
Não é fácil para os operadores novatos de modelos generativos de conversão de texto em imagens navegar pela variedade de opções oferecidas pelo AUTOMATIC1111 e outros ambientes de trabalho (com exceção, talvez, do Fooocus, que é o mais mesquinho em termos de opções disponíveis para o do utilizador). Uma combinação bem-sucedida de parâmetros, que dá origem a uma imagem particularmente atraente, às vezes é percebida como um achado raro – não é por acaso que já existem muitas trocas on-line de dicas de negociação na Internet. Sim, é isso mesmo: as pessoas estão dispostas a pagar por combinações de palavras que garantam a produção de imagens obviamente de alta qualidade (seja lá o que todos querem dizer com essa palavra). “Engenheiro imediato” é hoje uma profissão que proporciona um rendimento de até 300 mil dólares por ano, embora ainda não esteja muito claro quais são as suas perspectivas, mesmo a médio prazo. A coisa é,
Porém, além da dica em si, qualquer geração tem muitos outros parâmetros – os de serviço. Isso inclui a escolha de um ponto de verificação pré-treinado (se você usar modelos SD 1.5 ou SDXL 1.0 não originais, cuja configuração inicial foi realizada pelos próprios desenvolvedores do Stability.ai) e o número de etapas de “remoção de ruído ”a representação numérica da imagem no espaço latente (etapas), e o escalonador/amostrador específico, e o valor CFG (classificador de orientação livre, uma medida da liberdade de ação do classificador), e até mesmo as dimensões da tela : tanto as dimensões quanto a proporção de seus lados longos e curtos. É por isso que navegar no espaço latente – do qual o modelo generativo de IA realmente extrai imagens, com base em todo o conjunto de parâmetros que lhe são dados – é uma tarefa tão difícil: há muitas variáveis.

Fonte: geração de IA baseada no modelo SDXL 1.0
Isso, por sua vez, torna o procedimento de otimização de dicas (texto e serviço) uma tarefa extremamente trabalhosa: é preciso otimizar o sistema de acordo com um conjunto impressionante de parâmetros simultaneamente, e até mesmo levando em consideração o fato de que cada imagem é gerada em dezenas de segundos, ou mesmo um minuto – outro (em nosso PC de teste com GPU GTX 1070). Então o que resta: confiar na caprichosa Fortuna e simplesmente alimentar aleatoriamente o AUTOMATIC1111 com as mais diversas combinações de valores de entrada na esperança de um dia alcançar um resultado verdadeiramente atraente? Sim, você pode fazer isso, mas é melhor organizar seus esforços se possível, realizando uma busca com pelo menos um nível básico de sistematização. Isto não será semelhante a uma viagem moderna usando um navegador por satélite até ao ponto cobiçado no mapa, mas sim
Vamos tentar?
⇡#Inspeção em doca seca
Antes de zarpar da costa, é necessário colocar o navio em ordem. No nosso caso, isso significará atualizar o ambiente de trabalho AUTOMATIC1111 para a versão 1.6.0 atual (no momento em que este artigo foi escrito) – e ao mesmo tempo verificar quão bem o alardeado suporte para SDXL 1.0 está organizado nesta versão, uma vez que reclamamos da falta desta opção na versão 1.5.1. O Periplus, que usaremos no futuro para explorar o espaço latente, será baseado no modelo SD 1.5, já que é o mais estudado até agora pela comunidade de entusiastas do desenho de IA (e é executado no hardware existente muito mais rápido do que seu sucessor superdimensionado), mas os princípios e ferramentas gerais dessa navegação permanecerão corretos para todos os modelos. Pelo menos dentro do ambiente de trabalho selecionado:
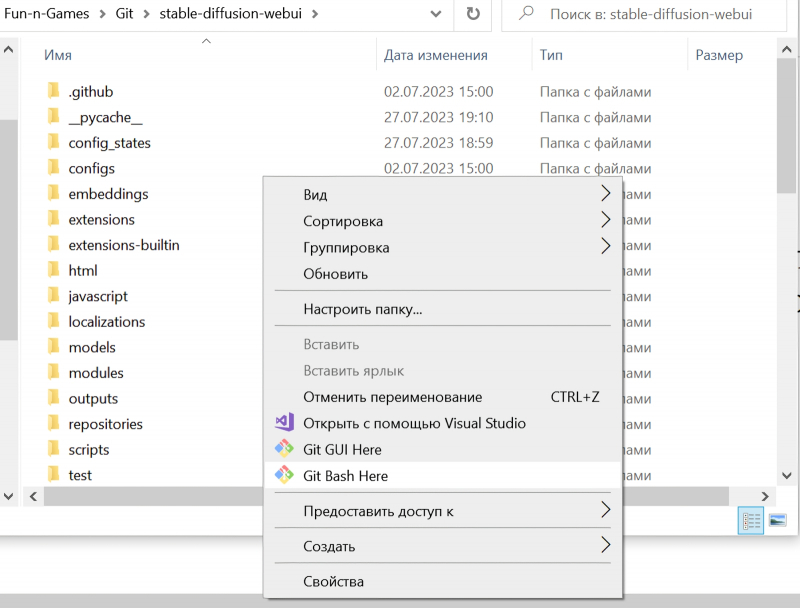
Então, antes de tudo, vamos atualizar a versão mais recente do ambiente de trabalho com uma solicitação direta ao GitHub de uma forma já familiar aos leitores de nossos “Workshops” anteriores – você só precisa primeiro ter certeza de que este software não está em execução no momento. Tendo aberto a pasta na qual o AUTOMATIC1111 foi instalado anteriormente no Windows Explorer, clique com o botão direito e selecione “Git Bash Here” no menu que aparece. A janela do aplicativo de linha de comando instalado junto com o ambiente de trabalho será aberta e você precisará inserir literalmente duas palavras nela,
Puxa
Em seguida, pressione Enter. Lá, na janela da linha de comando, o sistema informará sobre a atualização realizada – e, provavelmente, oferecerá novamente a atualização do aplicativo de serviço pip. Se estiver com vontade, você pode atualizar – já realizamos esse procedimento durante a primeira instalação do AUTOMATIC1111.
Lembremos que durante o treinamento de modelos de difusão latente, o espaço latente do autoencoder, que atribui determinadas imagens aos tokens (nos quais a entrada de texto é convertida), é fixo. É por isso que, com a reprodução precisa dos parâmetros de geração, o padrão final pode ser reproduzido em outro PC de forma quase idêntica, às vezes apenas sem os estocásticos inevitavelmente adicionados em etapas individuais. Em outras palavras, teoricamente ainda é possível mapear com precisão o espaço latente; o único problema é o seu volume verdadeiramente imenso. Uma estimativa aproximada do número total de imagens potencialmente disponíveis para extração do espaço latente do modelo SD 1.5 fornece o valor 10 ^ 1010 – ou seja, dezenas elevadas à potência de 10 bilhões. 10 ao quadrado é cem, 10 elevado a nove é Um Bilhão, e aqui – 10 elevado a dez bilhões. É por isso que os entusiastas do desenho de IA têm que confiar em mapas em vez de mapas – isto é, essencialmente, na experiência dos pioneiros. E nós mesmos nos tornamos pioneiros para aqueles que virão a seguir.
Fica imediatamente claro que na versão 1.6.0 o ambiente de trabalho AUTOMATIC1111 está focado na operação de modelos SDXL: ao lado do menu suspenso “Highres. fix”, que já estava presente, apareceu outro, “Refiner”, para escolha de modelo de fecho de porta.
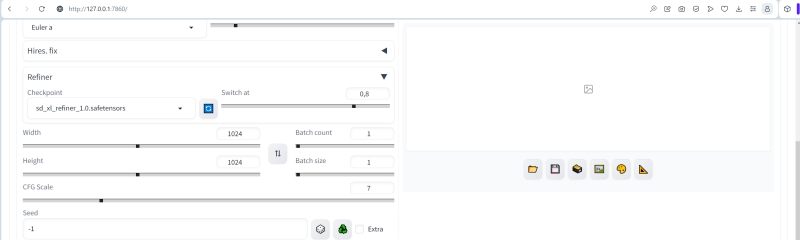
Para verificar como nosso ambiente de trabalho padrão funciona com “Oversized”, vamos definir o modelo base sd_xl_base_1.0.safetensors nos menus suspensos na parte superior, VAE – sdxl_vae.safetensors, definir “Clip skip” para “1” por enquanto (embora para muitos pontos de verificação pré-treinados SD 1.5 seus criadores recomendem o uso de “2”). Deixamos o parâmetro “Switch at” no valor recomendado de 0,8 – no último “Workshop” explicamos porque os desenvolvedores do SDXL recomendam que os primeiros 80% das etapas de geração sejam deixados para o modelo base e apenas os últimos 20% para o modelo base. mais perto. Definimos os parâmetros de tamanho da tela como padrão para SDXL 1024 × 1024.
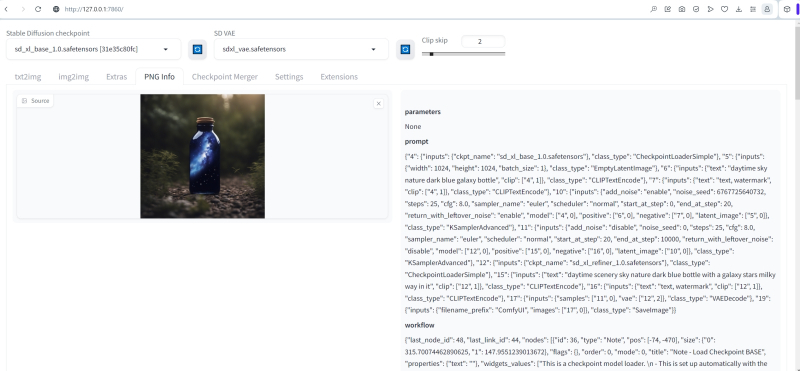
Agora vamos tentar reproduzir a imagem sdxl_refiner_prompt_example, retirada da coleção oficial de exemplos de geração do ComfyUI + SDXL. Os parâmetros com os quais esta geração foi realizada estão escritos no cabeçalho do arquivo PNG e, portanto, arrastando a imagem correspondente do Explorer com o mouse para a janela da aba PNG Info demonstra todos esses parâmetros em um formato acessível para estudo por um operador ao vivo. É verdade que simplesmente clicar no botão “Enviar para txt2img” e transferi-los para a aba de geração não funcionará: o formato dos campos de texto no ComfyUI é diferente. Mas isso não é assustador: é fácil copiar e transferir manualmente (ou definir manualmente com controles deslizantes adequados na interface AUTOMATIC1111) os seguintes valores:
Dica positiva: céu diurno natureza garrafa galáxia azul escuro (há, no entanto, uma sutileza aqui: no ciclograma ComfyUI, diferentes dicas positivas são especificadas para a base e para o mais próximo: para o primeiro – aquele dado anteriormente; para o segundo – “cenário diurno céu natureza garrafa azul escuro com uma galáxia estrelas via láctea” AUTOMATIC1111 não fornece indicação separada de dicas, então por enquanto vamos nos concentrar na primeira, mais curta),
Negativo: texto, marca d’água,
Semente: 6767725640732,
Número de etapas: 25,
CFG: 8,0,
Agendador (amostrador): euler.
E lançamos com esses parâmetros para execução.

À esquerda está um modelo de galáxia em uma garrafa do manual para usar o modelo SDXL no ambiente de trabalho ComfyUI (fonte: GitHub), à direita está a geração em AUTOMATIC1111 com o mesmo modelo e parâmetros especificados no texto
Tudo levou cerca de 6 minutos, dos quais uma quantidade significativa de tempo – pelo menos um minuto e meio – foi gasta carregando o modelo mais próximo na memória de vídeo e, em seguida, aproximadamente a mesma quantidade de tempo – alterando-o de volta para o modelo básico. Em geral as imagens são muito semelhantes, mas há claramente menos detalhes naquela feita com AUTOMATIC1111. Vamos agora tentar uma dica mais longa – aquela que foi originalmente alimentada mais perto:
Cenário diurno céu natureza garrafa azul escura com uma galáxia estrelando a Via Láctea

A imagem certa é a mesma de antes; esquerda – geração em AUTOMATIC1111 com dica estendida
Pode ter havido mais detalhes, mas agora as fotos são bem diferentes!
Desista das amarras!
Isto significa que a questão não está na dica (o mais próximo, em qualquer caso, faz essencialmente o mesmo trabalho de “acabamento” do VAE, portanto fundamentalmente não pode influenciar a composição da imagem), mas, muito provavelmente, na implementação de SDXL como tal. Suspeita-se que na versão 1.6.0 o modelo básico transfira para o mais próximo após completar 80% das etapas uma imagem totalmente acabada – em vez de deixar nela vestígios não apagados de ruído latente, que, durante o processamento normal do ciclograma no mesmo ComfyUI, torna-se a base para um trabalho mais produtivo dos modelos refinadores.
Vamos tentar outro método – implementar a cocriação da base e do close usando um script externo, Refiner (extensão webui). Em princípio, você não precisa seguir o link fornecido: esta extensão é instalada a partir do próprio ambiente de trabalho. Basta selecionar a subguia “Disponível” na guia “Extensões”, clicar no botão laranja “Carregar de:” ali,
E (após uma pequena pausa para atualização) encontre a palavra “refinador” na página resultante com extensões – simplesmente via “Ctrl” + “F” no navegador. No momento em que escrevo este artigo, existe apenas um desses scripts, é impossível cometer um erro: clique no botão cinza “Instalar” na linha correspondente.
E então, voltando à subaba “Instalado”, registramos o fato da instalação bem-sucedida do script. Para ter certeza, você pode verificar se o apelido do autor, wcde, presente no link para a página inicial deste projeto no GitHub é o mesmo do endereço direto deste projeto acima. Agora só falta clicar em “Aplicar e reiniciar UI”.
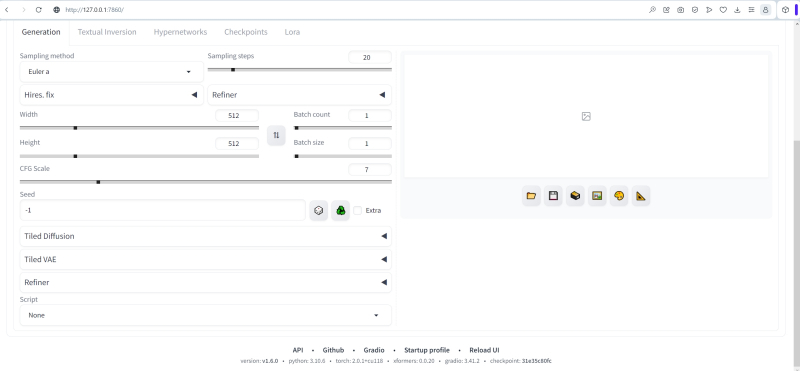
Depois de atualizar a interface, outro menu suspenso “Refiner” apareceu na parte inferior da página em nossa aba principal de trabalho “txt2img” – é isso que você deve usar a partir de agora. IMPORTANTE: sobre sua implementação padrão, aquela localizada ao lado de “Highres. fix” deve ser esquecido como um pesadelo, pelo menos até que o autor do AUTOMATIC1111 consiga fazê-lo funcionar corretamente.
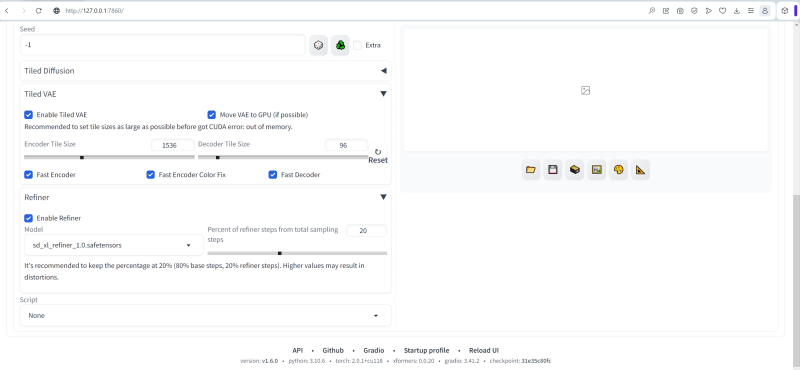
E eu gostaria de acreditar que o Refiner (webui Extension) irá agora nos demonstrar exatamente como isso deve ser feito. Nós o ativamos, agora indicando aqui o modelo mais próximo, e, claro, restauramos manualmente todos os outros parâmetros. A propósito: o autor do script recomenda usar o Tiled VAE com ele em qualquer placa de vídeo com menos de 12 GB de memória, o que é exatamente verdade no caso do nosso sistema de teste (GTX 1070, 8 GB). O que há de bom no script Tiled VAE é que ele não desperdiça recursos do sistema. Se a imagem for muito pequena para carregá-la na memória de vídeo, cortando-a em pedaços (os blocos reais), o Tiled VAE ativado exibirá uma mensagem sobre isso na linha de comando do servidor e simplesmente pulará a execução desta tarefa. Então vamos habilitar este script, não esquecendo de marcar a caixa ao lado de “Fast Encoder Color Fix”,
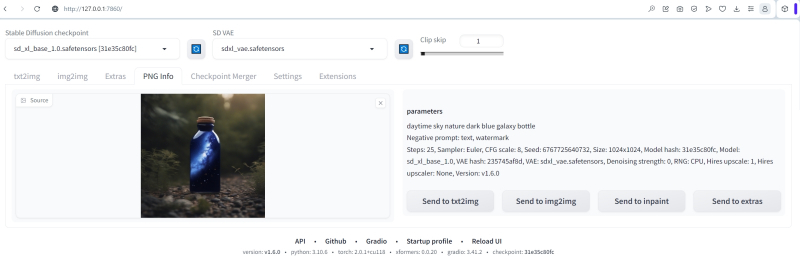
Como opção, para não inserir manualmente todos os parâmetros novamente após atualizar a interface web, você pode fazer upload de uma imagem (com uma pequena dica positiva) criada anteriormente em AUTOMATIC1111 com SDXL 1.0 e uma chamada integrada para o mais próximo no “PNG Aba Info” – e envie para a aba “txt2img” ” Curiosamente, o menu suspenso padrão “Refiner” permanecerá desativado: o ponto de verificação não foi carregado automaticamente – e não é indicado na descrição do texto do arquivo PNG. Mais uma prova de que o desenvolvimento do ambiente de trabalho para compatibilidade SDXL foi realizado… bem, digamos, com pressa. Agora tudo o que resta é verificar todos os parâmetros novamente, fechar o menu suspenso padrão “Refiner”, certificar-se de que tanto o “Refiner” quanto o “Tiled VAE” inferiores estão ativos e, em seguida, iniciar a geração.
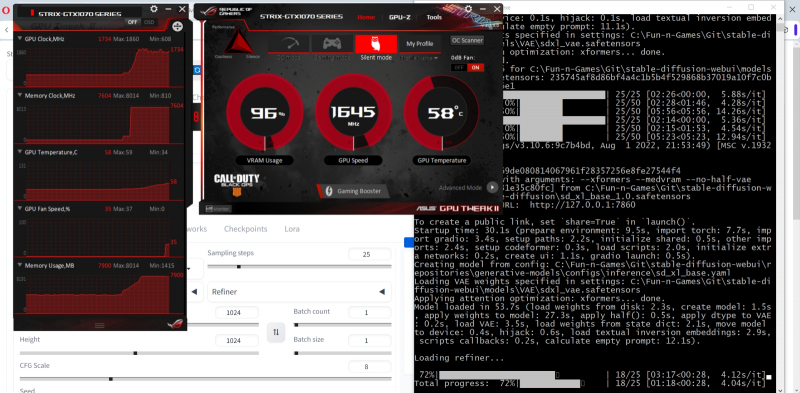
Aqui leva cerca de um minuto para pré-carregar o mais próximo, mas então as coisas se movem com mais vigor – quase o mesmo que no caso do ComfyUI. Em ambos os ambientes de trabalho (lembre-se de que nosso sistema de teste possui apenas 8 GB de RAM de vídeo, enquanto a base e o refinador para SDXL 1.0 ocupam aproximadamente 6 GB cada), a implementação da mudança de pontos de verificação em tempo real claramente não é feita inteiramente, como é feito por padrão AUTOMATIC1111 versão 1.6.0 (remova 6 GB da RAM de vídeo – adicione novos 6 GB), mas de alguma forma mais eficiente. Como resultado, a renderização completa real da imagem – sem levar em conta o carregamento inicial do close – leva aproximadamente 2,5 minutos contra quase 5,5 para a implementação padrão deste script.

A imagem da esquerda foi gerada em AUTOMATIC1111 com o modelo SDXL 1.0 usando um script Refiner externo (extensão webui), enquanto a da direita, como nos dois exemplos anteriores, foi gerada usando a implementação mais próxima incorporada na versão 1.6.0
E aqui já há visivelmente mais detalhes do que ao implementar uma corrida com um fecho de porta padrão – e até um pouco mais do que no ComfyUI (subjetivo, mas ainda assim). A diferença aqui provavelmente é feita pela ausência de prompts separados para a base e mais próxima, e pelo uso do parâmetro –medvram no arquivo em lote para iniciar o AUTOMATIC1111 – mas em qualquer caso, a opção com o script Refiner (extensão webui) reproduz claramente de forma mais adequada o que foi proposto pelos desenvolvedores do diagrama Stability.ai do modelo SDXL 1.0. Ou seja, primeiro – geração preliminar de uma imagem com ponto de verificação básico, depois transferência da imagem “não cozida” (com resquícios de ruído latente) para uma imagem mais próxima – e no final, execução do VAE com base no resultado do refinador modelo. Portanto consideraremos oficialmente o ambiente de trabalho AUTOMATIC1111 na versão 1.6.

Fonte: geração de IA baseada no modelo SDXL 1.0
No entanto, ainda não há correspondência completa entre as implementações SDXL aqui e no ComfyUI. A título de exemplo, vamos tentar reproduzir uma imagem mais complexa criada no ambiente de trabalho “macarrão”. Os parâmetros para sua criação podem ser estudados na aba “PNG Info”:
Escolha: protovisionXLHighFidelity3D_beta0520Bakedvae.safetensors,
Dimensões da tela: 1344 × 768,
Dica positiva:
Foto grande angular de steampunk [nave espacial | dirigível | veleiro] flutuando sobre ilhas pitorescas em um vasto oceano,
, Latão brilhante, cobre oleoso, velas membranosas, engrenagens e rebites, relógios desconstruídos, rodas dentadas, mecânica, mecanismo de relojoaria, muitas peças, ferrugem, pátina,
, Ampla profundidade de campo, mapeamento radiante, reflexos, refração de luz, dispersão subterrânea, sombras detalhadas, traçado de raios, alta faixa dinâmica, sombras e realces nítidos,
, Proporção áurea, regra dos terços, obra-prima incomparável, deslumbrante, atmosfera elaborada, muito complexo, hiper-realista, colorido, hipnotizante, épico, dinâmico, dramático, vibrante, meticulosamente detalhado, intrincado, majestoso)
(Linhas vazias e vírgulas no início das linhas separam visualmente os blocos de texto relacionados à descrição da cena, detalhes de sua composição, características de incorporação, etc.; o formato da entrada nave|dirigível|veleiro significa que as entidades listadas através de linhas verticais se alternam: na primeira etapa, o sistema gera uma nave, na segunda, um dirigível, na terceira, um veleiro, na quarta, um nave espacial novamente, então o resultado é uma combinação relativamente orgânica de todos os três)
Negativo: moldura de tela, EUA, pintura, desenho, esboço, cartoon, anime, mangá, render, CG, 3d, marca d’água, assinatura, rótulo (o que os EUA fizeram de errado neste caso é que o modelo utilizado prefere desenhar bandeiras no mastros por algum motivo principalmente americanos),
Semente: 123456991,
Número de etapas: 50,
CFG: 8,0,
Mas então é interessante: nos parâmetros do ComfyUI, “sampler_name” – “dpmpp_sde_gpu” – e “scheduler” – “karras” são especificados separadamente; ou seja, os conceitos de escalonador e seletor são separados neste ambiente de trabalho, enquanto em AUTOMATIC1111 são especificadas algumas de suas combinações pré-compostas, restando apenas escolher a mais adequada; neste caso DPM++ 2M SDE Karras.
E vamos ver o que acontece.

Fonte: geração de IA baseada no modelo SDXL 1.0
Demorou quase o mesmo tempo para gerar a mesma imagem no ComfyUI – mais de 7 minutos. Mas o resultado é significativamente diferente, embora próximo. Isto pode ser devido a diferenças na implementação do agendador/seletor; talvez porque a dica especifique a alternância de entidades através do operador “|”, e seja de alguma forma implementada de forma diferente nesses dois ambientes de trabalho. De uma forma ou de outra, para experimentos com SDXL 1.0, faz sentido deixar o ComfyUI por enquanto.
Nesse ínterim, retornaremos ao AUTOMATIC1111 – e continuaremos conduzindo nossa jornada, para a qual estudaremos um poderoso kit de ferramentas integrado a este ambiente de trabalho como scripts de geração.
⇡#Saindo do porto
Assim, para estudar as técnicas básicas de orientação no espaço latente utilizando os contornos da costa e o comportamento das aves (análoga à antiga navegação ao longo do periplus sem bússola e mapa), voltemos ao SD 1.5. Fazer isso na interface AUTOMATIC1111 é tão fácil quanto descascar peras: desmarque “Ativar” no menu suspenso Refiner (extensão webui) na parte inferior da página principal da web, feche este menu e altere o VAE para um daqueles projetado para o “Lortorka” – por exemplo, para o clássico vae-ft-mse-840000-ema-pruned – e também selecione o ponto de verificação apropriado. Mas qual exatamente? E com quais parâmetros de serviço devemos começar a gerar? Sim, e talvez o mais importante: como construir um prompt de texto para obter imagens esteticamente aceitáveis com pelo menos uma garantia mínima?

Sobre a questão das profundezas escuras do espaço latente. Ambas as pistas para esta imagem consistem em uma palavra: positivo – nada, negativo – qualquer coisa (fonte: geração de IA baseada no modelo SD 1.5)
Vamos começar com o fato de que o objetivo determina os meios: se o modelo de IA precisar representar alguma imagem abstrata ou mesmo surreal, você pode se limitar a um ponto de verificação padrão básico (que na instalação AUTOMATIC1111, como leitores de o primeiro “Workshop” sobre este tópico provavelmente lembra, nós o renomeamos para modelo .safetensors) e dê asas à sua imaginação em termos de dicas e seleção de outros parâmetros, e então execute o sistema no modo “Gerar para sempre”: algo adequado certamente aparecerá em um prazo razoável. É outra questão se você precisa de uma imagem em um determinado estilo – pixel, digamos, ou um desenho a caneta, ou um esboço em aquarela, e até mesmo com objetos ou criaturas bastante reconhecíveis: aqui você terá que mexer mais a sério. Mas para esses casos hoje existe uma excelente ajuda – LoRA,
Acontece que talvez a tarefa mais difícil quando aplicada ao desenho com IA seja a geração de imagens realistas, como se tiradas com uma câmera convencional (filme ou digital), com objetos e personagens de aparência verossímil. A tese provavelmente não é controversa, mas – de acordo com sentimentos internos – há muito mais imagens de IA estilizadas de sucesso na Internet (como mangá/anime, como miniaturas de livros medievais, como pinturas impressionistas, etc.) do que aquelas que imitam de forma confiável fotografias banais . Ou não muito banais – com efeito de pareidolia, por exemplo.

Você não vê nesta imagem, que à primeira vista não é nada notável, alguma palavra escrita em quatro letras bastante grandes? E se você se afastar ainda mais do monitor? (Fonte: Reddit)
Até agora, um consenso bastante estável surgiu na comunidade de entusiastas do desenho de IA: quanto mais antigo for o ponto de verificação (a fronteira convencional entre “velho” e “novo” vai aproximadamente de julho a agosto de 2023), mais detalhada e sofisticada será a dica é necessário para resultados satisfatórios com base nele apareceu com mais frequência. Os modelos posteriores são treinados, como regra, em matrizes de imagens anotadas, cuidadosamente selecionadas de tal forma que a saída mesmo de uma dica curta (3-5 palavras) com uma semente aleatória teria grande probabilidade de ser digna de salvar a imagem resultante – e não envie para o “Lixo” (talvez este seja o único, embora em grande parte subjetivo, critério para distinguir uma geração “bem-sucedida” de uma “malsucedida”). Outro ponto sutil:
Isso significa que para uma comparação confortável (proprietários satisfeitos de uma GPU com memória de vídeo de 16 GB ou mais podem adicionar “e rápido” aqui com o coração leve) de como vários parâmetros afetam a implementação de uma dica testada pelo operador, um é necessária uma ferramenta apropriada – que permitiria não altere manualmente os parâmetros de geração repetidas vezes – e depois compare uma imagem com outra por um longo tempo e tediosamente – mas automatize esse procedimento. Felizmente, neste aspecto, o AUTOMATIC1111 faz jus ao seu nome: este tipo de ferramenta é implementada nele como padrão – e é chamada de “script X/Y/Z”.

A ferramenta “X/Y/Z script” permite gerar automaticamente uma série de imagens a partir do mesmo conjunto geral de dados de entrada, variando apenas alguns parâmetros (neste caso, passos e CFG) e apresentando os resultados na forma de um tabela conveniente (fonte: geração de IA baseada no modelo SD 1.5)
Então, vamos começar compilando uma dica de tamanho médio: não a mais simples (“uma galinha robô”, digamos) e nem a mais complicada (“1girl, obra-prima. melhor qualidade, solo, olhando para o espectador, realista, 8k. foco nítido . cabelo longo, sorriso, corpo inteiro, alta resolução, altamente detalhado, complexo, ilustração, em pé, blush. iluminação cinematográfica, franja, hdr. profundidade de campo, extremamente detalhado, absurdos, alta qualidade, olhos azuis, foto bruta, olhos detalhados, cabelo curto, cabelo preto, decote, rosto detalhado…” – e isso é só o começo!), inspirado neste post:
Uma garota celta alegre (com uma armadura enferrujada) (caminhando sobre um dragão: 1.3) em frente a um castelo distante, (selfie em close: 1.4), foto espontânea, atmosfera elaborada, meticulosamente detalhada
E vamos fazer o negativo assim:
Anime, desenho animado, pintura, ilustração, porta-retratos, assinatura, marca d’água, (pior qualidade, baixa qualidade, qualidade normal:1,5), nude
Tecnicamente, poderíamos ter evitado adicionar “nude” à dica negativa; afinal, a publicação tem classificação “18+”. Mas minimizar por padrão a possibilidade de nudez aparecer nas gerações de IA é considerado uma boa forma – se o operador não a visar inicialmente especificamente, é claro. Sim, muitos postos de controle (especialmente recentemente) são treinados para gerar imagens de pessoas sem roupas somente se isso for indicado direta e explicitamente na parte positiva da dica de ferramenta – mas também há exemplos opostos.
Então, qual ponto de verificação você deve escolher, já que já existem muitos deles, principalmente para SD 1.5? Existem duas maneiras de chegar aqui. Primeiro: estude cuidadosamente o já mencionado Civitai, onde as páginas de checkpoint são acompanhadas de imagens criadas com a ajuda deles (e muitas vezes junto com todos os parâmetros de geração: dicas, planejador, CFG, número de etapas). Se você gosta de muitas fotos, baixe este modelo e experimente com suas próprias dicas. A propósito, geralmente os autores (que se dividem em treinadores que gastam os recursos de hardware de seus PCs no treinamento adicional de modelos que não lhes agradam em conjuntos de imagens cuidadosamente selecionados e compiladores que “mesclam” dois ou mais já prontos pontos de verificação em um) escreva nos comentários quais parâmetros de geração são ideais para suas criações. Com base nessas dicas,
⇡#Ao longo de praias familiares
No entanto, seguiremos um caminho diferente: compilaremos automaticamente um periple que nos permitirá selecionar a combinação ideal (ou próxima a ela) – bem, para começar, um ponto de verificação e um amostrador. A propósito, os mais recentes chegaram no AUTOMATIC1111 1.6.0 em comparação com as versões anteriores deste ambiente de trabalho – faz sentido experimentá-los.
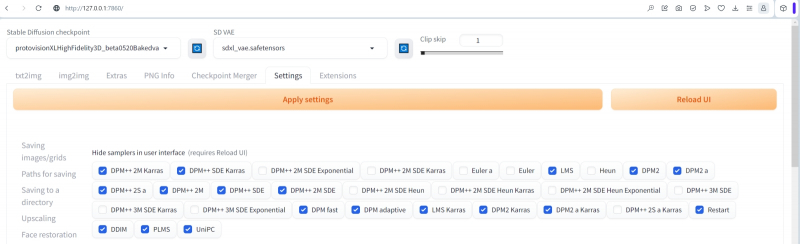
Para não ficarmos confusos sobre quais agendadores testar e quais não, deixaremos disponíveis para seleção apenas aqueles que nos interessam: os mais novos e alguns antigos comprovados. Para isso, na seção correspondente das configurações (veja o primeiro “Workshop” de desenho AI) deixaremos apenas os seguintes desmarcados (e os marcados, ao contrário, ficarão ocultos):
Exponencial DPM++ 2M SDE
DPM++ 2M SDE Karras
Euler e
Euler
Ei
DPM++ 2M SDE Ei
DPM++ 2M SDE Olá Karras
DPM++ 2M SDE Sim Exponencial
DPM++ 3M SDE
DPM++ 3M SDE Karras
Exponencial DPM++ 3M SDE
DPM++ 2S para Karras
Após o novo particionamento, você precisará, como sempre ao alterar as configurações, clicar em “Aplicar configurações” e depois em “Recarregar UI”.
E aqui estão os modelos envolvidos nos próximos testes:
Quais parâmetros de serviço escolher para testes preliminares são comuns a todas as combinações de pontos de verificação e escalonadores? Sim, os mais utilizados no apêndice SD 1.5:
Número de etapas – 25,
CFG — 6,
Dimensões – 512 × 768 (orientação retrato).
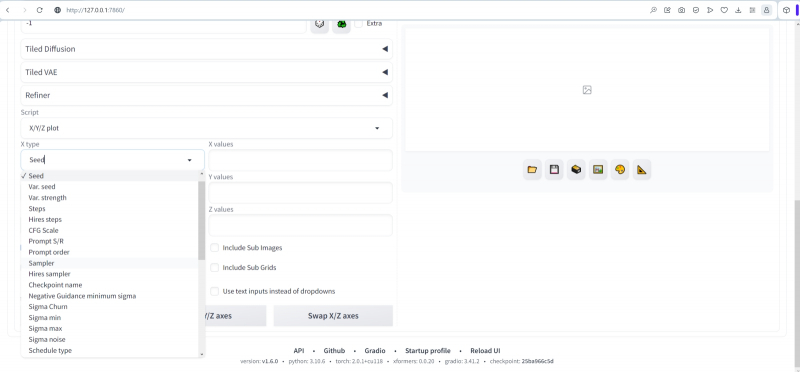
E agora começa a parte mais interessante – a própria compilação do periplus: agora indicaremos ao ambiente de trabalho as diretrizes pelas quais ele navegará nas ondas furiosas do espaço latente – e retornaremos com as fotos obtidas durante esta jornada. Role até a parte inferior da página da web e abra o menu suspenso “Script”. Nele ativamos “X/Y/Z Plot” e será possível selecionar mais vários parâmetros para cada uma das variáveis. Horizontalmente (“tipo X”) teremos pontos de verificação, “nome Checkpioint”. Outro menu suspenso aparecerá, permitindo que você selecione manualmente os que você precisa na lista de disponíveis.
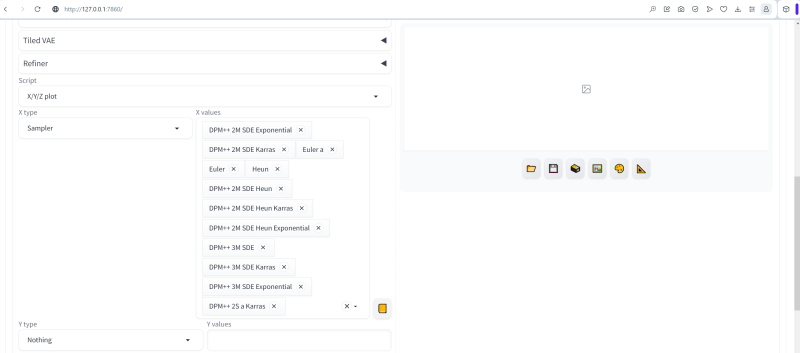
Colocaremos os planejadores verticalmente (“tipo Y”). Como precisamos de todos os disponíveis (só os deixamos visíveis nas configurações um pouco antes), basta clicar no botão com um retângulo laranja à direita do campo “Valores Y” – seu conjunto completo será adicionado automaticamente.
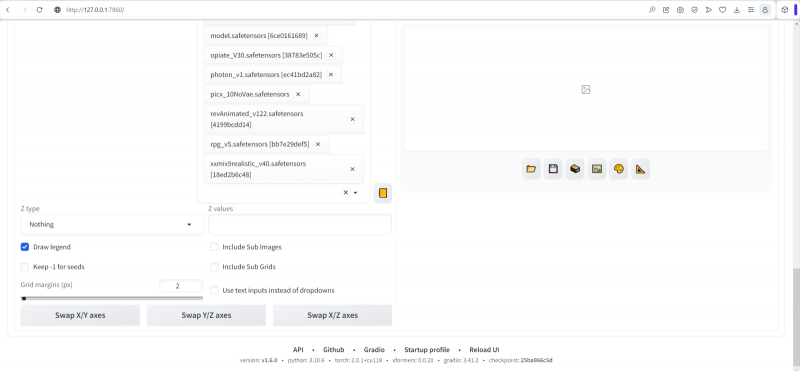
Não removemos a marca de seleção de “Legenda do desenho”; “Margens da grade (px)” está definido como 4 – um valor completamente razoável para o intervalo entre imagens adjacentes na tabela. Não tocamos em outros parâmetros por enquanto.
E vamos lá! O sistema promete gerar as 180 imagens (12 × 15) planejadas em menos de algumas horas. Considerando que cada um é calculado em 30-50 segundos, dependendo do amostrador, esta é uma estimativa totalmente confiável. A carga da GPU é inferior a 60% – e, aliás, faz sentido ativar o “modo silencioso”, um modo de economia de energia no painel de controle do adaptador gráfico: este é um ponto importante para os entusiastas do desenho de IA. Uma GPU que funciona com frequência e consome muita energia, mas a soma ponderada (a principal operação no cálculo de modelos generativos) é um processo puramente aritmético e não requer nenhum overclock. Por isso é recomendado reduzir o desempenho da placa de vídeo ao trabalhar com SD/SDXL por muito tempo: o tempo de geração de imagens praticamente não aumentará, mas a conta de luz será pelo menos um pouco menor.

Fonte: geração de IA baseada no modelo SD 1.5
Já a partir deste periplus extremamente áspero fica muito mais claro onde você pode navegar livremente, explorando a extensão (quase) infinita do espaço latente, e onde armadilhas, tempestades, calmarias e outras Cilas e Caríbdis digitais aguardam o azarado entusiasta. A primeira conclusão, que chama a atenção de imediato: várias fotos saíram “não cozidas”, salpicadas de manchas de formas e cores não naturais. Isso geralmente indica um número insuficiente de etapas de amostragem (parâmetro steps): como você pode ver, várias combinações de “ponto de verificação + agendador” requerem um número mais significativo de iterações. Em outros casos, as figuras da menina (e principalmente do dragão) ficam muito distorcidas e, em alguns lugares, uma delas está completamente ausente. Isto pode indicar parcialmente o subtreinamento deste posto de controle específico nas fotografias anotadas de dragões (e de onde eles vieram, desculpe?
Vamos agora selecionar uma das imagens com artefatos óbvios – bem, digamos, gerada pelo checkpoint Photon 1.0 com o agendador (apenas um dos recém-adicionados no AUTOMATIC1111) DPM++ 3M SDE. Há uma garota, e um dragão, e o castelo está no lugar, e a expressão em seu rosto é bastante alegre, e em geral a composição parece uma selfie – em uma palavra, a dica está incorporada quase perfeitamente. Apenas a combinação passos/CFG nos decepcionou. Vamos tentar compor outro périplo – explorando agora essa combinação em suas diversas formas.
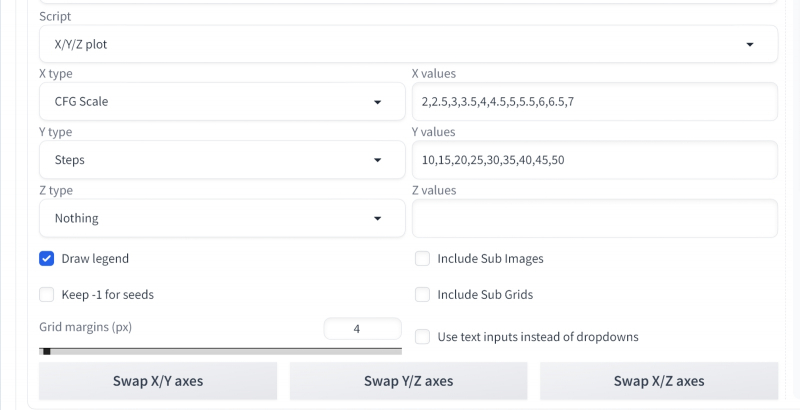
Deixamos a dica igual, selecione o checkpoint Photon, atribua o valor Seed usado na geração anterior – 989666162 (você pode obtê-lo enviando a imagem para “PNG Info”, ou pode apenas olhar o nome do arquivo: se você tiver feito os passos com as configurações que descrevemos no terceiro “Workshop”, ele simplesmente conterá esta mesma semente separada por um hífen após o número de série do arquivo na pasta atual), selecione o agendador DPM++ 3M SDE. Role a página até o final novamente e nas configurações do script “Plotagem X/Y/Z” altere “Tipo X” para Escala CFG com os seguintes valores:
2,2,5,3,3,5,4,4,5,5,5,5,6,6,5,7
E «tipo Y» — nas etapas:
10,15,20,25,30,35,40,45,50
A ausência de espaços é importante aqui: as vírgulas separam diretamente os valores, e as frações decimais, segundo a tradição anglo-americana, são indicadas por pontos. Começamos a geração novamente.

Fonte: geração de IA baseada no modelo SD 1.5
Fica imediatamente claro que CFGs grandes são contra-indicados para esta combinação “ponto de verificação + agendador”, e aumentar o número de etapas a partir de um determinado limite para cada CFG não leva a um aumento dramático na qualidade da imagem. Uma espécie de “cunha de adequação” é claramente visível: o retângulo CFG/Steps é cortado aproximadamente na diagonal (neste caso, ao longo da linha, condicionalmente, de 4,0/10 a 7,0/25), à esquerda e abaixo da qual existem imagens de qualidade bastante aceitável, à direita e acima, estão distorcidas por artefatos. Como você pode ver, Photon, em colaboração com DPM++ 3M SDE, permite que você produza imagens realistas e bastante detalhadas muito rapidamente (10 iterações equivalem a apenas cerca de 10 s em uma placa de vídeo GTX 1070!).
Uma vantagem adicional desta abordagem: com CFGs pequenos, o “potencial criativo” da IA generativa é mais libertado – isto é, seguir as instruções é o menos literal. Isso significa que ao iniciar a geração infinita com tais parâmetros e com uma semente aleatória, uma imagem por vez (o modo “Gerar para sempre”), você pode capturar tantas coisas inesperadas e incomuns do espaço latente. É claro que uma cunha deste tipo específico é definida apenas para esta combinação de ponto de verificação e planejador; será diferente para outras combinações. Mas você pode e deve trabalhar com isso!
⇡#Indo para um farol distante
Vamos agora tirar uma foto com CFG=4 e passos=45 – o giro da cabeça da heroína é muito dinâmico aí – e vamos ver quais outras possibilidades de compilação de períbulos espaciais latentes são oferecidas pelo script “X/Y/Z Plot”.
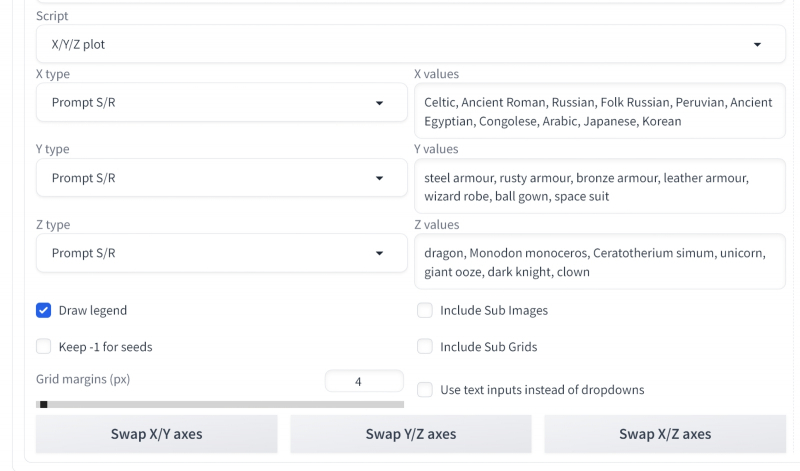
Vamos tentar outro tipo de variável ao criar tabelas – “Prompt S/R”. S neste caso é pesquisa, R é substituição. Isso significa que o sistema encontra na dica do texto fonte uma sequência de caracteres que corresponde ao primeiro dos indicados aqui separados por vírgulas, e primeiro a gera com ela. E então ele faz uma segunda passagem – pegando a segunda sequência e substituindo a primeira por ela. Ou seja, se selecionarmos a opção “Prompt S/R” como o “tipo X” e especificarmos, por exemplo, tal cadeia de sequências separadas por vírgulas (tudo depende da sua imaginação) –
Celta, Escandinava, Russa, Peruana, Egípcia Antiga, Congolesa, Árabe, Coreana
Então a primeira geração terá uma dica positiva
Uma garota celta alegre (com uma armadura enferrujada) (caminhando sobre um dragão: 1.3) em frente a um castelo distante, (selfie em close: 1.4), foto espontânea, atmosfera elaborada, meticulosamente detalhada
Segundo – de
Uma garota escandinava alegre (com uma armadura enferrujada) (caminhando sobre um dragão: 1.3) em frente a um castelo distante, (selfie em close: 1.4), foto espontânea, atmosfera elaborada, meticulosamente detalhada
Terceiro – de
Uma garota russa alegre (com uma armadura enferrujada) (caminhando sobre um dragão: 1.3) em frente a um castelo distante, (selfie em close: 1.4), foto espontânea, atmosfera elaborada, meticulosamente detalhada
Etc.

Fonte: geração de IA baseada no modelo SD 1.5
Pouco de! Não é à toa que o script se chama “X/Y/Z Plot”: ele permite construir tabelas-períodos visuais para três variáveis. Anteriormente, usávamos apenas dois – mas por que não experimentar todas as possibilidades oferecidas? Vamos escolher as seguintes opções para “Tipo Y”: “Prompt S/R”:
Armadura enferrujada, armadura de bronze fosco, armadura de couro, manto elegante revelador, terno justo neon brilhante, vestido de baile com babados, armadura de fantasia brilhante
E para “tipo Z” –
Dragão, urso polar, robô mecânico, pônei louco, água-viva gigante, fênix ardente, palhaço fantasma

Todo mundo adora selfies com robôs! (Um dos fragmentos da grade de imagem anterior; fonte – a mesma geração de IA baseada no modelo SD 1.5)
Vamos iniciá-lo – a execução levará cerca de cinco horas. O resultado, claro, não é uma tabela cúbica (como ela pode ser exibida em um monitor plano?), mas uma sequência convenientemente organizada de tabelas retangulares. Além de cada um deles separadamente – para facilitar a visualização.
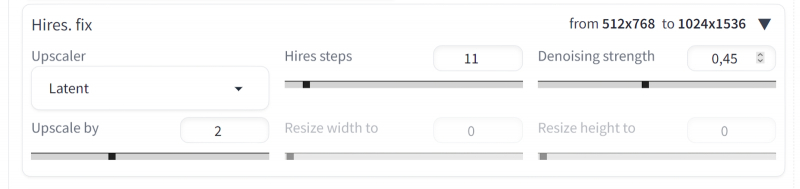
Agora vamos voltar ao menu suspenso “Contratações. fix”, que está localizado próximo ao menu padrão (e não funcional na versão 1.6.0) “Refiner” para SDXL. Em essência, um upscaler é um “aumento” automático de resolução com maior detalhe; Por “correção de alta resolução” é exatamente isso que se entende – pode ser considerado um análogo do mais próximo para SD 1.5, trabalhando apenas com uma imagem totalmente acabada da iteração anterior, e não com vestígios residuais de ruído latente. Vamos abordar as configurações do upscaler deste ponto de vista: duplicaremos a imagem em ambos os lados, e para simular o trabalho do close, definiremos o número adequado de passos (11, já que 11+45=56, e 20% de 56 com arredondamento é exatamente 11). É verdade que o valor correto da força de redução de ruído (força de redução de ruído) é difícil de adivinhar,
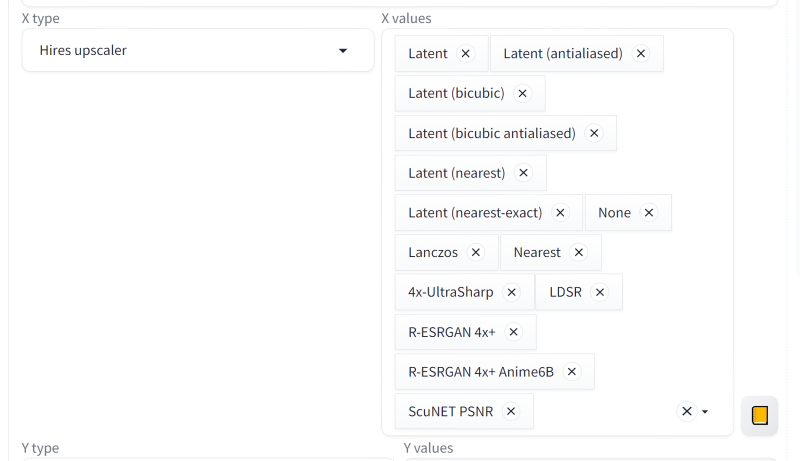
Bem, vamos tentar manualmente, alterando apenas o próprio algoritmo de redução de ruído durante o dimensionamento – este é o “Hires. sofisticado”. O resultado será uma tabela unidimensional (vetor) de imagens com os mesmos parâmetros iniciais, mas diferentes upscalers. Este é para resistência de remoção de ruído = 0,45:

E este para força de remoção de ruído = 0,15:

Mesmo nessas miniaturas, é perceptível que em grandes valores de redução de ruído não há diferença particular entre os algoritmos de upscaling; em geral, todos funcionam bem – porém, da mesma forma, todos estragaram a mão que segurava o smartphone (o dedinho desapareceu em algum lugar). Se considerarmos a intensidade de remoção de ruído = 0,15, aproximadamente metade das imagens (no lado esquerdo da linha) estão repletas de artefatos. Acontece que se você deseja preservar a composição e os grandes detalhes da imagem original com a maior precisão possível, é melhor usar algoritmos da metade direita do vetor.

Resultados do dimensionamento da imagem com seed 989666162 e os seguintes pares de parâmetros Intensidade Upscaler/Denoising, da esquerda para a direita: Latente/0,45; 4x-UltraSharp/0,45; Latente/0,15; 4x-UltraSharp/0.15 (fonte: geração de IA baseada no modelo SD 1.5)
Especificamente para a imagem em que paramos – com seed = 989666162 – você pode navegar pela qualidade da exibição do dedo mínimo: a combinação ideal de uma força de redução de ruído de 0,15 e o algoritmo 4x-UltraSharp deve ser considerada (embora SwinR, por exemplo, também é bastante adequado, mas o mais próximo, digamos, tem um dedo mindinho torto).
De que outra forma você pode facilitar a navegação no espaço latente? Ele – ao contrário do mar real – em certo sentido está pronto para se adaptar à vontade e ao estabelecimento de objetivos do pesquisador: em outras palavras, existem maneiras de avançar no determinismo da composição artística criada pela IA generativa. O mais proeminente desses métodos hoje, ControlNet, merece consideração especial e detalhada, mas já entre as ferramentas incorporadas ao AUTOMATIC1111 há uma semelhança aproximada com ele, ou seja, a ferramenta de esboço “Sketch”. Ela é implementada como uma subguia no “img2img” tab e se destina a , para que, com base em um esboço (o conceito de “áspero” é bastante vago aqui), o sistema “esclareça” os contornos gerais da composição pretendida – e então preencha esses contornos com os produtos apropriados de o espaço latente.
O esboço pode ser feito até no MS Paint, mas instalaremos o conhecido “Photoshop com código aberto”, GIMP, daqui: https://www.gimp.org/downloads/. Sua instalação é simples e bastante rápida.
Após o lançamento, crie uma tela vazia 512 × 768, selecione a ferramenta “Lápis”, altere seu tamanho do original 50 para pelo menos 3 e comece a desenhar de fato. Que seja um esboço no estilo da pintura épica “O Semeador”, do camarada Bender (que é Ostap), está tudo bem – a IA nos ajudará. Um pouquinho mais tarde.
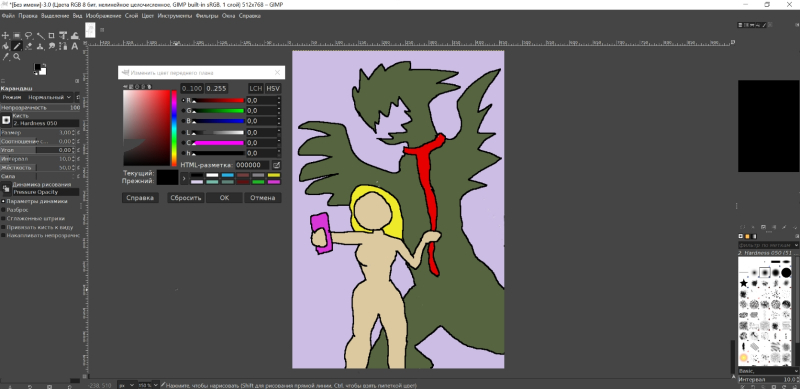
Poder! Força! A arte da composição! Em geral, a capacidade de desenhar não é de fundamental importância: é importante esboçar em termos gerais o que é mencionado na dica do texto (mesmo sem muitos detalhes: não há castelo neste esboço, por exemplo). A propósito, seria sensato selecionar tonalidades ao pintar de forma a garantir o máximo contraste entre os objetos vizinhos. Se você não colorir o esboço, será muito mais difícil para o sistema identificar objetos nele, especialmente os pequenos. Pois bem, os detalhes da pista em si devem ser levados em consideração: em particular, a garota deste desenho não está em vão vestida com cáqui deserto – essa cor geralmente se aproxima da combinação do marrom e do cinza claro (armadura enferrujada: ferro e couro). Se você preencher com, digamos, azul,
Agora vamos alimentar esta obra-prima para AUTOMATIC1111 exportando-a do GIMP em formato PNG e arrastando o arquivo de desenho para o campo correspondente na subguia “Esboço” com o mouse do Windows Explorer. Vamos definir o número de passos para 60, pois na aba “img2img” o número real desses mesmos passos que o sistema irá realizar durante o processo de geração é calculado como o produto da “Força de Denoising” por “Passos” – e com o o valor recomendado desta resistência é 0,7 em 60 passos, assim que obtivermos 42. Mas quais valores específicos devemos adotar para a resistência de remoção de ruído e CFG? “X/Y/Z Plot” nos ajudará novamente: ao longo do eixo X executamos CFG nas seguintes opções:
1,5,2,2,5,3,3,5,4,4,5,5,5,5,6,6,5,7
а по Y — Força de eliminação de ruído:
0,71,0,72,0,73,0,74,0,75,0,76,0,77,0,78,0,79,0,8

Fonte: geração de IA baseada no modelo SD 1.5
O efeito resultante é interessante – também uma espécie de “cunha de adequação”: quanto menor o CFG e a resistência à redução de ruído, mais servilmente o sistema segue o esboço que lhe é proposto. Mas em níveis elevados (canto inferior direito da tabela) ele se desvia cada vez mais significativamente. Talvez nos concentremos na opção com CFG=6 e força de Denoising = 0,72. Mas não porque exista uma imagem particularmente marcante, mas simplesmente pelo equilíbrio subjetivo do seguimento do esboço, por um lado, e do detalhe realista introduzido pelo modelo generativo (céu, nuvens, castelo, etc.), por outro.

Sobre a questão de quão grande é o papel do acaso na criação de imagens a partir de um esboço. Todos os parâmetros de geração para as imagens acima são completamente idênticos, exceto para a semente – da esquerda para a direita e de cima para baixo: 2854953743, 775689019, 3263462885, 3189244609, 2918779236, 2036605733, 2504183938, 1064413415 (fonte editar: geração de IA baseada em SD modelo 1.5)
E então – DE REPENTE! – sorte: foi gerada uma imagem (semente = 1064413415), na qual quase tudo está exatamente como no esboço original, até a coleira e a guia. E os dedos são bastante decentes! Agora você pode trabalhar o quanto quiser para finalizar a obra-prima resultante: usando a ferramenta “Inpaint” para editar detalhes individuais, no GIMP para corrigir manualmente o dedo mínimo muito longo na mão que segura o smartphone, depois aumentar a escala com mais detalhes e assim sobre. Não importa: o principal é que o objetivo final da nossa viagem pelo espaço latente com a periferia gerada ao longo do caminho tenha sido alcançado. A sugestão de texto tornou-se uma imagem gráfica que correspondia adequadamente ao conceito original, embora com uma muleta um tanto desajeitada na forma de um esboço grosseiro. Os sortudos que sabem desenhar, Assim, eles descobrirão a oportunidade de alcançar com rapidez e precisão o resultado desejado a partir do modelo generativo – bom, para nós, meros mortais, o ControlNet foi inventado para nossa alegria. Sobre o qual falaremos na próxima vez.