
A NVIDIA anunciou hoje o NVIDIA Dynamo, o sucessor do NVIDIA Triton Inference Server, um ambiente de software de código aberto para desenvolvedores que acelera a inferência e facilita o dimensionamento de modelos de IA de raciocínio em fábricas de IA com sobrecarga mínima e eficiência máxima. O CEO da NVIDIA, Jensen Huang, chamou o Dynamo de “um sistema operacional para fábricas de IA”.
O NVIDIA Dynamo melhora o desempenho de inferência ao mesmo tempo que reduz o custo de dimensionamento da computação durante os testes. Ao otimizar a inferência no NVIDIA Blackwell, a plataforma aumenta drasticamente o desempenho do modelo de IA de raciocínio DeepSeek-R1.

Fonte da imagem: NVIDIA
Projetada para maximizar a receita de tokens para data centers de IA, a plataforma NVIDIA Dynamo orquestra e acelera as comunicações de inferência em milhares de aceleradores e usa processamento de dados desagregados para separar as fases de processamento e geração de modelos de grandes linguagens (LLMs) em todos os aceleradores. Isso permite que cada fase seja otimizada independentemente de suas necessidades específicas e garante a utilização máxima dos recursos de computação.
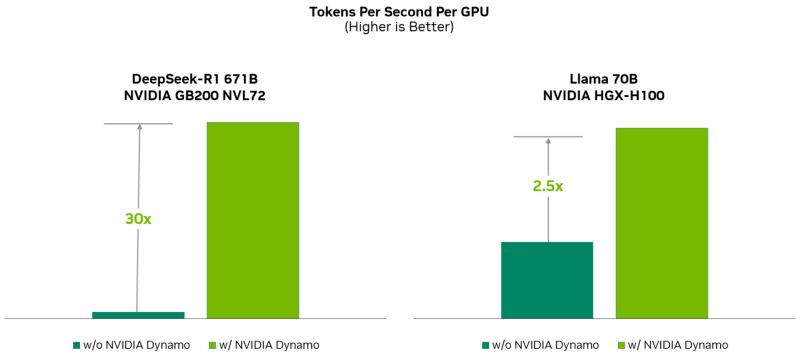
Com o mesmo número de aceleradores, o Dynamo dobra o desempenho (ou seja, a receita real das fábricas de IA) dos modelos Llama na plataforma NVIDIA Hopper. Ao executar o modelo DeepSeek-R1 em um grande cluster GB200 NVL72, a otimização de inferência inteligente usando NVIDIA Dynamo aumenta o número de tokens gerados por acelerador de tokens em mais de 30 vezes, disse a NVIDIA.
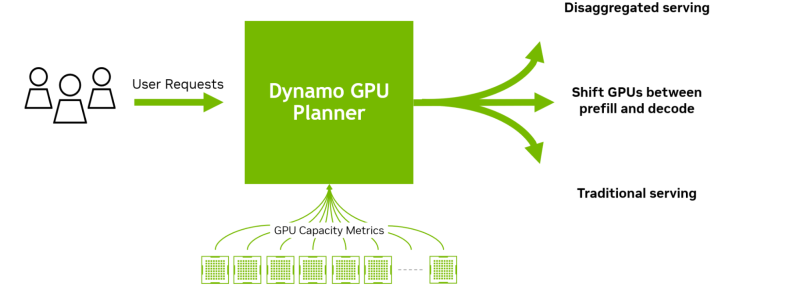
O NVIDIA Dynamo pode redistribuir dinamicamente cargas de trabalho entre aceleradores em resposta a alterações nos volumes e tipos de solicitações, e pode atribuir tarefas a aceleradores específicos em grandes clusters para ajudar a minimizar a computação de resposta e as solicitações de roteamento. A plataforma também pode descarregar dados de inferência para dispositivos de memória e armazenamento mais acessíveis e recuperá-los rapidamente quando necessário.

O NVIDIA Dynamo é totalmente de código aberto e oferece suporte a PyTorch, SGLang, NVIDIA TensorRT-LLM e vLLM, permitindo que os clientes desenvolvam e otimizem maneiras de executar modelos de IA dentro de inferência desagregada. De acordo com a NVIDIA, isso acelerará a adoção da solução em várias plataformas, incluindo AWS, Cohere, CoreWeave, Dell, Fireworks, Google Cloud, Lambda, Meta✴, Microsoft Azure, Nebius, NetApp, OCI, Perplexity, Together AI e VAST.
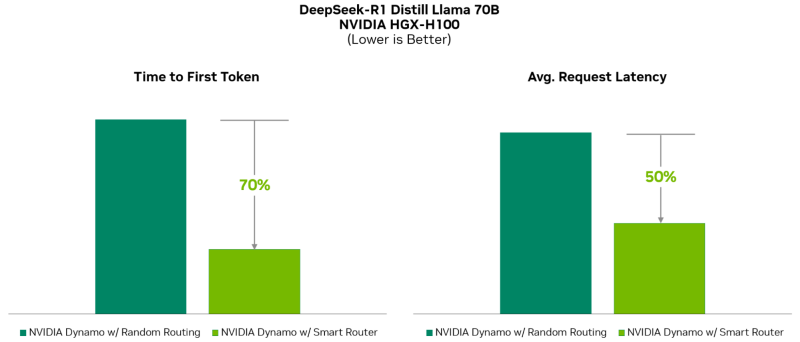
O NVIDIA Dynamo distribui as informações que os sistemas de inferência armazenam na memória após o processamento de solicitações anteriores (cache KV) entre muitos aceleradores (até milhares). A plataforma então encaminha novas solicitações para os aceleradores cujos conteúdos de cache KV estão mais próximos da nova solicitação, evitando assim recomputações dispendiosas.
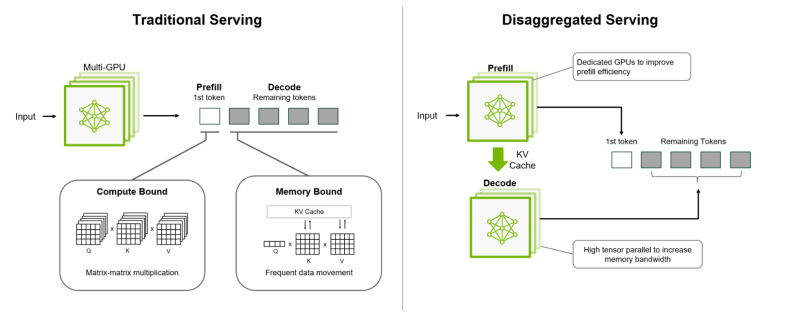
O NVIDIA Dynamo também fornece desagregação do processamento de solicitações recebidas, que despacha diferentes estágios da execução do LLM — da compreensão da solicitação à geração — para diferentes aceleradores. Essa abordagem é ideal para modelos de raciocínio. O atendimento desagregado permite que os recursos sejam configurados e alocados para cada fase de forma independente, proporcionando maior rendimento e resposta mais rápida às solicitações.
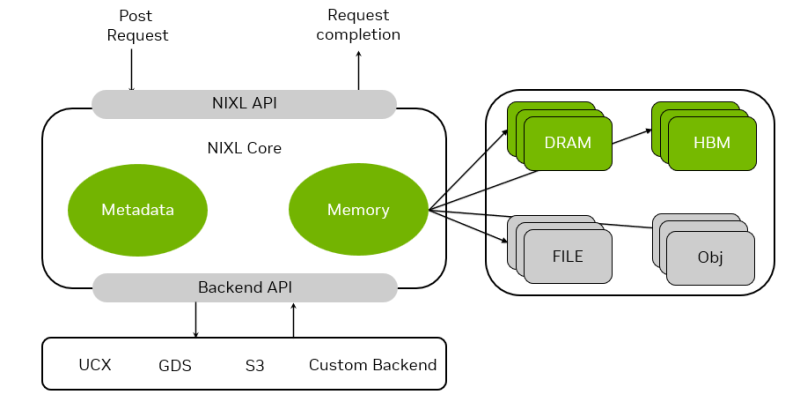
O NVIDIA Dynamo inclui quatro mecanismos principais:
- GPU Planner: um mecanismo de agendamento que altera dinamicamente o número de aceleradores para atender às demandas variáveis, eliminando a possibilidade de provisionamento excessivo ou insuficiente de recursos.
- Roteador inteligente: um roteador para LLM que distribui solicitações entre grandes grupos de aceleradores para minimizar recomputações caras de solicitações duplicadas ou sobrepostas, liberando recursos para lidar com novas solicitações.
- Biblioteca de comunicação de baixa latência: uma biblioteca otimizada para inferência que oferece suporte à comunicação entre aceleradores e simplifica a comunicação entre dispositivos diferentes, acelerando a transferência de dados.
- Gerenciador de memória: Um mecanismo que carrega, descarrega e distribui de forma transparente e inteligente dados de inferência entre dispositivos de memória e armazenamento.
A plataforma NVIDIA Dynamo estará disponível nos microsserviços NVIDIA NIM e terá suporte em uma versão futura da plataforma NVIDIA AI Enterprise.