sua largura de 2.048 bits e operação a 2,1 GHz. Para efeito de comparação, o barramento Infinity Fabric, que a AMD usa para comunicar chips em seus processadores Ryzen, tem uma largura de banda radicalmente menor – 64 GB/s. E isso significa que, embora o Arrow Lake seja montado a partir de várias peças de silício diferentes, elas estão conectadas umas às outras de maneira muito firme e eficiente.
⇡#CPU Cristal
Todo o conjunto de núcleos Lion Cove e Skymont é montado em Arrow Lake em um chip semicondutor separado (bloco de computação), que também possui um cache de terceiro nível comum a todos eles. Não há mais unidades funcionais nele, mas não é isso que é interessante, mas o fato de a Intel ter misturado a localização dos núcleos P e E – eles não estão mais agrupados dentro do cristal em dois clusters.

Como explicação, a Intel fala sobre uma melhor distribuição de calor na superfície do silício. E isso faz certo sentido. Como o bloco de computação é fabricado na TSMC usando o processo N3B, mesmo com 24 núcleos, a área é de apenas 117,1 mm² – mais da metade da área do chip Raptor Lake. É realmente difícil remover o calor de uma matriz pequena, mas quente (a AMD não deixa você mentir), então a Intel tentou colocar áreas com alta geração de calor distantes umas das outras. A solução mais óbvia para este problema é espalhar núcleos P quentes ao redor do perímetro do cristal. Isso é exatamente o que vemos no layout.
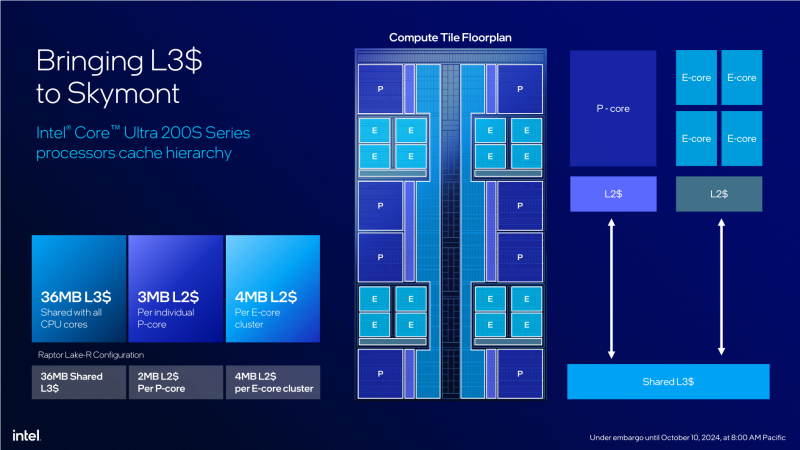
Essa distribuição tem outra vantagem não óbvia. Um cristal reduzido com a fórmula nuclear 6P+8E, usado nos processadores Core Ultra 5, pode ser facilmente obtido a partir da versão máxima do cristal simplesmente truncando alguma parte dele. Até o momento, a Intel não utilizou essa abordagem, mas é bem possível que, com a disseminação de modificações mais baratas do Arrow Lake, ela comece a ser usada.
É verdade que o desagrupamento dos núcleos P e E teve um efeito colateral inesperado – uma numeração incomum de núcleos. Por exemplo, no Core Ultra 9 285K, os núcleos produtivos são numerados 0, 1, 10, 11, 12, 13, 22 e 23. Isso significa que agora será muito mais difícil reconhecer núcleos produtivos e energeticamente eficientes em o monitoramento de desempenho no gerenciador de tarefas do Windows 11. Eu gostaria de esperar que, para evitar confusão, a Microsoft ainda descubra como dividir de alguma forma os núcleos por tipo.
O tamanho do L3-Kesha, permitido nas versões máximas do lago Arrow, atinge 36 Mb. Como antes, as partes deste cache são distribuídas por 3 multas por blocos na parada do pneu anel relacionado ao P-Yadra ou a grupos de quatro e-jader. Assim, não existem mais de 12 blocos Kesha do lago sênior de Arrow com uma fórmula de 8p+16e. Mb. E o núcleo Ultra 5 com seis P-nucleares e oito e-jader só podem contar com oito blocos de L3-Kesh com uma capacidade total de 24 MB.
Esse design de cache L3 o torna comparativamente lento em termos de latência, um problema que piora à medida que aumenta o número de núcleos conectados ao barramento em anel. No entanto, a Intel está combatendo isso aumentando o cache L2. Seu volume total para Core Ultra 9, por exemplo, chega a 40 MB, enquanto para Core Ultra 7 e Core Ultra 5 é de 36 e 26 MB, respectivamente. Assim, em Arrow Lake, a Intel chegou à conclusão de que o cache L2 ultrapassou o cache L3 em volume. Isso nunca aconteceu em processadores de gerações anteriores.
Você pode ver como a latência de todo o subsistema de memória cache Arrow Lake em conjunto pode ser vista no gráfico a seguir, que mostra os resultados do teste Memlat (em comparação com Raptor Lake).
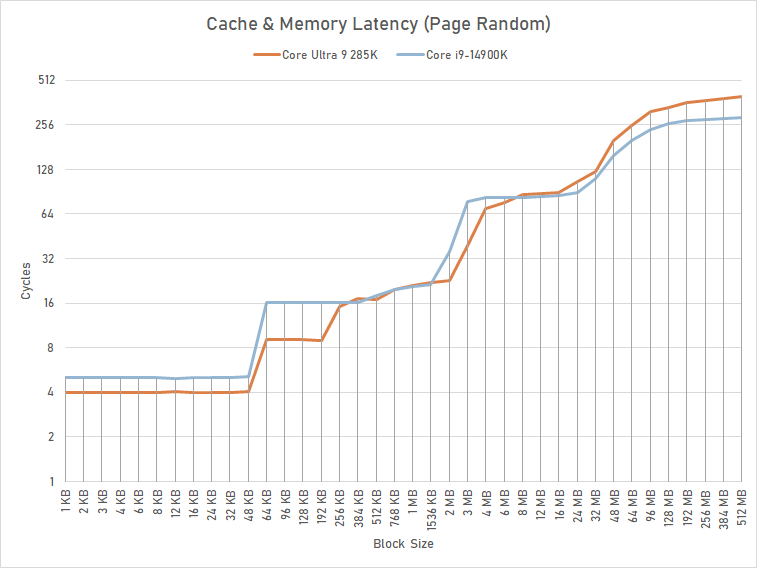
Ao adicionar um cache “um e meio” e aumentar o cache L2, a Intel realmente conseguiu que, ao trabalhar com quantidades relativamente pequenas de dados (até 8 MB), o Arrow Lake tivesse uma vantagem sobre o Raptor Lake em termos de velocidade na qual eles são processados nos núcleos. Porém, então as curvas relacionadas a esses processadores mudam de lugar, e o líder é o antigo Raptor Lake, cuja vantagem fica especialmente clara onde todos os tipos de caches se esgotam e os acessos são endereçados diretamente à memória. E esse fenômeno merece discussão detalhada.
⇡#SoC e trabalho de memória
O segundo cristal mais importante de Arrow Lake, que determina em grande parte suas características e características, é o SoC (system-on-chip). Ele é fabricado usando o processo técnico TSMC N6 e contém três componentes principais: um controlador de memória DDR5, um controlador de barramento PCI Express e um acelerador de rede neural.

Além disso, dentro do SoC existe um mecanismo de mídia relacionado ao núcleo gráfico integrado (que no Arrow Lake é implementado em um chip separado), bem como uma unidade responsável pelas interfaces de exibição. As últimas gerações de processadores móveis, por exemplo, Meteor Lake ou Arrow Lake-H, também contêm um par de núcleos LPE com eficiência energética na arquitetura Crestmont no SoC, mas os processadores de desktop não.
O controlador PCIe integrado ao Arrow Lake é notável pelo fato de suportar 24 pistas – quatro pistas a mais que o Raptor Lake. Isso permite conectar diretamente ao processador apenas uma placa de vídeo no modo PCIe x16, mas também duas unidades no modo PCIe x4. É verdade que uma das interfaces PCIe x4 para SSDs está limitada apenas à quarta versão do protocolo, mas 20 das 24 linhas disponíveis funcionam sem problemas com dispositivos PCIe 5.0.
Quanto ao coprocessador de rede neural de hardware NPU, ele foi adicionado ao SoC “apenas para ter”. Ele não pode assumir nenhum trabalho sério devido à sua produtividade relativamente baixa. Mas a Intel teve a oportunidade de marcar a caixa “otimizado para IA” nas especificações do Arrow Lake.

Este NPU é teoricamente limitado a 13 TOPS (trilhões de operações inteiras de oito bits por segundo) e é obtido inalterado do Meteor Lake. Esse desempenho não é suficiente para atender aos requisitos do Microsoft Copilot+ PC (40 TOPS), o que significa que Arrow Lake não será capaz de trabalhar com a maior parte das funções de IA do Windows 11 executadas localmente (principalmente Recall). Portanto, não é de surpreender que, ao falar sobre novos processadores para sistemas desktop, a Intel esteja tentando evitar o tópico NPU, especialmente porque o Lunar Lake móvel lançado anteriormente tem desempenho três vezes e meia maior do coprocessador AI. .
Mas o controlador de memória DDR5 localizado no SoC merece muito mais atenção, já que nele ocorreram mudanças bastante sérias. Nos novos processadores, a Intel elevou o padrão de frequência de memória e agora suas características incluem suporte até DDR5-6400. Ao mesmo tempo, o controlador de memória Arrow Lake perdeu a compatibilidade com versões anteriores do DDR4, que foi preservada por muito tempo nas últimas gerações de processadores Intel.

Ao mesmo tempo, uma nuance está associada ao suporte ao DDR5-6400. Com base em informações oficiais, esse modo requer conformidade com algumas condições adicionais. Em primeiro lugar, é formalmente possível apenas ao usar DIMM duas tábuas de classificação única no sistema. Em segundo lugar, seu desempenho é garantido exclusivamente com os módulos Cudimm, que estão equipados com seu próprio gerador de relógio, o que melhora a sincronização do sinal. O modo máximo garantido oficialmente, disponível para módulos UDIMM convencionais, permanece DDR5-5600, que também estava disponível em Raptor Lake.
No entanto, todos estes requisitos de memória definidos na especificação oficial não impedem a Intel de dizer que com Arrow Lake é melhor usar a memória mais rápida possível, por exemplo, DDR5-8000 (a Intel até a chama de “a melhor escolha para entusiastas” ). A compatibilidade com ele não é garantida pela especificação, mas como segue pelas explicações da empresa, os novos processadores receberam um controlador de memória significativamente mais estável em comparação com aquele equipado com Raptor Lake, e a maioria dos CPUs em placas-mãe de alta qualidade devem funcionar sem problemas com módulos DDR5 de alta velocidade, especialmente se esses módulos forem CUDIMM.
No entanto, como se viu na prática, o design do Arrow Lake é permitido um erro de cálculo irritante associado à colocação do controlador de memória precisamente no cristal SoC, e não junto com os núcleos do processador. A remoção física desse controlador de seus principais usuários (núcleos de computação) afetou o desempenho do subsistema de memória fortemente negativamente. Nos processadores das gerações passadas, o controlador de memória foi conectado ao pneu anel diretamente, o que tornou possível alcançar ao acessar a memória e a alta taxa de transferência e o baixo latente. Agora, nas rodovias entre os núcleos do processador e o controlador de memória, outro link adicional surgiu – o barramento de IDE, responsável pela conexão dos ladrilhos. E embora esse pneu tenha uma taxa de transferência gigantesca, o problema está em sua operação em sua própria frequência de 2,1 GHz, que não é sincronizada com a frequência do pneu de anel de 3,8 GHz. Esse assincronismo causa despesas gerais visíveis ao abordar a memória, que nos processadores das gerações passadas não eram em princípio.
Como resultado, Arrow Lake é visivelmente inferior aos processadores da geração anterior em termos de velocidade de processamento de memória. Vamos dar uma olhada, por exemplo, nos resultados da medição das métricas do subsistema de memória usando o Aida64 Cache & Memory Benchmark para o Core Ultra 9 285K e Core i9-14900K ao usar os mesmos módulos DDR5-6400 com temporizações de 32-39-39 -102.
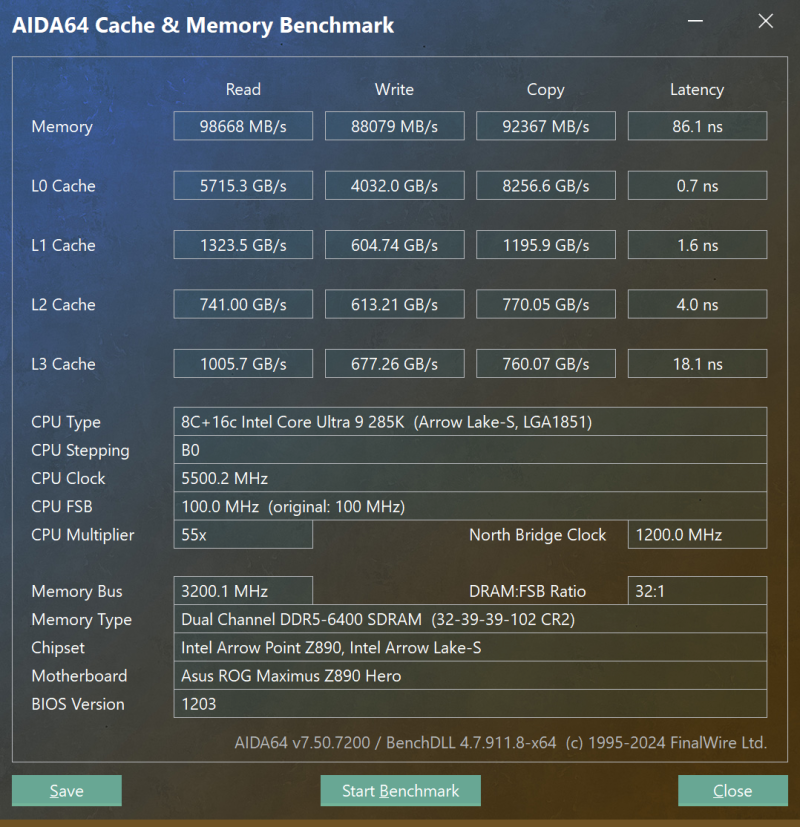
Núcleo Ultra 9 285K, DDR5-6400

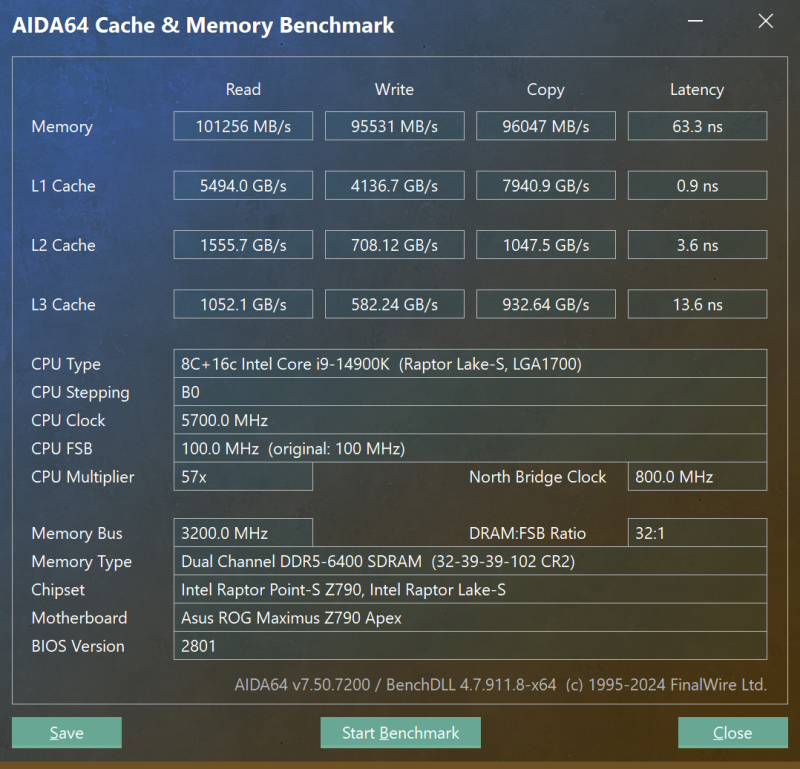
Núcleo i9-14900K, DDR5-6400
Em termos de largura de banda de memória, o Core Ultra 9 285K e o Core i9-14900K são quase iguais – o barramento FDI quase não tem efeito neste parâmetro devido à largura de banda suficiente. Mas a diferença na latência parece simplesmente catastrófica. A latência de Arrow Lake é mais de um terço maior e isso pode ser um problema sério em aplicativos sensíveis à memória, que incluem muitos jogos modernos.
Como consolo, só podemos dizer que a Intel já percebeu seu erro, e na próxima geração de processadores (em Panther Lake) vai primeiro devolver o controlador de memória ao mesmo chip com os núcleos de computação, e depois (em Nova Lake) tentará implementá-lo em um chip separado de uma nova maneira, evitando a dessincronização prejudicial dos pneus.
⇡#GPU integrada
A Intel geralmente não fornece aos seus processadores de desktop um núcleo gráfico poderoso, redistribuindo o orçamento do transistor em favor dos recursos de computação. Esta mesma abordagem continua em Arrow Lake. Os gráficos nele são feitos na forma de um cristal separado (ladrilho), produzido com a tecnologia TSMC N5P 5nm, e este é o menor cristal que faz parte do Lago Arrow.

Além disso, o núcleo gráfico de Arrow Lake é baseado na arquitetura relativamente antiga do alquimista, não no BattleMage, e contém apenas quatro núcleos XE-LPG (que oferecem 64 dispositivos executivos e 512 shaaders unificados). Assim, os gráficos integrados do Lago de Arrow da Desktop são inferiores em desempenho teórico, mesmo uma placa de vídeo discreta do arco A310 inicial. Além disso, a Intel removeu os blocos de tensores XMX da GPU -in construída. Mas, apesar de todas essas restrições, a Intel promete um aumento no desempenho em comparação com a versão antiga do núcleo gráfico dos processadores gráficos XE-LP Raptor Lake é mais da metade, além de suporte total para raios e escalonamento XESS, bem como a compatibilidade com DirectX 12 Ultimate.

No entanto, os gráficos de Arrow Lake dificilmente podem ser considerados seriamente por alguém como uma opção adequada para construir um PC para jogos. Pode ser interessante apenas em configurações de escritório que não enfrentam cargas de jogos. Em outras palavras, os usuários de sistemas baseados em processadores Intel que se preocupam com o desempenho gráfico devem, como antes, focar em placas de vídeo discretas completas.
Mas Arrow Lake recebeu um mecanismo de mídia muito bom. Ele suporta reprodução de vídeo acelerada por hardware em resoluções de até 8K a 60 Hz com cores de 10 bits e pode decodificar todos os formatos modernos, em particular VP9, AVC, HEVC, AV1 e SSC. A codificação acelerada por hardware é compatível com formatos VP9, AVC, HEVC e AV1 e resoluções de até 8K a 120 Hz com HDR de 10 bits. O núcleo gráfico também é capaz de enviar imagens para quatro monitores com resoluções de até 8K a 60 Hz, e os padrões de conexão suportados incluem HDMI 2.1, DisplayPort 2.1 e eDP 1.4.
⇡#Plataforma LGA1851 e chipset Intel Z890
Juntamente com os processadores de desktop Arrow Lake, foi lançada a nova plataforma LGA1851, na qual eles deveriam ser usados. Isso significa que para construir um sistema baseado no Core Ultra 200, será necessária uma nova placa-mãe. Até agora, todas essas placas-mãe são baseadas no chipset Intel Z890, mas isso mudará em um futuro próximo. Opções de lógica de sistema mais acessíveis na forma de B860 e H810 já foram apresentadas.

A Intel tem o hábito de trocar de soquete quando isso não é realmente necessário, mas a mudança do soquete LGA1700 para o novo soquete LGA1851 foi necessária devido a mudanças nas interfaces que o processador suporta. Além dos já familiares PCIe 5.0 x16 para gráficos e PCIe 4.0 x4 para SSDs, os novos processadores adicionam uma interface PCIe 5.0 x4 para os dispositivos de armazenamento mais modernos e de alta velocidade. Além disso, com a adição de um controlador Thunderbolt 4 integrado ao Arrow Lake, o processador agora pode ser conectado a duas portas correspondentes com uma taxa de transferência de até 40 Gbps. Tudo isso requer contatos adicionais do soquete do processador.
Ao mesmo tempo, o próprio soquete LGA1851 parece quase igual ao LGA1700. Os novos processadores mantêm as dimensões de 37,5 × 45 mm, como o Raptor Lake, então os coolers antigos são bastante adequados para sistemas desktop baseados em Arrow Lake – não há mudanças nem mesmo na localização dos orifícios de montagem nas placas-mãe. No entanto, se Arrow Lake e Raptor Lake forem colocados lado a lado, o aumento do número de almofadas de contato será claramente visível – elas ocupam a maior parte da barriga do processador.

Esquerda – Lago Arrow; à direita – Lago Raptor
A lógica do sistema do Z890 não difere muito dos chipsets anteriores. O chip do chipset, como antes, se comunica com o processador através do barramento DMI 4.0 x8 e contém seu próprio controlador PCIe com suporte para 24 pistas. No entanto, essas próprias linhas agora operam em um modo de velocidade diferente – todas elas atendem ao padrão PCIe 4.0 e não há mais linhas limitadas ao modo PCIe 3.0.

O controlador USB integrado do Z890 suporta até 32 “vias” USB com largura de banda de 5 Gbps cada. Eles podem ser combinados em diferentes conjuntos, resultando em portas USB 3.2 Gen 1 simples (5 Gbps), USB 3.2 Gen 2 de alta velocidade (10 Gbps) ou até mesmo portas USB 3.2 Gen 2×2 (20 Gbps). Pode haver até 10 portas do primeiro e segundo tipos em sistemas baseados no Z890 e até cinco do USB 3.2 Gen 2×2 mais rápido. Além disso, o Z890 ainda suporta 14 portas USB 2.0 lentas e 8 portas SATA.
É bastante curioso que, tendo mantido algumas interfaces antigas, a Intel tenha decidido se desfazer de outras. A interface de áudio HD, codinome Azalia, passou pela faca no Z890. Isso significa que os fabricantes de placas-mãe não poderão mais usar codecs como ALC892 e ALC1200 e irão cada vez mais migrar para soluções mais modernas com conexões USB ou I2S/I2C.
Ao mesmo tempo, o Z890 ainda oferece suporte a redes gigabit e Wi-Fi 6, mas a Intel não recomenda o uso desses recursos integrados. Segundo a empresa, as placas LGA1851 deverão ser equipadas com controladores de rede externos mais rápidos, com velocidade de pelo menos 2,5 Gbps over the wire e com suporte ao padrão wireless Wi-Fi 7.
Quanto aos chipsets mais acessíveis, tradicionalmente, em comparação com o Z870, eles oferecem capacidades significativamente truncadas. O popular B860 limita o overclock da CPU e permite que apenas um SSD seja conectado ao processador. Além disso, o número de pistas PCIe 4.0 suportadas é limitado a 14, e o número total de portas USB 3.2 (qualquer variante) é limitado a seis.
O orçamento H610 é ainda mais rápido. Não permitirá que você faça overclock não apenas do processador, mas também da memória. As placas permanecerão sem slots M.2 conectados ao processador e não poderão receber mais do que dois slots DIMM. O número máximo de pistas PCIe 4.0 suportadas foi reduzido para oito e o número de portas USB 3.2 foi reduzido para quatro.
⇡#Novo carro-chefe: Core Ultra 9 285K
Antes de passarmos aos resultados de testes extensos, vamos dar uma olhada em seu personagem principal – o Core Ultra 9 285K.

Este é o principal representante da família de desktops Arrow Lake, que se tornou o sucessor ideológico do Core i9-14900K. Seu novo nome não deve confundir: se a Intel não tivesse decidido redesenhar todo o sistema de nomenclatura de seus processadores, o Core Ultra 9 285K provavelmente teria se chamado Core i9-15900K e nada mais. Ou seja, trata-se de um processador completamente familiar para desktops, focado em jogos e no trabalho do dia a dia, como criação ou edição de conteúdo digital.
As principais especificações do Core Ultra 9 285K já foram fornecidas acima: 8 núcleos produtivos e 16 núcleos com eficiência energética, a frequência máxima do primeiro é 5,7 GHz, a segunda é 4,6 GHz. Esses números por si só não são tão interessantes, mas se forem comparados com as características do Core i9-14900K, surge uma imagem bastante interessante.
O novo carro-chefe perdeu o P-Jader em frequência, mas supera o antecessor na frequência do E-Jader, que no novo processador reivindica um papel muito mais sério. Ao mesmo tempo, devido à falta de apoio à hiper-fibra, o novo núcleo Ultra 9 285K é inferior aos carros-chefe das gerações passadas no número máximo de fluxos realizados. De acordo com essa característica, ele rolou mais perto do nível do núcleo i7-14700K e Ryzen 9 9900X, mas não se esqueça de que núcleos completamente diferentes são usados em Arrow Lake.
Além disso, a dependência da frequência na carga do Core Ultra 9 285K parece um pouco diferente quando comparado com o Core i9-14900K. Medições da frequência realmente observada ao renderizar no Cinebench R23 com limite no número de threads executados nos permitem obter o seguinte gráfico.
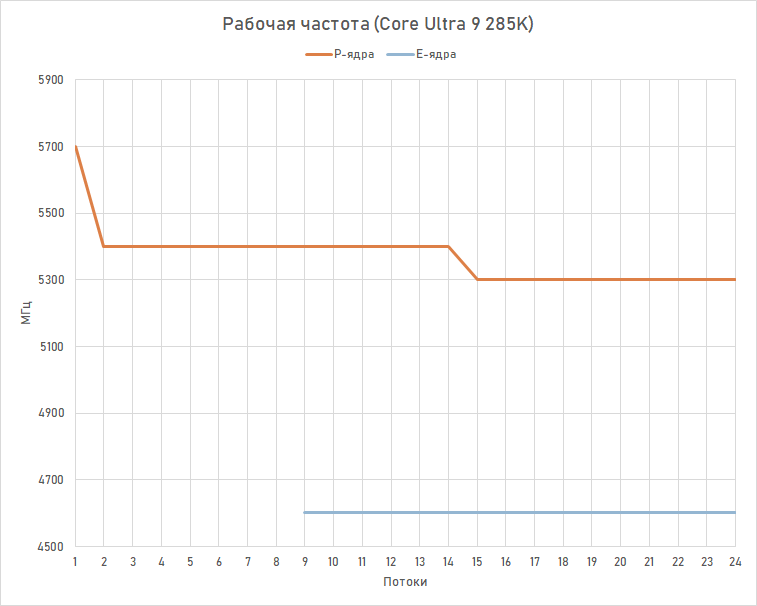
Não há dependências complexas aqui. Os núcleos P do novo produto quase sempre operam na frequência de 5,3-5,4 GHz, e o processador atinge no máximo 5,7 GHz apenas no caso de carga de thread único. Ao mesmo tempo, os E-cores mantêm sempre o máximo de 4,6 GHz, independente da quantidade deles envolvidos no trabalho. Isso significa que sob cargas de trabalho multithread intensivas, o Core Ultra 9 285K acaba tendo uma freqüência maior que o Core i9-14900K. E isso se deve em parte à eficiência energética muito melhor do antigo Arrow Lake, que, mesmo com uma carga intensiva de recursos em todos os núcleos, cabe no orçamento de 250 W alocado para ele, consumindo cerca de 225-230 W.
Outra característica do novo produto é o grande volume total de memória cache de segundo nível. De acordo com esta característica, supera todos os CPUs x86 que existiam até então. No entanto, em termos de tamanho total de cache, o Core Ultra 9 285K ainda perde, e significativamente, para os processadores Ryzen concorrentes com cache 3D.
O preço oficial do antigo Arrow Lake é o tradicional US$ 589 – o mesmo preço recebido pelos carros-chefe da Intel das gerações anteriores. No entanto, existem duas advertências. Primeiro, o Core Ultra 9 285K não tem a opção com gráficos integrados desabilitados, que existia antes e era oferecida por US$ 25 a menos. Na geração atual de CPU-KF, as modificações permanecem apenas na forma de Core Ultra 7 265KF e Core Ultra 5 245KF. Em segundo lugar, após o escândalo de degradação, o preço do Core i9-14900K caiu significativamente e agora é impossível dizer que o novo carro-chefe custa quase o mesmo que o seu antecessor. O preço real de varejo do antigo Raptor Lake está agora em torno de US$ 435, então, na verdade, o Core Ultra 9 285K custará pelo menos um terço a mais do que um processador da mesma classe da geração anterior.
⇡#Consumo de energia e temperaturas
A Intel destaca particularmente o progresso da Arrow Lake em eficiência energética em comparação com seus antecessores. E de acordo com todas as estimativas preliminares, os novos processadores deveriam de fato consumir significativamente menos energia, tanto devido à transição para processos técnicos mais finos, quanto devido a mudanças arquitetônicas e à desativação do Hyper-Threading. E isso é fácil de ver nos resultados dos testes.
Para avaliar o consumo do Core Ultra 9 285K em uma carga com uso intensivo de recursos, tradicionalmente usamos o teste multithread Cinebench 2024. E nele o carro-chefe Arrow Lake realmente se comporta de maneira completamente diferente de seu antecessor – é realmente mais econômico. Enquanto o consumo do Core i9-14900K atinge o limite de 253W, o Core Ultra 9 285K não atinge seu limite. Seu consumo sob carga em todos os 24 núcleos é de 225 W.
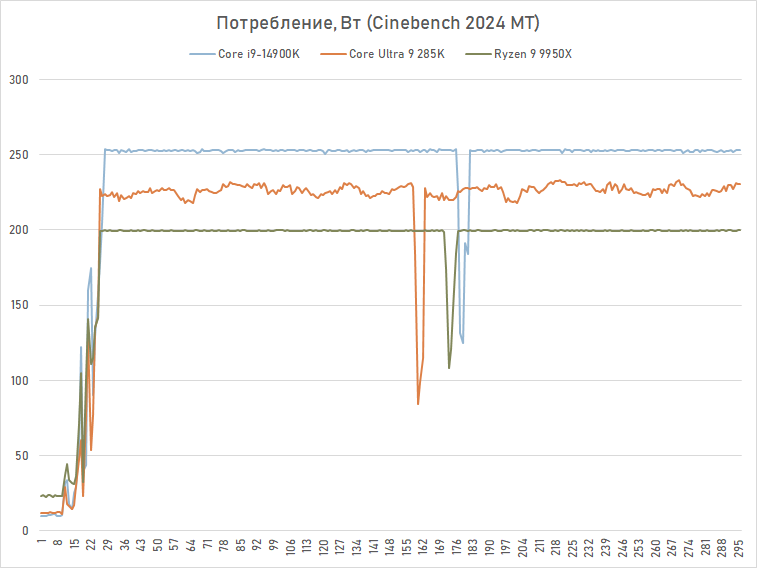
No entanto, isso não afeta particularmente o regime de temperatura. Ambos os processadores aquecem até cerca de 80 graus. No entanto, na realidade, este é um sinal positivo. A experiência da AMD mostrou que ao mudar para processos técnicos mais finos e reduzir a área da matriz com núcleos de processador, fica cada vez mais difícil remover o calor. Mas a Intel não tem esses problemas. O chip do processador Arrow Lake, produzido usando uma tecnologia de processo de 3 nm, é resfriado o suficiente: aparentemente, ajuda o fato de ser cerca de uma vez e meia maior que o chip do processador Zen 4 e Zen 5.
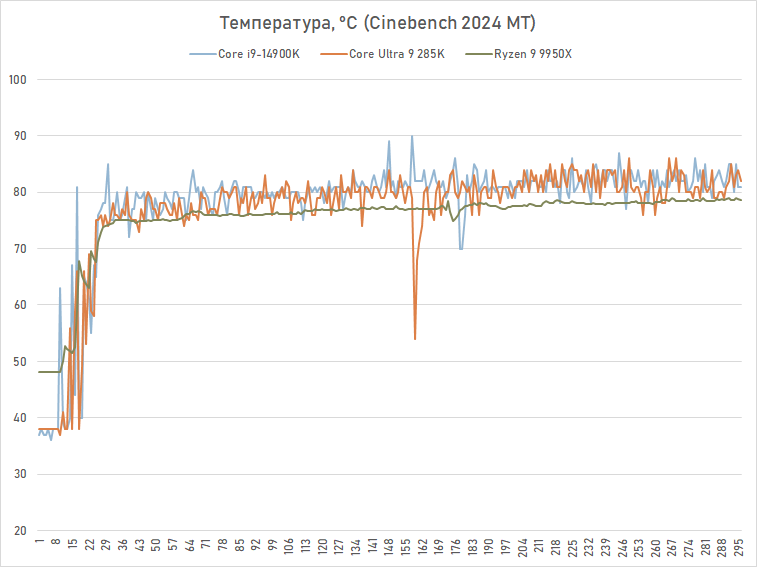
Parecia um sintoma bastante assustador o fato de a Intel ter aumentado a temperatura máxima permitida para o Core Ultra 9 285K para 105 graus. Mas, na verdade, isso não foi feito sob pressão das circunstâncias – o novo processador Intel não esquenta mais do que seus antecessores, mesmo sob pesadas cargas multithread.
Um quadro ainda mais inesperado pode ser visto ao medir o consumo em uma carga single-threaded no Cinebench 2024. Aqui, o Core Ultra 9 285K consome literalmente metade de seu antecessor, exigindo apenas 35 W de potência para renderização com um único P- essencial. Isso, naturalmente, se reflete na temperatura: ela é limitada a 62 graus, enquanto o Core i9-14900K fica cerca de 10 graus mais quente nas mesmas condições.
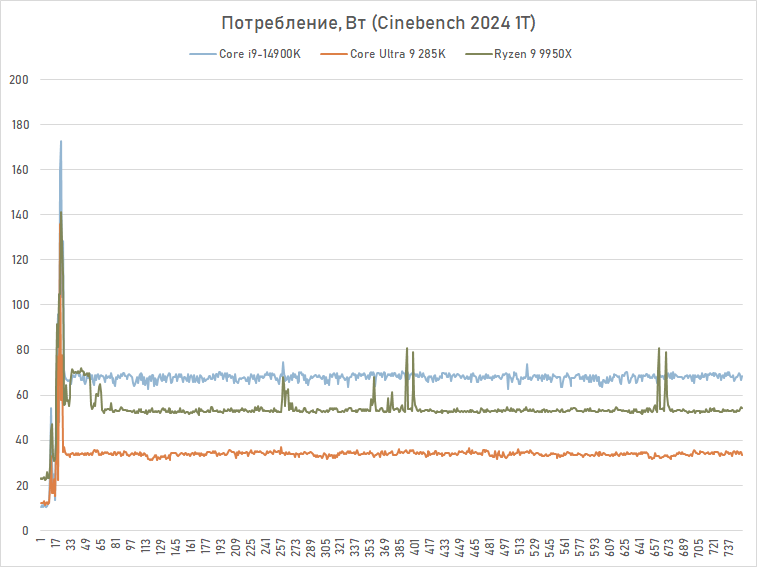
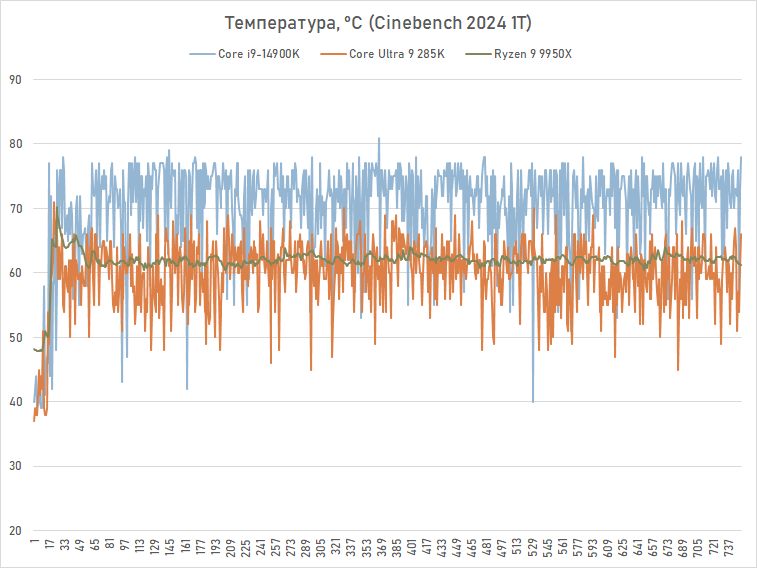
Assim, a eficiência do Core Ultra 9 285K é melhor sob cargas de trabalho de baixa intensidade, o que é uma ótima notícia para os jogadores. Os jogos, via de regra, são o tipo de aplicação que não utiliza todos os recursos disponíveis do processador, graças aos quais Arrow Lake mostra toda a sua eficiência energética.
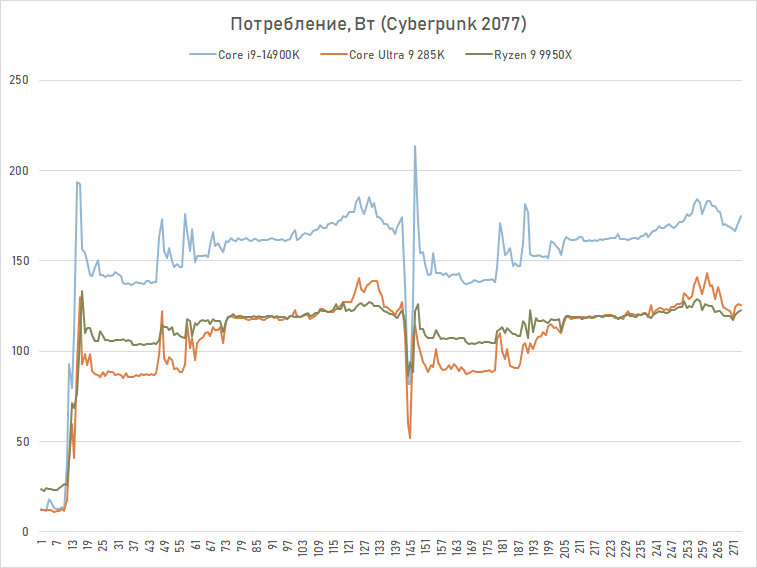
Por exemplo, o consumo médio do Core Ultra 9 285K no Cyberpunk 2077 é de cerca de 110-120 W, enquanto o Core i9-14900K requer cerca de 160 W de eletricidade para operar nas mesmas condições. Claro, isso ainda é visivelmente maior do que o consumo do Ryzen 7 9800X3D, mas o Core Ultra 9 285K é bastante comparável ao Ryzen 9 9950X em termos de consumo de energia para jogos.
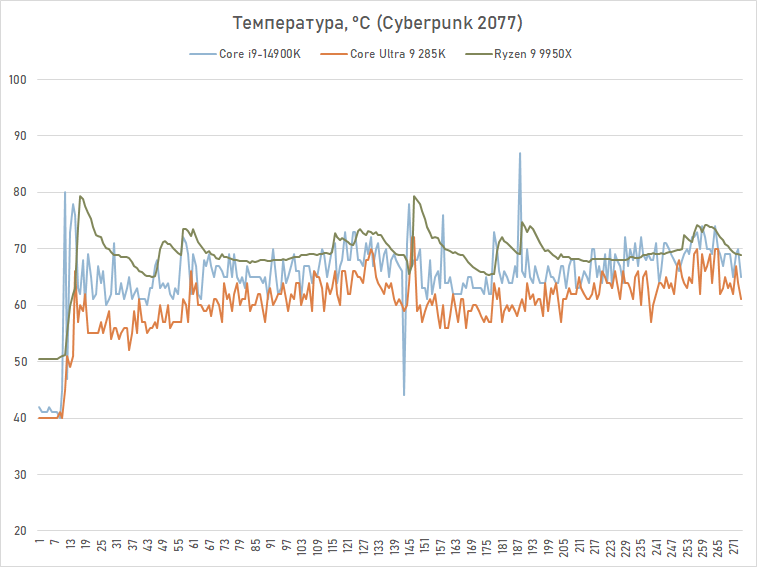
A temperatura do carro-chefe Arrow Lake é visivelmente mais baixa do que seu antecessor. No Cyberpunk 2077, ele oscila em torno de 62 graus, o que é até alguns graus mais baixo do que a temperatura que medimos no Ryzen 7 9800X3D no mesmo teste. Já o Core i9-14900K aquece até uma temperatura de cerca de 68 graus.
Em outro jogo, Horizon Zero Dawn Remastered, a relativa eficiência energética do Core Ultra 9 285K sob carga de jogo é totalmente confirmada. O consumo médio deste processador é de 110 W, enquanto o Core i9-14900K requer cerca de 145 W para funcionar. Para efeito de comparação, o consumo do Ryzen 7 9800X3D no mesmo jogo é de 95 W, e do Ryzen 9 9950X é de 135 W.
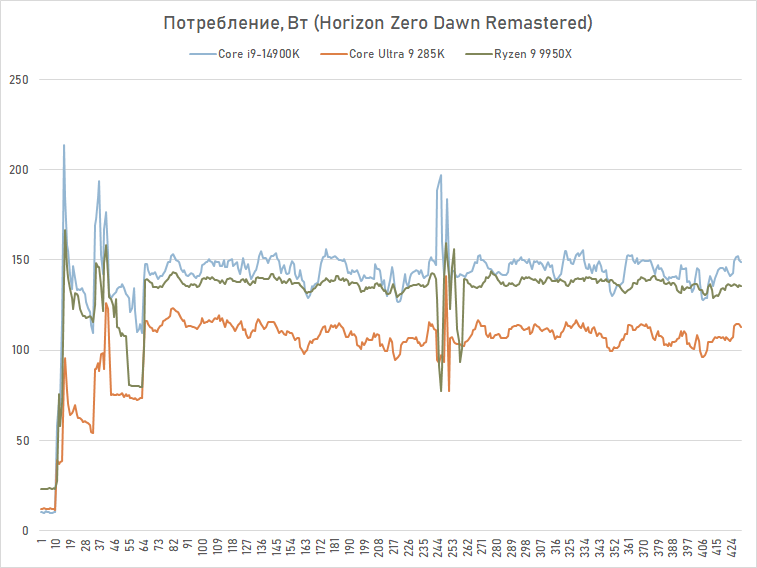
A temperatura do Core Ultra 9 285K é novamente baixa, mas neste caso não há separação significativa em termos de aquecimento de outros processadores. Temperaturas de cerca de 60 graus em jogos são típicas de CPUs modernas, desde que seja usado um sistema de resfriamento suficientemente eficiente. Apenas os Ryzens mais antigos se destacam nesse quadro, principalmente os Zen 4 gerações, que conseguem esquentar muito mais.
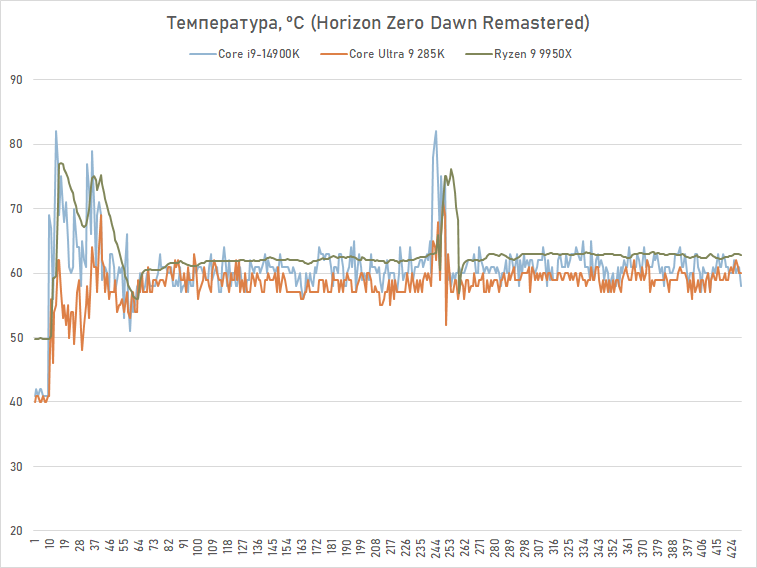
Ou seja, com a nova geração de processadores, a Intel realmente conteve o consumo, que tem sido alvo de sérias críticas nos últimos anos. Como pode ser concluído a partir dos resultados dos testes, em média, o apetite energético do Lago Arrow em comparação com o Lago Raptor diminuiu cerca de um quarto. Assim, o carro-chefe Core Ultra 9 285K tornou-se mais econômico não apenas em comparação com o Core i9-13900K e Core i9-14900K, mas até mesmo em comparação com o concorrente Ryzen 9 9950X.
⇡#Descrição do sistema de teste e metodologia de teste
Core Ultra 9 285K é o novo processador de desktop carro-chefe da Intel, por isso é lógico compará-lo com processadores de posicionamento semelhante. Porém, além do Core i9-14900K e Ryzen 9 9950X, incluímos mais dois CPUs AMD entre os participantes do teste. Em primeiro lugar, o Ryzen 7 9800X3D, que, embora não seja um carro-chefe, é um líder inatingível em desempenho em jogos graças à presença de um cache 3D. E em segundo lugar, o processador Ryzen 9 7950X3D de 16 núcleos com cache 3D, que pertence à geração anterior, que ainda não possui um sucessor completo na série Ryzen 9000.
Como resultado, a lista completa de componentes envolvidos é semelhante a esta:
-
- AMD Ryzen 9 9950X (Granite Ridge, 16 núcleos, 4,3-5,7 GHz, 64 MB L3);
- AMD Ryzen 9 7950X3D (Raphael, 16 núcleos, 4,2-5,7 GHz, 128 MB L3);
- AMD Ryzen 7 9800X3D (Granite Ridge, 8 núcleos, 4,7-5,2 GHz, 96 MB L3);
- Intel Core Ultra 9 285K (Arrow Lake, núcleos 8P+16E, 3,7-5,7/3,2-4,6 GHz, 36 MB L3);
- Intel Core i9-14900K (Raptor Lake Refresh, núcleos 8P + 16E, 3,2-6,0/2,4-4,4 GHz, 36 MB L3).
- Cooler do processador: cooler líquido personalizado feito de componentes EKWB.
-
- Herói ASUS ROG Maximus Z890 (LGA1851, Intel Z890);
- ASUS ROG Maximus Z790 Apex (LGA1700, Intel Z790);
- MSI MPG X670E Carbon WiFi (soquete AM5, AMD X670E).
- Memória: 2 × 16 GB DDR5-6400 SDRAM (G.Skill Ripjaws S5 F5-6400J3239G16GX2-RS5K).
- Placa de vídeo: GIGABYTE GeForce RTX 4090 Gaming OC (AD102 2235/2535MHz, 24GB GDDR6X 21Gb/s)
- Subsistema de disco: Intel SSD 760p 2 TB (SSDPEKKW020T8X1).
- Fonte de alimentação: ASUS ROG-THOR-1200P (80 Plus Titanium, 1200 W).
Os subsistemas de memória nas plataformas Intel foram configurados usando o perfil XMP do conjunto de módulos selecionado – DDR5-6400 com temporizações 32-39-39-102. Na plataforma Socket AM5, devido à incapacidade dos processadores Ryzen com DDR5-6400 de trabalhar em modo síncrono, um perfil alternativo DDR5-6000 com temporizações de 30-38-38-96 foi selecionado para memória.
Os testes foram realizados no sistema operacional Microsoft Windows 11 Pro (24H2) Build 26100.2605, que inclui todas as atualizações necessárias para o correto funcionamento dos agendadores nos modernos processadores AMD e Intel. Para melhorar ainda mais o desempenho, desativamos a “Segurança baseada em virtualização” nas configurações do Windows e ativamos o “Agendamento de GPU acelerado por hardware”. O sistema usou o driver gráfico mais recente GeForce 566.36 Driver.
Também é necessário ressaltar que o BIOS da plataforma Core i9-14900K foi atualizado para uma versão com microcódigo Intel 0x12B, o que finalmente elimina a degradação do processador associada ao fornecimento de tensões excessivas. E o BIOS da plataforma Core Ultra 9 285K foi atualizado para a versão com microcódigo Intel 0x114, o que deve aumentar o desempenho em jogos dos processadores da família Arrow Lake. Além disso, ambas as plataformas usaram o perfil de configurações padrão da Intel, que substitui as “otimizações” introduzidas pelos fabricantes de placas-mãe por iniciativa própria.
Descrição das ferramentas usadas para medir o desempenho da computação:
Benchmarks sintéticos:
- 3DMark Professional Edition 2.29.8256 – teste no cenário CPU Profile 1.1 nos modos single-threaded e multi-threaded.
- Cinebench 2024 – mede o desempenho da CPU single-threaded e multi-threaded ao renderizar no Cinema 4D usando o mecanismo Redshift.
- O Geekbench 6.3.0 mede o desempenho da CPU de thread único e multithread em cenários comuns de usuário, desde a leitura de e-mail até o processamento de imagens.
Testes de aplicação:
- 7-zip 24.08 – testando a velocidade de compactação e descompactação. É usado um benchmark integrado com um tamanho de dicionário de até 64 MB.
- Adobe Photoshop 2024 11.25.0 – testando o desempenho ao processar imagens gráficas. É utilizado o script de teste PugetBench para Photoshop 1.0.1, simulando operações básicas e trabalhando com filtros Camera Raw, Correção de lente, Reduzir ruído, Nitidez inteligente, Desfoque de campo, Desfoque Tilt-Shift, Desfoque de íris, Grande angular adaptativo, Dissolver.
- Adobe Photoshop Lightroom Classic 13.4 – testando o desempenho ao processar em lote uma série de imagens no formato RAW. É utilizado o script de teste PugetBench for Lightroom Classic V0.96, simulando trabalho básico com biblioteca e edição, bem como importação/exportação, Smart Preview, criação de panoramas e imagens HDR.
- Adobe Premiere Pro 2024 24.5.0 – testando o desempenho da edição de vídeo. É utilizado o script de teste PugetBench for Premiere Pro 1.1.0, que simula a edição de vídeos 4K em diversos formatos, aplicação de diversos efeitos neles e a renderização final para YouTube.
- Blender 4.2.0 – testando a velocidade de renderização final na CPU. O Benchmark padrão do Blender é usado.
- Corona 10 – testando a velocidade de renderização final na CPU. O padrão Corona Benchmark é usado.
- DaVinci Resolve Studio 19.0 – avaliação do desempenho do processamento de vídeo ao codificar com vários codecs, processar arquivos de origem e aplicar efeitos. O script de teste PugetBench para DaVinci Resolve 1.0 é usado.
- CPU FastSD – medindo a velocidade de geração rápida de imagens AI em Stable Diffusion 1.5 no modo LCM-LoRA na CPU. Uma imagem com resolução de 1024×1024 é criada em cinco iterações.
- Microsoft Visual Studio 2022 (17.13.3) – medindo o tempo de compilação de um grande projeto MSVC – Blender versão 4.2.0.
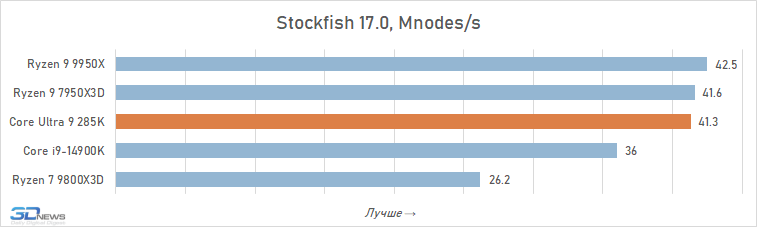
- Stockfish 17.0 – testando a velocidade do popular mecanismo de xadrez. É utilizado um benchmark padrão com uma profundidade de análise de 28 meios-movimentos.
- SVT-AV1 2.1.0 – testando a velocidade de transcodificação de vídeo para o formato AV1. O vídeo original 4K@24FPS é usado com cores de 10 bits e taxa de bits de 51 Mbps.
- Topaz Video AI v5.3.0 – testa o desempenho ao melhorar a qualidade do vídeo usando algoritmos de IA executados na CPU. O vídeo original 640×360@30FPS é aumentado usando o modelo Proteus para uma resolução de 1280×720, e o FPS é aumentado para 60 usando o modelo Chronos Fast.
- X264 164 r3186 – testando a velocidade de transcodificação de vídeo no formato H.264/AVC. O vídeo original 4K@24FPS é usado com cores de 10 bits e taxa de bits de 51 Mbps.
- X265 3.6 – testando a velocidade de transcodificação de vídeo no formato H.265/HEVC. O vídeo original 4K@24FPS é usado com cores de 10 bits e taxa de bits de 51 Mbps.
- V-Ray 6.00.01 – testando a velocidade da renderização final na CPU. Usa o padrão V-Ray 5 Benchmark.
Jogos:
- Assassin’s Creed Mirage. Configurações gráficas: Qualidade gráfica = Muito alta.
- Baldur’s Gate 3. Configurações gráficas: Vulcan, Predefinição geral = Ultra.
- Cidades: Skylines II. Gráficos principais: Qualidade gráfica global = Alta, Qualidade de anti-aliasing = Baixa SMAA, Configurações de qualidade volumétrica = Desativada, Qualidade de profundidade de campo = Desativada, Nível de detalhe = Baixo.
- Cyberpunk 2077 2.01. Configurações gráficas: Quick Preset = RayTracing: Médio.
- Dying Light 2 Permaneça Humano. Configurações gráficas: Qualidade = Raytracing de alta qualidade.
- Hitman 3. Gráficos personalizados: Super Sampling = 1.0, Nível de detalhe = Ultra, Qualidade de textura = Alta, Filtro de textura = Anisotrópico 16x, SSAO = Ultra, Qualidade de sombra = Ultra, Qualidade de reflexão de espelhos = Alta, Qualidade SSR = Alta, Taxa variável Sombreamento = Qualidade.
- Legado de Hogwarts. Configurações gráficas: Predefinição de qualidade global = Ultra, Qualidade de traçado de raio = Baixa, Modo anti-aliasing = TAA alto.
- Horizon Zero Dawn Remasterizado. Configurações gráficas: Preset = Very High, Anti-Aliasing = TAA, Upscale Method = Off.
- Homem-Aranha da Marvel remasterizado. Gráficos padrão: Predefinição = Muito alto, Reflexão Ray-Tracing = Ligado, Resolução de reflexão = Muito alta, Detalhe de geometria = Muito alto, Alcance do objeto = 10, Anti-Aliasing = TAA.
- Montagem e montagem Lâmina II: Senhor da Bandeira. Configurações gráficas: Predefinição geral = Muito alta.
- Sombra do Tomb Raider. Configurações gráficas: DirectX12, Preset = Mais alto, Anti-Aliasing = TAA, Ray Traced Shadow Quality = Ultra.
- Campo Estelar. Configurações gráficas: Predefinição de gráficos = Ultra, Upscaling = Desligado.
- O Quebra-Fendas. Gráficos padrão: DirectX12, Qualidade de textura = Alta, Sombras suaves com Raytraced = Ativado, Qualidade de sombra com Ray Tracing = Ultra, Oclusão de ambiente com Raytraced = Ativado.
- The Witcher 3: Caça Selvagem 4.04. Configurações gráficas: Predefinição gráfica = RT Ultra.
Em todos os testes de jogos, o número médio de quadros por segundo, bem como 0,01-quantil (primeiro percentil) para valores de FPS são dados como resultados. O uso de 0,01-quantil em vez do FPS mínimo deve-se ao desejo de esclarecer os resultados de rajadas aleatórias de desempenho provocadas por razões não diretamente relacionadas à operação dos principais componentes da plataforma.
⇡#Desempenho em benchmarks sintéticos
Se julgarmos as capacidades do Core Ultra 9 285K apenas por testes sintéticos, a impressão da novidade é muito positiva. Neste estudo, usamos Geekbench 6, 3DMark CPU Profile e Cinebench 2024, e dois dos três benchmarks relatam a superioridade do carro-chefe Arrow Lake sobre Raptor Lake e Ryzen 9000 em desempenho de thread único (isso é graças ao novo Lion Cove arquitetura).
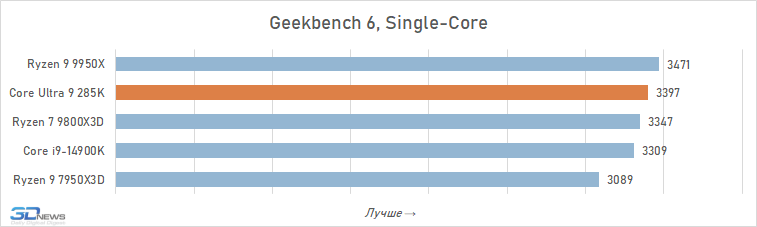

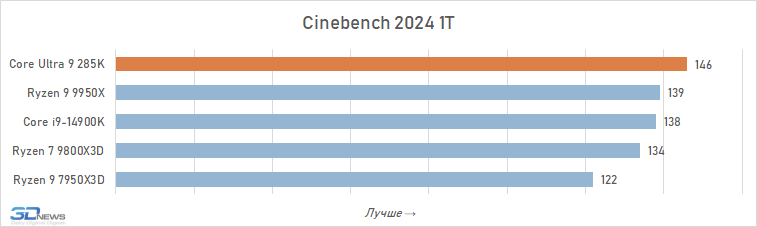
E ao avaliar o desempenho multithread, todos os três testes concordam que o Core Ultra 9 285K é visivelmente mais rápido que o Core i9-14900K e o Ryzen 9 9950X. A vantagem média do novo produto sobre seu antecessor é de 11% e sobre o representante mais antigo da família Ryzen 9000 – 9%.

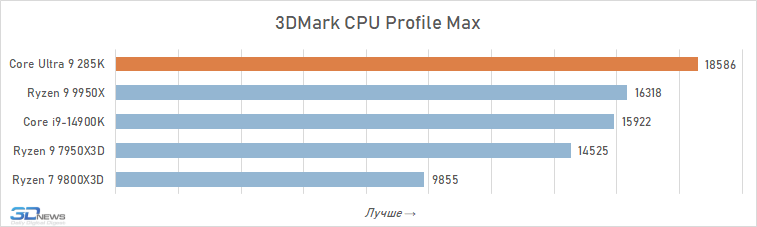
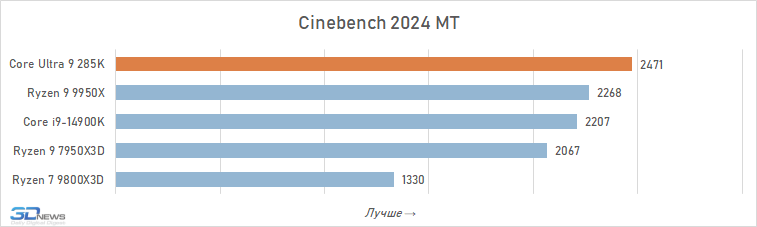
O problema é que essa avaliação preliminar do desempenho do Core Ultra 9 285K usando benchmarks sintéticos é quase a única seção de todos os testes onde o novo produto da Intel pode realmente ser elogiado.
⇡#Desempenho em aplicativos exigentes
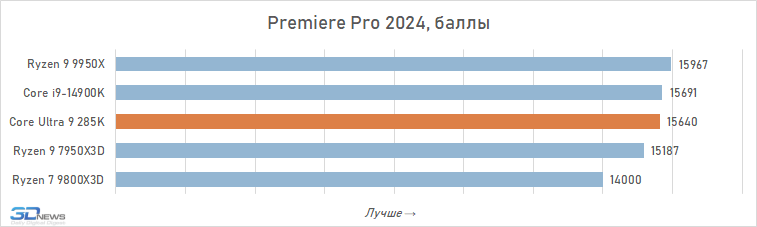
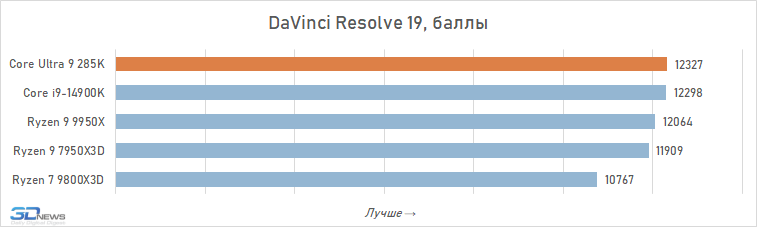
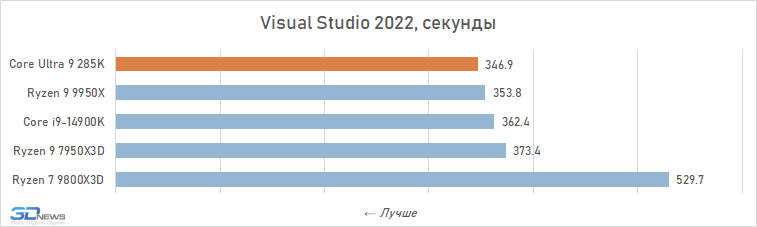
Muitas das análises do Core Ultra 9 285K publicadas por outras publicações sugerem que este processador pode ser adequado para sistemas de trabalho. No entanto, nossos testes aprofundados mostram que tal conclusão é um grande exagero. Sim, é em média mais rápido que o Core i9-14900K em aplicativos que consomem muitos recursos. A vantagem é de cerca de 6% e, em algumas situações, por exemplo, ao trabalhar com algoritmos de IA, pode chegar a 30-40%. Mas, apesar disso, a Intel não conseguiu fabricar um processador capaz de competir em igualdade de condições em aplicações de trabalho com o Ryzen 9 9950X: o produto de 16 núcleos da AMD supera o produto de 24 núcleos da Intel em 12 dos 16 testes, à frente por uma média de 5. %.
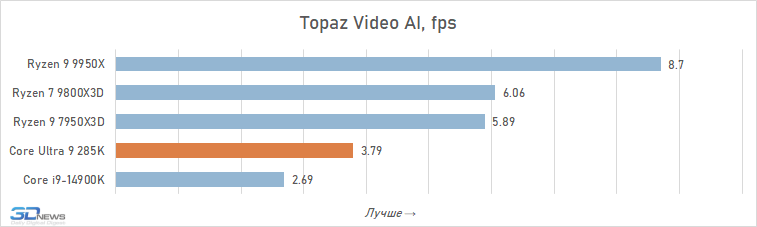
Ao mesmo tempo, o Core Ultra 9 285K tem pontos fracos óbvios. Em primeiro lugar, este processador não suporta instruções AVX-512, o que leva ao seu atraso catastrófico em relação ao Ryzen 9 9950X em aplicações que as utilizam ativamente (Topaz Video AI). Em segundo lugar, o Core Ultra 9 285K tem um desempenho ruim onde é necessário um trabalho rápido com memória (Photoshop, 7-zip).
Na verdade, o desempenho do aplicativo do Core Ultra 9 285K está próximo do desempenho do Ryzen 9 7950X3D, baseado na arquitetura Zen 4 anterior. É provável que, se a Intel não tivesse desabilitado o suporte Hyper-Threading nos desktops Arrow Lake, o. condicional Core Ultra 9 285K teria a chance de competir com o carro-chefe da geração Ryzen Zen 5 em aplicativos para criação e processamento de conteúdo, mas agora seus 24 threads estão perdendo 32 fios Ryzen 9 9950X. No entanto, habilitar o Hyper-Threading levaria invariavelmente a um aumento no apetite por energia, e agora o Core Ultra 9 285K conseguiu se aproximar do Ryzen 9 9950X em termos de consumo de energia.
Renderização:
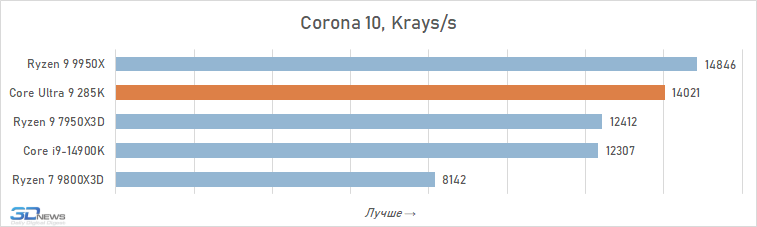
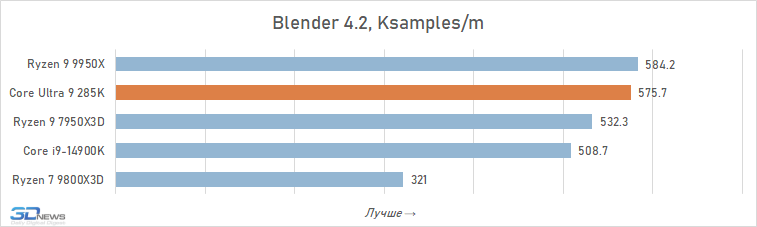
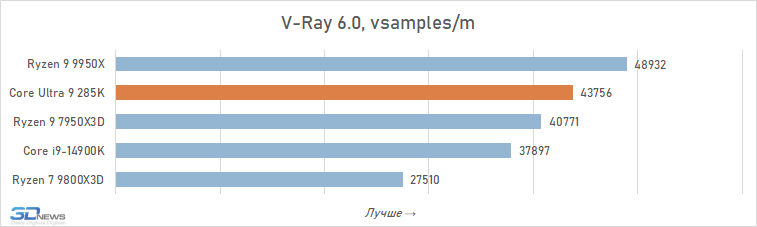
Transcodificação de vídeo:
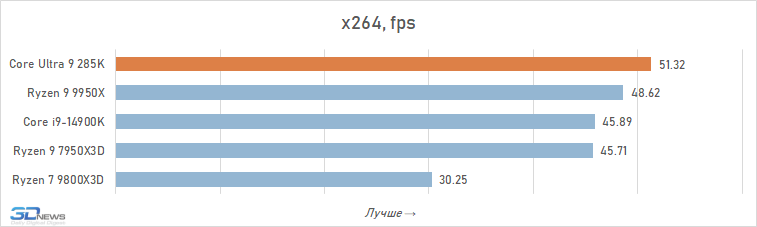
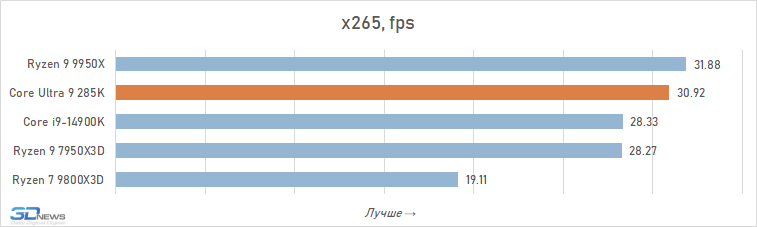
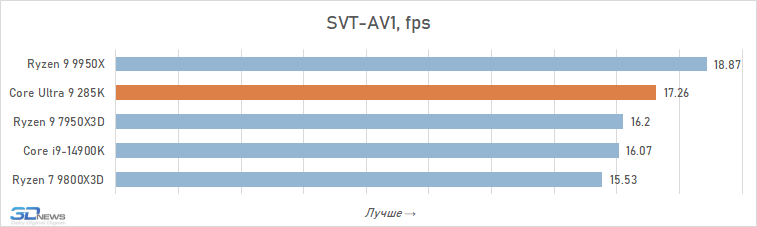
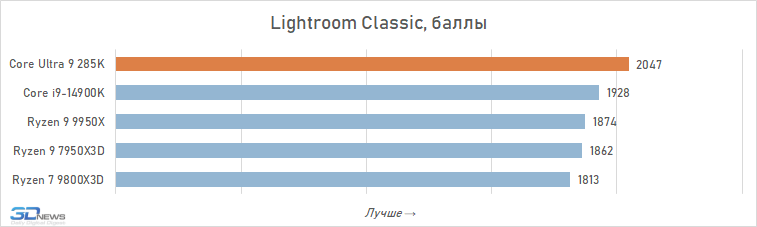
Processamento de fotos:

Trabalhar com vídeo:
Redes Neurais:

Compilação:
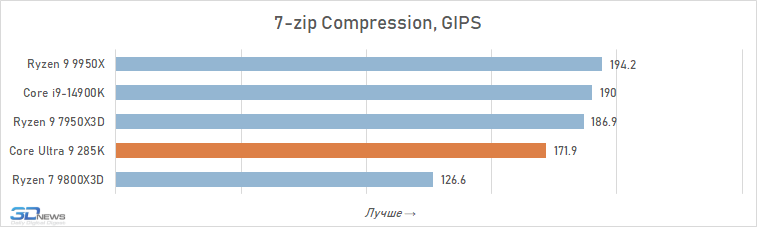
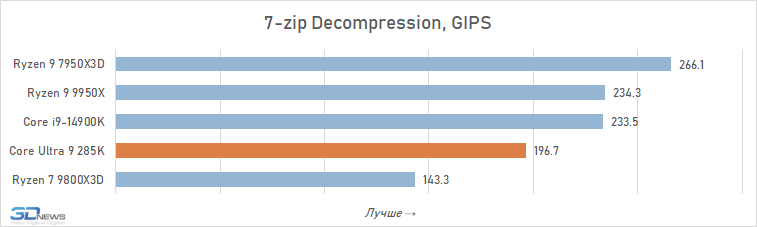
Arquivamento:
Xadrez:
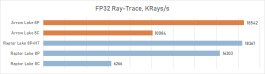
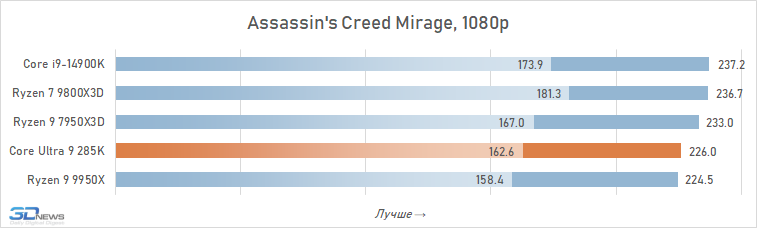
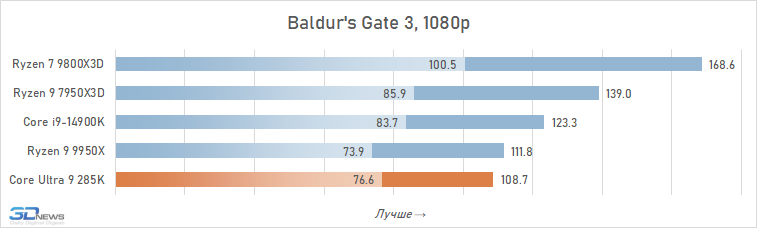
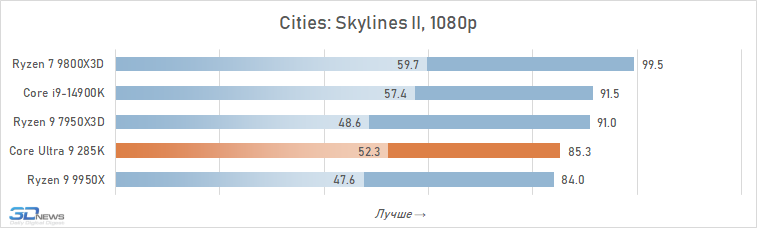
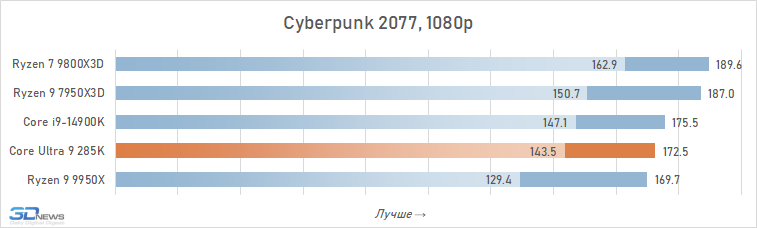
⇡#Desempenho de jogo. Testes 1080p
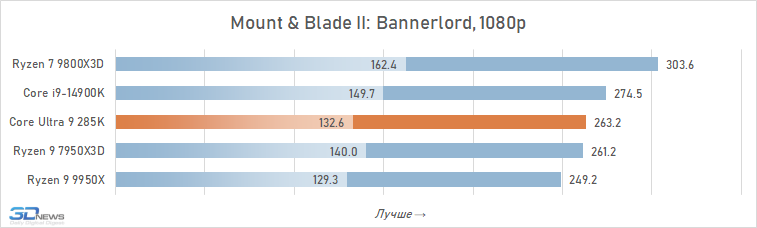
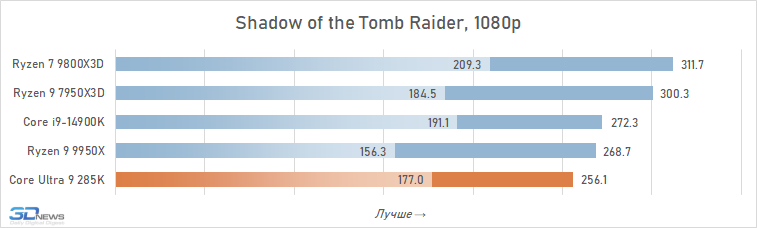
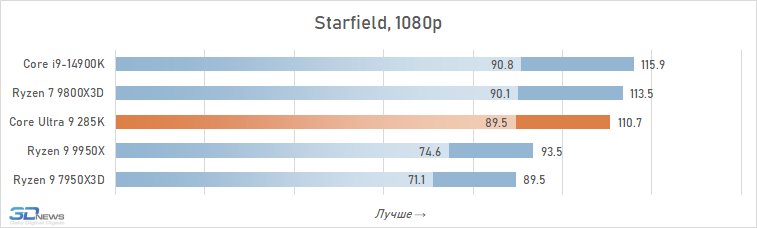
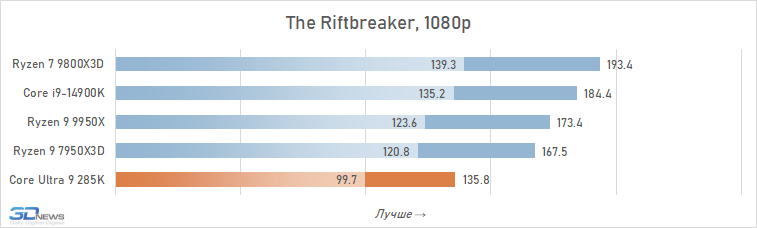
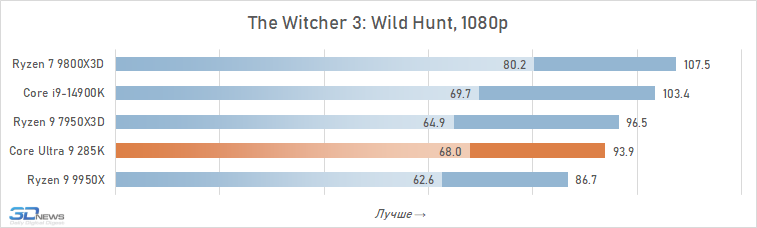
O desempenho do Core Ultra 9 285k em jogos é uma visão bastante triste. Uma vantagem perceptível dos núcleos desse processador no IPC sobre seus antecessores, a memória de cache expandida do segundo nível e a rejeição do hiper-threading deveriam ter contribuído para um aumento no desempenho do jogo. Mas, na prática, vemos os termos de imagens opostas da frequência média de pessoal no Core Ultra 9 285K, o Core i9-14900K perde cerca de 8 %.
E isso significa que, é claro, não pode fazer nenhuma concorrência com as soluções da AMD com um discurso em 3D-kosh. O núcleo médio Ultra 9 285k de Ryzen 7 9800x3D em cargas de jogo excede 15 %, e isso significa que a plataforma LGA1851 não pode ser chamada de jogo. Além disso, o melhor que o principal Ultra 9 285K, os FPs podem ser oferecidos não apenas pelos arquitetos Zen 5, mas também relacionados à geração passada Ryzen 9 7950x3d-sua superioridade sobre o lago sênior de Arrow é de 7-8 %. De fato, a Intel, em seu novo carro-chefe, lançou o desempenho do jogo para o nível do processador Ryzen 9 9950X-A, que no momento de sua saída foi confrontado com críticas fortes, inclusive devido a um desempenho fraco nos jogos modernos.
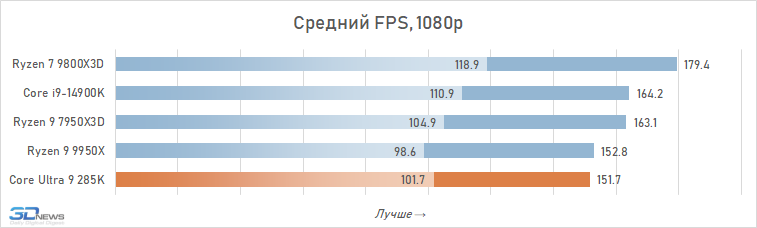
Também vale a pena enfatizar que conduzimos estes testes depois que a Intel tomou medidas adicionais para melhorar o desempenho do Core Ultra 9 285K. Mas nem as atualizações do Windows 11 nem as novas versões de microcódigo tiveram qualquer impacto qualitativo na situação. O Core Ultra 9 285K continua sendo o pior processador carro-chefe de 2025 para a construção de sistemas de jogos.
E as razões para esse fracasso estão na superfície. A questão, é claro, não são os problemas com a distribuição de threads entre núcleos e erros na implementação da tecnologia Thread Director, com os quais a Intel está lutando em seus patches. A falta de desempenho em jogos é consequência direta da alta latência do subsistema de memória. Os jogos são um dos tipos de aplicativos mais sensíveis à memória, mas a Intel de alguma forma ignorou esse ponto em seu design Arrow Lake e permitiu que a latência aumentasse em quase um terço em comparação com CPUs anteriores. Seria muito ingênuo esperar que um processador com latência prática ao acessar a memória de 80-90 ns fosse capaz de mostrar um nível decente de FPS.
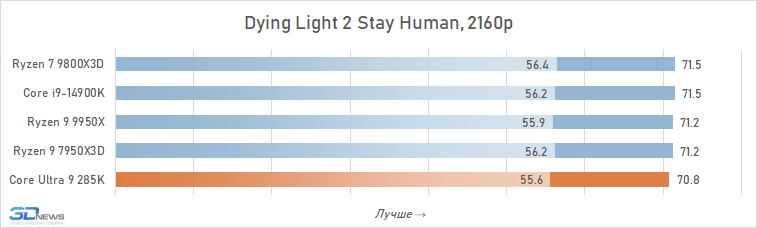
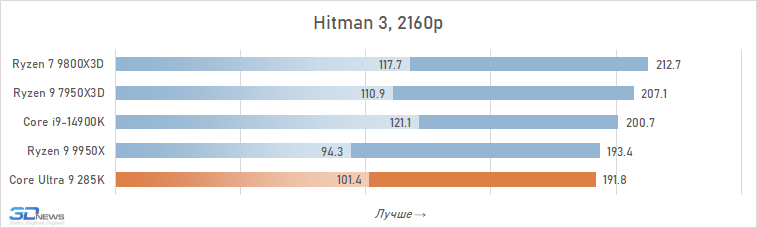
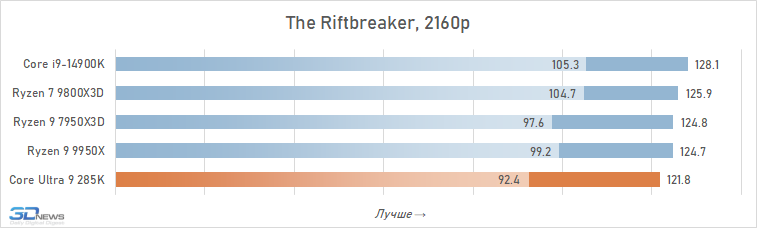
Além disso, entre os jogos há aqueles que sofrem especialmente com esse aumento de latência. Em alguns deles, o Core Ultra 9 285K perde para o Core i9-14900K em FPS em mais de 15% (por exemplo, em Baldur’s Gate 3, Dying Light 2 Stay Human, The Riftbreaker ou Hitman 3). E seu atraso em relação ao Ryzen 9 9800X3D pode até ir muito além da marca de 25%.
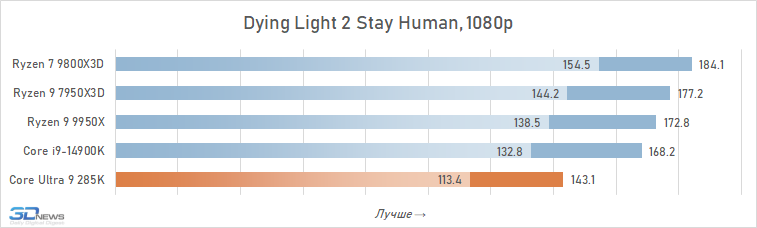
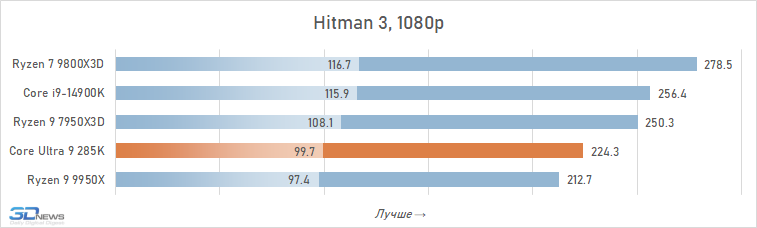
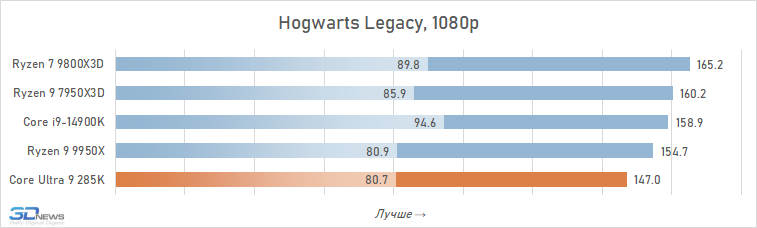
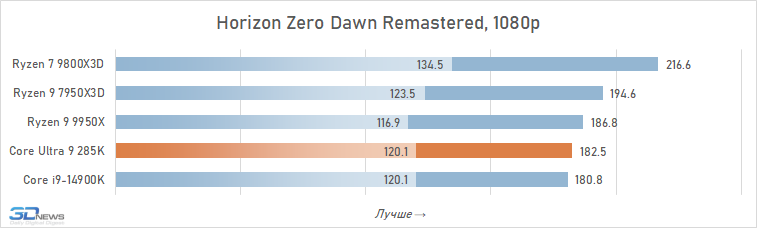
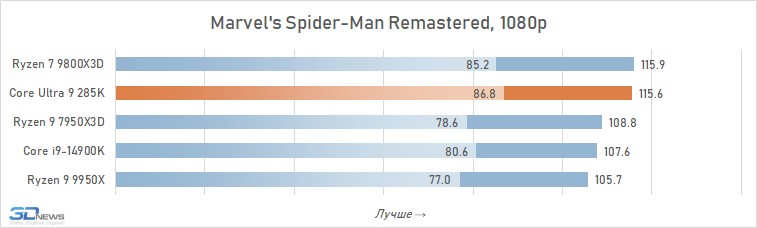
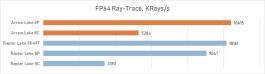
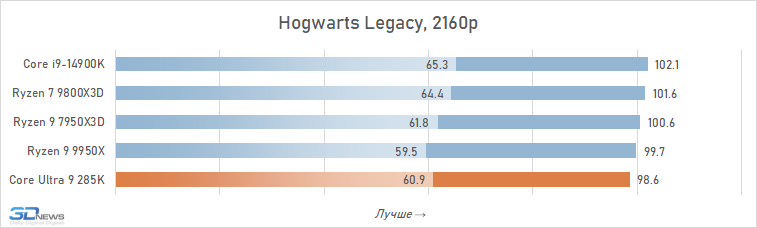
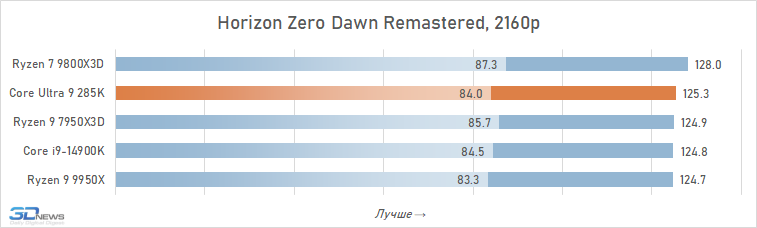
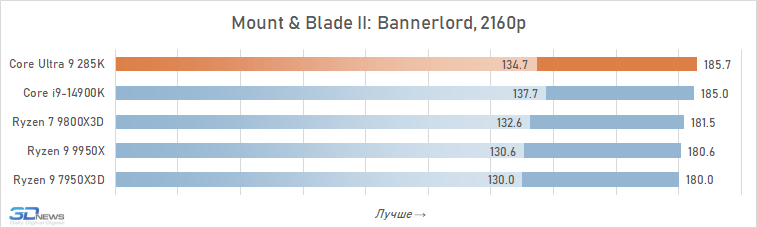
⇡#Desempenho de jogo. Testes em 2160p
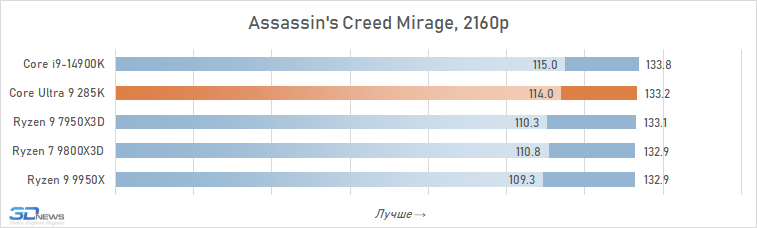
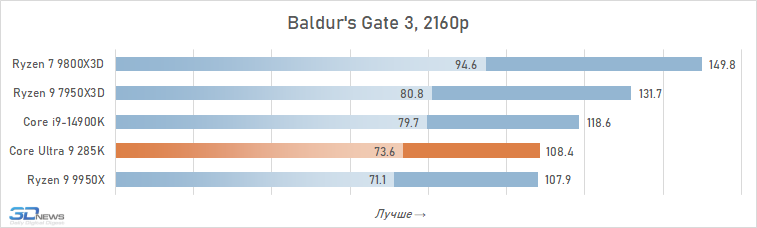
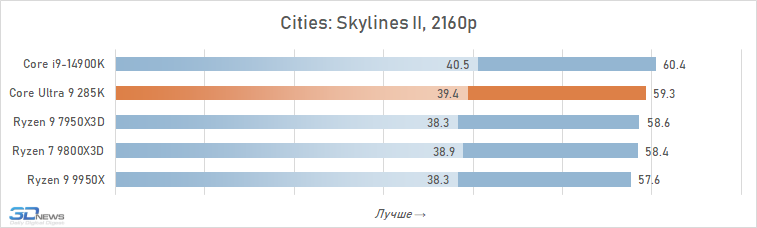
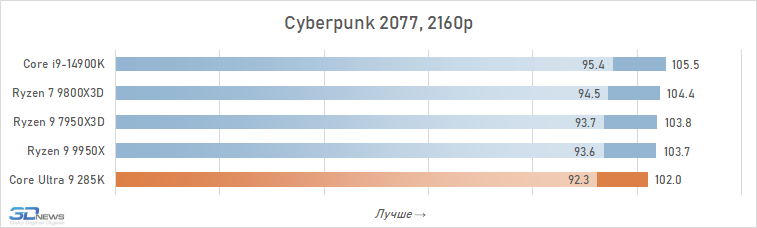
É geralmente aceito que, em altas resoluções, o desempenho de vários processadores está alinhado e, para os jogadores que preferem jogar 4K, mesmo um processador pode ser adequado, o que mostrou maus resultados nos testes em HD completo. Isso é parcialmente assim: o crescimento da resolução aumenta a carga na placa de vídeo e a contribuição relativa da CPU para os resultados finais se torna definitivamente menor. Portanto, à primeira vista, o Core Ultra 9 285k parece não tão sem esperança nesta parte dos testes.
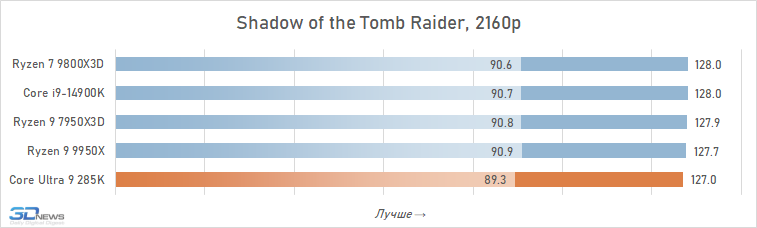
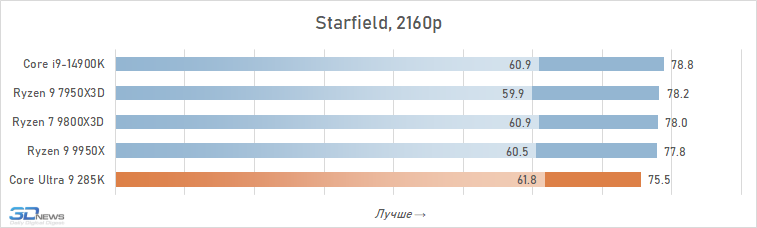
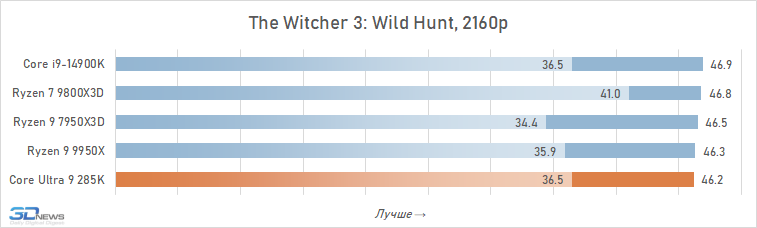
Se você se concentrar no FPS médio para todos os 14 jogos usados em testes, o lago sênior de Arrow perde ao seu antecessor em 4K apenas 2,5 %e Ryzen 7 9800x3D – 4 %. Mas há uma nuance: a situação é muito heterogênea. Entre os jogos, sempre haverá mais dependente do processador, e neles o núcleo Ultra 9 285K será muito mais fraco que as alternativas. Por exemplo, no Hitman 3, é inferior ao Ryzen 7 9800x3d a mais de 10 %e no portão de Baldur 3 – mais de 30 %. Portanto, não recomendamos o uso do Core Ultra 9 285K em nenhuma configuração de jogo, incluindo orientação de 4K-Gaming: o dependente do processador pode ser facilmente seu jogo favorito.
Além disso, mesmo em alta resolução, o núcleo Ultra 9 285K perde visivelmente o Ryzen 7 9800X3D não na média, mas no FPS mínimo, o que indica a pior suavidade da mudança de pessoal nas configurações com base nela. Por essa métrica, a vantagem da versão AMD já é em média 6 %e, em mais de um quarto dos jogos do conjunto de testes, excede 10 %.
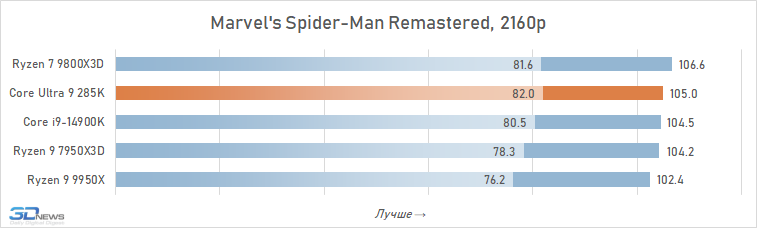
⇡#O Arrow Lake pode ser consertado com memória rápida?
Antes de resumir os resultados finais de nosso conhecimento do Core Ultra 9 285K, gostaria de esclarecer mais uma dúvida a respeito de seu controlador de memória. Ou seja, é possível corrigir de alguma forma a situação com latência catastroficamente alta, aproveitando a capacidade do Arrow Lake de trabalhar com módulos de memória de alta velocidade. A recomendação da Intel de usar módulos DDR5-8000 com novos processadores para melhorar o desempenho não surgiu do nada. Arrow Lake é de fato capaz de funcionar de forma estável com memória DDR5 regular sem buffer em torno de 8 GHz, mesmo em placas com quatro slots DIMM. No entanto, isso pode curar o Core Ultra 9 285K do baixo desempenho em jogos?
Para testes práticos, usamos um conjunto de módulos SDRAM G.Skill Trident Z5 DDR5-7600 CL36 de 32 GB. Na plataforma LGA1851, este kit tem overclock fácil para a configuração DDR5-8000 38-48-48-128, na qual o desempenho prático do subsistema de memória realmente se torna maior. É fácil verificar isso na captura de tela fornecida do Aida64 Cache & Memory Benchmark.
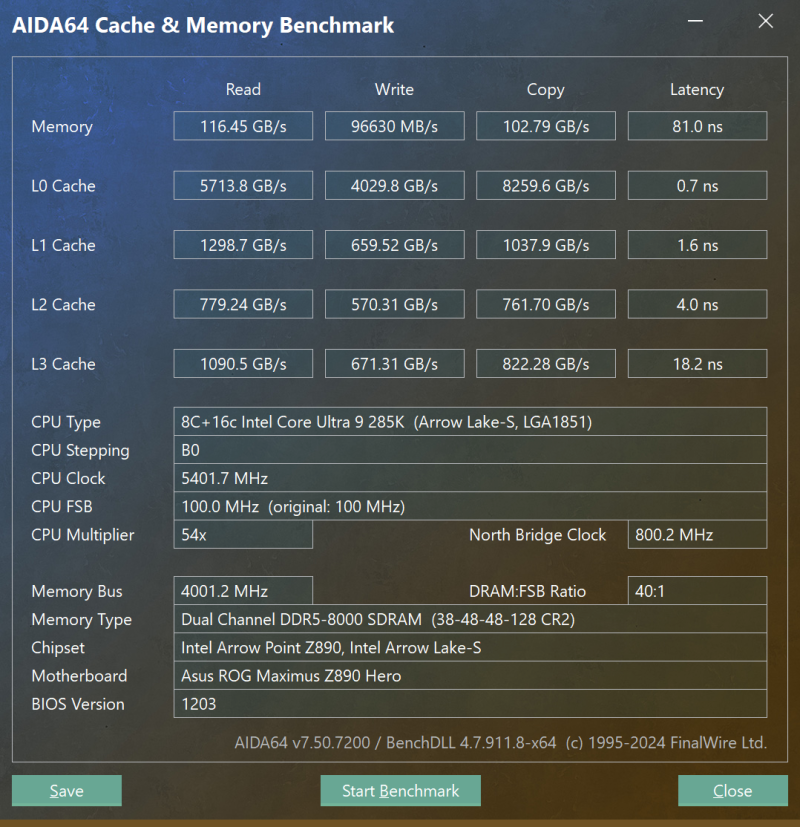
Núcleo Ultra 9 285K, DDR5-8000
Núcleo Ultra 9 285K, DDR5-6400
Aumentar a frequência da memória em um quarto levou a um aumento na velocidade de leitura em 18%, na velocidade de gravação em 10% e na velocidade de cópia de dados em 11%. Parece que este é um efeito muito bom do overclock do DDR5, mas a situação com a latência estraga tudo. Nenhuma quantidade de overclock de módulos DDR5 pode eliminar a assincronia da linha do processador para a memória, como resultado o atraso ao mudar para DDR5-8000 é reduzido em comparação com DDR5-6400 em apenas 6%. A latência da memória permanece num nível “acima de 80 ns”, o que significa que, francamente, não há como esperar uma melhoria fundamental no desempenho dos jogos.
Os testes confirmam apenas essa suposição. O FPS médio, fornecido no sistema com o núcleo Ultra 9 285K, quando o DDR5-6400 a DDR5-8000 aumenta em média em apenas 2-3 %. Isso, em primeiro lugar, indica uma resposta bastante fraca do Arrow Lake para acelerar a memória, pois no caso do Lago Raptor, um aumento semelhante na frequência da memória daria pelo menos metade do FPS. Em segundo lugar, esse aumento não é absolutamente suficiente para mudar pelo menos alguma coisa. O Core i9-14900K com DDR5-6400 permanece 6 % mais combinação de jogos rápida em comparação com o núcleo Ultra 9 285K com DDR5-8000, e você nem pode mencionar a grande maioria preservada do RYZEN 7 9800X3D.
32-39-39-102DDR5-8000,
Em outras palavras, o esquema implementado em Arrow Lake, onde o controlador de memória e os núcleos do processador estão localizados em cristais diferentes conectados por um barramento FDI que não está sincronizado com o barramento em anel da CPU ou com o controlador de memória, é fundamentalmente malsucedido. Parece quase impossível consertar qualquer coisa aqui sem um redesenho de hardware, e os excelentes recursos de overclocking DDR5 do Arrow Lake não significam quase nada. Mesmo em jogos que normalmente respondem de forma muito responsiva ao aumento da velocidade da memória, o desempenho da plataforma Arrow Lake é bastante modesto. Tudo se resume a latências inevitavelmente altas ligadas ao design do processador.
Claro, alguma mudança no desempenho com o aumento da velocidade DDR5 ainda é observada, mas o DDR5-8000 oferecido pela Intel como a “melhor opção” não muda a situação qualitativamente, deixando o Core Ultra 9 285K entre os outsiders dos jogos. Talvez um desempenho de jogo mais competitivo do Core Ultra 9 285K possa ser obtido com módulos ainda mais rápidos, mas para testar isso, você terá que esperar pela ampla disponibilidade de módulos CUDIMM, dos quais se espera que os mais avançados sejam capazes de empurrar o frequência de memória para cerca de 10 GHz.
⇡#Achados
Core Ultra 9 285K é um novo produto muito controverso. Por um lado, a Intel deu vários passos positivos, graças aos quais Arrow Lake subiu significativamente acima de Raptor Lake na escada evolutiva. A arquitetura central atualizada levou a um aumento no IPC. O processador recebeu uma nova estrutura multichip, que possibilitou otimizar produção e custos. Os componentes mais importantes mudaram para uma avançada tecnologia de processo de 3 nm, tornando o Arrow Lake visivelmente mais eficiente em termos energéticos em comparação com seus antecessores. Além disso, a plataforma foi atualizada: o número de pistas PCIe 5.0 suportadas aumentou e a capacidade de suportar memória de alta velocidade melhorou.
No entanto, todas essas vantagens desaparecem contra os antecedentes de resultados reais do núcleo do Ultra 9 285k em testes de desempenho. Aqui ele literalmente falha com um estrondo: o aumento de tarefas difíceis em comparação com o Core i9-14900K não é grave 6 %, e os jogos observaram o FPS médio em 8 %.
A causa do desastre é bastante óbvia. Em primeiro lugar, a Intel limitou deliberadamente o desempenho dos núcleos P, reduzindo sua frequência e desativando o suporte para Hyper-Threading, o que afetou negativamente o trabalho multithread. Em segundo lugar, a transição para um layout multichip levou a uma desaceleração do controlador de memória. Sua latência aumentou em 20–25 ns, e isso afetou bastante a velocidade de aplicativos sensíveis à memória, principalmente de jogos.

Como resultado, é improvável que o Core Ultra 9 285K se torne um processador popular, porque ao construir um PC moderno para qualquer finalidade, você pode escolher uma alternativa da AMD com uma relação preço-desempenho claramente mais favorável. Assim, o Ryzen 7 9800X3D oferece desempenho significativamente melhor no segmento de jogos, e em tarefas profissionais o Ryzen 9 9950X é uma solução mais produtiva. Além disso, a próxima versão do AMD de 16 núcleos com cache 3D certamente proporcionará uma vantagem ainda maior. Em outras palavras, mesmo levando em consideração a melhoria da eficiência energética, a concorrência com os produtos AMD modernos permanece além das capacidades do Core Ultra 9 285K.
Supunha-se que os processadores Arrow Lake melhorariam a posição de mercado da Intel no segmento de desktops após o escândalo de degradação de Raptor Lake e se tornariam uma resposta à família AMD Ryzen 9000. No entanto, descobriu-se que sua aparência apenas piorou a posição da Intel. Chega ao ponto que nas condições atuais, a opção mais lógica para os apoiadores da Intel é comprar chips de gerações anteriores, em vez de mudar para a nova plataforma LGA1851 com a controversa família de processadores Arrow Lake.
E a coisa mais triste é que a falta de soluções dignas da Intel para computadores para desktop durará muito tempo, pois a empresa poderá oferecer os produtos da próxima geração não antes do final de 2026. E isso significa que nos próximos meses a concorrência no mercado de processadores de desktop enfraquecerá constantemente, o que é improvável que beneficie os consumidores.