
Em 2024, a Nvidia apresentou os primeiros processadores gráficos de servidor baseados em Blackwell, litografados para ela nas fábricas da TSMC, que continham 208 bilhões de transistores de efeito de campo, e engenheiros de microeletrônica já discutem quando serão capazes de superar o limite tecnologicamente (e psicologicamente) significativo de um trilhão desses menores elementos da lógica de computação de semicondutores em um único chip, embora não monolítico. No entanto, por que perseguir uma densidade de transistores tão alucinante? Se não levarmos em conta o desejo altruísta de engenheiros e cientistas de verdade de romper as fronteiras do já conhecido rumo ao desconhecido (o que é nobre em si mesmo, mas quanto mais longe avança, mais caro se torna – e, portanto, requer apoio financeiro substancial de governos, estruturas empresariais ou mesmo ambos ao mesmo tempo), tudo se resume a uma economia banal. Quanto mais circuitos lógicos – compostos desses mesmos transistores – couberem em um chip, mais complexos serão os problemas que ele conseguirá resolver; e, ao mesmo tempo, menos tempo levará para lidar com os problemas atualmente relevantes.
Isto é especialmente importante na era da revolução da inteligência artificial, que ainda não conseguiu escapar do espaço virtual, no sentido de que todas as redes neurais hoje em demanda são emuladas na memória de computadores clássicos em uma base de elementos semicondutores, construída de acordo com os princípios arquitetônicos estabelecidos por John von Neumann. Operações aritméticas simples, multiplicação e adição, às quais essa emulação é geralmente – embora nem sempre – reduzida, são executadas mais rapidamente, quanto menor o atraso na transferência de dados da memória para o processador (para realizar os cálculos) e vice-versa (para salvar o resultado intermediário). E como essas operações são perfeitamente paralelizadas – felizmente, um número incrível de números precisa ser adicionado e multiplicado em cada camada de uma rede neural profunda (vamos levar em conta que o número de parâmetros nos modelos de IA atuais já ultrapassa um trilhão), – quanto mais (micro)núcleos físicos em um único chip trabalhando simultaneamente nelas, melhor. Claro, não será difícil distribuir tais tarefas entre processadores com um número relativamente pequeno de transistores, mas a necessidade de enviar dados por longos barramentos de interconexão inevitavelmente aumentará a latência – e, portanto, reduzirá catastroficamente o desempenho das redes neurais.

A dependência empírica do número de transistores em um único chip em relação ao tempo é bem aproximada por uma linha reta (em um gráfico logarítmico), então se a tendência que dura várias décadas continuar, os engenheiros serão capazes de encaixar um trilhão de transistores em um único processador, mesmo antes de 2035 (fonte: IEEE Spectrum)
⇡#Quando é bom ir pequeno
No final de 2022, quando o ChatGPT estava apenas começando a ganhar sua atual popularidade retumbante, representantes do Grupo de Pesquisa de Componentes da Intel previram, falando no Encontro Internacional de Dispositivos Eletrônicos do IEEE, que até 2030 a densidade de transistores em chips simplesmente teria que crescer dez vezes. Considerando que naquela época o valor máximo desse indicador para microcircuitos seriais já havia atingido quase 100 bilhões, estávamos falando de um trilhão de transistores por cristal. Parece que as coisas estão caminhando nessa direção: na primavera de 2024, a Nvidia lançou seu chip mais poderoso para aceleradores de servidor, o Blackwell B200, com 208 bilhões de transistores, e um ano depois, a Apple lançou ao mercado computadores pessoais baseados em seus próprios processadores ARM M3 Max com um total de 184 bilhões de transistores – no entanto, aqui esse número recai sobre dois chips separados, encapsulados em um único gabinete e conectados por um barramento de dados de alto desempenho.
É importante enfatizar que a simplicidade (no nível operacional básico) da computação de IA é um dos principais incentivos para que a indústria de microprocessadores domine padrões de produção cada vez menores. Em média, para tarefas algorítmicas “clássicas”, resolvidas principalmente por processadores centrais, a multicore não é da maior importância – o aumento da velocidade das operações single-threaded ao passar de um processo tecnológico maior para um menor é importante por si só. O desempenho das redes neurais generativas emuladas na memória dos computadores de von Neumann, grosso modo, é diretamente proporcional ao número de transistores localizados em uma pastilha de silício sob a cobertura do gabinete de um processador especializado que realiza cálculos de IA (tradicionalmente, eles continuam sendo chamados de “gráficos”, embora os termos “tensor” ou simplesmente “neuroprocessador” já estejam em uso) – partindo do pressuposto de que a imagem digital de tal rede neural cabe inteiramente na memória operacional (vídeo) rápida, eliminando assim atrasos adicionais para múltiplos carregamentos e descarregamentos parciais dessa imagem da memória permanente para a memória operacional e vice-versa. Assim, é lógico organizar a maior parte dos transistores disponíveis para organizar cálculos lógicos em núcleos de hardware relativamente simples (CUDA, no caso da Nvidia, ou seus análogos), e então se constata que quanto mais núcleos houver no processador, proporcionalmente mais operações de IA ele será capaz de produzir por unidade de tempo. Se não houvesse limitações tecnológicas na fase de litografia dos microcircuitos e neurochips modernoscertamente se tornaria maior a cada geração, já que aumentar a área para aumentar o número total de transistores em um cristal deveria ser obviamente mais barato do que miniaturizar os padrões de produção. Mas essas limitações, infelizmente, existem.
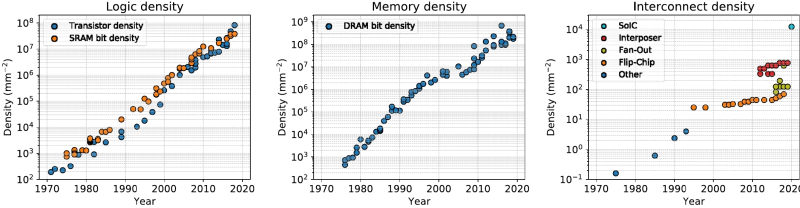
Os gráficos do crescimento anual da densidade de elementos lógicos e células SRAM estruturalmente semelhantes (esquerda), células de memória DRAM (centro) e interconexões em um chip semicondutor (direita) pareceriam bastante consistentes organicamente, não fosse por alguns pontos sutis. Primeiro, a escala vertical (logarítmica, em milímetros quadrados inversos) é diferente para os três gráficos: de 102 para 108, de 102 para 109 e de 10−1 para 104, respectivamente. Segundo, desde meados da década de 1990, a densidade de interconexões começou claramente a crescer a um ritmo muito mais contido do que os dois primeiros valores (fonte: IEEE Spectrum).
Como os leitores familiarizados com nosso artigo de quase três anos “Por que os chiplets são necessários, ou como dar nova vida à “Lei de Moore” além de 3 nm” provavelmente já adivinharam, estamos falando do limite da área de projeção da fotomáscara na peça de trabalho alcançada pela indústria de microprocessadores – o limite do retículo – que é de cerca de 800 mm². Além disso, para as fotolitografias mais promissoras da série EUV High-NA – utilizando óptica anamórfica, que, devido à ampliação não axissimétrica (em direções perpendiculares), fornece a resolução máxima permitida em apenas uma das dimensões – essa área efetiva corre o risco de ser reduzida aproximadamente pela metade. Portanto, infelizmente, só há uma maneira de aumentar o número de transistores sob a tampa do processador finalizado: encaixar o máximo possível deles em um submicrocircuito (chiplet) e, em seguida, conectar esses chiplets com barramentos curtos e ultralargos para minimizar atrasos na transferência de dados entre eles dentro de um único cristal lógico. Esta é, sem dúvida, uma opção de compromisso: em um chip fisicamente sólido com o mesmo número de transistores que em um composto, os impulsos elétricos ainda se propagariam com atrasos menores. Mas sem uma reformulação conceitual do próprio circuito litográfico EUV (com a rejeição do plasma de estanho como fonte de fótons com o comprimento de onda necessário e de um sistema complexo de espelhos metálicos que focalizam o fluxo resultante de radiação de raios X), um cristal semicondutor monolítico para uma fotomáscara com uma área muito maior que 800 mm² não pode ser criado com os meios disponíveis hoje, e a transição para um método diferente de geração de EUV exigirá esforços titânicos.Investimentos de capital e muitos anos, senão algumas décadas, para levar um protótipo de laboratório ao estágio de uma instalação industrial pronta para operação em série. Assim, na ausência de um brasão, a indústria de TI continua a escrever em linguagem simples – e, como mostra a prática, cumpre suas tarefas muito bem.
⇡#CoWoS, por favor?
A diferença fundamental entre um microcircuito baseado em chiplet, mas logicamente único, e um conjunto multiprocessador, por exemplo, comum para servidores de alta carga (quando duas ou mais CPUs — e às vezes até GPUs, conectadas por NVlink — trabalham juntas para resolver o mesmo problema) é o comprimento, a largura e o método de implementação física do barramento de dados que conecta as partes individuais do sistema montado. Para minimizar atrasos, esse barramento deve ser, por um lado, o mais largo (multicanal) possível e, por outro, o mais curto possível. Um tópico separado é a condutividade elétrica do condutor selecionado para formar tal barramento, especialmente considerando a área de sua largura de seção transversal, que já se aproxima de unidades de nanômetros quadrados: o cobre clássico deixa de ser adequado para engenheiros de microeletrônica à medida que continua a miniaturizar — prevê-se que grafeno, rutênio, semimetais de película fina e outros materiais o substituam. Mas, por enquanto, esses estudos são relevantes apenas para interconexões dentro de microcircuitos fisicamente únicos; Os barramentos entre chips ainda estão sendo fabricados, inclusive por fotolitografia, usando o bom e velho processo de Damasco.

A integração de chiplets via substrato de silício é um clássico, mas a Imec também está desenvolvendo outras conexões mais promissoras (em termos de redução de custos e complexidade de processamento) em camadas de redistribuição (RDL) de polímeros orgânicos intercalados com folhas de cobre ultrafinas (fonte: Imec)
Uma das maneiras mais comuns de organizar chiplets em um microcircuito logicamente unificado é a “conexão bidimensional e meia através de um substrato comum”, a tecnologia de interposição 2,5D. Na maioria das vezes, o substrato é o silício — justamente porque a microeletrônica moderna funciona melhor com silício do que com qualquer outro material, inclusive em termos de litografia de trilhas condutoras de corrente. Mas, como substrato, é, em princípio, permitido o uso de vidro, plástico laminado e vários polímeros orgânicos — os próprios condutores ainda são exclusivamente de cobre. Geometricamente, as conexões 2,5D podem diferir bastante: inicialmente, a colocação direta de chiplets com uma folga extremamente pequena (50 µm ou menos) em um único substrato era amplamente utilizada, dentro do qual eram colocados barramentos de cobre, e os chiplets eram acoplados ao substrato por meio de contatos pontuais (microbumps) com dimensões características de dezenas de micrômetros, com folgas igualmente longas entre eles.
Outra opção é usar pontes feitas de wafers estreitos de silício costurados com barramentos de cobre, que são colocados ponta a ponta entre os chiplets, em vez de uma camada adicional de silício comum a todo o chip composto, o que aumenta a espessura da estrutura e reduz a eficiência da dissipação de calor. A partir daqui, na verdade, resta apenas um passo das “duas dimensões e meia” para o verdadeiro 3D: em vez de colocar os chiplets um ao lado do outro e conectá-los, mesmo com conectores intermediários muito estreitos, faz sentido reduzir o comprimento desses conectores a quase zero – colocando um chiplet em cima do outro e conectando-os com contatos de ponto direto. Já falamos sobre como exatamente os engenheiros de microeletrônica fazem isso e quais dificuldades eles têm que superar aqui no artigo “Um difícil ataque às alturas microscópicas: como os chiplets entram na terceira dimensão”. Vamos apenas lembrar que se as conexões de microgrãos fornecem lacunas entre contatos de cerca de 30, 10 ou, no máximo, 5 µm (e para tecnologias de processo ultraminiatura modernas isso é muito para criar um barramento de dados entre chips de alta densidade), então métodos mais avançados tecnicamente – mas também caros – de colocação de microcircuitos pré-preparados em uma placa recém-litografada (ligação de matriz a wafer), bem como combinações de duas placas complementares para formar chips 3D praticamente prontos – basta cortar e embalar – (ligação de wafer a wafer) – tornam possível reduzir as lacunas entre contatos adjacentes para 200 nm e 100 nm e, no futuro previsível – para várias dezenas de nanômetros.

Diagrama esquemático da organização do chip composto híbrido dentro da arquitetura CoWoS-S (fonte: TSMC)
Em 2021, a quinta geração da tecnologia de integração híbrida multichiplet CoWoS-S (Chip-on-Wafer-on-Substrate com interposer de Si), desenvolvida pela taiwanesa TSMC, tornou possível quase triplicar a área efetiva de projeção da fotomáscara: de 830 para cerca de 2500 mm². Isso se refere ao recálculo inverso do número de transistores (em todos os “andares” no total, é claro) que cabem em um determinado cristal — na área que uma única fotomáscara ocuparia, necessária para sua exposição conjunta. Nesse caso, porém, tudo é ainda mais complicado: para circuitos lógicos, a área efetiva da máscara não cresceu tanto, chegando a 1200 mm², enquanto a principal contribuição para o aumento foi feita por “cubos” verdadeiramente multicamadas da ultrarrápida RAM HBM, montados no mesmo cristal composto. De acordo com um princípio semelhante, a área efetiva da fotomáscara projetada na placa pode ser potencialmente seis vezes maior do que a fisicamente permitida, mas novamente devido à proximidade de “arranha-céus” de módulos HBM e chips lógicos com um número muito menor de andares em um microcircuito híbrido comum. Mas seria incorreto considerar isso algum tipo de trapaça por parte dos engenheiros de microeletrônica: RAM próxima à lógica computacional, conectada a esse barramento de dados ultralargo com atrasos mínimos, é exatamente o que é urgentemente necessário para resolver problemas modernos de IA em computadores von Neumann. Portanto, se o cobiçado trilhão de transistores em um cristal é obtido principalmente por meio da compactaçãoEstruturas DRAM, não circuitos lógicos, ninguém desqualificará tal registro.
⇡#Refinamentos (não) com um arquivo
É claro que colocar um microchip composto em uma mesa convencional, cujos chiplets e módulos HBM juntos contêm um trilhão de transistores, não é um fim em si mesmo para a indústria de microeletrônica: é muito mais importante em cada etapa da transição para esse marco significativo (principalmente psicologicamente) alcançar um aumento perceptível no desempenho dos microcircuitos resultantes em aplicações reais. E, nesse sentido, qualquer redução na latência dos sinais que se movem dentro de tal chip já é um passo valioso. Para reduzir a latência, os engenheiros constantemente oferecem soluções práticas que não estão diretamente relacionadas ao aumento da densidade de transistores em nenhuma das três dimensões disponíveis: por exemplo, a tecnologia proprietária da TSMC, sistema em chips integrados, SoIC (não confundir com sistema em um chip, SoC!), implementa integração heterogênea de chips de vários andares usando conexões verticais através de silício (TSV), em vez de contatos pontuais — microgrãos. A própria transição para canais gravados em substratos de silício (ou outros) a partir de “grãos” de contato que se projetam além desses substratos encurta o caminho de propagação do sinal elétrico e, dependendo da tarefa, as tecnologias modernas tornam possível criar TSVs de comprimentos muito diferentes – de dezenas e centenas de micrômetros (para sensores de imagem CMOS, nos quais tais conexões apareceram inicialmente) a “pinos” de 5 nm e até mais curtos para fornecer energia da parte traseira dos microcircuitos, fornecimento de energia traseira ou PowerVia na terminologia da Intel.

Várias variantes de TSV – e não as menores – disponíveis na microeletrônica hoje (fonte: Imec)
É verdade que, como o leitor atento provavelmente já adivinhou, a velocidade do progresso nessa direção de desenvolvimento da microeletrônica é limitada por um fator extremamente importante: o econômico. À medida que os TSVs se tornam mais estreitos e longos, o custo de sua produção aumenta: canais profundos exigem uma gravação mais longa (e o aumento do tempo de produção do chip em uma máquina carregada com pedidos com quase um ano e meio de antecedência resulta em um aumento no custo de tal microcircuito simplesmente porque outros lotes são forçados a esperar sua vez nesse momento), aplicar as camadas de materiais necessárias durante esse processo às paredes de um poço estreito é mais difícil e caro, e a camada de cobre condutora formada no mesmo canal deve ser uniforme e de espessura rigorosamente calculada ao longo de toda a sua altura considerável – o que não é fácil de alcançar tecnologicamente e extremamente difícil de controlar conscientemente. Por esse motivo, os chips compostos baseados em TSV são caros não apenas na fase de fabricação: eles exigem equipamentos especializados de controle e medição, que por sua vez também precisam ser fabricados em algum lugar (e obviamente em um lote extremamente limitado, o que automaticamente aumenta o preço de custo) e, em seguida, reparados, etc. Em suma, para a ampla distribuição desses chips, é urgentemente necessário um mercado de vendas extremamente amplo, cujos volumes permitirão manter o preço de cada unidade de bens oferecidos aos clientes dentro de limites razoáveis - e, desse ponto de vista, os chips compostos baseados em TSV e o segmento de computação de IA são simplesmente feitos um para o outro.
Adicionemos aqui outro problema, que abordamos em nosso artigo relativamente recente “A Velhice Não É Uma Alegria (E para o Silício Também)” para a indústria microeletrônica como um todo: canais estreitos e profundos que perfuram cristais de silício bastante pequenos, como perfurações, não os tornam resistentes. Quanto maior a razão entre a profundidade do poço TSV e seu diâmetro, maior a tensão mecânica devido à contração (tensão de tração) à qual as substâncias depositadas nas paredes do canal durante o processo de fabricação do chip submetem a seção adjacente do substrato de silício. E como a escala aqui não é nem micrométrica, mas nanométrica, essa tensão (que se manifesta na deformação da rede cristalina) começa a afetar diretamente a mobilidade das cargas livres na espessura do semicondutor – organizadas, recordemos, por meios fotolitográficos na mesma base de silício – e, consequentemente, as características operacionais dos transistores adjacentes. Por esse motivo, ao projetar microcircuitos híbridos, os engenheiros de microeletrônica precisam cercar “zonas de exclusão” ao redor dos canais TSV, nas quais não é recomendado colocar elementos lógicos dos microcircuitos. Acontece que, embora, em geral, o desenvolvimento da terceira dimensão leve a um óbvio aumento múltiplo no número de transistores sob a tampa do encapsulamento do cristal CoWoS, a taxa desse aumento não é tão grande quanto gostaríamos, pois é necessário colocar um pouco menos transistores em cada “piso” do que seria possível para um microcircuito planar clássico da mesma área. Além disso, a camada de cobre dentro dos poços longos e estreitos e o silício ao redor deles têmcondutividade térmica irregular, para dizer o mínimo, que, com o aquecimento inevitável do chip durante a operação, apenas aumenta as tensões acumuladas em sua espessura, e como a perfuração dos wafers de silício mais finos pelos canais TSV é necessariamente irregular (os contatos entre os chips são agrupados em zonas muito específicas), isso adiciona dores de cabeça aos engenheiros de projeto.

Diagrama esquemático da organização da fonte de alimentação na parte traseira dos chips (esquerda) e uma micrografia de uma seção transversal de tal chip (fonte: Imec)
É bem possível que, num futuro próximo, o TSV dentro de cristais logicamente unificados seja substituído por fotônica de silício – e, em geral, os sistemas optoeletrônicos podem, em última análise, provar ser um hardware mais econômico especificamente para computação de IA – mas, por enquanto, o CoWoS e tecnologias similares continuam a triunfar nessa área. Sem dúvida, o papel da inércia já conquistada pela indústria generativa é extremamente grande aqui: sim, o trabalho extensivo para aprimorar tecnologias previamente dominadas é caro e proporciona ganhos de desempenho não muito impressionantes em cada estágio subsequente, mas aqui é possível planejar com mais ou menos confiança tanto a demanda dos clientes quanto o cronograma de domínio desses mesmos estágios. Se largarmos tudo agora e investirmos no desenvolvimento de áreas francamente cruas, embora extremamente promissoras, de modificação de hardware, corremos o risco de não atender à demanda do mercado por novos lotes de computadores de IA a tempo e de estimar incorretamente o tempo necessário para o lançamento confiante de novos produtos em produção em série.
Os sistemas híbridos de computação eletrônica-fotônica, no entanto, mantêm a vantagem incrivelmente atraente (no sentido comercial mais prático) de que, com seu desenvolvimento confiante, a própria tarefa de “atingir o limiar de 1 trilhão de transistores em um cristal” pode perder relevância. Julgue por si mesmo: se cinco chips gráficos de servidor de alto desempenho, como o já mencionado B200 com 208 bilhões de transistores, forem conectados em um único sistema com interconexões ópticas – e o método fotônico de transmissão de informações tiver um atraso incomparavelmente menor que o eletrônico – eles poderão funcionar (após um certo ajuste fino de software) como um único microcircuito lógico com o mesmo trilhão de transistores – e o sinal entre os blocos de GPU vizinhos passará quase mais rápido do que de uma extremidade de cada bloco separadamente para a outra. Além disso, centenas de servidores em racks dentro de uma sala de máquinas comum poderão atuar essencialmente como um único neurocomputador, mesmo com uma quantidade incrível de RAM de alta velocidade (também conectada por canais fotônicos) – isso abre perspectivas quase ilimitadas para complicação adicional dos modelos de IA. Portanto, é bem possível que a fotônica de silício e os sistemas híbridos um dia nos permitam remover o “problema do trilhão de transistores” da agenda – embora haja uma chance de que tal solução, levando em conta o custo de todos os desenvolvimentos de laboratório e seu subsequente desenvolvimento em sistemas comerciais produzidos em massa, custe mais de um trilhão de dólares.
⇡#Materiais relacionados
- Intel pronta para ultrapassar a TSMC – Detalhes da tecnologia Turbo Cells para tecnologia de processo de 14 angstroms revelados.
- A Lei de Moore completa 60 anos.
- Os chineses fabricaram o transistor mais rápido do mundo sem silício e sancionaram litografias.
- A AMD ultrapassou a Nvidia em densidade de transistores — até mesmo o chip GeForce RTX 5090 perdeu.
- «A fronteira final da arquitetura de transistores: TSMC e Intel falam sobre transistores de nanofolha.