

Entre as imagens que nem mesmo o PC para jogos mais poderoso que roda Stable Diffusion na versão básica do modelo 1.5 produz, uma notável maioria sai, para dizer o mínimo, de qualidade média. “Qualidade” é entendida aqui da forma mais ampla possível: é a reprodução correta de objetos do mundo real (especialmente pessoas, especialmente suas mãos), a harmonia da composição e até a adequação da perspectiva. Os pontos de verificação treinados por entusiastas mostram, em média, resultados mais aceitáveis, mas mesmo aqui você não deve esperar que na primeira vez consiga obter uma imagem que gostaria de colocar como papel de parede na “Área de trabalho” ou imprimir e pendurar um quadro na parede.
Portanto, antes de julgar o quão bom é este ou aquele texto da dica, este ou aquele parâmetro de geração, esta ou aquela adição ao modelo principal (inversão de texto, LoRA, etc.), faz sentido realizar testes bastante longos – olhando nas dezenas emitidas pelo sistema , mas centenas de fotos são melhores. Felizmente, a geração de uma única imagem de 512 × 768 pixels leva menos de dois minutos em uma GeForce GTX 1070 com 8 GB de memória de vídeo, portanto, coletar essas estatísticas é uma tarefa bastante viável. Outra coisa é que com uma foto de tamanho tão insignificante hoje em dia não há nada de especial a fazer. Hoje, poucas pessoas usam telas de smartphones e computadores com resolução inferior a Full HD e esticadas sem arte em um editor gráfico, digamos,

Fragmentos da imagem usada como exemplo principal neste workshop, antes (à esquerda) e depois (à direita) de um zoom inteligente quádruplo. A altura real do fragmento à esquerda é de 300 pixels (esticada para facilitar a comparação por ferramentas de escala algorítmica padrão no editor gráfico), à direita – 1200 pixels.
Existe remédio para esse flagelo? Existe e também está disponível para usuários de Stable Diffusion com a interface AUTOMATIC1111 (e várias outras): esta é uma ampliação inteligente da imagem. Aquele em que as lacunas que ocorrem naturalmente entre os pontos de partida são preenchidas com o chamado ruído latente (e então as linhas pixeladas “ásperas” se transformam em suaves, as transições entre campos de cores adjacentes também são suavizadas adequadamente) ou com detalhes gerados adicionalmente. Por exemplo, alguma casa na floresta, em uma imagem com dimensões de 768 × 512 pixels, marcada com literalmente um punhado de pixels, com uma ampliação inteligente de toda a imagem, digamos, três vezes, até 2304 × 1536, será adquira detalhes naturalistas – até a textura das encadernações das janelas, tijolos distinguíveis de um cano e uma maçaneta que brilha claramente com o metal.
Sim, para isso você terá que usar consideráveis recursos de computação: o tempo gasto nessa ampliação, em vez de unidades de minutos, já será calculado em dezenas, senão horas. Mas se você tiver a sorte de arrebatar do oceano sem fundo de imagens potencialmente disponíveis para geração de IA (ou seja, do espaço latente) apenas uma, mas merecendo retornar a ela repetidas vezes, faz sentido dar esse passo. Além disso: muitas vezes a imagem acaba tendo um sucesso geral, mas um certo fragmento dela deseja desesperadamente ser corrigido sem tocar em todo o resto. E esse também é um objetivo alcançável para os usuários do pacote Stable Diffusion + AUTOMATIC1111, o principal é saber exatamente como e com quais ferramentas agir. E o mais importante, não tenha medo de experimentar!
⇡#Com o direito de errar
É lógico fazer a correção de um desenho já finalizado (aliás, não necessariamente gerado por IA; é bem possível editar qualquer outra imagem ou fotografia de maneira semelhante, bastará dedicar mais tempo para selecionando os prompts de texto corretos e um ponto de verificação adequado) usando quase o mesmo modelo usado para obter o original.
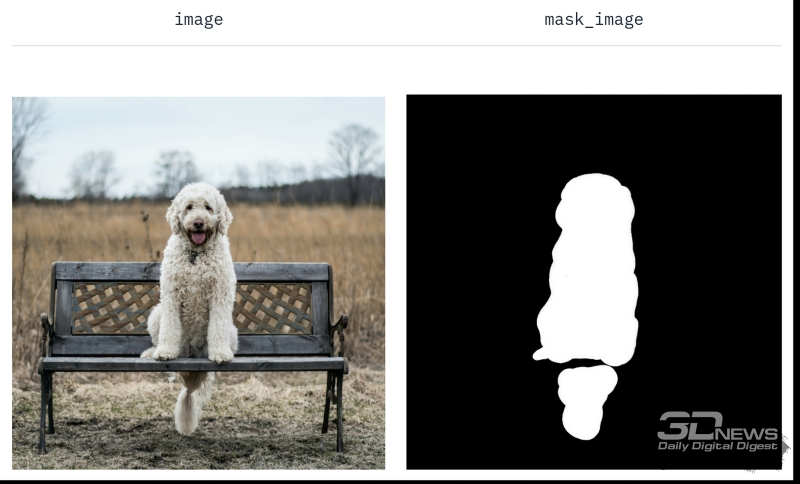
Explicação do princípio de operação do modelo de pintura Stable Diffusion 1.5 na página principal do projeto: uma máscara é atribuída à imagem redesenhada (fonte: Hugging Face)
Lembre-se que a galeria de robôs, que recebemos no final da primeira parte desta ciberprática, foi criada usando o modelo Deliberate v2. Mas também possui uma versão adicional especialmente treinada para finalizar imagens acabadas – Deliberate_v2-inpainting. Terminaremos de desenhar (e redesenhar parcialmente) um dos robôs que recebemos usando-o.
O modelo de pintura de difusão latente para a versão básica do Stable Diffusion 1.5 foi criado em paralelo com o ponto de verificação principal. Ela é especialmente treinada para preencher o espaço coberto por uma máscara de configuração arbitrária. O preenchimento é feito com conteúdo gráfico, que, por um lado, corresponderia ao novo prompt de texto especificado pelo usuário e, por outro lado, se encaixaria organicamente no fundo que envolve a área mascarada. O resultado do trabalho de tal modelo, na versão básica chamada Stable-Diffusion-Inpainting, é a substituição do objeto especificado pelo operador sem violar (idealmente, é claro) a integridade e organicidade da composição gráfica.

Depois que o sistema aprende a trabalhar com máscaras, torna-se fácil e agradável substituir um dos objetos da imagem original por quase qualquer outro (fonte: Hugging Face)
“No entanto, se você aplicar o Stable-Diffusion-Inpainting básico a imagens criadas usando pontos de verificação especialmente treinados, o contraste entre o fundo e a imagem pintada pode se tornar muito impressionante. É por isso que o autor do Deliberate v2 propôs, junto com deste modelo, uma versão especializada para tinta – Deliberate_v2-inpainting , que pode ser baixada no formato .safetensors na guia correspondente na página do projeto dentro do já conhecido portal Hugging Face.”
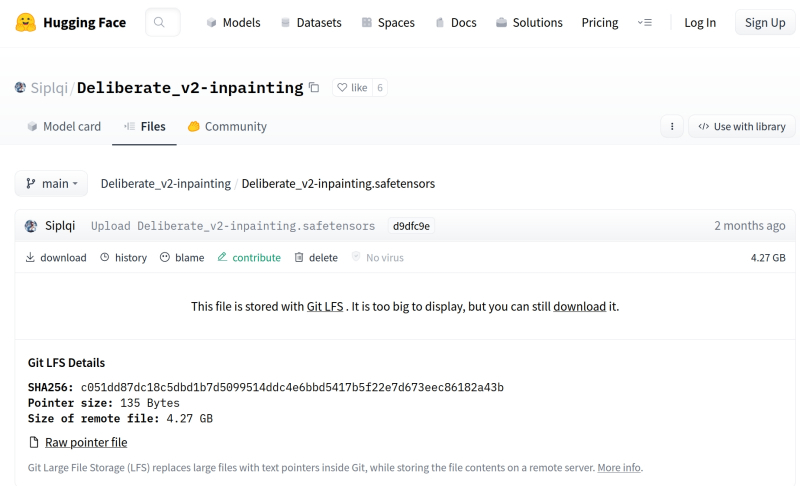
Fonte: captura de tela Abraçando o rosto
Por hábito, é difícil encontrar um link direto para download aqui, mas ele está localizado bem no meio da tela. A linha “Este arquivo é armazenado com Git LFS . É muito grande para exibir, mas você ainda pode baixá-lo ”contém um link ativo na palavra download – você deve clicar lá para iniciar o download.
“Por que precisamos de um modelo para acabamento, que provavelmente não usaremos diretamente, porque já existem (e cada vez mais) postos de controle pré-treinados no mundo, que permitem obter fotos não apenas aceitáveis , mas com qualidade muito decente com mais frequência? que – ao contrário do desenvolvedor do Deliberate e de vários outros modelos populares – a maioria dos criadores de pontos de verificação geralmente negligencia o layout das versões orientadas para pintura interna de seus projetos. E se não houver ponto de verificação de pintura interna do autor , você sempre pode criá-lo usando o kit de ferramentas para mesclar construído em modelos AUTOMATIC1111 acabados.
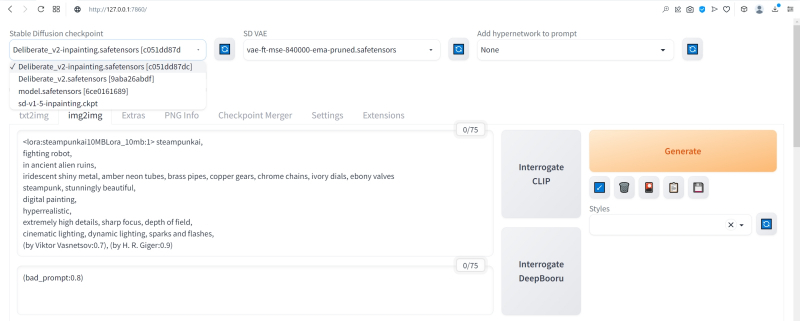
Depois de colocar ambos os pontos de verificação inpainting baixados na pasta de modelos, na página principal do AUTOMATIC1111, clique no quadrado azul com setas brancas semicirculares perto da lista suspensa de modelos disponíveis para geração. Agora ambos Deliberate_v2-inpainting.safetensors e sd-v1-5-inpainting.ckpt apareceram neste menu.
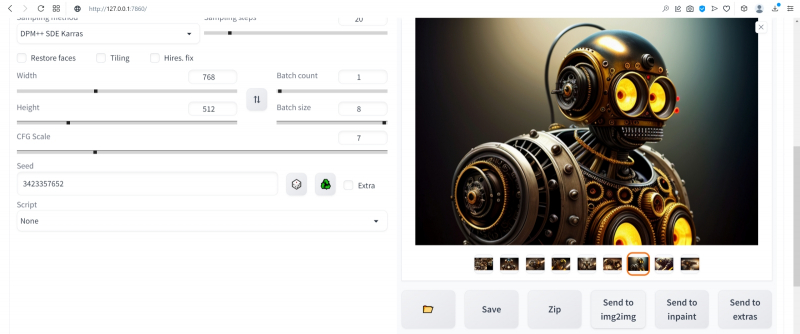
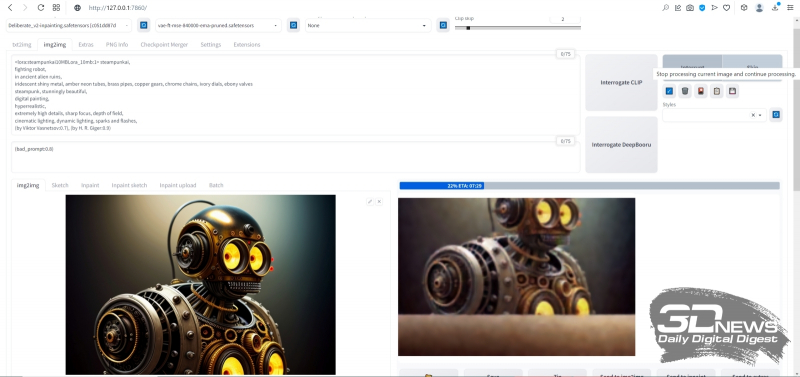
Depois disso, na galeria de imagens, que ainda está aberta e disponível no final da geração final, selecionaremos este robô com a semente (semente) 3423357657 – lembra dolorosamente o ancestral steampunk do conhecido Bender de Futurama , incluindo a “expressão facial” , então mesmo o segundo par de olhos – aquele que pode ser visto na caixa – não estraga a impressão geral positiva. Vamos tentar a amplitude das possibilidades de desenho nesta imagem: enquanto ela estiver ativa na janela de visualização, clique no botão cinza “Enviar para img2img” abaixo – e o AUTOMATIC1111 nos redirecionará para a guia apropriada.
Observe: as dicas positivas e negativas usadas para gerar esta imagem foram transferidas automaticamente para os campos obrigatórios na guia img2img. Agora você precisa selecionar o modelo Deliberate_v2-inpainting.safetensors necessário para exercícios adicionais no menu suspenso do ponto de verificação Stable Diffusion, deixar o campo VAE e o controle deslizante Clip skip no mesmo estado e rolar a tela abaixo.
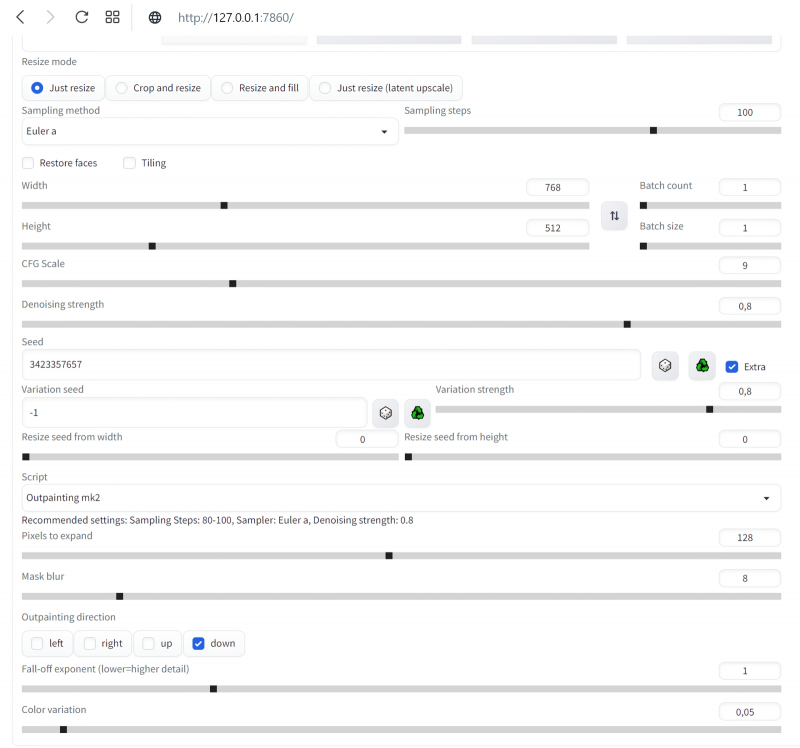
Deixe o modo Redimensionar como está — apenas redimensione. Também definiremos os parâmetros Batch count e Batch size para 1. Aumentaremos a CFG Scale para 9, embora este seja um ponto discutível – no sentido de que a única resposta correta para a pergunta “Qual valor é melhor usar?” só a prática dará e só em aplicação a esta geração em particular (tendo em conta todos os seus parâmetros e dicas).
⇡#Variáveis de Liberdade
Completamente liberado dos grilhões do controle da mente biológica. Dentro do posto de controle selecionado, é claro.”
A propósito, como o papel do estocástico é sempre grande na geração de IA, a manifestação do efeito de ignorar a dica é inevitável mesmo com CFGs maiores – apenas com uma probabilidade proporcionalmente decrescente. Mas se este parâmetro for muito alto – 15 ou mais – então, dependendo das características deste ponto de verificação em particular, é muito provável que apareçam artefatos extremamente desagradáveis: ruído semelhante ao desfoque de uma imagem JPEG de baixa resolução, halos de cores contrastantes ao redor de objetos, saturação de cor excessiva e outras coisas. No entanto, ao mesmo tempo, o modelo fará o possível para seguir a dica dada a ele com a maior precisão possível; portanto, em alguns casos, mesmo valores altos de CFG permitirão obter um resultado bastante aceitável do ponto de vista de visão do operador.

Geração com a mesma dica de “gato flutuando no espaço”, mas com diferentes CFGs (fonte: OpenArt)
Preste atenção ao parâmetro Seed: inicialmente o definimos como 3423357652 – esse é o valor que apareceu no campo correspondente durante a transferência automática de dados da guia PNG Info. Vale a pena verificar a precisão da semente especificada: para isso, volte para a guia “txt2img” e estude cuidadosamente o bloco de texto abaixo da imagem selecionada. Ele lista todos os parâmetros de geração fixados por AUTOMATIC1111, incluindo “Seed: 3423357657”. Acontece que neste caso a transferência não foi realizada de forma bastante correta: os robôs foram gerados em um pacote, e acabou sendo transferida a primeira semente do pacote, e não a que corresponde à imagem selecionada. É possível que em versões posteriores do AUTOMATIC1111 este bug já esteja corrigido, mas neste caso vale a pena retornar à aba “img2img” e alterar manualmente o valor do parâmetro seed para o correto,
À direita do campo de entrada de sementes, há uma pequena caixa próxima a ele chamada “Extra”. Vale a pena marcar a caixa ali, e um menu adicional de várias posições se abrirá. Seu significado é que se você usar sua semente original para desenhar / redesenhar a imagem, o sistema gerará quase a mesma coisa repetidamente, mas se você definir para ser completamente aleatório (o valor “-1” no campo “Seed ” campo), o resultado pode ser muito imprevisível. Variações na semente original são uma boa maneira de manter a criatividade do Stable Diffusion sob controle: uma “semente de variação” aleatória (valor “-1”) fornece a variabilidade necessária dentro de limites razoáveis, e o parâmetro “intensidade da variação” define a intensidade dessa variabilidade. Vamos definir este parâmetro como “0,8” por enquanto e não vamos tocar nos dois controles deslizantes “Redimensionar…” abaixo,

“Um exemplo de por que você não deve desenhar nas quatro direções ao mesmo tempo: se a imagem à esquerda foi complementada de forma bastante orgânica, à direita, o arco no topo repousa sobre uma lanterna de papel e um pequeno pedestal, que foi parcialmente visível no canto inferior direito da imagem original, apenas pairando no ar (fonte: Okuha)”
Vamos começar, de fato, com a pintura externa – pintar a imagem original em uma das quatro direções possíveis ou em qualquer combinação delas ao mesmo tempo. Não há diferença fundamental entre in-painting e outpainting: o último se resume ao fato de que a “tela” da imagem é ampliada, uma máscara é aplicada ao espaço adicional que apareceu e, então, o sistema “tenta descobrir ” como continuar organicamente o desenho original em uma direção ou outra. Digamos, se na imagem gerada na aba “txt2img”, em sua borda direita, estiver o lado esquerdo da janela com a cortina puxada para trás, seria lógico (tanto para a pessoa quanto para o sistema de IA treinado por ele para converter texto em imagens) no caso de desenhar à direita, exibir já toda a janela, devendo a cortina do seu lado direito, se não for estritamente simétrica à esquerda,
⇡#Do amanhecer ao anoitecer
Outro ponto importante na prática: carregar a GPU – tanto ao gerar pequenas imagens iniciais quanto ao desenhá-las em tiras de 128 pixels cada – acaba sendo relativamente suave. Pelo menos para a GeForce GTX 1070 com o parâmetro –midvram no arquivo de configuração, essa carga não excede 35-50% no primeiro desses casos e 40-70% no segundo. Portanto, diretamente no mesmo PC que está atualmente trabalhando no modo “Gerar para sempre” para resgatar imagens visíveis do espaço latente ilimitado do modelo AI, você pode fazer outra coisa – navegar na web, conversar em um messenger, escrever textos , etc
“Mesmo muitos jogos que não exigem muito VRAM, incluindo MMORPGs, serão iniciados e executados sem lentidão perceptível – mas, é claro, a velocidade de geração de imagens neste caso diminuirá um pouco em comparação com a situação em que nenhum programa de terceiros reivindicar memória de vídeo. Além disso: o Windows 10 hiberna todos os dados da RAM, incluindo a memória de vídeo, para a unidade lógica, para que o entusiasta de pintura AI mais endurecido que ainda tenha que dormir com o ruído dos ventiladores de seu PC tenha a oportunidade de colocar o computador em este modo à noite – e pela manhã, depois que a máquina sair da hibernação, a imagem de difusão estável continuará automaticamente sem qualquer interrupção.”
O que mais há de bom no modo “Gerar para sempre” é a presença de uma visualização (em uma resolução deliberadamente reduzida) do que exatamente o sistema está desenhando no momento. Não faz muito sentido julgar a qualidade da imagem final pelos primeiros aproximadamente 30% da geração, mas se depois que o desenho estiver pronto pela metade, a visualização definitivamente não combina com você, faz sentido economizar um precioso recurso de computação. Para isso, com o botão esquerdo do mouse, como de costume, basta clicar no grande botão cinza “Pular” que apareceu no lugar de “Gerar”. Ao final da próxima iteração, o sistema será interrompido e passará a renderizar a próxima imagem – porém, não é fato, claro, que o operador ficará satisfeito com isso. De qualquer maneira, você terá que ser paciente.

Aqui, por exemplo, que busto impressionante do herói acabou com base na imagem original com uma semente igual a 3423357657, depois de desenhar usando o script Outpainting mk2 com uma semente de 2817834830 (esta é a semente do desenho, ou seja, a faixa adicionada à imagem). Pode-se esperar que apareça uma imagem mais dinâmica – digamos, um corpo de robô em movimento; em seguida, continue de novo, de novo e de novo – e termine com uma composição estreita vertical de alta definição. Mas como neste caso é importante dominarmos as ferramentas básicas, vamos nos concentrar neste busto.
Tudo está bem nele – exceto pela “inscrição” (mais precisamente, um punhado de pixels agrupados em linhas ordenadas que se assemelham a sequências de letras) no canto inferior esquerdo. Como o Stable Diffusion e seus checkpoints derivados foram treinados em uma enorme variedade de imagens da Internet, incluindo imagens com direitos autorais, dados de saída superimpressos e até mesmo, assustador dizer, tiradas sem permissão de bancos de fotos comerciais (mais precisamente, de suas zonas de visualização, onde todas as imagens são cobertas com “marcas d’água”). sinais”), o aparecimento de tais artefatos é inevitável – mesmo que apenas de vez em quando.
O que exatamente corrigir, o sistema indicará os traços deixados na imagem original pela ferramenta de redesenho. Na imagem com o robô, em seu canto inferior esquerdo, nesta captura de tela, um ponto preto em negrito com um núcleo branco é visível – é isso. Quando você passa o mouse sobre uma imagem na janela de pintura interna, seu cursor se transforma em um ponto: se você pressionar o botão esquerdo do mouse e movê-lo de um lado para o outro, um traço preto permanecerá na imagem – a máscara do futuro redesenho. Em princípio, você pode escurecer imediatamente todas as partes da imagem que não combinam com você, mas todas elas serão geradas para cada passagem de uma vez – o que significa que certamente surgirá uma situação em que o redesenho é claramente bem-sucedido em um lugar, mas ainda não em outro. Portanto, também aqui, como no caso da pintura externa, faz sentido agir de forma consistente,
A rigor, é a pintura interna que é um dos pontos fracos do AUTOMATIC1111: a ferramenta para aplicar a máscara é grosseira (embora o diâmetro do círculo preto possa ser alterado – uma etiqueta com um lápis simbólico é fornecida para isso no canto superior direito canto da imagem), mas a escala da imagem em si não pode ser aumentada, portanto, especialmente em qualquer caso, não será possível aplicar traços finos. Em princípio, isso não é um problema, pois o modelo para redesenho em qualquer caso levará em consideração as áreas da imagem adjacentes à máscara aplicada – e tentará (dentro de seu treinamento, é claro) fazer a transição entre a área redesenhada e a imagem original ao seu redor de acordo com características naturais e suaves. Muitos entusiastas do desenho AI recomendam outra interface gráfica para Stable Diffusion, o projeto InvokeAI, por ser mais conveniente e oferecer mais opções para editar as imagens resultantes (não sua geração inicial!) Até agora, porém, com todas as suas vantagens incondicionais, parece mais cru do que AUTOMATIC1111 – então você terá que testá-lo por sua própria conta e risco, adotando ativamente a experiência de outros testadores entusiastas em fóruns especializados, em particular na plataforma Reddit .
⇡#Máscara, eu te conheço!
De uma forma ou de outra, neste caso, é importante para nós simplesmente dominar o redesenho como princípio. Cubra aproximadamente a “inscrição” no canto inferior esquerdo, deixe o “Modo de redimensionamento” na posição “Apenas redimensionar” e mantenha o desfoque da máscara — a largura da borda na qual o sistema levará em consideração o conteúdo da fonte imagem ao redor da máscara — na posição “4”. Abaixo, entre o “Modo Mask”, selecione “Inpaint masked” (ou seja, a área dentro da mancha preta será redesenhada, e não fora dela).
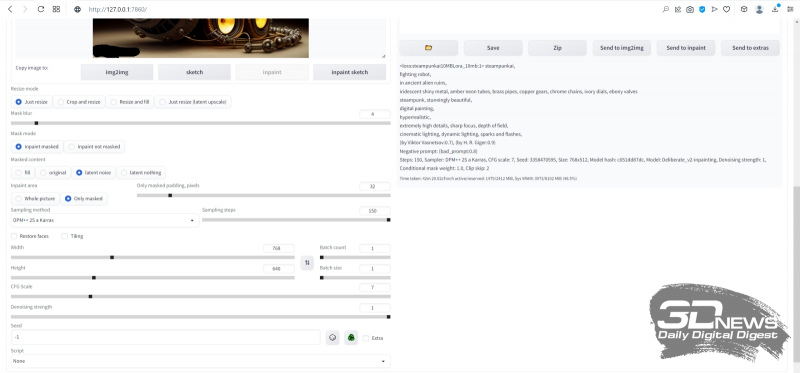
«

E este (redraw seed 2345658978), aliás, não é nada mau! A “inscrição” desapareceu sem deixar vestígios, mas na mesa (ou seja lá o que for que o busto gerado pelo sistema do tataravô de Bender repousa) apareceu alguma peça complexa, obviamente eletromecânica. Ela é fofa sozinha, mas em combinação com a expressão extremamente característica dos olhos do próprio busto (dos dois pares), tem-se a sensação de que caiu da estrutura por acidente – e o próprio tataravô foi seriamente abalado por este incidente. Na verdade, essa é a beleza da criatividade artística da IA: não importa quão detalhada (ou, ao contrário, vaga) seja a dica, a estocástica no nível do espaço latente ilimitado, mais cedo ou mais tarde, cobrará seu preço – e eventualmente dará origem a um imagem que pode surpreender a pessoa que lançou a geração em um bom usuário.
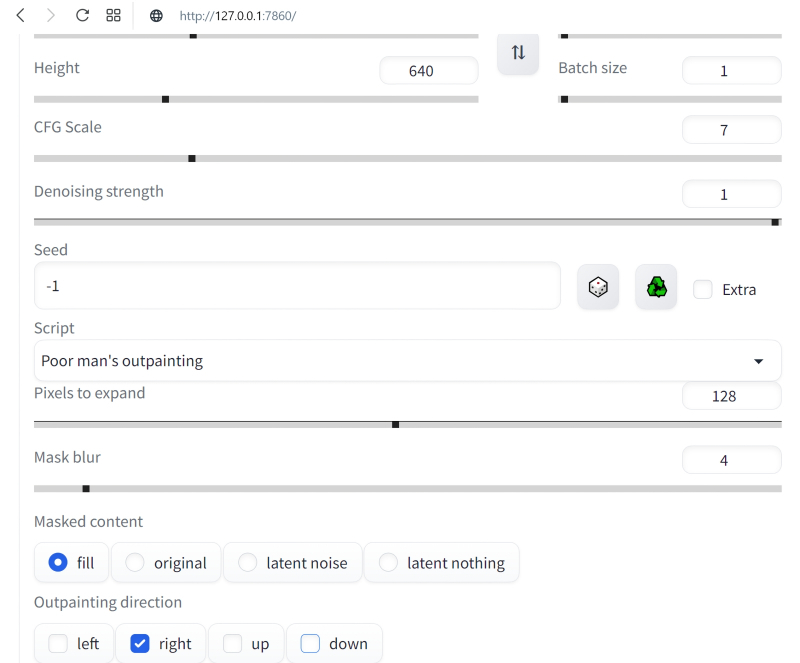
Agora, de forma familiar, vamos estender a imagem para a direita, tornando-a mais alongada na composição, usando outpaint. Para fazer isso, você precisará parar novamente a geração através do botão direito do mouse e “Cancelar geração para sempre”, carregar a imagem redesenhada que escolhemos (sua semente, lembramos, se alguém quiser reproduzir meticulosamente o processo – 2345658978) em “PNG info”, de lá envie a imagem para a guia inpaint. Agora, para variar, usaremos, porém, outro script – não “Outpaint mk2”, como da última vez, mas “Poor man’s outpainting” com os parâmetros “fill” e “Mask blur: 4”

De alguma forma não muito expressivo, certo (Seed: 2583232873)? Apenas uma continuação natural do fundo geral da imagem original à direita. É verdade que se for o papel de parede para o “Desktop” que é gerado, esta opção pode ser bastante preferível: neste caso, deve haver o mínimo de detalhes possível abaixo e à direita que possam ser cobertos pelo sistema operacional barras de ferramentas. Mas neste caso, continuaremos alterando um pouco a ponta do desenho.
Aqui é importante decidir: o que exatamente você, o (co)autor da imagem gerada pela IA, quer ver nesta seção da imagem? Talvez outro robô steampunk, em uma pose triste e concentrada (“Pobre Yorick! ..”), olhando para o busto, de onde os relés já estão saindo? Ou um traficante de sucata alienígena puxando as patas predatórias para o artefato? Ou uma criada androile futurística com um espanador de penas de avestruz? Ou alguma outra coisa? A fantasia do operador (“usuário” para chamá-lo agora é um tanto envergonhado) Difusão estável, em cooperação com o abismo do espaço latente, é capaz de gerar as imagens mais sofisticadas – mas quais, a dica para a área de desenho determinará .
Nesse caso, daremos à IA o maior escopo de criatividade simplesmente removendo tudo da parte positiva da dica, exceto para chamar LoRA:
Negativo continua igual
Vamos voltar ao script, definido de acordo com as recomendações de seus desenvolvedores, defina o modelo de ponto de verificação como antes, defina o Parâmetro igual a

Novamente, uma espécie de imagem sobreposta apareceu na parte inferior, mas desta vez não são pseudo-letras ilegíveis, mas um logotipo natural Agora, esta é uma ilustração direta de um livreto de jogo fictício, disse ele “” A imagem é bastante detalhada, embora não sem falhas, por exemplo, na parte inferior do mesmo, aproximadamente ao nível das “pupilas” localizadas no corpo do robô, o segundo par de olhos linhas de luz estendendo-se para a esquerda e para a direita, diminuindo gradualmente a luz linhas Eles não são difíceis de remover a roda em qualquer editor gráfico no nível acima do Linux, os luxoids lembram imediatamente a essência e é raro que uma amostra amplamente divergente de visual e geração na Internet fique sem esse ajuste fino manual
⇡Expandindo os limites
Mas agora há uma tarefa mais importante. A imagem é muito pequena. É hora de aprender como aumentá-la – não apenas mantendo a qualidade no mínimo, mas no máximo – até mesmo aumentando os detalhes
Todo o kit de ferramentas para isso oferece – extremamente potencialmente Vamos para a guia com extensões «»lá na seção»»será necessário pressionar o grande botão laranja»»Endereço da Web do repositório principal de onde o nome do download de status extensões pela interface do desenvolvedor aqui apenas gentilmente especificadas no futuro serão necessárias facilmente e serão transferidas para outra fonte
O desenvolvimento deste comando pode levar alguns minutos de extensões para uma interface realmente extremamente impopular, ax já criou muito Orientar na lista de hábitos resultante não é fácil neste caso, precisamos de um script bem definido chamado ” ” pressione o botão cinza “” na linha desejada …
…Então aqui na guia “” vá para o link “” no topo desta mesma página da web à esquerda de “” e pressione o grande botão laranja “” Aqui, a propósito, você pode atualizar manualmente scripts de terceiros instalado desta forma, se necessário – um botão para isso também é fornecido
A rigor, o pacote inicial já inclui vários scripts para aumentar a escala do upscaling da imagem, mas eles precisam de uma memória de vídeo bastante grande – muito mais do que a geração inicial exige. A imagem do busto que recebemos agora – com o detalhe à esquerda e o logotipo da franquia inexistente à direita – ocupa pixels em largura e alturaMais de duas vezes o upscale em ambas as dimensões mttenarea aumenta por vezes, preservando a imagem e aumentando a qualidade dos detalhes, detalhes dos quais nós agora descreva o computador com a placa de video gasto quase um minuto
Como é realizado o upscaling O princípio geral do conceito é que a imagem é esticada mecanicamente, admissível com certeza, para quatro na área, após o que o sistema analisa a posição relativa e a cor dos pixels ampliados obtidos e de certa forma suaviza as transições entre eles. tanto quanto maior resolução permite, é claro, uma linha inclinada da cor correspondente. No entanto, deve-se lembrar que, ao aumentar a escala, leva em consideração dicas de texto positivas e negativas, portanto, o resultado de tal script pode parecer bastante inesperado

Comparação da imagem original com uma baixa resolução de seu upscaling algorítmico com o uso de um filtro Lanczos de fonte de dimensionamento AI inteligente
Antes do advento dos sistemas de IA disponíveis publicamente para trabalhar com imagens, artistas de computador e editores de fotos usavam vários algoritmos para dimensionar imagens bitmap, incluindo interpolação bicúbica, o filtro Lanczos e muitos outros, muitas vezes tinham que operar em duas passagens, pois em muitos o dimensionamento de casos de acordo com o algoritmo levou ao aparecimento de pixels irregulares claramente distinguíveis, especialmente em linhas curvas contrastantes – o que, por sua vez, exigia processamento anti-aliasing adicional. Em geral, o aumento de escala de imagem na era pré-gerativa da IA era um recurso extremamente -tarefa intensiva e raramente dava o resultado mais satisfatório – principalmente devido à quase inevitável diminuição da nitidez com o dimensionamento algorítmico
O dimensionamento AI remove o problema de nitidez às custas do já conhecido espaço latente. Na verdade, qualquer upscaler na composição é um modelo separado especialmente treinado para restaurar detalhes ausentes. Ao inverter o processo, o modelo para dimensionamento primeiro aprende a reduza a resolução das imagens originais, tornando-as ruidosas – e, em seguida, reverte essa ação, restaurando assim os detalhes perdidos ao reduzir
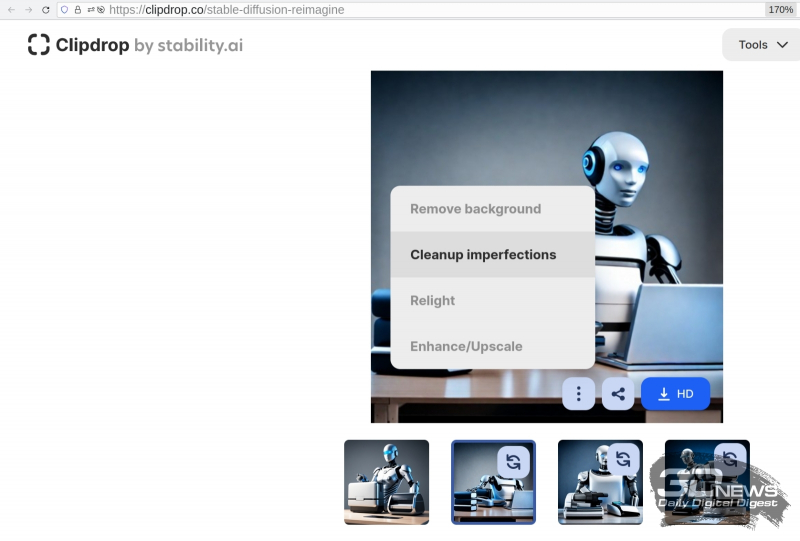
Ferramentas on-line Método de processamento de imagem AI agora apenas dimensionar imagens do filme e recortar objetos remover o fundo eliminar defeitos alterar a posição da luz e a temperatura da cor de uma fonte de luz invisível no quadro muitas outras fontes captura de tela do site a imagem original também é gerado por IA
Aqui, incondicionalmente, uma sutileza, restaurando a clareza de algum fragmento borrado da imagem, o sistema é forçado em maior ou menor grau a determinar aleatoriamente que tipo de objeto está escondido sob cada ponto lamacento, definindo um parâmetro para um valor alto um pouco mais baixo, o resultado pode parecer excessivamente criativo – a ponto de ser rejeitado.
Em primeiro lugar, faz sentido manter as mesmas dicas de aumento de precisão, de modo que foram aplicadas ao gerar a imagem original. Ao mesmo tempo, você precisa estar ciente de que esse dimensionamento será acompanhado por um aumento no detalhe do desfoque . transforme-se em um tubo em miniatura e aponte para cada rodada em uma engrenagem. Nesse caso, quando um robô de desenho não é um problema, mas dimensionar, digamos, um retrato humano com cópia direta dos parâmetros de geração originais “loiro encaracolado cabelo, olhos azuis, até dentes …” pode gerar uma imagem bastante grotesca na qual, em pequenos detalhes, um rosto ampliado será claramente adivinhado outros rostos ou seus fragmentos Normalmente, se você quiser evitar detalhes excessivos ao dimensionar, você é limitado à dica positiva mais geral como “”

A supressão de ruído forçada praticamente destrói todas as informações da fonte
O segundo até que ponto o modelo de upscaling é livre para permitir maior detalhe na imagem ampliada determina o já mencionado parâmetro de poder de redução de ruído. o valor mínimo para retratos de paisagens realistas e naturezas mortas não deve exceder o valor exato final aproximado dependerá a imagem específica e no ponto de verificação selecionado e as dicas indicadas para upscaling.

Resultados da geração de imagens com dicas de pontos de verificação fixos e outros parâmetros que diferem apenas por um determinado número de etapas de amostragem – da fonte
Em terceiro lugar, ao enviar a imagem para aumentar, o número de etapas de amostragem deve ser ajustado. Um valor razoável para esse parâmetro é – mas este é o caso da geração inicial, de fato, quando o sistema extrai a imagem do abismo do espaço latente com uma rede de dicas de texto tokenizadas, enquanto o valor de “redução de ruído” é necessário diminuir e, portanto, precisa ser selecionado o número de etapas de amostragem de forma que o produto desses dois valores ainda permaneça dentro dos limites de – Em outras palavras, se na etapa de dimensionamento for definido, será necessário aumentar até então e Caso contrário, a qualidade da imagem ampliada ficará, para dizer o mínimo, longe da expectativa
Resuma os parâmetros de upscaling na guia Positive Hint
Negativo
Próxima escolha
Tes random embora você possa usar e original – neste baixo não haverá muita diferença
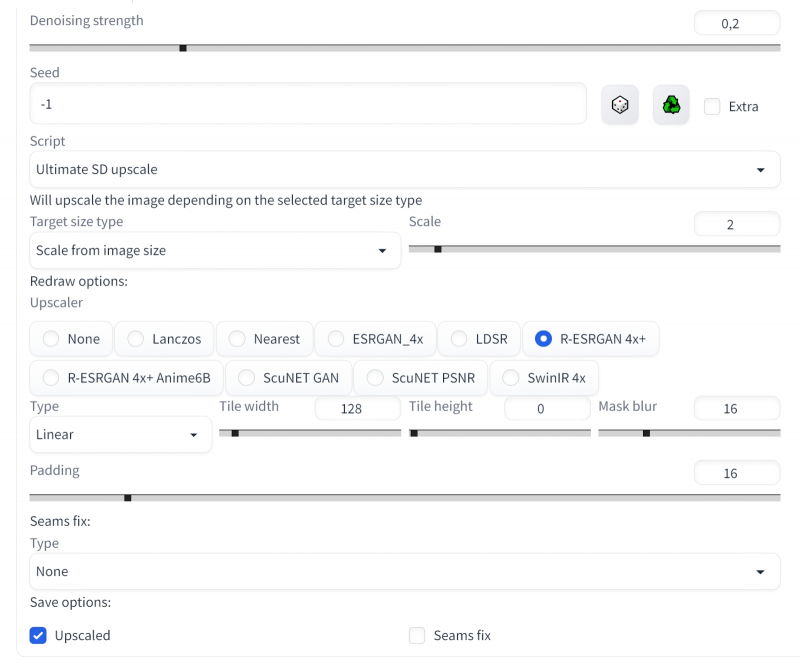
Em seguida, selecione o script com os parâmetros “” e “” – isso define um aumento de duas vezes em ambos os lados quatro vezes na área. Aqui, dobrar é suficiente, se houver desejo de aumentar ainda mais a imagem – para para imprimir em um formato grande, por exemplo – nada o impedirá de enviar a imagem resultante para a guia novamente e repetir todo o procedimento novamente Somente neste caso o dimensionamento exigirá muito mais tempo
⇡Нетпредалапольшесту
Ao escolher um modelo upscaler, vamos parar em “”reconhecido por muitos entusiastas e desenhar um dos melhores universais e definir por enquanto””a””Aqui é necessária uma explicação. Devido a essa abordagem, é possível minimizar o uso de memória de vídeo, os ladrilhos para processamento são carregados um a um, o que reduz significativamente os requisitos de volume mínimo – mas à custa de um aumento considerável no tempo de processamento de imagens
Parâmetros adicionais indicam a que distância os pixels estão nos ladrilhos vizinhos, o sistema deve procurar para correlacionar a escala desse ambiente produzida neste bloco “” e quão forte deve ser o anti-aliasing dos ladrilhos de máscara “” Com todos esses valores, o kaki informa a página oficial do projeto sobre você pode precisar jogar para obter o resultado mais satisfatório para você – mas por enquanto nos limitaremos a esses valores Resta selecionar “” na esperança de que nenhum visível as articulações aparecerão na imagem e, portanto, você não precisará corrigi-las e “” pois precisamos de uma imagem dimensionada com precisão – e agora execute a geração

É assim que nosso busto steampunk do tataravô Bender fica no estilo de “arte oficial do jogo” depois de ser ampliado com um leve aumento de detalhes. Isso já é quase um papel de parede “Desktop” – a resolução original × para isso publicação é necessário reduzir a pixels no lado maior. Realmente sem “sabão” e quase sem ruído disperso as imagens demoravam pouco mais de uma hora por PCssGByte, tornou-se a sexta semente da série lançada da maneira que já conhecemos bem – pressionando “” em vez do habitual “”
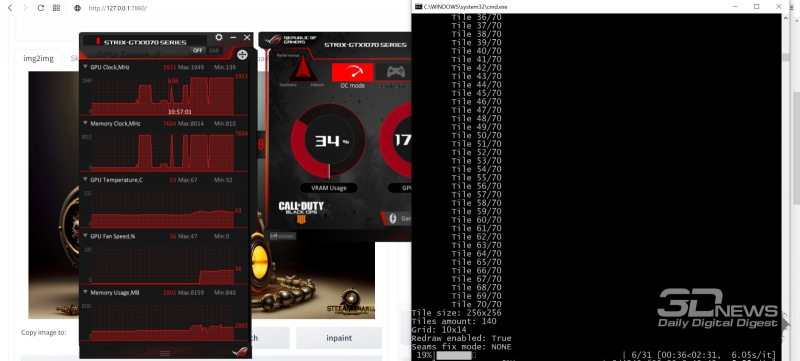
Então, após interromper o procedimento de geração infinita, transferimos a imagem em escala obtida novamente para – e novamente executamos o script no trabalho. Desta vez, a diferença da execução anterior anterior, apenas um parâmetro “” será definido para completamente encolher com blocos “” permanece igual – isso implica que a altura dos ladrilhos é igual à largura do neonicquadrado. Como você pode ver, a memória de vídeo no processo de trabalho é ocupada por apenas um terço – mas o tempo e a execução de dimensionamento leva mais de horas. Com base nesses parâmetros, você pode aumentar ainda mais o tamanho de um único ladrilho – isso levará a uma aceleração do processo

Foi assim que nosso beautifu geo acabou sendo a semente final – × pixels quadruplicados no processamento da imagem gerada em geral, uma dica bastante simples, mesmo usando inversões de texto. Em todo o esplendor da resolução original, esta amostra e a criatividade pode ser vista aqui. desenho científico, enquanto o modelo generativo permite que você se sinta o criador do belo, quase qualquer pessoa à sua disposição tem um PC para jogos ligeiramente funcional
Claro, este é apenas o começo do caminho, extremamente confuso em alguns lugares, mal transitável aqui e ali, mesmo com uma amplitude impressionante de possibilidades, o caminho do III e das artes plásticas Depois de dominar a geração básica antes e redesenhar e dimensionar, é faz sentido tocar pelo menos na extração de pistas de texto de imagens de terceiros, modelo de desenho, expansão especialmente na versão mais atual, fragmentação da imagem diretamente no processo de geração primária – permite criar imagens composicionalmente corretas que são fortemente alongado horizontal ou verticalmente, além de fornecer dicas para áreas individuais de uma única tela e muito mais
Fique ligado – será interessante