

No início de setembro de 2020, a NVIDIA estreou sua família de placas gráficas GeForce RTX 3000 de segunda geração baseada na arquitetura RTX de segunda geração – Ampere. A NVIDIA quebrou sua tradição quando as novas gerações de placas foram vendidas mais caras do que suas antecessoras, o que significa que o custo de treinamento do modelo permaneceu no mesmo nível.
Desta vez, a NVIDIA definiu o preço das placas novas e mais populares no mesmo nível das placas da geração anterior no momento de suas vendas. Para os desenvolvedores de IA, este evento se tornou realmente importante – na verdade, as placas RTX 3000 oferecem acesso a um desempenho comparável ao Titan RTX, mas com um preço muito mais agradável. Os desenvolvedores de ciência de dados agora podem treinar modelos mais rapidamente sem aumentar os custos.
As placas principais da nova série GeForce RTX 3090 receberam 10.496 núcleos NVIDIA CUDA com clock de 1,44 GHz (aceleração de até 1,71 GHz), 328 núcleos tensores de terceira geração e 24 GB de memória gráfica GDDR6X de 384 bits. O ainda mais acessível GeForce RTX 3080 possui 8.704 núcleos CUDA nas mesmas velocidades de clock, 272 núcleos tensores e 10 GB de memória GDDR6X de 320 bits. Apesar da escassez de novas placas de vídeo (a NVIDIA ainda teve que pedir desculpas ao mercado pela resultante escassez de placas no início das vendas), no início de outubro, os servidores GPU apareceram na linha de produtos dos provedores de hospedagem.
O provedor holandês HOSTKEY foi um dos primeiros na Europa a testar e apresentar servidores GPU baseados nas novas placas GIGABYTE RTX3090 / 3080 TURBO. Desde 26 de outubro, as configurações baseadas em RTX 3090 / Xeon E-2288G e RTX 3080 / AMD Ryzen 9 3900X estão disponíveis para todos os clientes HOSTKEY em data centers na Holanda e Moscou.
Os cartões RTX3090 / 3080 são posicionados pelo fabricante como uma solução mais produtiva para substituir os cartões RTX 2000 pela arquitetura de Turing anterior. E, claro, os servidores com as novas placas são muito mais eficientes do que os servidores GPU “populares” disponíveis baseados em placas de vídeo GTX1080 (Ti), que também são adequados para trabalhar com redes neurais e outras tarefas de aprendizado de máquina (embora com reservas), mas estão disponíveis. a preços muito “democráticos”.
«Acima da “série NVIDIA RTX 3000 estão todas as soluções poderosas baseadas em placas da classe A100 / A40 (Ampère) com até 432 núcleos tensores de terceira geração, Titan RTX / T4 (Turing) com até 576 núcleos tensores de segunda geração e V100 (Volta ) com 640 núcleos tensores de primeira geração. Os preços dessas placas poderosas, bem como para alugar servidores GPU com elas, excedem significativamente as ofertas com o RTX 3000, por isso é especialmente interessante avaliar a lacuna de desempenho em tarefas de AI / ML na prática.
Uma das tarefas de trabalho para teste operacional de servidores GPU baseados nas novas placas RTX 3090 e RTX 3080 foi o processo de reconstituição de face para a rede neural U-Net + ResNet com normalização espacialmente adaptável SPADE e um discriminador de patch. Facebook PyTorch versão 1.6 com modo de precisão mista automatizada (AMP) integrado e torch.backend.cudnn.benchmark = O modo True flag foi usado como uma estrutura.
Para efeito de comparação, o mesmo teste foi executado em um servidor GPU com uma GeForce GTX 1080 Ti, mas sem AMP, o que apenas tornaria o processo mais lento, e também em uma máquina com uma placa Titan RTX. Para o bem da pureza do experimento, deve ser mencionado que neste teste com a placa Titan RTX, um sistema foi usado em um processador Intel Core i9-10920X, enquanto o resto dos servidores GPU com todas as outras placas rodaram em um Xeon E-2288G.
Claro, é importante fazer comparações durante a classificação nos mesmos processadores, uma vez que muitas vezes são o gargalo que limita o desempenho do sistema. Portanto, uma parcela de ceticismo sobre o erro nos resultados do teste de GPU é bastante apropriada neste caso. Obtivemos os seguintes resultados:
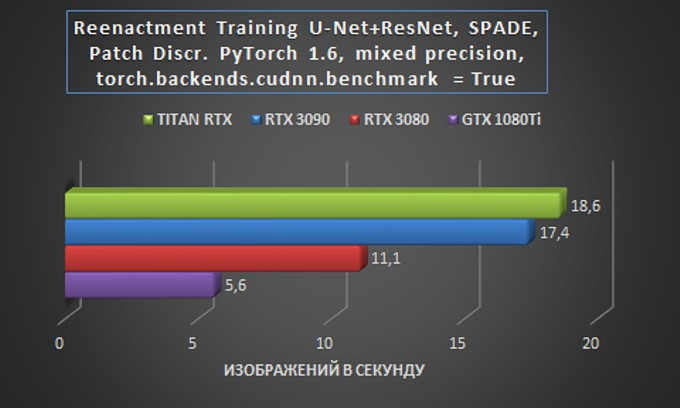
A diferença mínima entre o RTX 3090 e o Titan RTX é particularmente impressionante quando você considera a enorme diferença de preço entre as duas soluções. No próximo teste, o RTX 3090 merece, pelo menos, uma comparação completa e profunda com um servidor GPU baseado em uma e duas placas RTX 2080. e o atraso de três vezes da GTX 1080 Ti também deixou sua marca na diferença de arquitetura.
Se você olhar para esses resultados do ponto de vista prático, ou seja, em termos de avaliação dos custos financeiros de treinamento de um modelo no caso de aluguel de servidor GPU, então a balança finalmente pende a favor da escolha de um sistema com RTX 3090 – este cartão proporcionará o melhor aproveitamento do orçamento como em planos tarifários semanais e mensais.
No segundo problema de teste, que consistiu em treinar uma Rede Adversarial Gerativa (GAN) com o pacote PyTorch, foi interessante não só comparar o desempenho de cartas de diferentes gerações, mas também acompanhar o efeito do estado da bandeira torch.backends.cudnn.benchmark na final resultados. Ao treinar a arquitetura GAN, girar o sinalizador para True dá um ganho de desempenho, mas a reprodutibilidade dos resultados pode ser prejudicada.
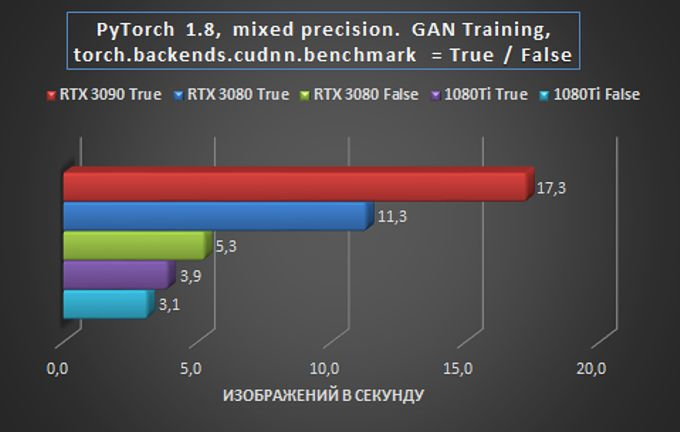
Esses resultados provam mais uma vez que o RTX 3090, com seus 24 GB de memória GDDR6X, é a melhor escolha para tarefas de imagem difíceis. Tanto no desempenho (melhoria de 65% em relação ao RTX 3080) e no custo de treinamento do modelo ao alugar um servidor GPU em termos de custo de treinamento.
O RTX 3080 superou significativamente o GTX 1080 Ti em desempenho, com qualquer configuração de sinalizador e apesar da paridade aproximada na memória. Lembre-se, no entanto, que ao treinar a arquitetura GAN, habilitar o sinalizador torch.backends.cudnn.benchmark = True dá ganhos de desempenho, mas os resultados na reprodutibilidade podem ser prejudicados. além disso,
Portanto, alugar um servidor GPU mais acessível com placas GTX 1080 Ti sob algumas condições pode ser uma escolha bastante razoável – ou pelo menos comparável em orçamento para modelos de treinamento com um RTX 3080. Infelizmente, não há tempo para executar esta grade através do Titan RTX permaneceu, mas com grande probabilidade a imagem neste caso permaneceria a mesma.
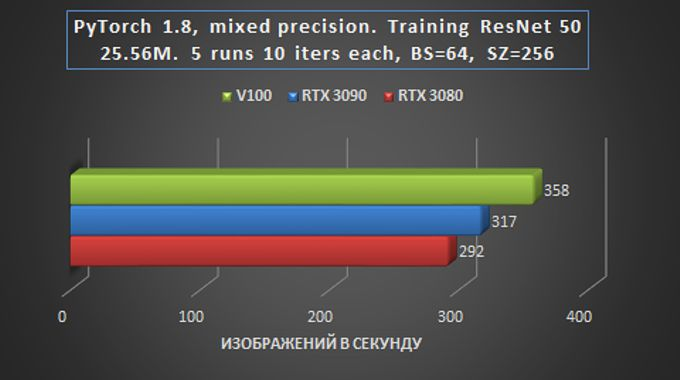
Na próxima tarefa de teste para treinamento de redes em tarefas de visão, o desempenho das placas gráficas RTX 3090 e RTX 3080 foi comparado com as capacidades do mais poderoso (e ainda muito caro) “veterano” Tesla V100 com 16 GB de memória HBM2. Cinco modelos de classificação foram testados para detecção de objetos com as seguintes configurações de treinamento: modelo para frente + média (sem perda) + para trás.
As tarefas de teste foram executadas com a versão mais recente da estrutura NVIDIA PyTorch (20.09-py3 de 24 de outubro). Infelizmente, esta versão não foi compilada para a arquitetura Ampere, então para suportar totalmente as placas de vídeo RTX 3000, eu tive que usar a versão PyTorch do nightly build, ou seja, 1.8.0.dev20201017 + cu110. A série RTX 3000 também tem alguns problemas com torch.jit, mas o problema foi completamente removido ao construir o PyTorch para uma placa específica. Em todos os testes, o PyTorch foi usado com o script automatizado Mixed Precision, com o sinalizador torch.backend.cudnn.benchmark = True habilitado por padrão.
Vale a pena mencionar algumas das nuances dessa comparação. Em particular, não estava envolvido o V100 mais rápido, que funcionava dentro de uma máquina virtual. Por causa disso, podem ocorrer algumas perdas que, muito possivelmente, podem ser otimizadas com uma configuração melhor. Além disso, todos os VRAM disponíveis não foram envolvidos no processo de teste, o que permitiria uma aceleração adicional dos cálculos.
A tarefa de treinar modelos de rede neural complexos é uma tarefa central para servidores GPU baseados em placas NVIDIA, às vezes permitindo reduzir o tempo de treinamento de algoritmos de aprendizado profundo em ordens de magnitude.
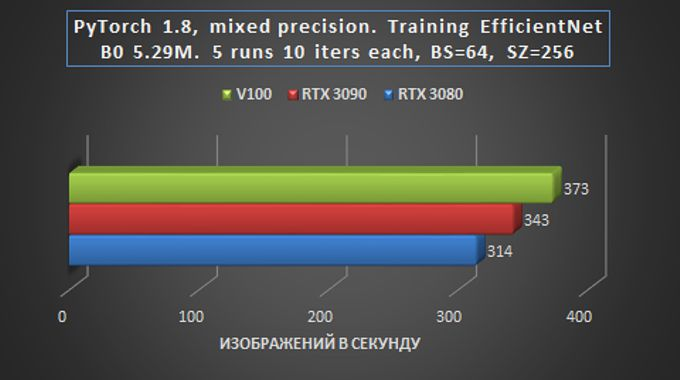
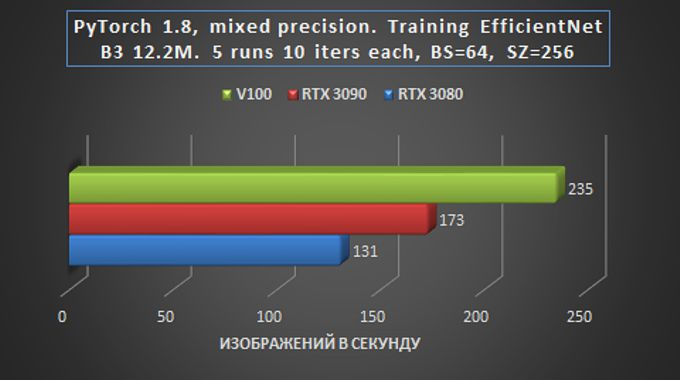
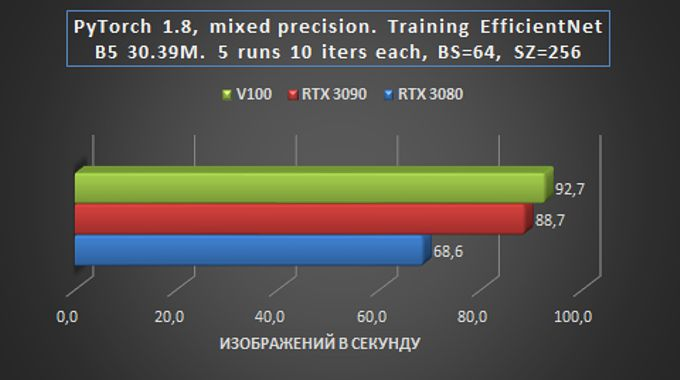
Quando a tarefa foi lançada para obter os resultados do benchmark, a detecção de objetos foi enviada sem um NMS, e a transferência para treinamento não incluiu correspondência de destino. Em outras palavras, na prática, a taxa de aprendizagem provavelmente diminuirá em 10-20% e a velocidade de saída diminuirá em cerca de 20-30%.
Nesse caso, inferência é o processo de obtenção de previsões pela execução de imagens por meio de uma rede neural pré-treinada, que é bastante adequada para implantação em um servidor GPU remoto.
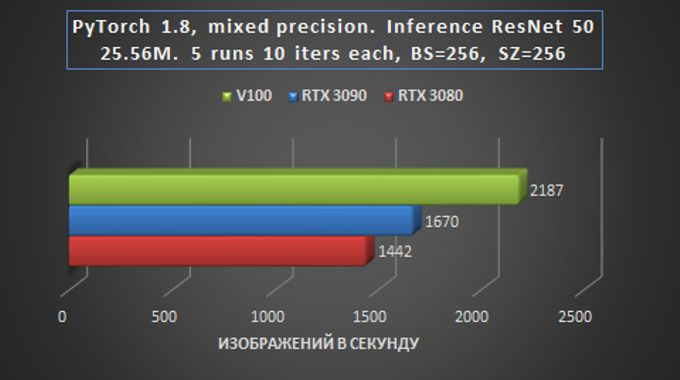
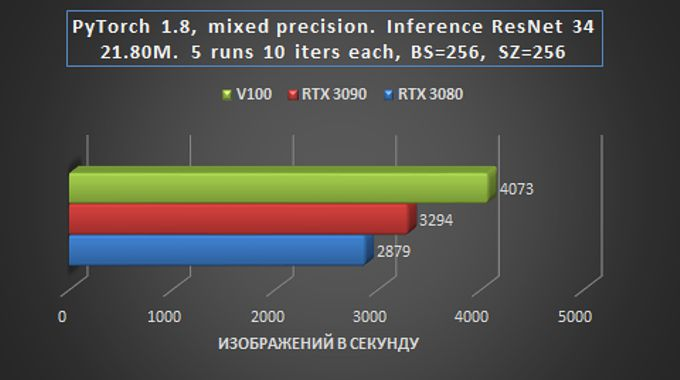
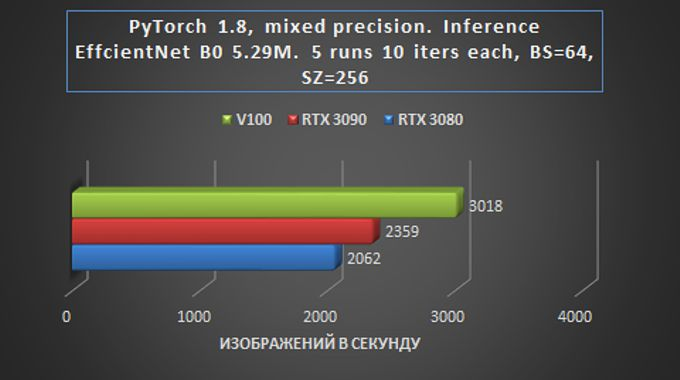
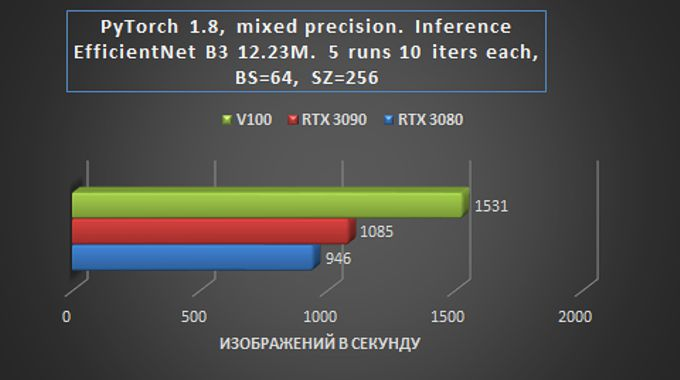
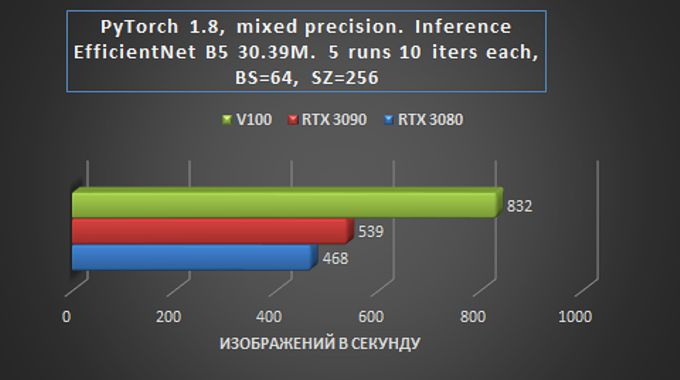
Em geral, podemos dizer que em tarefas de treinamento e inferência de rede em tarefas de Visão, a placa RTX 3090 é apenas 15-20% mais lenta que a Tesla V100, e isso é muito impressionante – especialmente considerando a diferença de preço.
O fato de que o RTX 3080 fica atrás do RTX 3090 é relativamente pequeno – pelo menos significativamente menos do que ao realizar outras tarefas, também é indicativo. Na prática, isso significa que mesmo com um orçamento relativamente pequeno alocado para alugar um servidor GPU baseado no RTX 3080, você pode obter um desempenho suficientemente alto com apenas um pequeno aumento no tempo de processamento de dados.
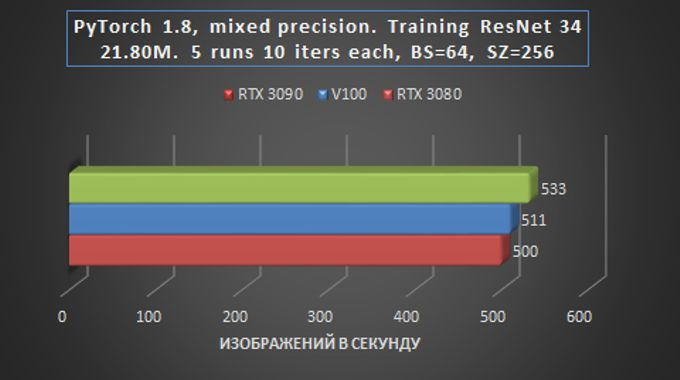
O teste RetinNet com ResNet50FPN para detecção de objetos foi realizado com os parâmetros PyTorch acima (20.09-py3 a partir de 24 de outubro), com o torch.backend.cudnn.benchmark = Bandeira verdadeira e com o modelo para frente + média (sem perda) + configurações de treinamento para trás.
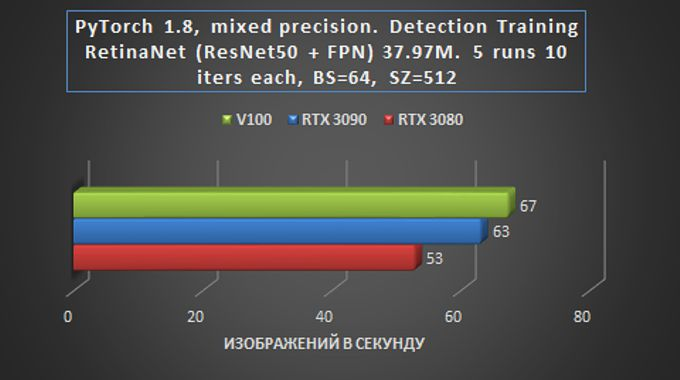
Aqui, o atraso das placas da série RTX30 já é mínimo, o que fala das vantagens indiscutíveis da nova arquitetura Ampere para solucionar tais problemas. A placa RTX 3090 teve um ótimo desempenho.
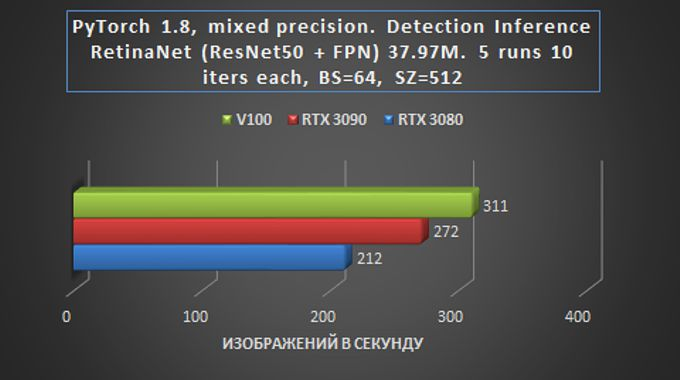
O atraso relativamente pequeno do cartão de orçamento sugere que a excelente relação preço / desempenho torna o RTX 3080 uma escolha desejável para tarefas de prototipagem em um orçamento econômico. Assim que o protótipo estiver concluído, o modelo pode ser ampliado, por exemplo, em servidores GPU com placas RTX 3090.
Com base nos resultados dos testes de novas soluções gráficas da família GeForce RTX 3000, podemos afirmar com segurança que a NVIDIA superou de maneira brilhante a tarefa de lançar placas gráficas acessíveis com núcleos tensores potentes o suficiente para computação AI rápida. Em algumas tarefas de treinamento de rede, como trabalhar com redes esparsas, as vantagens da arquitetura Ampere sobre a geração RTX20 podem ser aceleradas pela metade.
As vantagens de usar servidores GPU com placas GeForce RTX 3090 são especialmente óbvias em tarefas onde o treinamento do modelo está associado a maiores requisitos de memória – ao analisar imagens médicas, modelagem de visão computacional moderna e sempre que houver necessidade de processar imagens muito grandes – por exemplo, ao trabalhar com arquiteturas GAN.
Ao mesmo tempo, o RTX 3080 com seus 10 GB de memória gráfica é bastante adequado para trabalhar com tarefas profundas de aprendizado de máquina, já que para aprender o básico da maioria das arquiteturas, é suficiente reduzir o tamanho das redes ou usar imagens menores como entrada e, em seguida, dimensionar o modelo para os parâmetros exigidos, se necessário. em servidores GPU mais poderosos.
Considerando que a memória HBM usada nas placas classe A100 não deve cair significativamente de preço tão cedo, podemos dizer que as placas RTX 3090 / RTX 3080 são um investimento bastante viável para os próximos anos.
O provedor de hospedagem holandês HOSTKEY oferece uma ampla gama de servidores GPU em data centers na Holanda e Moscou, com base nas GPUs RTX3080 e RTX3090 de última geração, bem como nas placas RTX2080Ti e GTX1080Ti / 1080 da geração anterior. A empresa oferece servidores prontos para o uso e com configuração personalizada que atendem perfeitamente às necessidades do cliente. A empresa gostaria de agradecer a Emil Zakirov e Alexander Shironosov por sua ajuda na realização dos testes.