
A linha GeForce 50 de placas de vídeo ocorre na direção usual do carro -chefe, que não é apenas um jogo, mas também uma solução de solicitação, para dispositivos para entusiastas e, com um atraso justo, produtos de nível médio. Por motivos de logística, somos forçados a adiar o teste do GeForce RTX 5090 e iniciar uma série de críticas com o RTX 5080, que é bem -sucedido à nossa maneira. A proximidade única do segundo modelo ao seu antecessor, o RTX 4080 Super, de acordo com as características formais, nos permitirá pesar as vantagens da nova arquitetura de Blackwell e entender por que, juntamente com as gerações da GPU, não apenas o preço de um FPS, mas Além disso, sob certas condições, é puro desempenho.

A GeForce RTX 5080 apresenta a placa de vídeo Palit Gamerock.
⇡#Processadores gráficos GB20X
Na nova geração de processadores gráficos, a NVIDIA eliminou novamente a divisão formal em dois ramos da arquitetura – aceleradores para centros de dados, por um lado, e produtos para PCs e estações de trabalho, por outro. A HPC Solutions ainda possui várias diferenças quantitativas e funcionais da GPU em massa, mas aqueles e outros pertencem à mesma linha de Blackwell, em homenagem a Matemática Americana David Blackwell.
Os chips saem da linha TSMC 4NP, que é o segundo processo de 5 nanômetros, adaptado às solicitações da NVIDIA, enquanto a Apple e a Intel já estão pedindo grandes cristais feitos a 3 nm de norma. Para ser justo, observamos que os gráficos discretos dos concorrentes também não estavam prontos para a migração em 3 nm, mas essas empresas têm uma grande reserva para o crescimento do desempenho específico da GPU devido a mudanças arquitetônicas (que já foram demonstradas pelo segundo -Geleradores de geração de geração). E, em geral, a AMD e a Intel ainda não pretendem competir com os preços e o desempenho “verdes” no escalão mais alto. Mas para a NVIDIA, o atraso no nó fotopolográfico antigo foi a solução que, finalmente, determinou o aparecimento da geforce da 50ª série.
No momento, as características das três GPUs de consumidores da família Blackwell, que formaram a base dos modelos de desktop da nova geração, começando com o GeForce RTX 5070 e terminando com RTX 5090. Como veremos mais adiante, a própria lógica do Os processadores gráficos da NVIDIA não foram submetidos a alterações estruturais; portanto, a comparação quantitativa do bloco de bloqueio das fórmulas de chips antigos e novos são bastante apropriados e diz muito sobre o desempenho “bruto”.
O principal cristal GB202 estabeleceu um novo registro de orçamento do transistor entre o GPUS-92.2 bilhões de consumidores que o aproxima do chip HPC da linha Blackwell, GB100. Este último consiste em 104 bilhões de transistores e, de acordo com a Nvidia, está esgotado pelo tamanho da câmara de fotos do TSMC. Por sua vez, a área de 750 mm2 define o GB202 em segundo lugar após o TU102 (754 mm2) da família Turn.
Os recursos de computação incluem 192 multiprocessadores de streaming, que, em condições de distribuição imutável de ALU em SM separado, significa 24 576 Nuclear CUDA compatível com FP32. Para saturar essa variedade de blocos executivos com os dados, GB202 dotou 128 MB do último nível e interface VRAM-512 bits. Não vimos uma memória de vídeo tão ampla em combinação com os chips GDDR Sgram desde os chips “vermelhos” Havaí/Granada (série Radeon R 200/300).
Apesar das características impressionantes do GB202, é perceptível que o Blackwell Silicon esteja intimamente dentro dos limites da tecnologia TSMC 4NP. Anteriormente, a transição da arquitetura da Ampere para Ada Lovelace, que coincidiu com uma atualização completa da norma fotolitográfica, tornou possível aumentar o poder de computação da GPU sênior na linha de 72 %, mesmo sem levar em consideração o relógio frequências. Por sua vez, o GB202 supera o antecessor – AD102 – apenas em 33 % de acordo com a fórmula do shader alu.

Diagrama de blocos do processador gráfico NVIDIA GB202
Seja como for, o GB202 elevará a barra de velocidade para uma nova altura e não é menos projetada para tarefas profissionais, o que beneficiará mesmo o progresso moderado. Infelizmente, o mesmo não pode ser dito sobre as características da seguinte antiguidade do cristal de Blackwell. O GB203 é metade da GPU principal – tanto em termos do número de transistores quanto na área do cristal – e na configuração dos blocos de computação (84 SM e 10 752 de ALU materialmente dramático de precisão padrão) não foi muito Do modelo ADA Lovelace, AD103 correspondente. A diferença entre os processadores gráficos do primeiro e o segundo escalão da série Blackwell é mais do que nunca e é de 129 % dos recursos de computação programável! O GB202 após o AD103 recebeu um pneu de memória de vídeo de 256 bits e 64 MB Kesha L2.

Nvidia GB203
Finalmente, Blackwell não oferece substituição direta do chip AD104, e o GB205 mais próximo em termos de características tem a mesma configuração dos últimos níveis da pilha de memória (48 MB de Kesha L2 e pneu Vram de 192 bits), mas noticeavelmente menor número de SM e Cuda-polar Fp32: 50 e 6 400, respectivamente.
Uma comparação da GPU antiga e nova mostra que a Nvidia conseguiu colocar um pouco mais do que o shader ALU em um milímetro quadrado de silício, mas o processo TSMC 4NP não trouxe o menor aumento na densidade média dos transistores (em cada escalão mesmo diminuiu um pouco), que afeta diretamente o custo da produção e ,,,,,,,,,,, por, em última análise, os preços de varejo das placas de vídeo.
⇡#Energia -Salvando Funções Blackwell
Outro problema de Blackwell, que vem da fotolitografia TSMC 4NP, é o consumo de energia. Os chips Ada Lovelace têm uma produtividade líder de watt entre a GPU da geração passada, mas os valores absolutos do consumo de energia na 50ª série aumentaram acentuadamente. Felizmente, os engenheiros da NVIDIA tomaram várias medidas para conter o “Zhor”.

A desconexão de blocos não utilizados do gerador de frequência (bloqueio de relógio) ocorre anteriormente e mais seletivamente do que nos chips ADA Lovelace. A Blackwell também usa linhas de alimentação separadas dos núcleos de computação da GPU e sistemas de memória, o que possibilita o ajuste de tensão individual para determinados cenários de carga ou a descenegização completa dos núcleos de computação para evitar vazamentos. Infelizmente, a NVIDIA não especifica quais estruturas nesse caso são chamadas de núcleos (TPC, GPC ou SM), mas se sabe que o desligamento/inclusão pode ocorrer na velocidade da mudança de turno.
Como resultado dessas inovações, o Silicon Blackwell é capaz de regular o consumo de energia muito mais rápido em resposta a uma mudança na carga, e um atraso na transição do regime ativo mais econômico para o sono profundo diminuiu por uma ordem de magnitude. Segundo a NVIDIA, Blackwell consome 50 % menos energia em certas tarefas de curto prazo em comparação com Ada Lovelace.

Além disso, os chips Blackwell estão subordinados ao novo sistema de controle de relógio. Nas soluções anteriores da NVIDIA, até Ada Lovelace, a frequência mudou dinamicamente, mas foi registrada durante a renderização de um quadro. Agora, a resolução temporária do ajuste da frequência é aumentada em 1000 vezes, o que permite que a GPU use efetivamente a reserva de energia ou, inversamente, reduza o consumo de energia no curto período de inação relativa (por exemplo, enquanto recebe comandos do processador central) .
⇡#Memória de vídeo GDDR7
Uma das inovações do título da 50ª série GeForce é o suporte à memória de vídeo GDDR7 Sgram, que fornece largura de banda máximo de 32 Gbit/s com perspectivas de até 48 Gbit/s. O novo padrão VRAM difere no nível físico da memória GDDR6 generalizada e do GDDR6X, exclusivo para produtos da NVIDIA.
A interface de memória SDRAM de uso geral e o gddr sgram até a sexta versão codificam o sinal usando a modulação da amplitude-moppulis com dois níveis de sinal (PAM2), e a taxa de transferência desde o momento da transição para o DDR aumentou aumentando a velocidade simbólica (em in em o boda), que apresenta tudo mais rigoroso para o comprimento e a fiação das linhas de transmissão. Outras interfaces de alto desempenho, como PCI Express, USB e Ethernet, também enfrentaram esse problema, e a solução geral é a introdução de níveis adicionais de PAM.
Portanto, a memória de vídeo GDDR6X, desenvolvida pela Micron em colaboração com a NVIDIA, distingue quatro níveis de sinais e, portanto, transfere 2 batalhas de informação por ciclo, que, no entanto, não levaram a uma duplicação em condições práticas. A codificação PAM4 é especialmente sensível ao sinal/ruído, portanto, o GDDR6X não pode funcionar na mesma alta velocidade simbólica que GDDR6. No final, dois padrões chegaram à mesma taxa de dados de 24 GB/s, mas o GDDR6X é caracterizado pela complexidade dos circuitos de nível físico nas duas extremidades da linha e no consumo de alta energia. Sem mencionar o fato de que o único cliente desses microcircuitos é a NVIDIA, e o fornecedor é a Micron.

Ao contrário do GDDR6X, a tecnologia GDDR7 é padronizada por JEDEC, e Micron, Samsung e Sk Hynix já começaram a liberar os chips. A interface física GDDR7 como um compromisso entre a codificação tradicional PAM2 e PAM4 usa três níveis de sinais (-1, 0 e +1) e transfere 3 bits de dados para dois ciclos. Assim, foi possível diminuir o aumento da frequência do pneu VRAM, mas, ao mesmo tempo, os requisitos para a relação sinal/ruído do GDDR7 abaixo em comparação com o GDDR6X. Além disso, a memória GDDR7 suporta a correção de erro intra -ChIP (que anteriormente se tornou um atributo obrigatório do DDR5), possui uma tensão de potência reduzida e uma função de saída rápida do modo de dormir. O volume máximo do chip foi aumentado de 32 para 64 Gbit (8 GB), embora ainda esteja longe da produção em massa de tais chips densos. No contexto das placas de gráficos de consumo, é mais interessante que os volumes não warranty sejam permitidos – como 24 Gbit.
⇡#PCI Express 5.0, códigos de vídeo e saída de imagem
Além do VRAM, os processadores gráficos da NVIDIA estavam à frente dos chips de consumidores de concorrentes na migração para o barramento do sistema PCI Express System de 5ª geração, que há muito tempo está disponível em PCs de mesa, mas foi dominado apenas por acionamentos de estado sólido. Três linhas sênior de GPU Blackwell -UPs usam toda a largura da interface de 16 linhas.
Finalmente, houve alterações na multimídia ASIC e nos controladores de exibição. A GPU executa codificação e decodificação de hardware do vídeo H.264 e HEVC com subdiscreto de cores YUV 4: 2: 2, que fornece a melhor resolução de cores que a codificação Yuv 4: 2: 0 prevalecendo nesses formatos. Os chips de Blackwell têm dois decodificadores NVDEC, como Ada Lovelace, mas, de acordo com estima a NVIDIA, sua velocidade ao trabalhar com H.264, que na geração anterior foi visivelmente menor do que ao processar o HEVC e AV1, dobrou. Quanto aos codificadores, o cristal GB202 recebeu um bloco adicional de NVENC, além dos dois primeiros. E, finalmente, a codificação de hardware AV1 é complementada pelo novo modo de alta qualidade. Este último estará disponível no ferro da 40ª série, mas Blackwell oferece alta qualidade.

O controlador de exibição é compatível com as versões mais recentes das interfaces de saída da imagem: HDMI 2.1B e DisplayPort 2.1b no modo UHBR 20 mais alto (20 GB/s na linha e 80 GB/s ao usar todas as quatro linhas).
Arquitetura de computação SM
Enquanto o chip sênior GB202 equilibra a parada prolongada em um nó fotolitográfico de 5 nm com dimensões enormes e potência sem precedentes consumidos, os processadores gráficos dos trens a seguir podem confiar apenas na otimização da arquitetura. A série Blackwell trouxe mais melhorias na lógica da GPU verde do que a Ada Lovelace, e elas são mais qualitativas do que quantitativas.
A hierarquia de alto nível dos componentes do processador gráfico não é alterada desde os chips de amperes. A maior unidade escalável no diagrama de blocos é o GPC (cluster de processamento gráfico), que combina todos os estágios do transportador de renderização de um rasterizador que executa a geometria em pixels, até 16 blocos de operações de rasterização (ROP). Entre eles está uma matriz de multiprocessadores de streaming (SM), cada um dos quais é um análogo formal do núcleo do processador central-como a unidade de computação na arquitetura gráfica AMD e XE-core nos chips Intel.
Os pares de SM, amarrados a um motor geométrico comum, formam a estrutura intermediária do TPC (cluster de processamento de rosca). O número TPC dentro do GPC varia de um chip para outro e atinge 16 no principal GB202.

Finalmente, o próprio multiprocessador de streaming é dividido em quatro subseções (SM Subparition, SMSP). Cada uma das seções possui seu próprio arquivo de registro (a parte mais rápida da pilha de memória da GPU), o planejador e o despachante da equipe, ao qual vários blocos de computação estão conectados – incluindo o núcleo tensorado e duas baterias de 16 shaders ALU (que de outra forma, pode ser chamado SIMD16 usando a terminologia da AMD e Intel). Escrevemos em detalhes sobre como os processadores gráficos da NVIDIA funcionam nesse nível baixo, escrevemos na revisão teórica da arquitetura de ampere. A próxima iteração de silício, Ada Lovelace não carregou as principais mudanças na lógica do SM.
A principal inovação de Blackwell é que, se apenas um dos dois SIMD16 poderá realizar cálculos inteiros em vez de operações sobre vírgulas de natação, agora elas são funcionalmente equivalentes, o que significa que o desempenho da GPU nos cálculos Pure INT3 está envolvido. As instruções para operações nos dados FP16 (não matriz) ainda são realizadas por unidades SIMD16 sem embalagem, o que significa no mesmo ritmo que Fp32.

A taxa de transferência total de quatro núcleos tensores SM foi atrasada em 1.024 instruções da FMA com dados FP16 para uma batida (que são dispostos em 2.048 operações), mas a GPU agora pode processar dados materialmente de uma descarga ainda menor – FP4 – em uma proporção proporcionalmente mais alta Velocidade que FP16 ou FP8.
Além dos recursos de computação listados, os blocos SM SIMD4 são projetados para executar operações trigonométricas, quatro escalares e ALU de dupla precisão (FP64), que garantem a compatibilidade básica da GPU do consumidor com um código semelhante. A NVIDIA não relata nenhuma alteração associada a esses componentes secundários. O volume de instalações de armazenamento interno permaneceu o mesmo: Kesha L1 e o arquivo de registro.
Mas os blocos de bloqueio, que também fazem parte do SM, aprenderam a produzir uma amostra pontual duas vezes mais rapidamente, o que não afeta a filtração textual (bilinear, trilneal, anisotrópica), mas é importante para uma função como texturas de compactação usando o Rede neural (na qual abordaremos mais tarde).
Assim, o desempenho bruto para o relógio da operação de SM em comparação com a ADA Lovelace aumentou apenas em relação aos cálculos inteiros de precisão padrão (INT32). As regras para a coexistência de cargas heterogêneas dentro de uma subseção SM separada permaneceu em vigor. O INT32 pega a taxa de transferência do FP32, e o despachante pode fornecer apenas uma instrução para a batida de qualquer um dos vários tipos de unidades de computação, mas devido à latência do desempenho de pelo menos dois tatos, o paralelismo é mantido.
2 × SIMD32 (fp32/int32); 2 × SIMD32 (FP32);
2 × SIMD2 (FP64);
2 × SIMD8 (SFU);
2 × ALUs escalares
8 × SIMD16 (FP32);
8 × SIMD16 (INT32);
8 × SIMD2 (FP64);
8 × SIMD4 (SFU);
8 × XMX
4 × SIMD16 (fp32/int32);
4 × SIMD16 (FP32);
2 × SISD? (FP64);
4 × SIMD4 (SFU);
4 × ALUs escalares;
Núcleos tensores 4 ×
8 × SIMD16 (fp32/int32);
2 × SISD? (FP64);
4 × SIMD4 (SFU);
4 × ALUs escalares;
Núcleos tensores 4 ×
128×FP32;
64 x INT32;
256 × FP16;
4 × FP64;
Funções de 16 × trans-e
128×FP32;
128 × Int32; 256 × FP16;
16 × FP64;
32 × funções transc-e
128×FP32;
64 x INT32;
128 × FP16;
2 × FP64;
Funções de 16 × trans-e
128×FP32;
128×INT32;
128 × FP16;
2 × FP64;
Funções de 16 × trans-e
A arquitetura gráfica da Intel XE2 tem várias vantagens formais sobre Blackwell. Assim, os cálculos inteiros e materiais podem ocorrer em paralelo a toda velocidade, a ALU correspondente é inicializada em uma batida junto com a matriz de matriz XMX, e as instruções FP16 são embaladas em pares e executadas em um ritmo duplicado. Quanto aos aceleradores “vermelhos”, a lógica do rDNA3 em teoria desenvolve a mesma capacidade do FP32 que Blackwell e funciona duas vezes mais rápido que metade da precisão. No entanto, um conjunto de instruções de rDNA restringe -se fortemente as possibilidades de extrair o paralelismo máximo, sem mencionar o atraso de quatro vezes por trás dos concorrentes na computação matricular e a ausência de macacões densos Alu alocados para esse fim – como o núcleo do tensor ou XMX.
⇡#Rastreamento de raios e mega geometria
A NVIDIA aumenta constantemente a velocidade do rastreamento de hardware dos raios. Desta vez, a velocidade de um único bloco de RT aumentou de dois para quatro testes do raio com um triângulo pela batida. O número de interseções com caixas de BVH, que ocorrem em paralelo, ainda permanece em segredo, mas os chips da NVIDIA, pelo menos em um aspecto, antes do concorrente mais próximo-a arquitetura de Intel Xe2-Which realiza 2 testes do feixe com um triângulo e 18 Interseções com caixas BVH para um tato do bloco RT. Por sua vez, o bloco RT na composição do rDNA3 pode determinar apenas uma interseção de um feixe com um triângulo para uma batida ou quatro cruzamentos com um boxe, e a passagem da estrutura BVH é realizada por software, no shader alu .
Além disso, a Nvidia introduziu um conjunto de ferramentas de software chamado Mega Geometria, projetada para facilitar a tarefa de rastrear raios em condições de geometria complexa e dinâmica. Os algoritmos LOD modernos (nível de detalhe) – como nanite no motor irreal 5 – variam de maneira suave as grades poligonais, substituindo pequenos aterros (cerca de 128) para eliminar os saltos visíveis para detalhamento ao alterar a distância do ponto de visualização para o objeto. No entanto, cada etapa LOD complica acentuadamente a geração BVH, tão honesto traço de raios em combinação com nanite e sistemas similares não tem significado prático, e a BVH é baseada em uma proxy-geometria simplificada.
A abordagem da mega geometria é que o algoritmo LOD opera com entidades que são refletidas nativamente na BVH. Para esse fim, um novo tipo de BVH primitivo é introduzido estruturas de aceleração no nível do cluster. O CLAS é uma coleção de grupos localizados de triângulos, que é gerado sob demanda (por exemplo, quando o objeto de cena é carregado no disco) e pode ser conversado para uso em novos quadros. O nível de detalhamento da grade poligonal é alterado substituindo CLAs e, devido ao fato de o CLAS contém cerca de cem triângulos, a velocidade de cada reestruturação do BVH pode ser aumentada em duas ordens de magnitude.

As primitivas do CLAS encontrarão uso não apenas em jogos. A animação 3D profissional usa o algoritmo de superfície de subdivisão, que permite formar superfícies curvilíneas por complicação recursiva da malha poligonal e é tradicionalmente realizada na CPU. Para a superfície da subdivisão da superfície da subdivisão, o processador gráfico é necessário para realizar um teselia de curvas em triângulos, o que implica a construção de BVH volumétrico em cada quadro. Esse processo, novamente, pode operar com clusters de polígonos de célula.

Outra inovação da mega geometria permite que você simplifique a geração BVH, graças ao novo tipo de estrutura de aceleração de nível superior da estrutura de nível superior (PTLAS)-e repousa sobre a mesma idéia: abrir uma aplicação 3D de acesso direto a BVH, então que a GPU cumpre uma certa parte do trabalho uma vez e ele usou os resultados no futuro. Portanto, se o mecanismo do jogo souber que certos objetos da cena do jogo permanecerão estáticos por algum tempo em relação ao ponto de vista, eles podem ser levados para o BVH de suas próprias seções, que não serão reconstruídas sem a necessidade de cada próximo quadro .
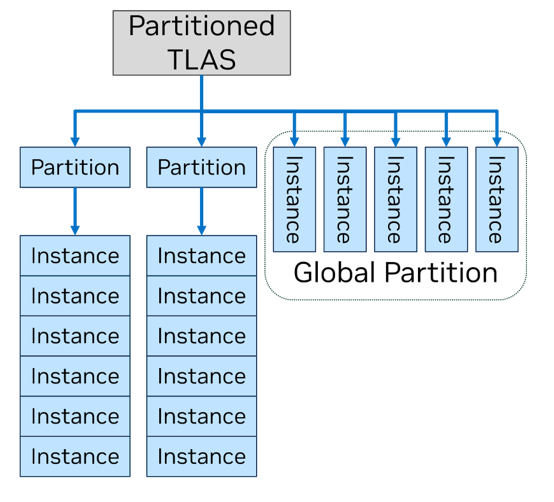
As chamadas de mega geometria são projetadas para processamento de pacotes, que permite descarregar completamente a CPU de tarefas como a seleção do LOD, e o acesso é realizado por meio de extensões de marca NVAPI, Optix e Vulkan. Esta é uma API proprietária e o suporte no nível de funcionalidade padrão Direct3D e Vulkan ainda não foi discutido. Quanto aos requisitos de hardware, a mega geometria é compatível com quaisquer cartões RTX-Video, mas, é claro, funciona melhor nos chips Blackwell, que possuem lógica especializada (mecanismos de cluster) para compressão de hardware de geometria e BVH. Segundo a NVIDIA, o consumo de memória de vídeo em tarefas como reiterar com nanita, foi possível reduzir em centenas de megabytes.
Finalmente, o Blackwell RT-Yaro é capaz de verificar a interseção de um raio com uma esferas lineares primitivas geométricas (LSS) projetadas para modelagem de cabelo realista, pêlo, ervas e objetos semelhantes. A figura do LSS é formada movendo a esfera ao longo da trajetória de vários segmentos lineares enquanto altera o raio e permite que você se livre de artefatos característicos do método predominante de aproximação de estruturas encadeadas – usando a cadeia de aterros sanitários (pontos, tiras de triângulo ortogonais desjuntos ).

Além disso, as esferas podem ser usadas sem mover (por exemplo, para renderizar partículas). O novo primitivo não apenas permite criar modelos melhores, mas, de acordo com a NVIDIA, a renderização do LSS ocorre duas vezes mais rápida, e a memória de vídeo é necessária cinco vezes menor que o uso de pontos.
⇡#Execução de shader Reordenando o processador de gerenciamento 2.0 ai (AMP)
Uma das poucas inovações da arquitetura Ada Lovelace foi a capacidade de reagrupar dinamicamente as instruções (reordenação de execução do shader) para aumentar a coerência do acesso à memória – por exemplo, sob circunstâncias como a execução de pixels shaaders no estágio do secundário, refletiu os raios.

A eficácia da lógica do SER nos chips de Blackwell, de acordo com a NVIDIA, dobrou em termos de estimativas da precisão dos custos de reagrupamento e desempenho para esta operação. O SER também ajuda a carregar os núcleos tensores, o que é importante para o desempenho de novos shaders neurais. O acesso às funções Seru é explicitamente através de uma API especial, que já foi dominada por alguns jogos com rastreamento de maneiras e pacotes de renderização em 3D profissional.

O FRONTND GPU é complementado por um planejador de contexto totalmente programável com base em um processador de gerenciamento de arquitetura RISC-V separado (AMP). As iterações anteriores dos chips “verdes”, começando com Turing, já tiveram um planejador de hardware, mas o AMP é mais flexível e, portanto, efetivamente, distribui o tempo da GPU em um ambiente multitarefa. Durante o jogo, o AMP foi projetado para reduzir o atraso de entrada, destacando o tipo de carga prioritário – por exemplo, as redes neurais DLSS.
⇡#DLSS 4
Da mesma maneira que o DLSS apscaling com a característica das placas de vídeo GeForce 40 Gaming, o cartão de visita da nova geração foi gerado usando uma rede neural de vários quadros seguidos – até três – que é baseado nos recursos do Blackwell Chips e, é claro, não é compatível com as iterações anteriores da arquitetura. O algoritmo de geração, de acordo com a NVIDIA, é 40 % mais rápido e consome 30 % menor de memória de vídeo. É curioso que, ao mesmo tempo, o cálculo do hardware do fluxo óptico não seja mais usado pela multimidina ASIC, que se tornou um obstáculo (pelo menos formal) para abrir a geração de quadros de aceleradores de ampérea – agora esta função é executada por um separado Rede Neural.
A taxa de quadros é controlada pelo hardware, na lateral do controlador de exibição, e não o processador central. Por sua vez, o planejador de processadores de gerenciamento de IA foi projetado para regular a prioridade de certos estágios de renderização, a fim de reduzir o atraso e minimizar o retirado estocástico da frequência do pessoal.
É importante observar que a geração de pessoal (especialmente múltipla, MFG), por mais alta qualidade que a imagem não seja uma substituição completa da renderização “honesta” em outro aspecto. O fato é que o tempo da reação de entrada depende da distância entre o pessoal que passou por toda a lógica do mecanismo de jogo – em outras palavras, essa estrutura que a GPU pode desenvolver sem gerar pessoal com uma rede neural (mas, opcionalmente, com escala). Portanto, o MFG tornará os movimentos mais suaves, mas o jogo não se tornará responsivo se a frequência inicial do pessoal estiver abaixo de um valor confortável (por exemplo, 60 fps).
A geração de pessoal, pelo contrário, tira a GPU alguma parte dos recursos de computação e, ceteris paribus, aumenta o tempo de reação. Portanto, o MFG foi projetado para trabalhar em conjunto com a nova versão da tecnologia Reflex. O último usa a técnica de distorção de quadros, emprestada do ambiente de VR: antes de enviar para o monitor, o quadro muda dependendo do último movimento do mouse.

O treinamento em máquinas da quarta versão do DLSS é baseado no modelo de transformador em vez de redes neurais adesivas (CNN, Convolution Neural Networks), que a NVIDIA usou anteriormente devido à sua complexidade computacional relativamente baixa. A CNN é uma estrutura hierárquica, que (em relação ao processamento da imagem) é realizada por padrões visuais que lançam camadas na direção a partir da parte inferior para cima – de grupos de pixels localizados a objetos grandes. Ao mesmo tempo, a própria operação de espaçamento é local, ou seja, é aplicada à área isolada da imagem, e o algoritmo geral sempre funciona o mesmo em determinados dados.
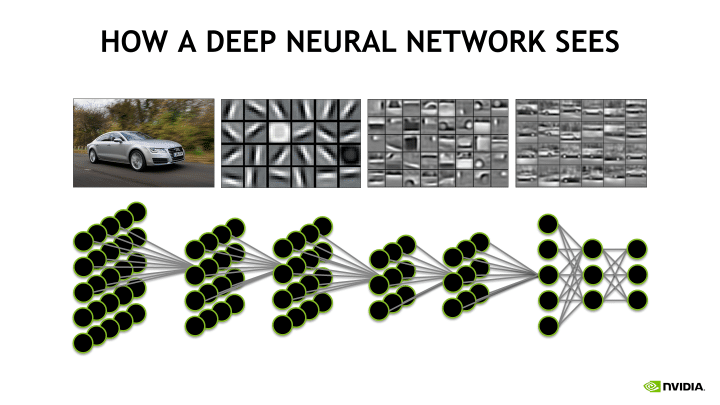
Pelo contrário, a propriedade chave do transformador é a atenção assim chamada (ou autoconfiança), que permite integrar o material processado e os cálculos diretos aos dados mais importantes. Graças a isso, os Transformers encontraram ampla aplicação em tarefas com um componente seqüencial pronunciado – como análise da fala. No contexto dos DLSs, os transformadores são mais eficientes que a CNN, eles são reconhecidos por grandes padrões e são mais fáceis de escalar, permitindo que você domine o dobro de dados iniciais e carregue mais fortemente os núcleos do tensor da GPU.
Como resultado, o trabalho de todas as funções do DLSS muda qualitativamente, incluindo não apenas apccilling, mas também reconstrução dos raios e suavização do DLAA na resolução nativa. O DLSS 4 permite que você use transformadores na glândula antiga, começando com a geração tena.

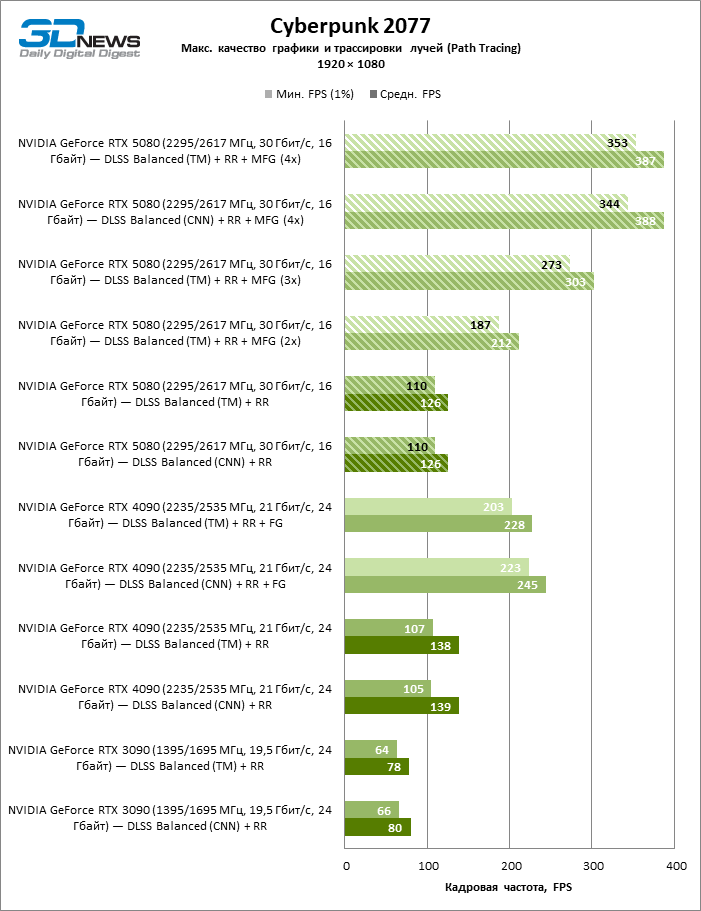
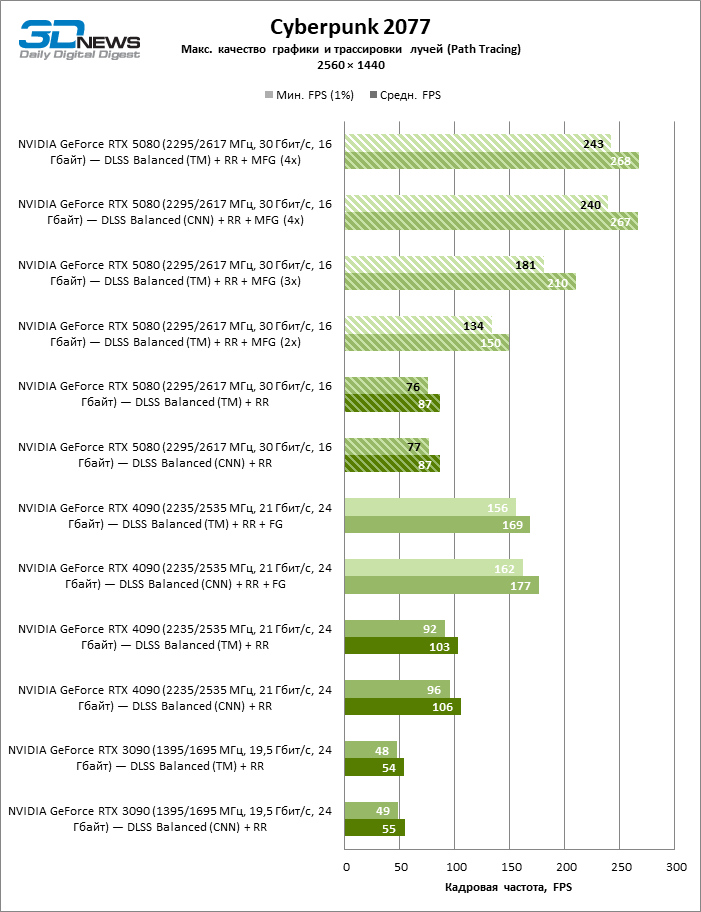
O aplicativo NVIDIA Desktop pode forçar o MFG (assim como outros parâmetros, incluindo o modelo de rede neural) em várias dezenas de títulos que suportam o DLSS, mas ainda não foram atualizados para a última versão. Antecipando o início das vendas da 50ª série, tivemos a oportunidade de testar as novas funções de Apxeyler apenas no Cyberpunk 2077, que já recebeu uma compatibilidade nativa com o DLSS 4. Como você pode ver, a geração de múltiplos funcionários e Realmente garante o crescimento múltiplo da estrutura da escala usual. Quanto ao modelo de rede neural, mas, para nossa surpresa, os transformadores não causam quase uma perda significativa de desempenho em comparação com as redes bundais, mesmo na GPU verde de um ano -geração.
⇡#Shaders neurais
Finalmente, mais um – definitivamente, não tão provocativo quanto o MFG, mas promissor – a iniciativa é que as redes neurais que trabalham nos núcleos tensores podem participar diretamente do desempenho dos shaders, aproximando o resultado do objetivo geral do objetivo geral. Ao mesmo tempo, o treinamento em rede neural é realizado localmente, na própria GPU, às vezes até em tempo real. A Microsoft já está trabalhando na interface de programação de vetores cooperativos, que permite multiplicar matrizes com o tamanho arbitrário de vetores em qualquer código de shader, necessário pelos neuralados. A nova API não está vinculada ao Ferro Nvidia e, em um futuro próximo, deve se tornar parte do Direct3D.
Os cenários do uso de shaders neurais são diversos, mas a NVIDIA citou um exemplo de várias tarefas que receberão o crescimento máximo da velocidade. Portanto, os shaders neurais são capazes de substituir parcialmente o modelo matemático de materiais multicamadas complexos por redes neurais. Uma tarefa relacionada é simular a dispersão de luz subterrânea em um ambiente translúcido – como a pele das criaturas vivas. Nos jogos para isso, eles ainda não usam o traço dos raios devido à alta complexidade computacional, que, novamente, são projetados para corrigir os shaders neurais.

A Nvidia propõe atrair IA generativa completa para tornar pessoas humanas. Um retrato rasterizado e coordenadas espaciais são tomadas como base, e a rede neural, anteriormente treinada em uma grande variedade de imagens, torna o rosto natural.

Outro tipo de shader neural é o cache de radiação neural (NRC), que simplifica a renderização de iluminação global usando o Rays Trace. A rede neural do NRC treina continuamente em tempo real para formar um modelo aproximado de reflexão secundária dos raios. Como resultado, o rastreamento é limitado aos raios primários e os caminhos das seguintes ordens são enviados para Kesh.

Finalmente, com a ajuda de shaders neurais, é possível uma compressão de texturas mais eficiente e de alta qualidade do que o uso de métodos tradicionais: a NVIDIA demonstrou uma economia de três vezes no volume VRAM. É curioso que, neste caso, a imposição de textura ocorra sem filtração de hardware (trilneina ou anisotrópica). Em vez disso, a filtração estocástica é usada com base em uma amostra de ponto aleatório para eliminar artefatos (escadas, muar etc.).
⇡#Especificações, preços
O GeForce RTX 5080 é baseado em um cristal GB203 completamente funcional, que é atípico para a NVIDIA, mas é justificado à luz de pequenas alterações na fórmula dos blocos de computação em comparação com o AD103. Se você tomar o GeForce RTX 4080 e o RTX 4080 Super no ponto de referência, a frequência do relógio da GPU recebeu um aumento simbólico em 67-112 MHz, o que significa que o crescimento intercorais da produtividade bruta nos calculativos FP32 é reduzida a processadores gráficos miseráveis de 8 a 15 % de Tflops.
O GeForce RTX 5080 está equipado com 16 GB de memória de vídeo do padrão GDDR7 com uma largura de banda de 30 gbit/s, que fornece o PSP total de 960 GB/s – 30-34 % maior em comparação com duas variedades de RTX 4080. A referência A potência do novo produto também é visivelmente maior que o RTX 4080 e o RTX 4080 Super, projetado para consumo de energia de 320 watts.
Com essas características, o GeForce RTX 5080 nada mais é do que uma atualização suave dos anos 80 dos modelos anteriores, mas isso não impediu a Nvidia de manter o custo recomendado de US $ 999. Portanto, mesmo que algumas das inovações da arquitetura Blackwell contribuam para o método tradicional de renderização, o valor do consumidor do RTX 5080 é completamente baseado na próxima versão do DLSS, agora com a função de gerar vários quadros.
Quanto ao GeForce RTX 5090, nesse caso, uma enorme variedade de blocos de computação GB202 foi cortada por 22 SM (ou 2.816 shader compatível com FP32 ALU), e a frequência do relógio da GPU foi reduzida em 113 MHz em comparação com RTX 4090. Nenhuma A diferença na velocidade teórica entre os principais modelos é de 27 %. Se levarmos em consideração que o cristal GB202 está se aproximando da área máxima do show de fotos do TSMC, a Nvidia apertou quase tudo, desde o processo de tecnologia de 5 nanômetros e não pode ser contado com os melhores resultados. O GeForce RTX 5090 possui 32 GB da memória GDDR7 e a capacidade de 28 Gbit/s em um pneu de 512 bits significa um enorme PSP 1.792 GB/s (78 % maior que o do RTX 4090).
A má notícia é que o GeForce RTX 5090 consome até 575 W e, o mais importante, custa US $ 1.999. custo-ou ainda mais nas condições da deficiência esperada. Ambos os dispositivos estão à venda hoje, para que os leitores já possam analisar os preços reais de novos produtos.
⇡#Palit GeForce RTX 5080 Gamerock: Construção
O GeForce RTX 5080 na modificação do Gamerock Palit opera em frequências de relógio de referência e é uma enorme placa de vídeo com exatamente as mesmas dimensões (331,9 × 150 × 70,4 mm), como na mesma versão do RTX 5090, que permite contar Na luz do TBP menor, aumentou o resfriamento dos componentes e o baixo ruído. O dispositivo ocupa quase quatro slots de expansão no caso do PC.

O painel frontal do invólucro possui uma superfície de espelho com áreas onduladas, que brilha com padrões de iluminação LED brilhantes. O padrão e a cor do LED podem ser ajustados separadamente ou sincronizados com a placa-mãe através do conector argb padrão, localizado próximo à entrada de 12V-2×6.

O perímetro da placa de vídeo cobre uma estrutura de alumínio fundida com slots de ventilação nos lados longos. No backplane, também um metal, já existe uma janela familiar que abre uma parte significativa do radiador para a passagem do ar.

O sistema de refrigeração é servido por três ventiladores com um diâmetro do impulsor de 92 mm. A baixa temperatura e carga na GPU, o dispositivo é resfriado passivamente.
O radiador é baseado na câmara evaporativa de forma complexa – grande o suficiente para cobrir o cristal do processador gráfico e dos chips VRAM. Como uma interface térmica entre a GPU e a câmara evaporativa, a pasta térmica comum é usada. Para cascatas de potência e acelerador de VRM, são fornecidos aquecedores lamelares separados, um dos quais está diretamente em contato com os tubos térmicos. O último aqui, a propósito, são nove pedaços.

Embora a placa traseira seja feita de metal, não há um único calor embaixo dela, o que significa que a placa não participa do resfriamento da PCB.

O kit de entrega de gamerock Palit inclui um adaptador de três conectores de energia de oito pinos ao plugue de 12V-2×6, o cabo de sincronização do ARGB, o suporte controlado pré-fabricado para a instalação rígida da placa de vídeo em uma posição horizontal e um pequeno mouse de tecido de tecido .

⇡#Palit GeForce RTX 5080 Gamerock: Impressão
A placa de vídeo é montada em uma PCB compacta, que, no entanto, possui um sistema de energia extremamente poderoso. A regulação da tensão na GPU e nos microcircuitos de memória de vídeo será gerenciada pelos controles de Monolith Power Systems MP29816 e MP2988 SWM. A VRM inclui um total de 19 fases, equipadas com Cascades de Power MPS87993. Sua corrente nominal não é conhecida exatamente por nós, mas, presumivelmente, é de 90 A.
A marcação da produção GDDR7 Chips Samsung (K4VAF325ZC-SC32) reflete 32 gbit/s capacidade-2 GB/s mais alto que as especificações do GeForce RTX 5080.


Palit Gamerock tem um interruptor de versão do BIOS. Um firmware é “silencioso”, o outro é “produtivo”. À medida que a escolha dos firmware atua nas frequências da GPU e na operação do sistema de refrigeração, descobriremos na próxima parte empírica da revisão.
⇡#Suporte de teste, metodologia de teste
Na maioria dos jogos, as taxas de quadros médias e mínimas (indicamos o 1º percentil da distribuição) são derivadas da matriz de tempos de renderização de quadros individuais ou da taxa de quadros instantânea obtida usando o benchmark integrado. As exceções são jogos que não possuem benchmark integrado e testes com geração de frames: nesses casos, utilizamos o programa OCAT para capturar intervalos entre frames.
A potência das placas de vídeo é registrada separadamente da CPU e de outros componentes do PC usando o dispositivo NVIDIA PCAT. A carga para testar os níveis de potência e ruído é Cyberpunk 2077 com resolução de 3840 × 2160 e configurações máximas de qualidade gráfica (sem ray tracing), bem como o teste de estresse FurMark com as configurações mais agressivas (resolução 3840 × 2160, MSAA 8x) . Todos os parâmetros são medidos após o aquecimento da placa de vídeo, quando a temperatura da GPU e as frequências de clock se estabilizam.
⇡#Participantes do teste
As seguintes placas de vídeo participaram do teste de desempenho:
- Nvidia GeForce RTX 5080 (2295/2617 MHz, 30 gbit/s, 16 GB);
- NVIDIA GeForce RTX 4090 (2235/2535 MHz, 21 Gb/s, 24 GB);
- Nvidia GeForce RTX 4080 Super (2295/2580 MHz, 23 gbit/s, 16 GB);
- NVIDIA GeForce RTX 4080 (2205/2505 MHz, 22,4 Gb/s, 16 GB);
- NVIDIA GeForce RTX 3090 (1395/1695 MHz, 19,5 Gbps, 24 GB);
- AMD Radeon RX 7900 XTX (1720/2499 MHz, 20 Gb/s, 24 GB).
Aprox. As GPUs básicas e de frequência de impulso são indicadas nos colchetes.
⇡#Velocidades de clock, consumo de energia, temperatura, ruído e overclocking
O processador gráfico GB203 na placa GeForce RTX 5080 suporta uma frequência de relógio de cerca de 2,8 GHz sob a carga do jogo – quase a mesma que o AD103 no GeForce RTX 4080 ou RTX 4080 Super. A tensão de alimentação da GPU não mudou muito.
Mas o consumo de energia do 80º modelo aumentou de 303-311 para 365-372 W no cyberpunk 2077 sem os raios de rastreamento. O Gamerock Palit Reserve completo está se aproximando completamente de 400 watts.
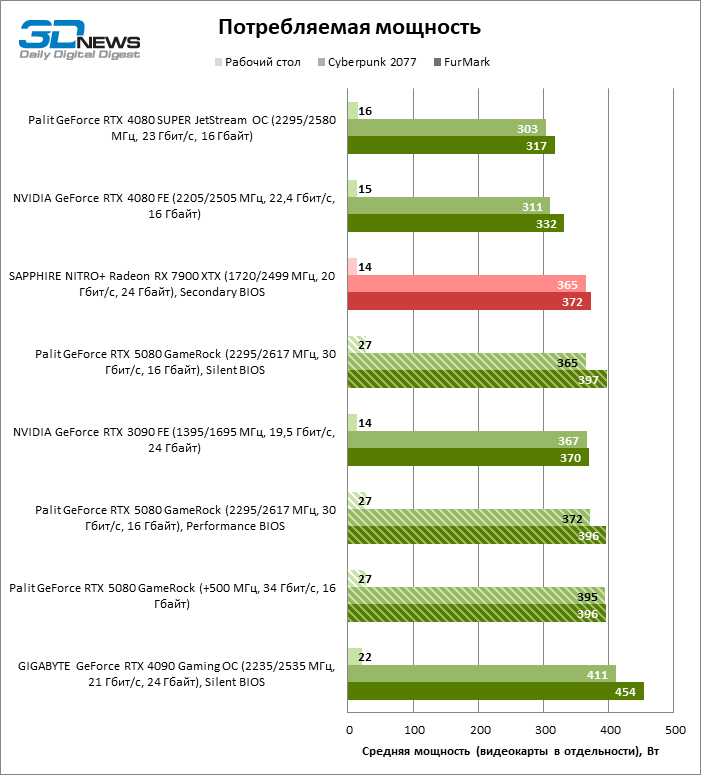
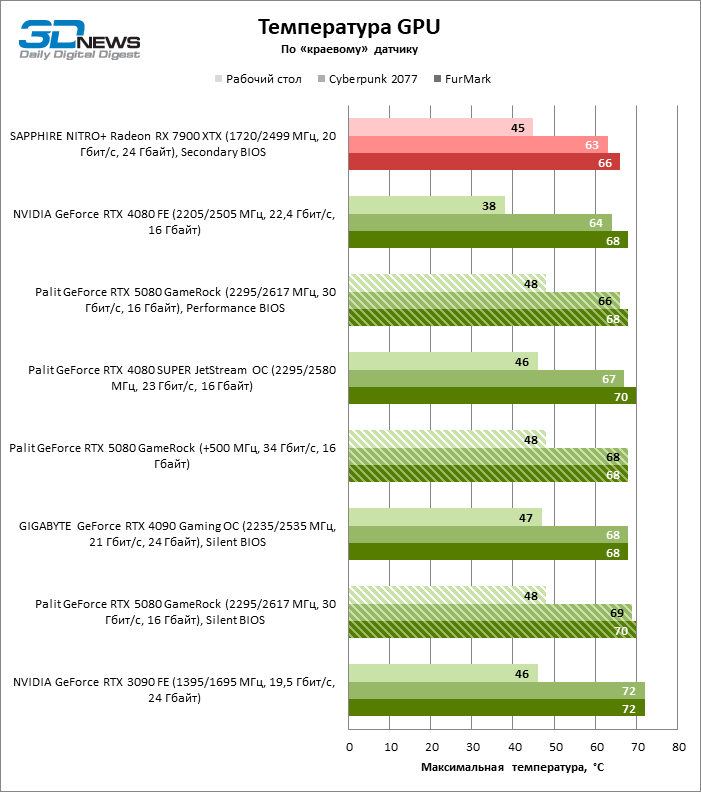
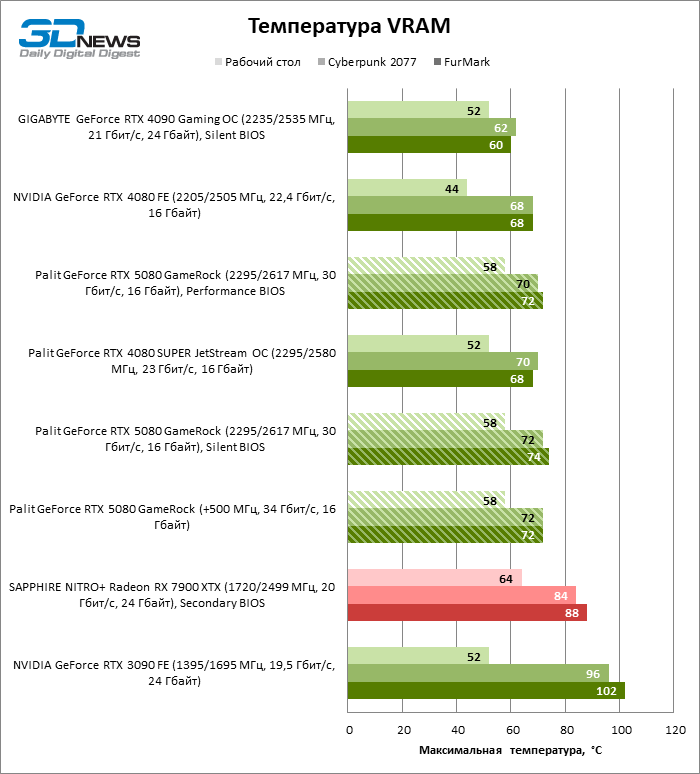
A alternância entre cópias “silenciosa” e “produtiva” do BIOS não regulamenta as frequências do relógio e um orçamento de energia, mas afeta a velocidade de rotação dos ventiladores. No entanto, a diferença na temperatura dos componentes ao usar firmware diferente não excede 3 ° C. Sob a carga de tensão, a GPU aquece da força para 70 e os chips de memória GDDR7 são 74 ° C, o que é um resultado muito típico para uma placa de vídeo moderna. Observe que o driver do Blackwell Chips não emite informações sobre a temperatura da zona de cristal mais quente. Se essa função retornará nas próximas versões do software ainda é desconhecida.
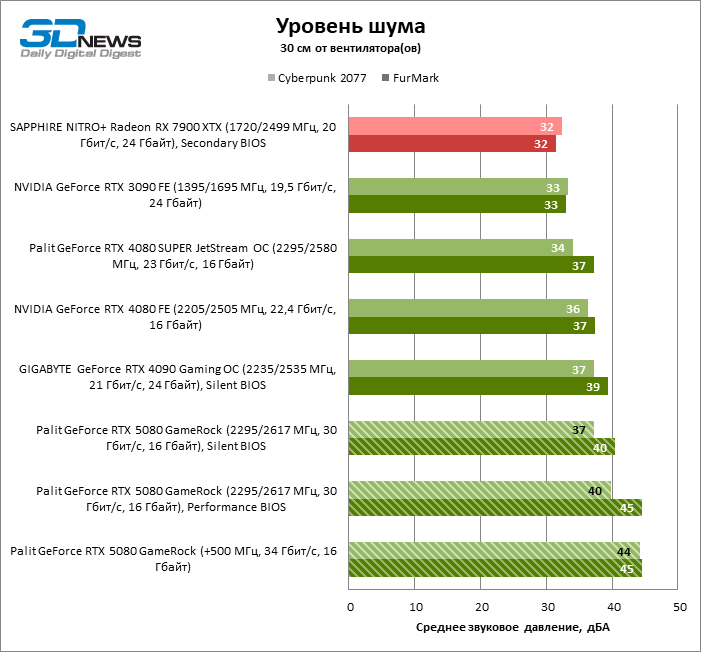
Apesar do alto consumo de energia do acelerador, o sistema de refrigeração do Gamerock Palit desenvolve um nível de ruído completamente aceitável até 37 dBA (a uma distância de 30 cm dos fãs) sob a carga do jogo – mas desde que o firmware “quieto” esteja ativo ativo . O BIOS “produtivo” aumenta a pressão sonora para 40 DBA nas frequências de relógio padrão e é bom apenas para overclock do usuário.
O GeForce RTX 5080 na modificação do Gamerock Palit (pelo menos sem uma marca de CO) não permite aumentar a TBP, o que, no entanto, não foi um obstáculo para overclock surpreendentemente produtivo. O GB203 mantém a estabilidade a uma frequência de 3,25 GHz (457 MHz acima do valor padrão) sob carga sem os raios de rastreamento, e a tensão de alimentação da GPU diminuiu automaticamente em 0,02 V. Esses resultados impressionantes provavelmente estão associados ao sistema de ajuste de frequência dinâmica atualizada. No entanto, flutuações constantes dentro da renderização de um quadro, atrás das quais o programa de monitoramento não tem tempo, também significa que, por algum tempo, a GPU não funciona em uma determinada frequência. Por sua vez, conseguimos dispersar os chips de memória de vídeo com a taxa de transferência inicial de 30 a 34 GB/s e, ao mesmo tempo, não há perda de velocidade devido à correção de erros.
A placa de vídeo dispersa Palit Gamerock consome quase inteiramente uma fonte de alimentação de cerca de 400 watts, mesmo em um teste de jogo sem Ray Trace. O sistema de refrigeração dominou o aumento da geração de calor sem danos à temperatura dos componentes, mas o nível de ruído saltou para 44 dBA.
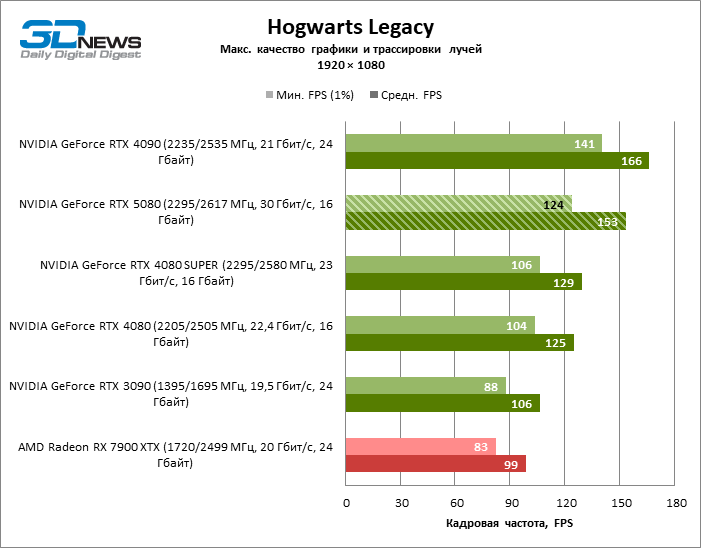
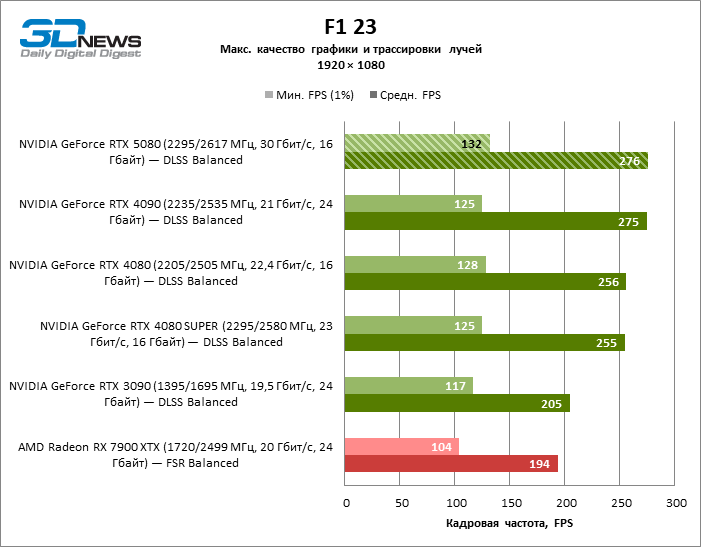
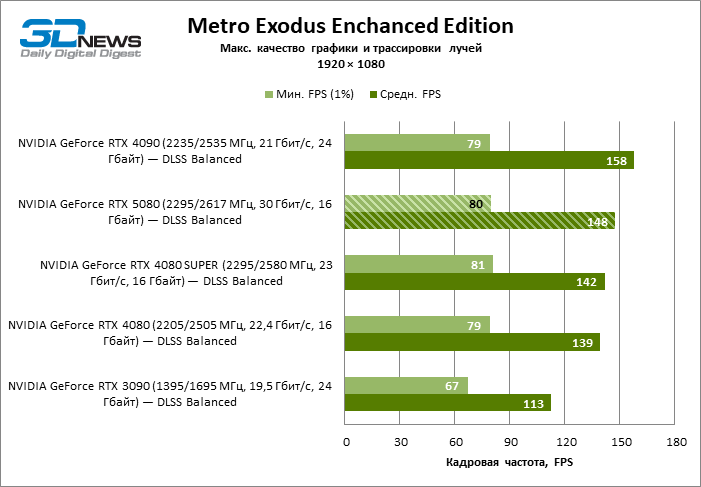
⇡#Testes de jogos (1920 × 1080)
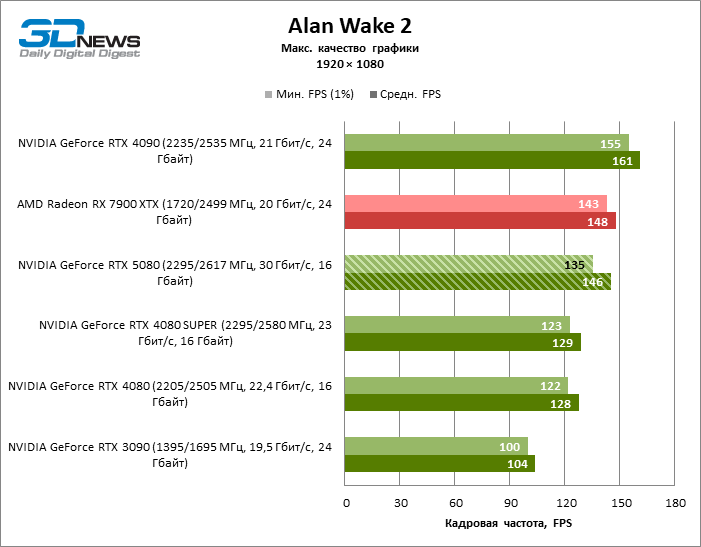
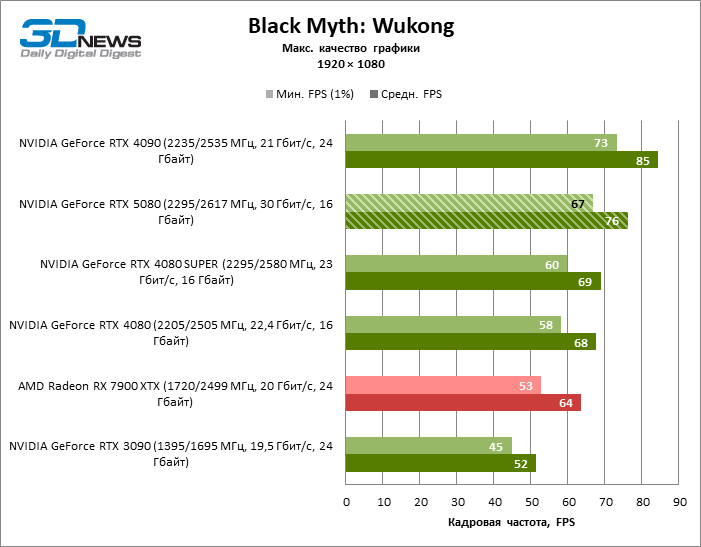
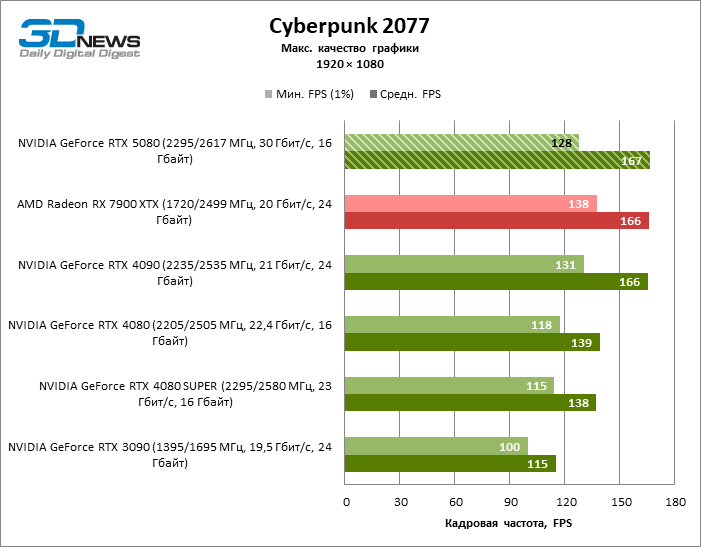
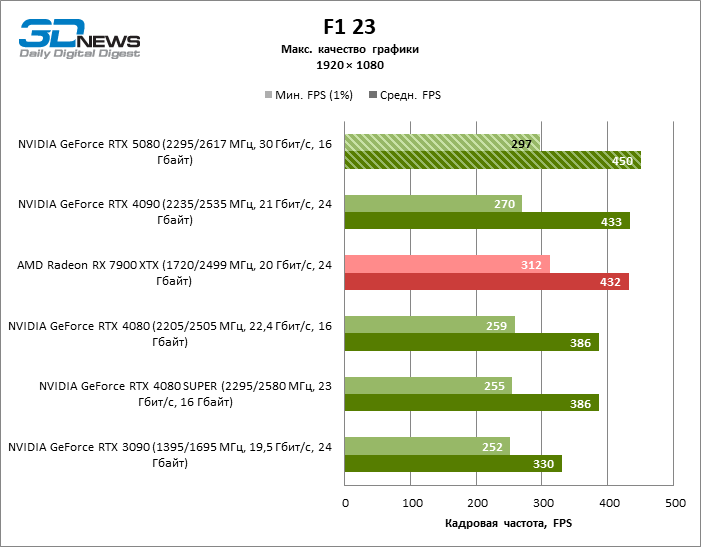
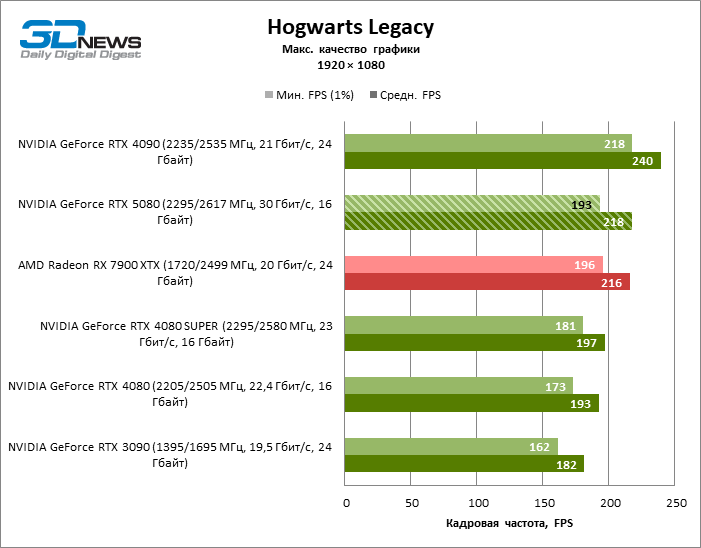
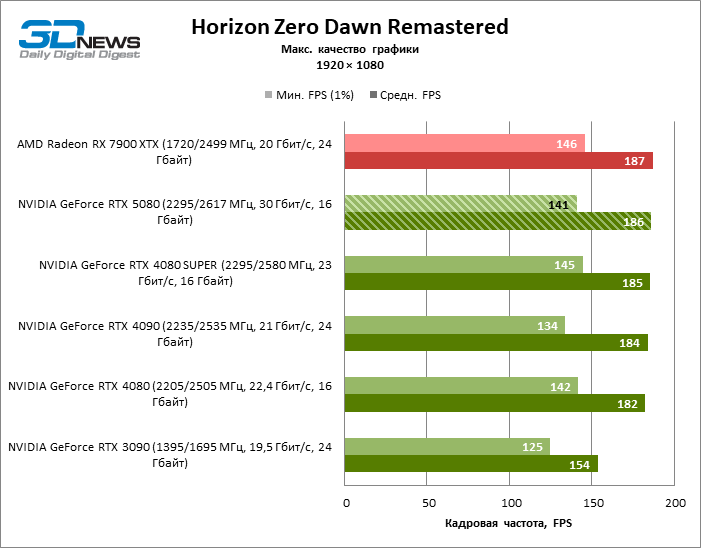
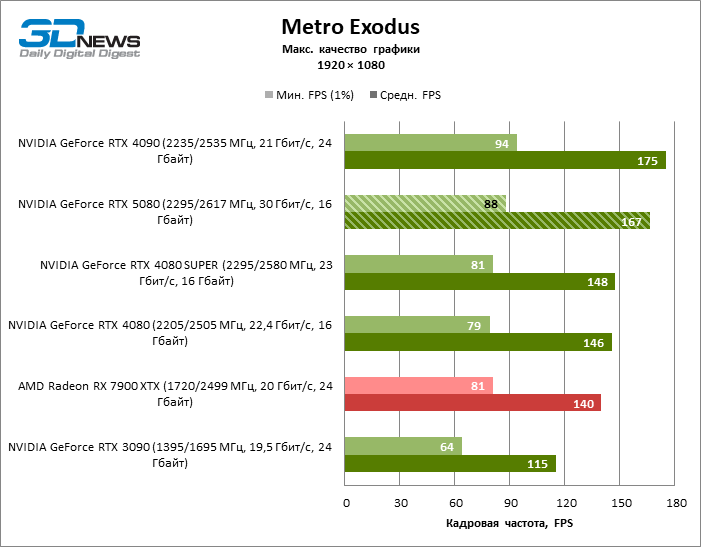
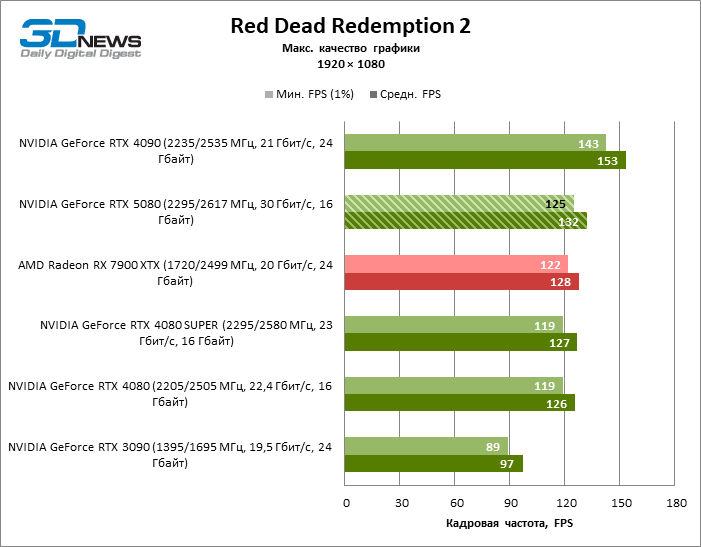
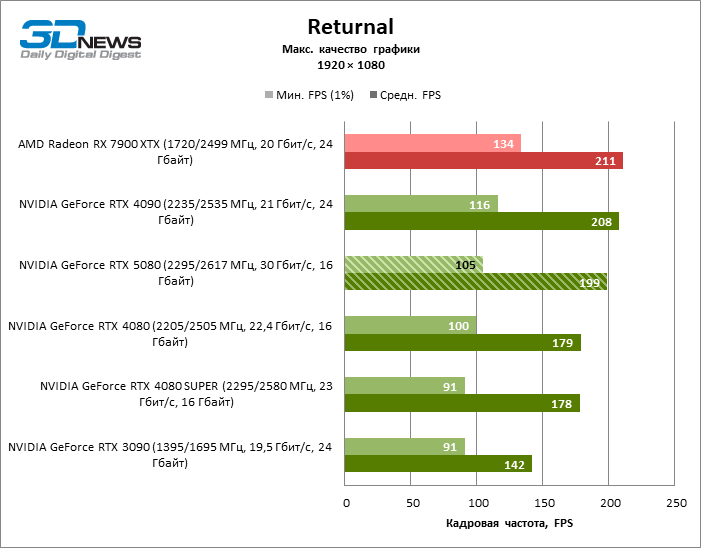
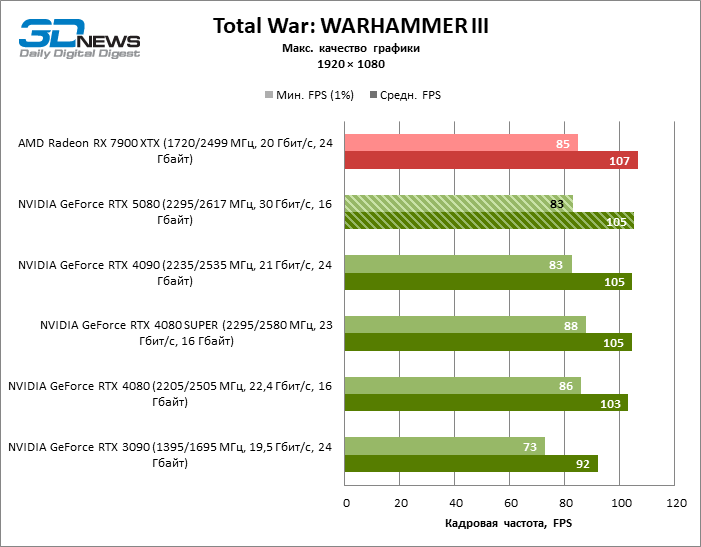
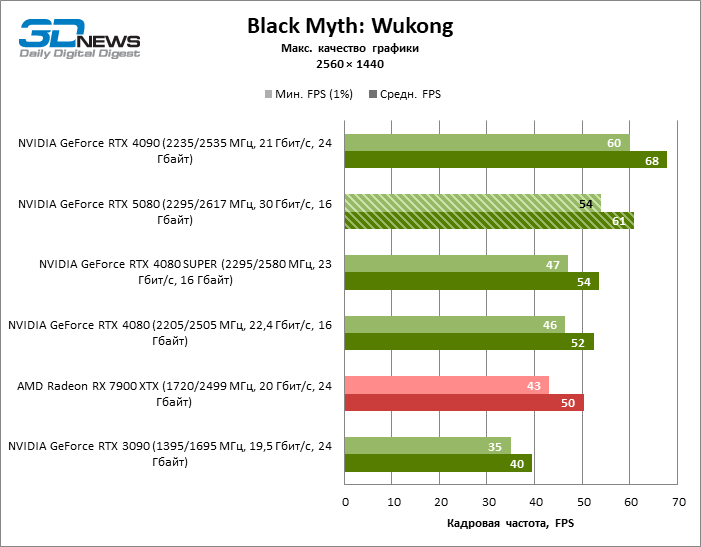
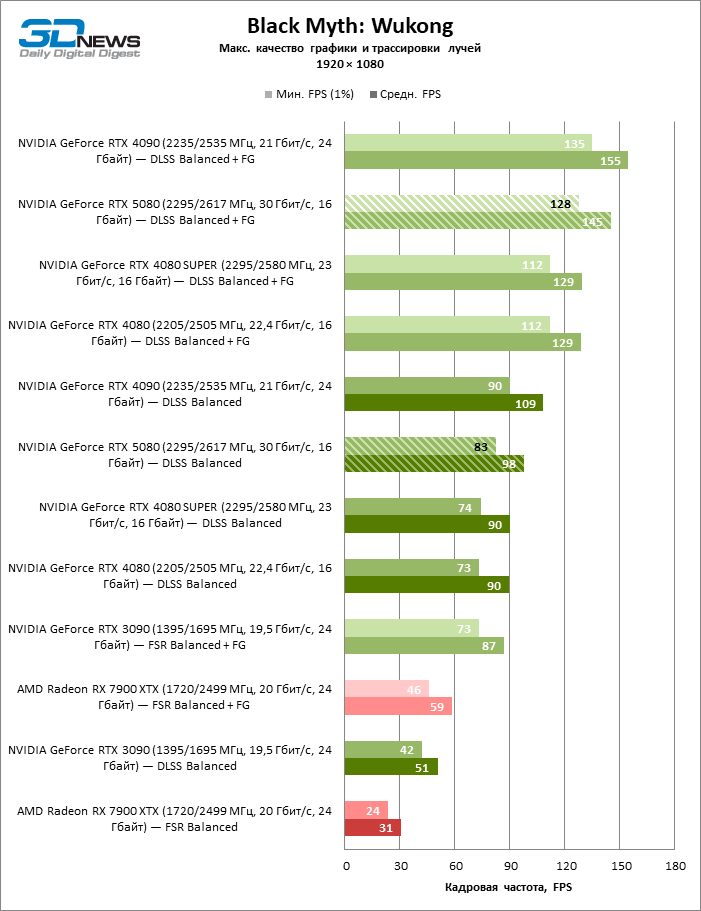
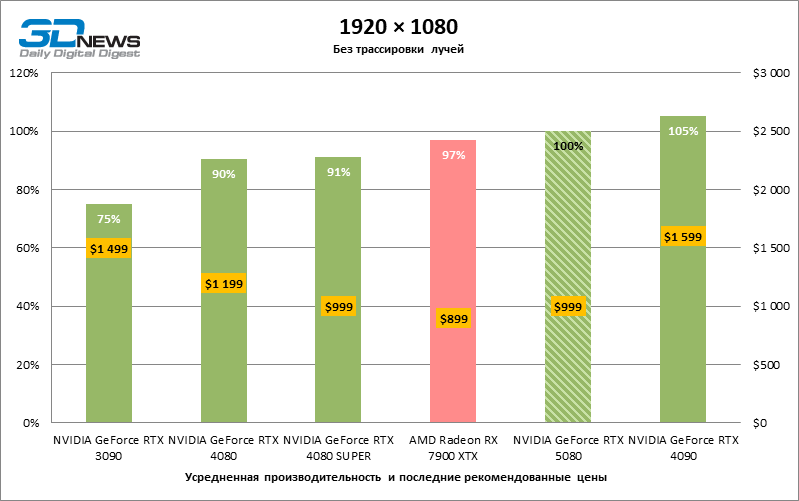
As placas gráficas GeForce RTX 5080 têm desempenho excessivo para jogos rasterizados no modo 1080p e, ao mesmo tempo, não podem funcionar com força total com baixa resolução de tela, mesmo em plataformas com processadores centrais avançados. Seja como for, o RTX 5080 desenvolve a frequência do pessoal é muito superior a 100 qps na grande maioria dos jogos de teste. Somente o mito negro: Wukong, onde a Framretic acima de 60 fps, dificilmente recebe até a GPU mais poderosa, foi uma exceção perceptível.
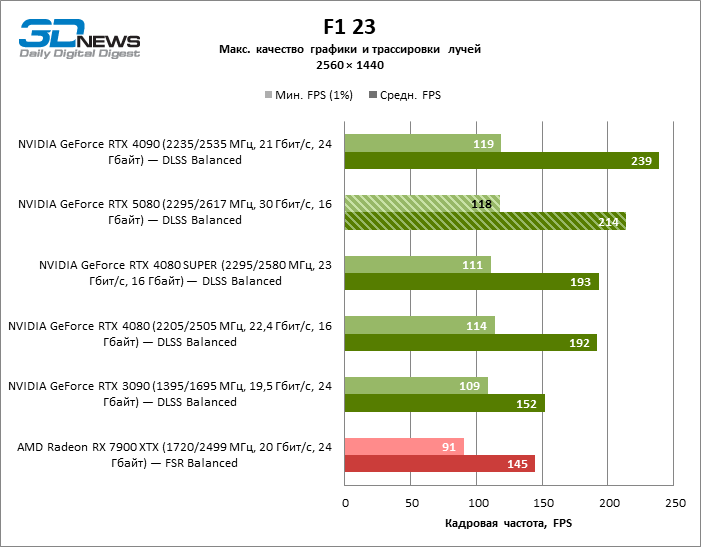
Devido às condições de teste não ideais, os resultados médios dos participantes dos testes são distribuídos em uma faixa muito estreita. No entanto, já podemos falar sobre algumas tendências. Assim, em comparação com o GeForce RTX 4080 ou RTX 4080 Super, a velocidade do 80º modelo aumentou apenas 10-11 %. O Radeon RX 7900 XTX é quase inferior à novidade, e o GeForce RTX 5090 tem uma vantagem igualmente insignificante. O GeForce RTX 5080 parece uma atualização notável apenas contra o fundo do GeForce RTX 3090, fornecendo um aumento no quadro médio de 33 %.
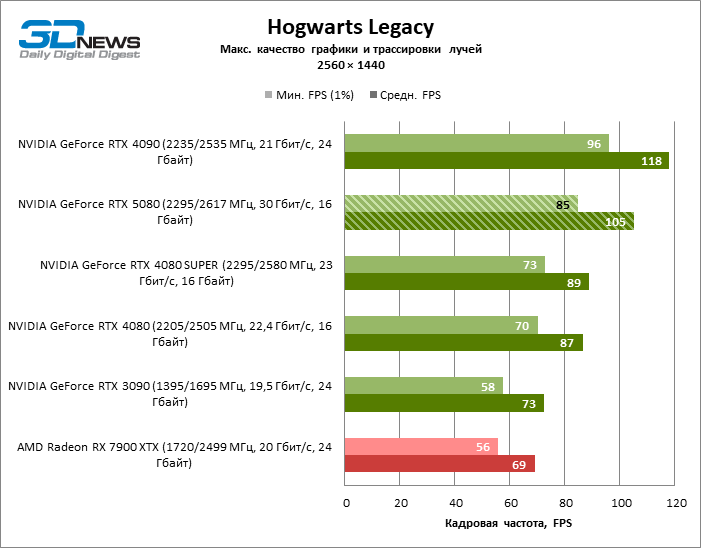
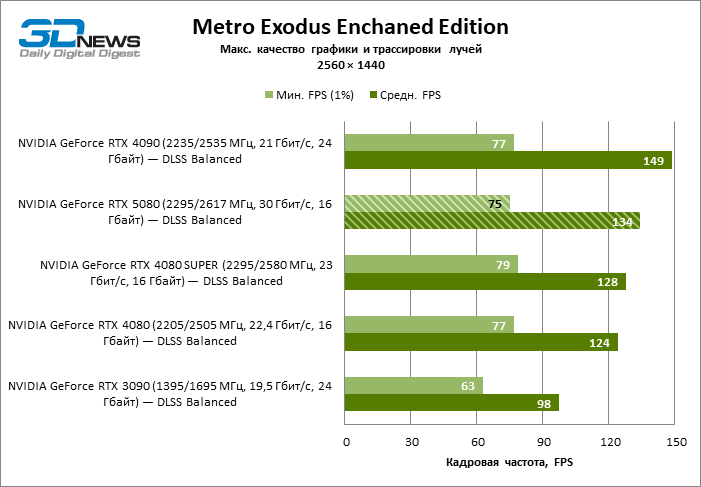
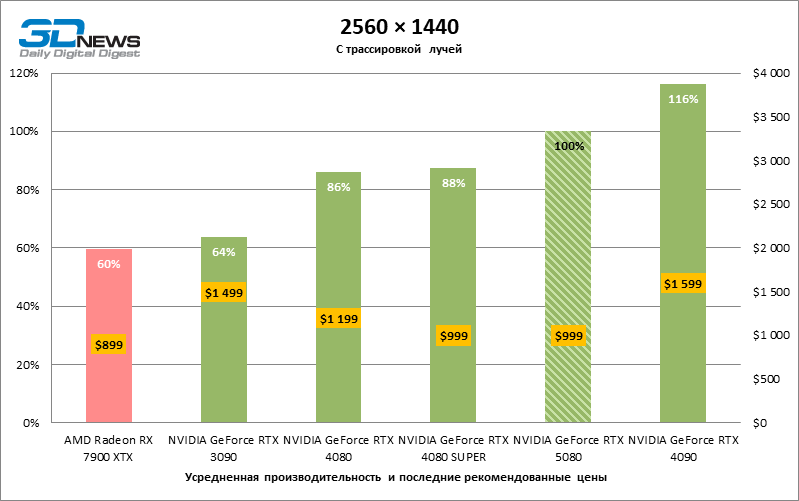
⇡#Testes de jogo (2560 × 1440)
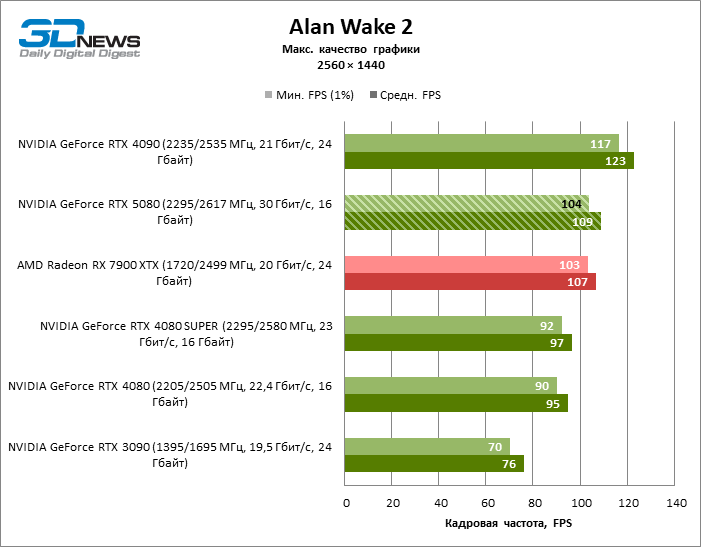
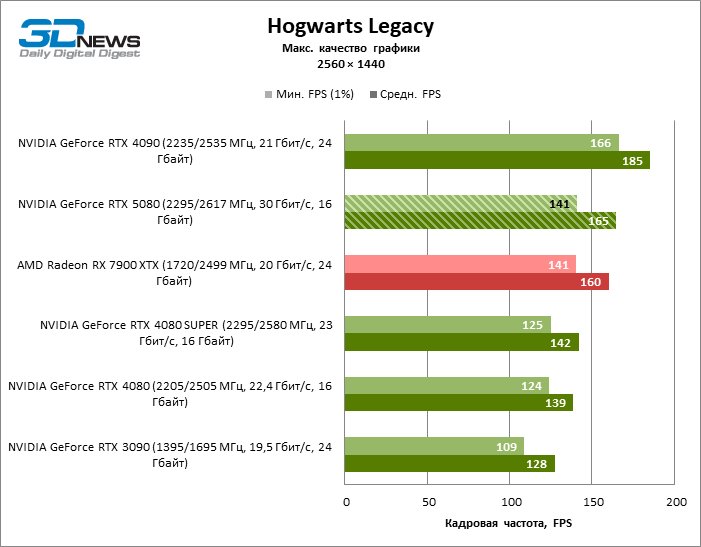
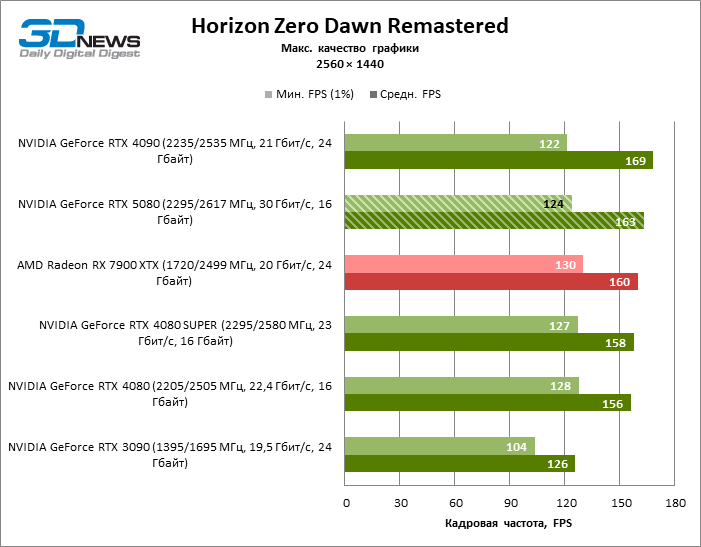
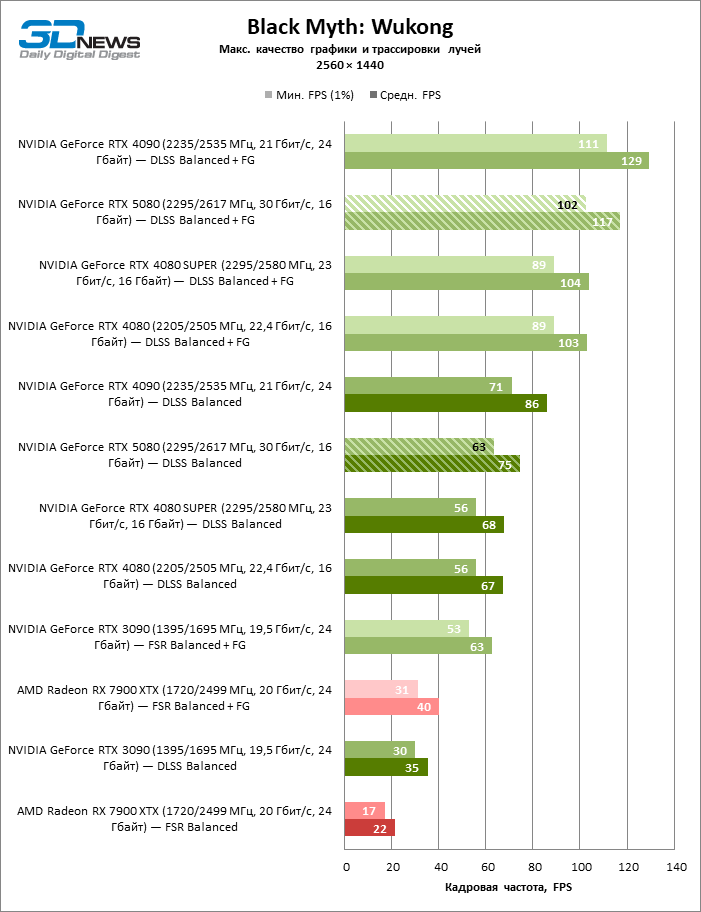
As conclusões gerais sobre os resultados do GeForce RTX 5080 no modo 1080p também podem ser estendidas aos jogos sem reiterar com uma resolução de 1440p. Nenhum dos títulos de teste é capaz de carregar o novo acelerador da NVIDIA, de modo que a estrutura média caia abaixo de 60 e, mais frequentemente e 100 fps. No entanto, há cada vez menos dúvidas de que a velocidade de avanço do RTX 5080 não deve ser esperada.
O herói da revisão foi 40 % mais rápido que o modelo de vice-flagmark do ano anterior, mas a distância entre os anos 80 da 50ª e 40ª linha é reduzida para 12-14 % da frequência do pessoal. Radeon RX 7900 XTX LAGS RTX 5080 por FPS a 4 %, e o GeForce RTX 4090 avançou a uma distância de 8 %.

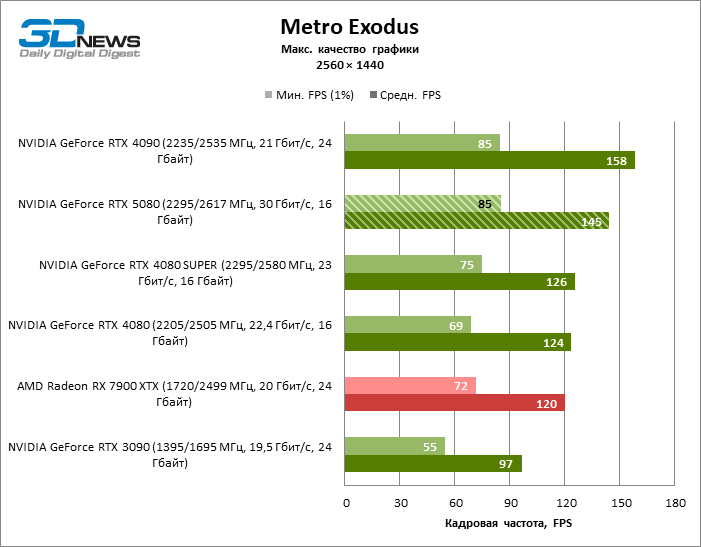
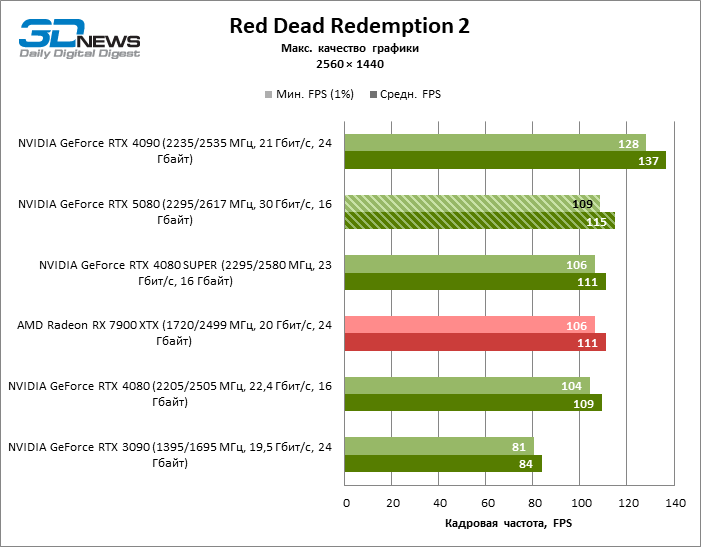
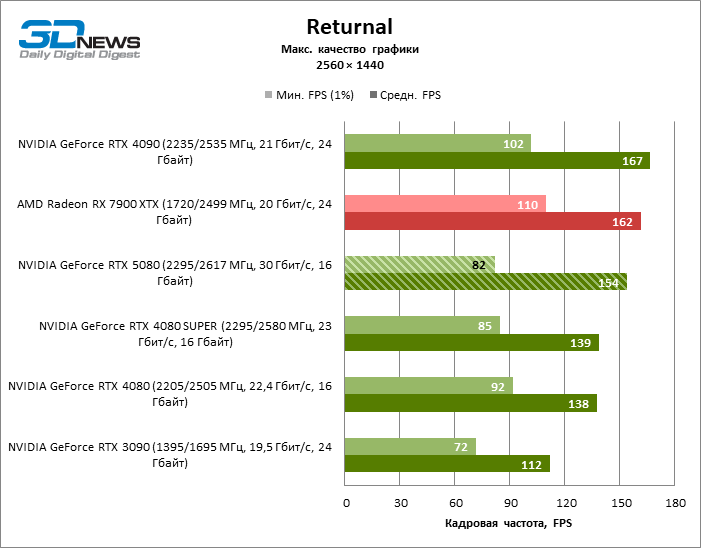
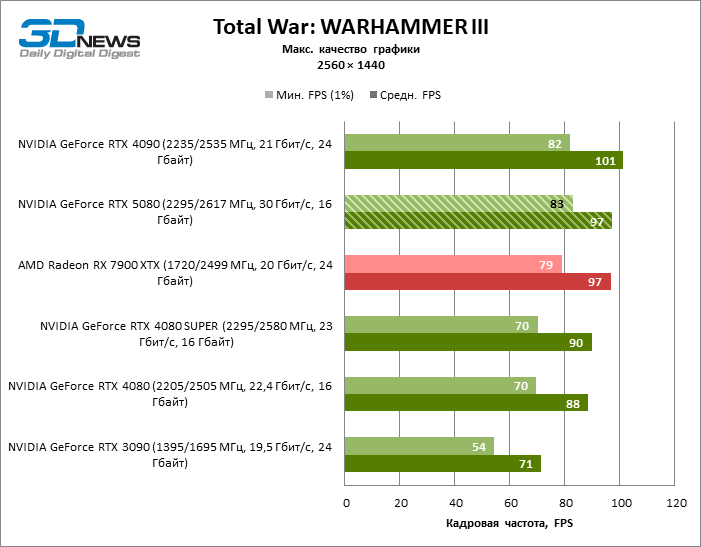
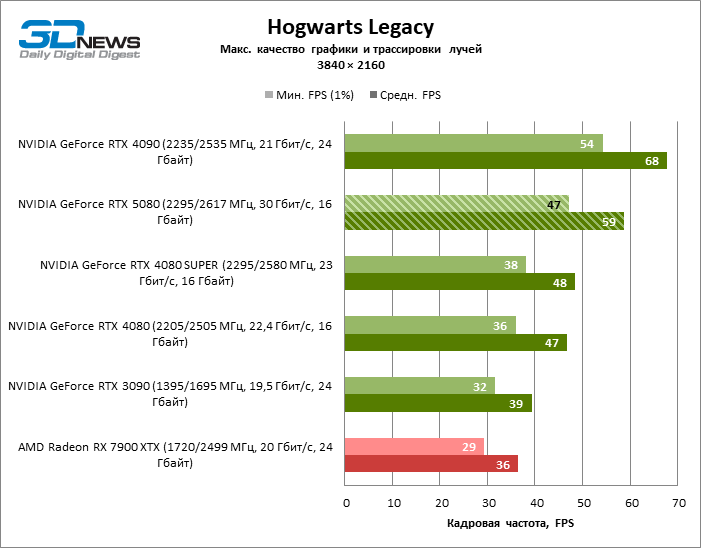
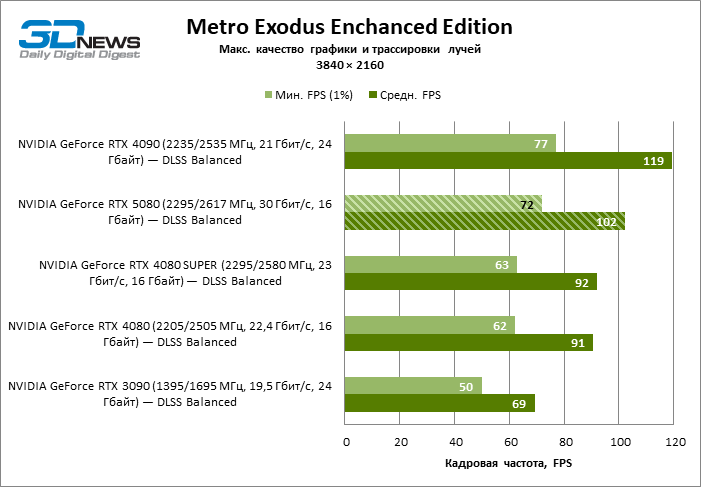
⇡#Testes de jogos (3840 × 2160)
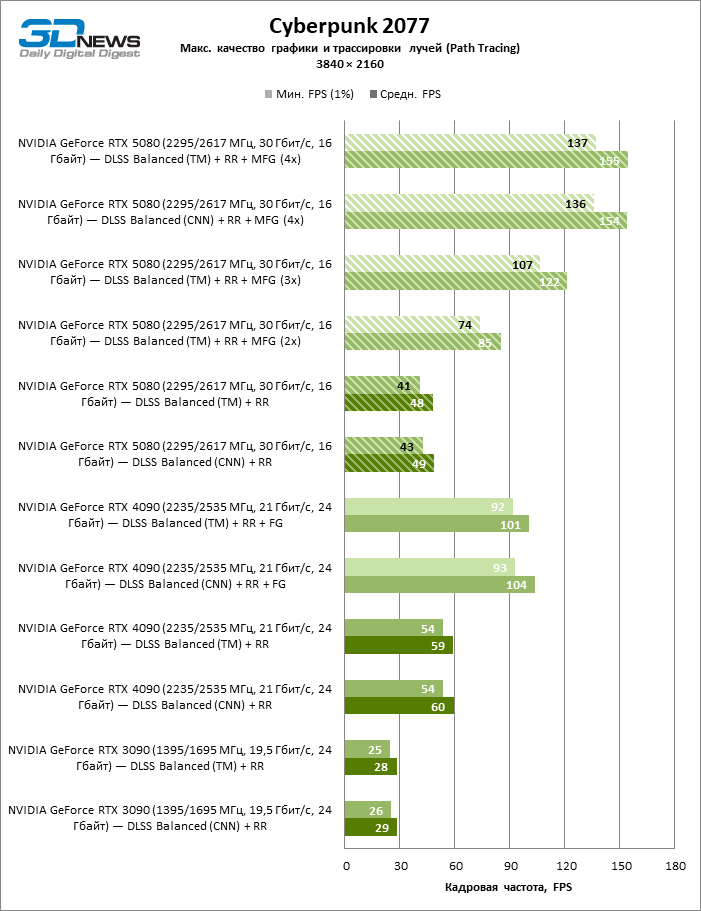
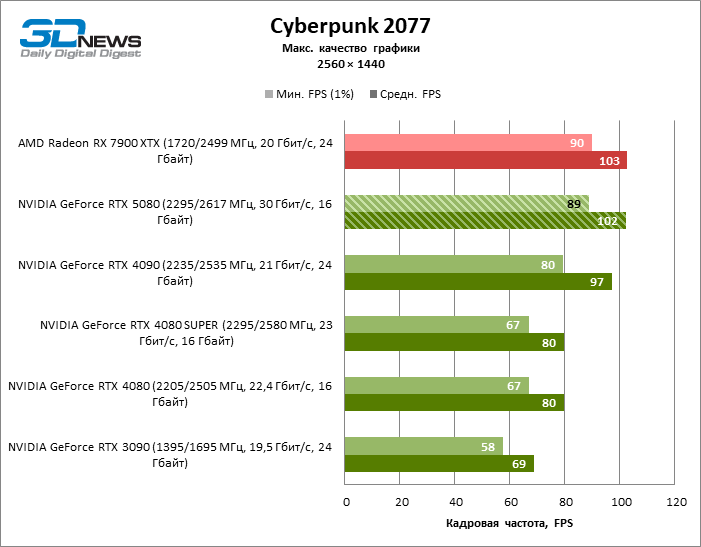
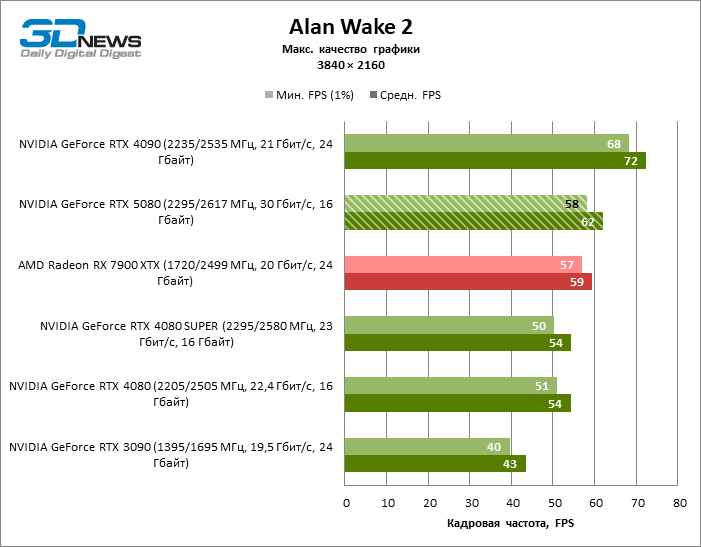
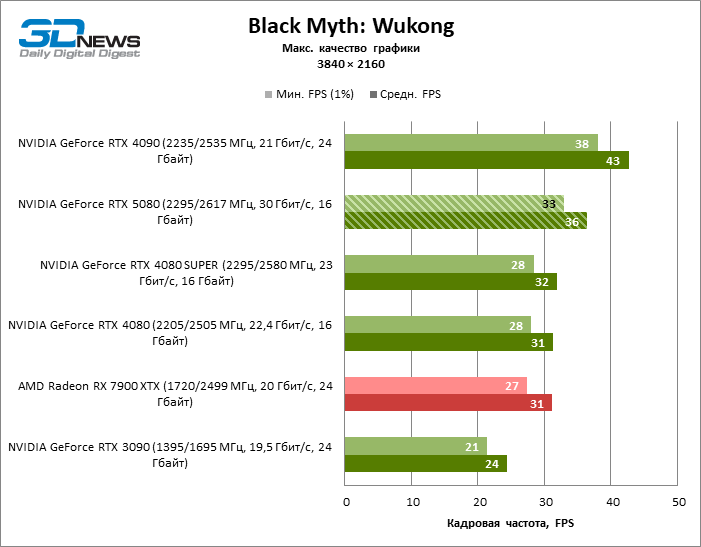
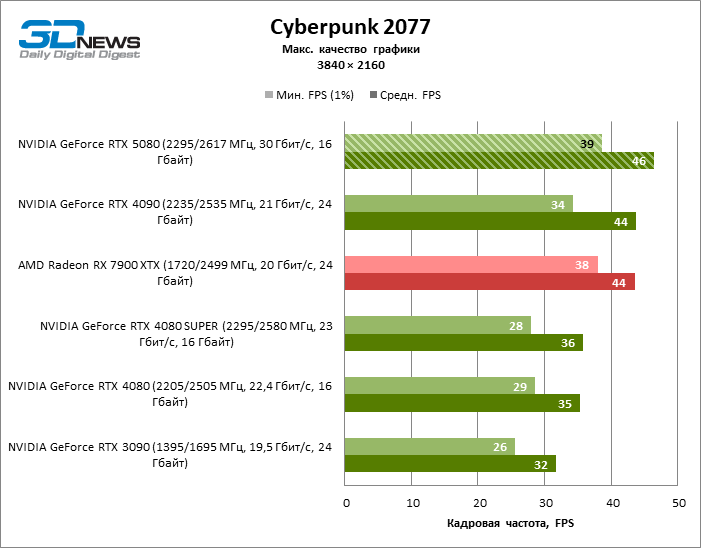
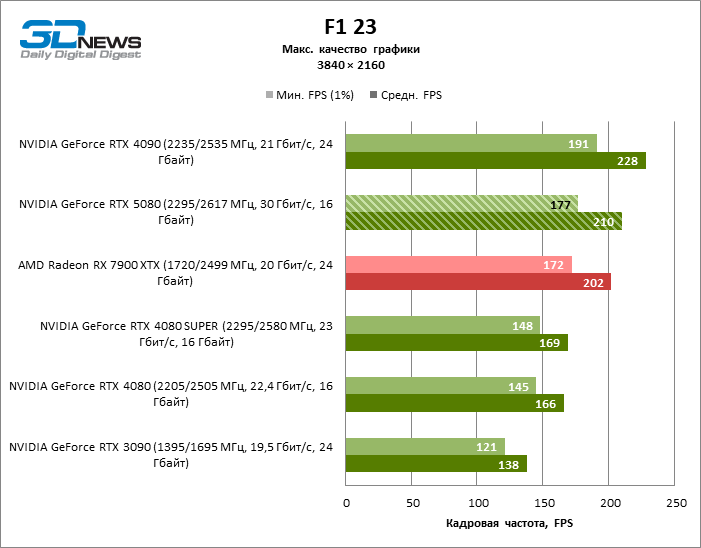
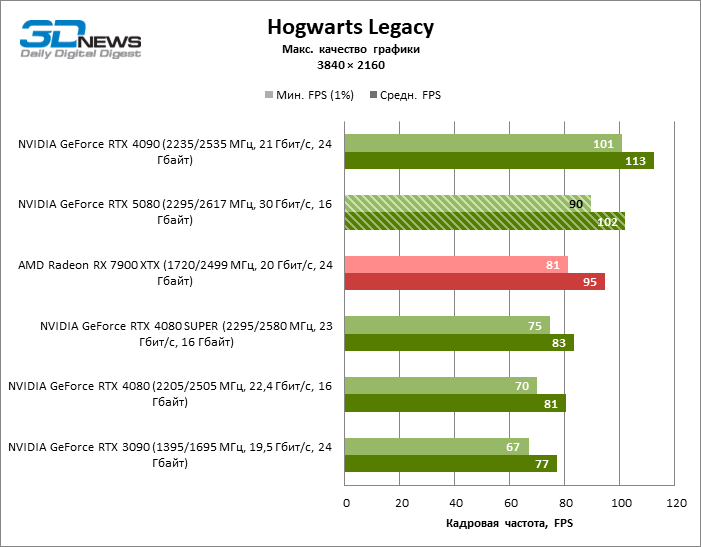
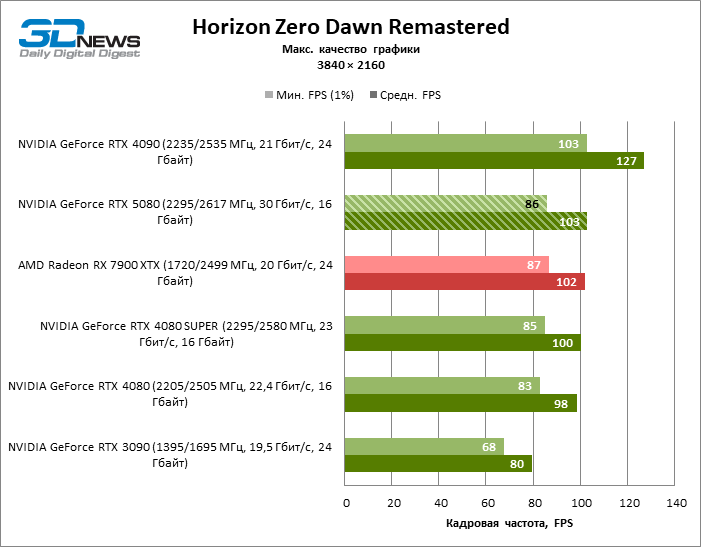
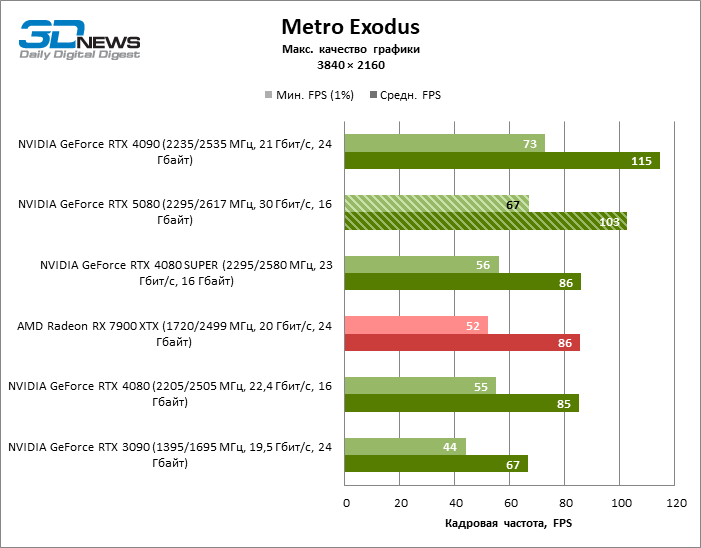
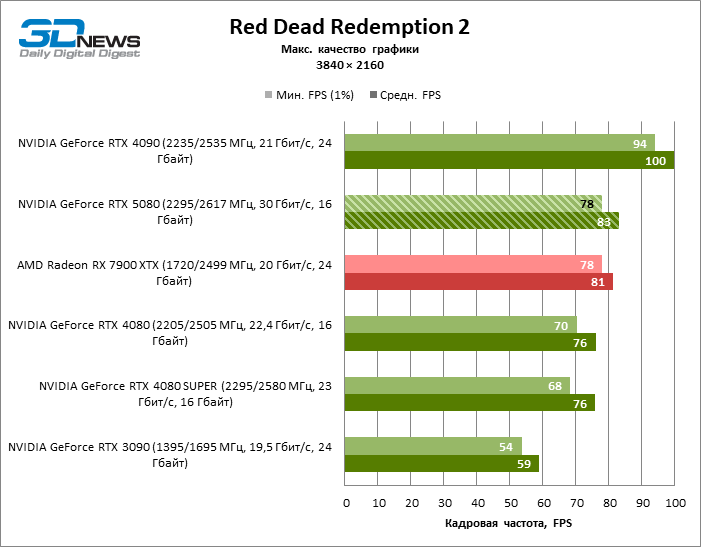
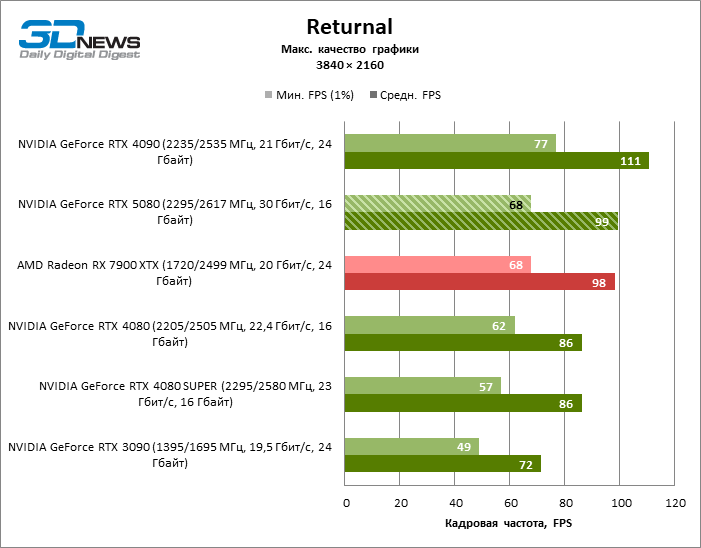
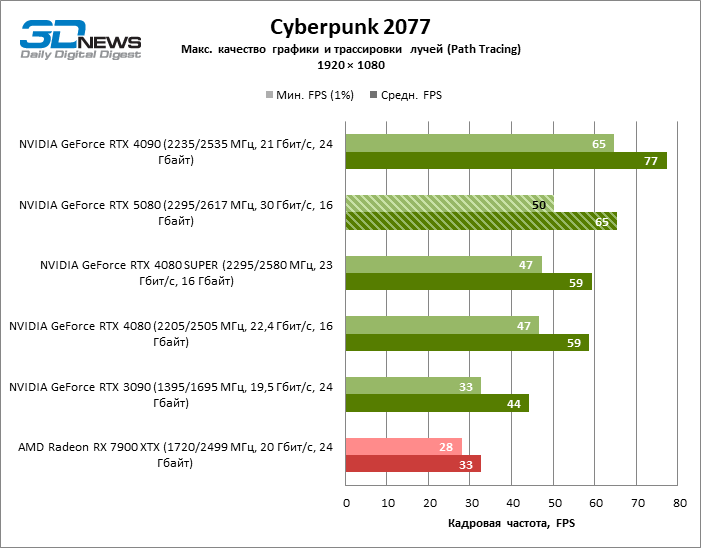
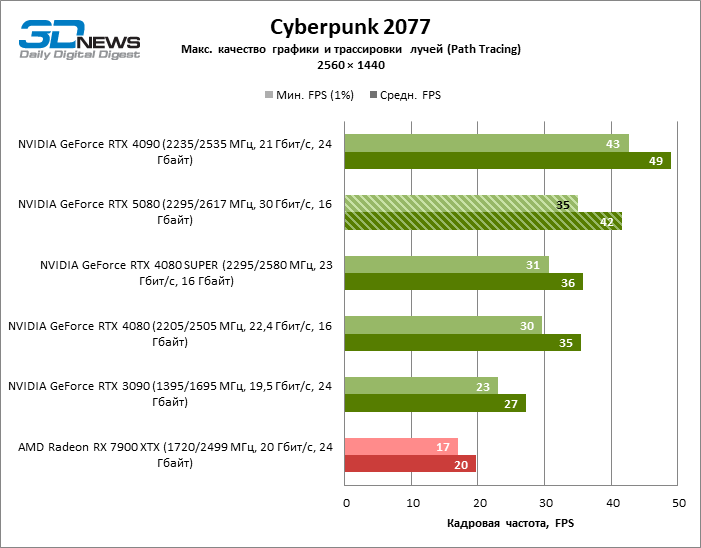
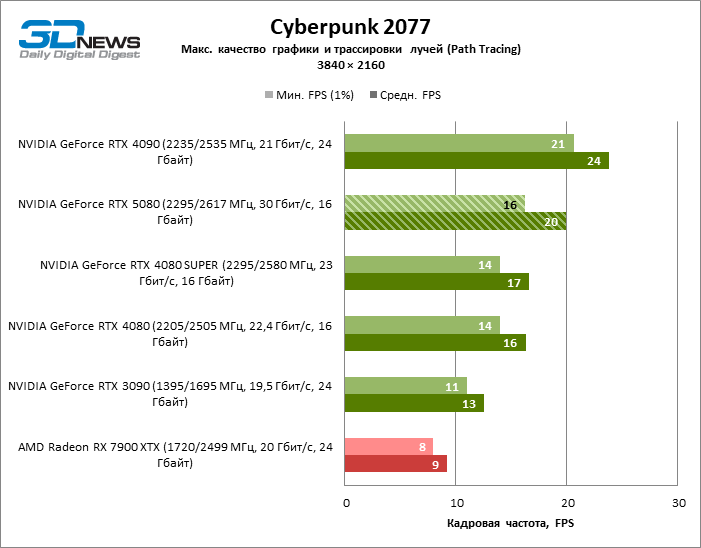
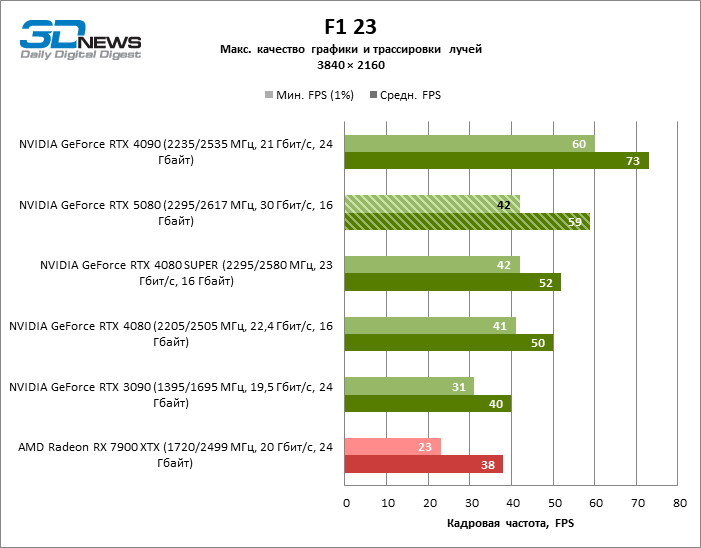
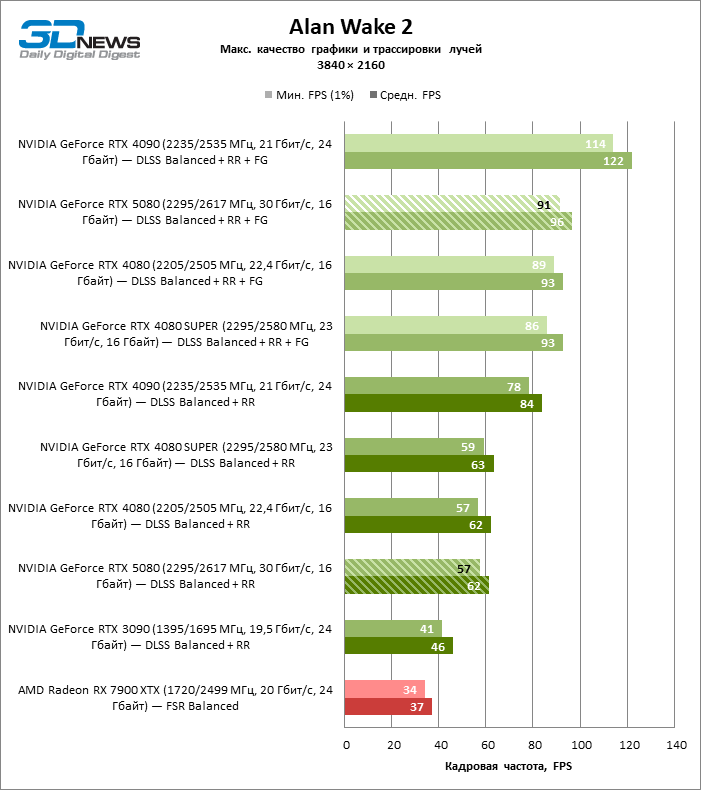
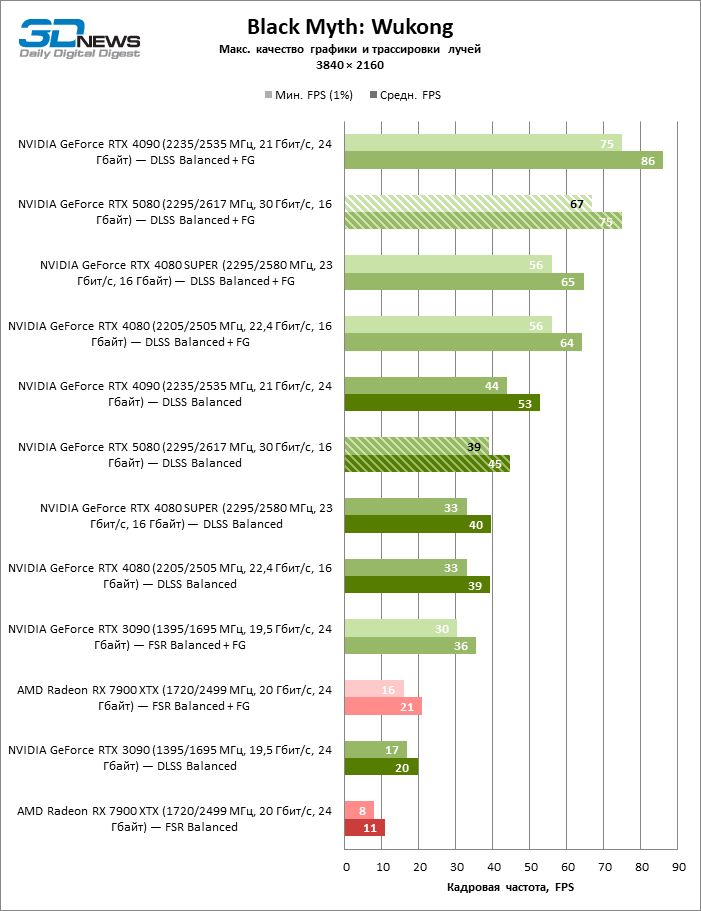
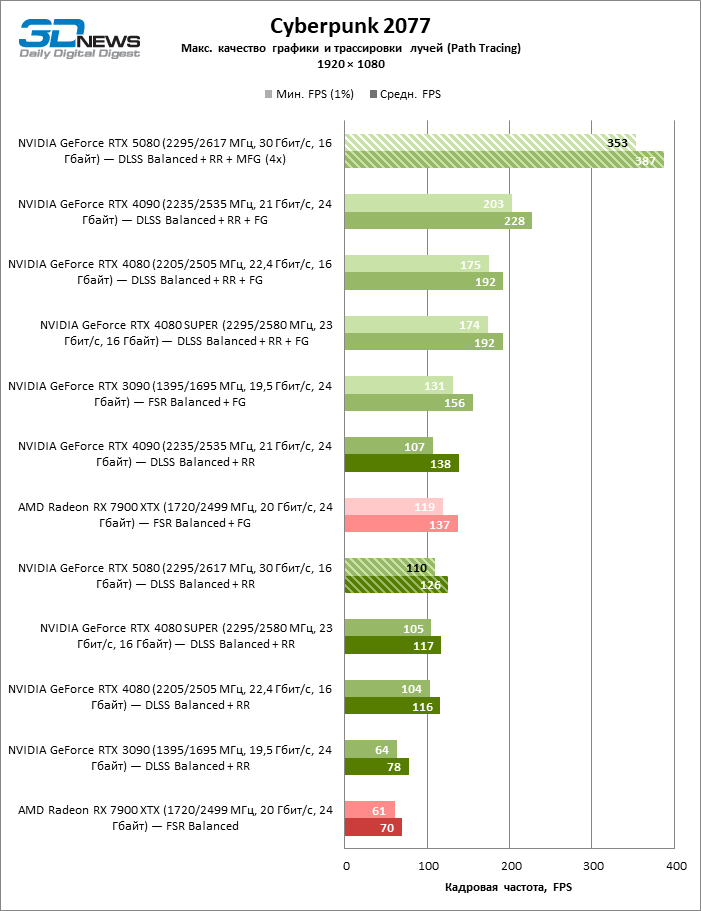
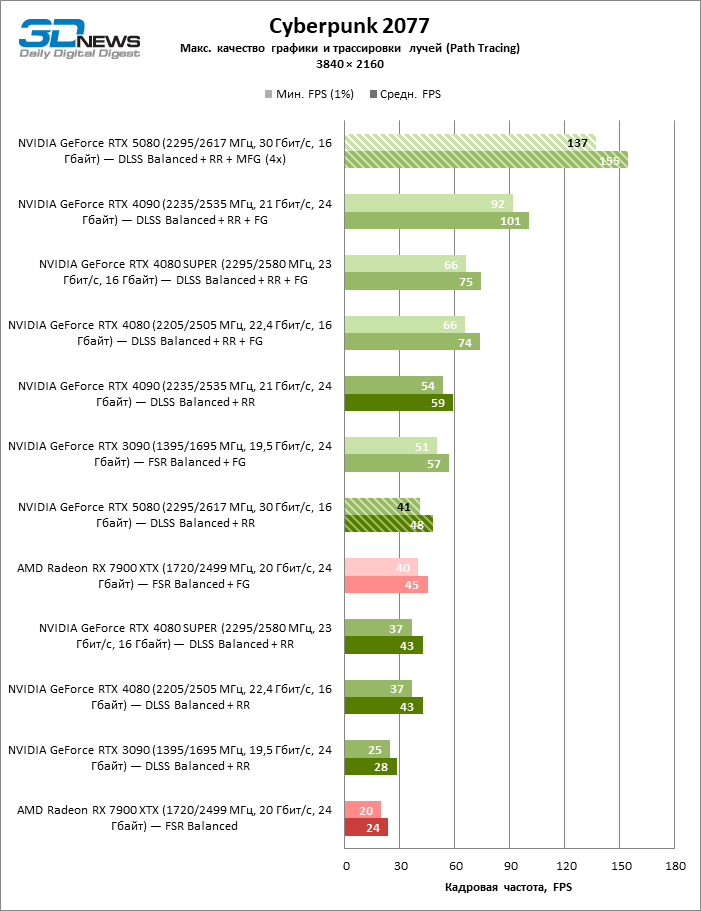
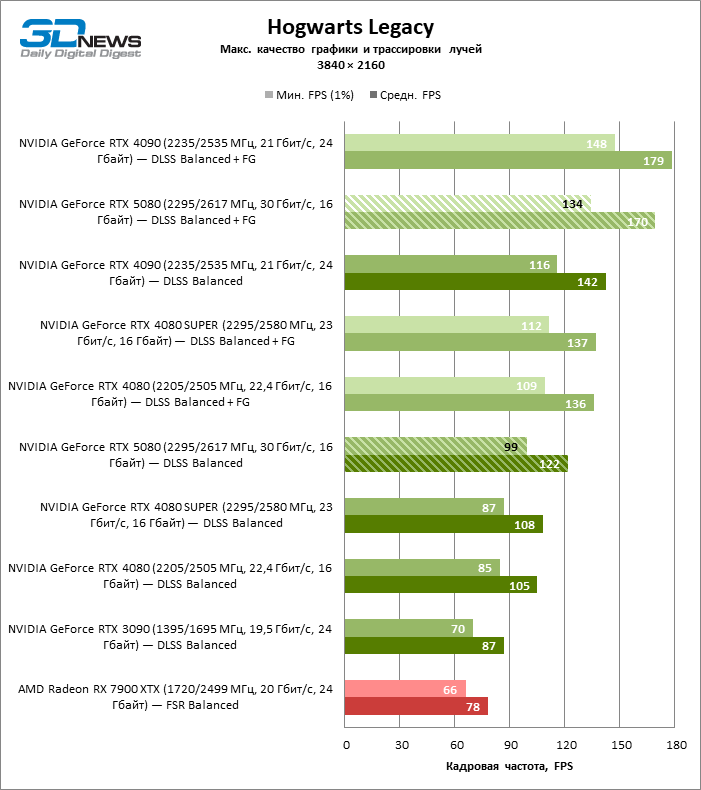
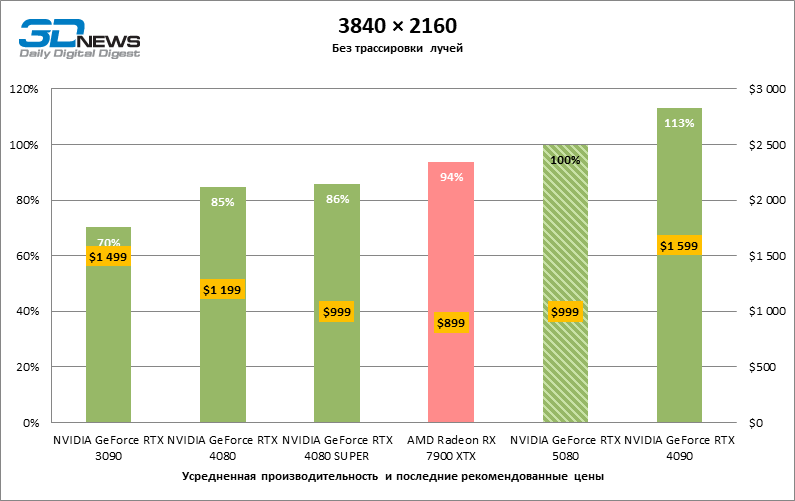
O GeForce RTX 5080 está posicionado como um acelerador para jogos em uma tela 4K. E ele, de fato, desenvolve um Freimrat a partir de 60 qps na maioria dos títulos (e em alguns ainda são cem). As exceções esperadas eram mito negro: Wukong e Cyberpunk 2077.
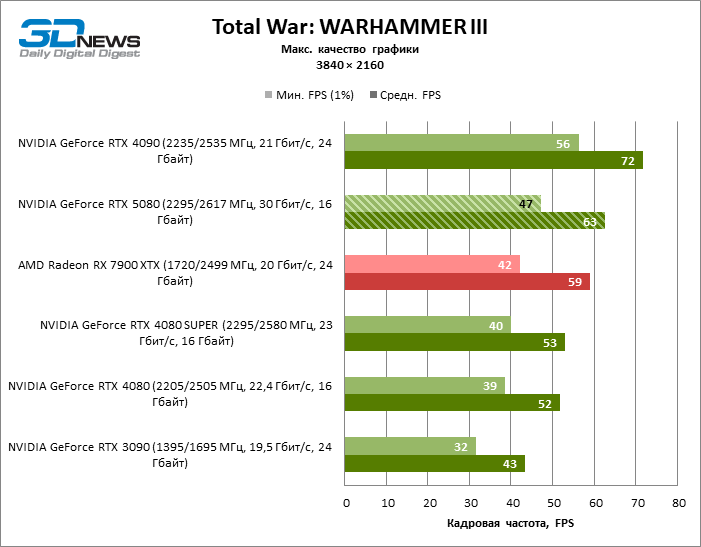
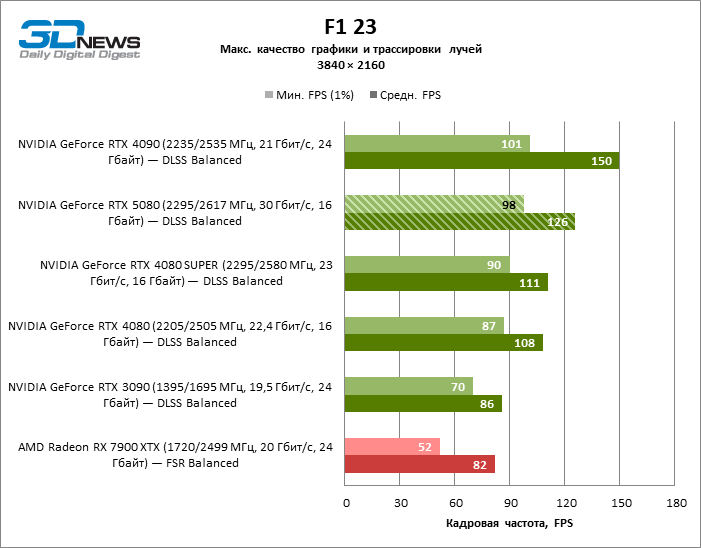
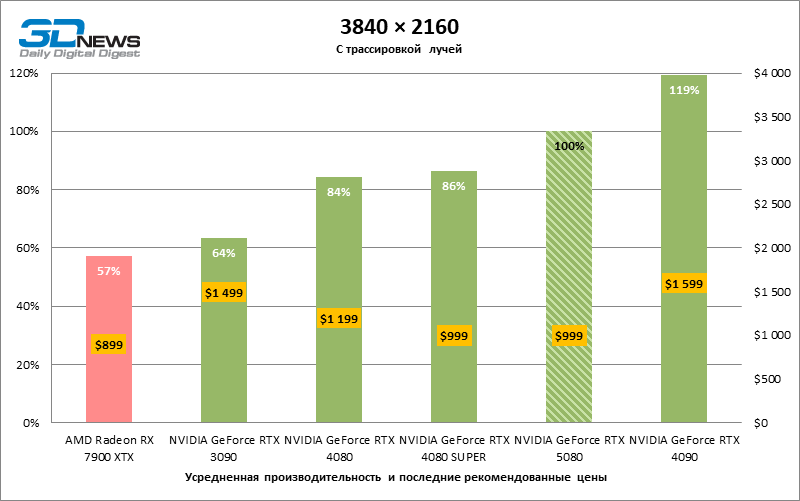
A diferença entre os dispositivos comparados atingiu os valores máximos possíveis sem envolver os raios de rastreamento, mas o GeForce RTX 5080 ainda não se parece com o dispositivo da próxima geração. Comparado ao GeForce RTX 3090, a velocidade RTX 5080 foi 43 % maior, mas se você tomar o GeForce RTX 4080 e o RTX 4080 Super, o crescimento será reduzido para 16-18 % de FPS. Por sua vez, a vantagem do GeForce RTX 4090 aumentou para 13% da estrutura média. Finalmente, o principal spoiler do GeForce RTX 5080 em Rasterização continua sendo o Radeon RX 7900 XTX, que perdeu apenas 6 % de FPS.
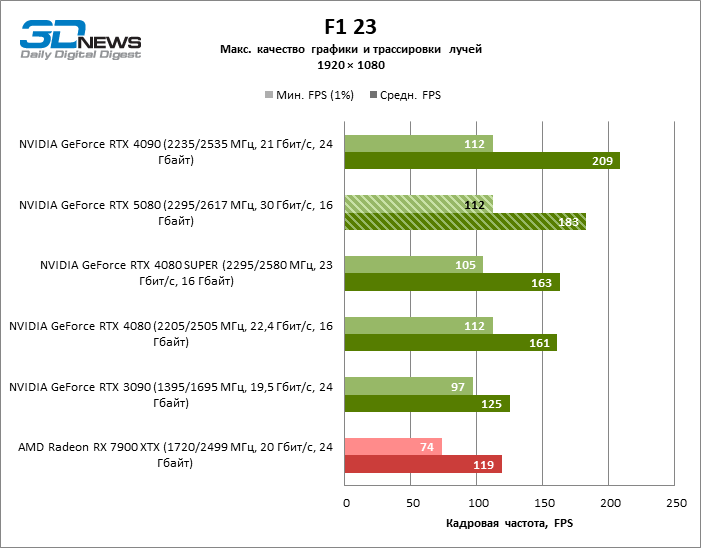
⇡#Testes de jogos Ray-tracing
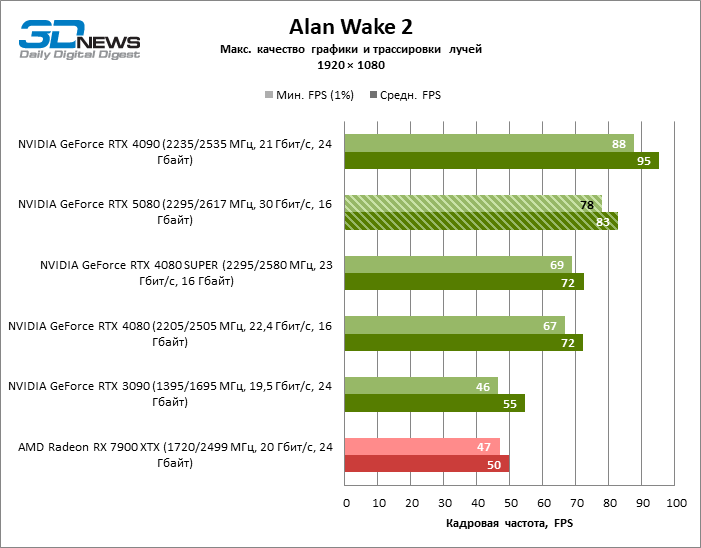
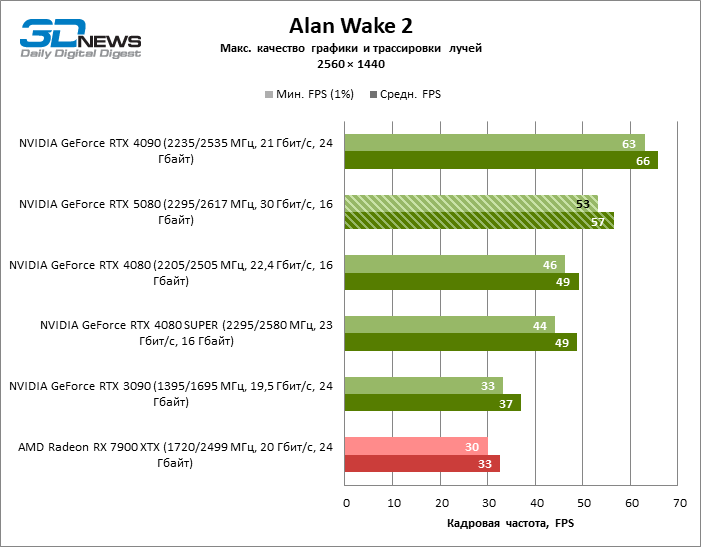
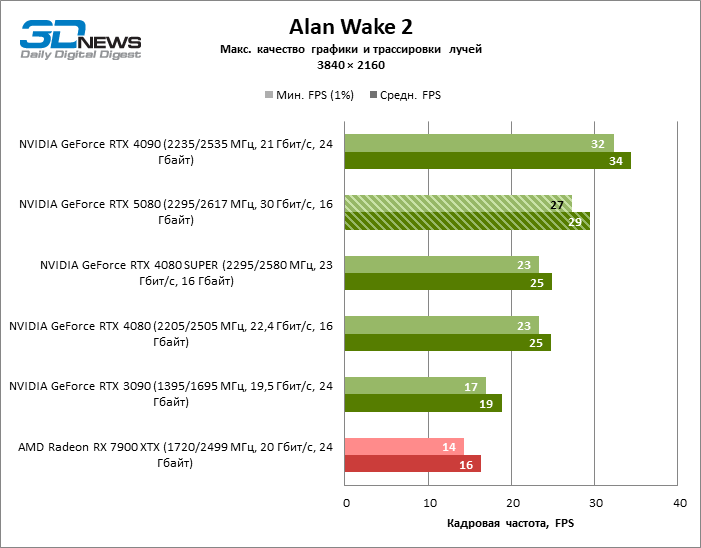
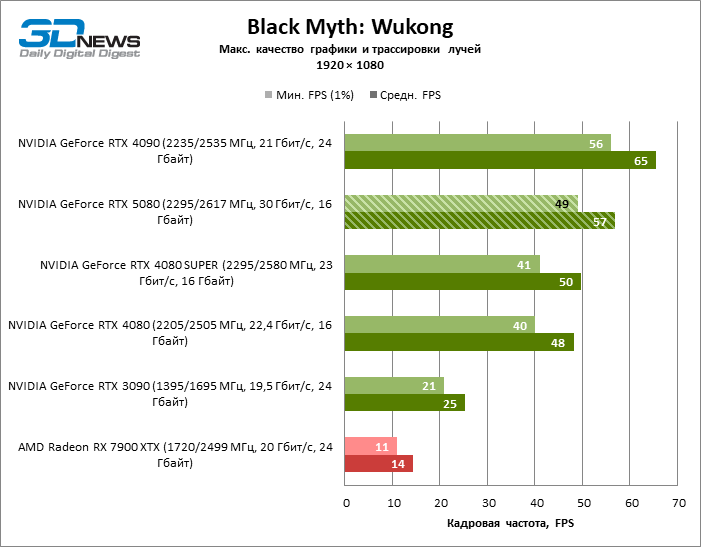
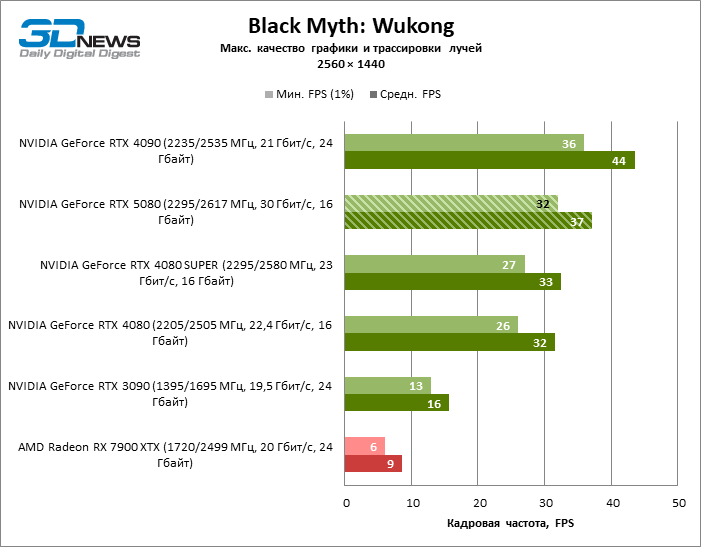
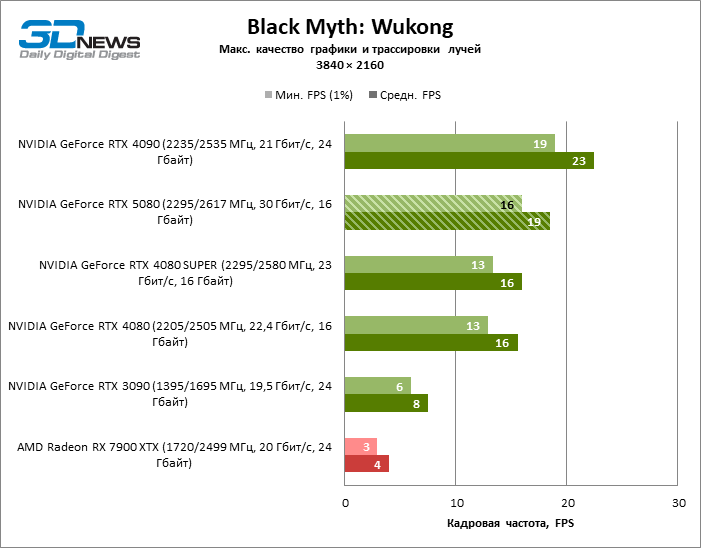
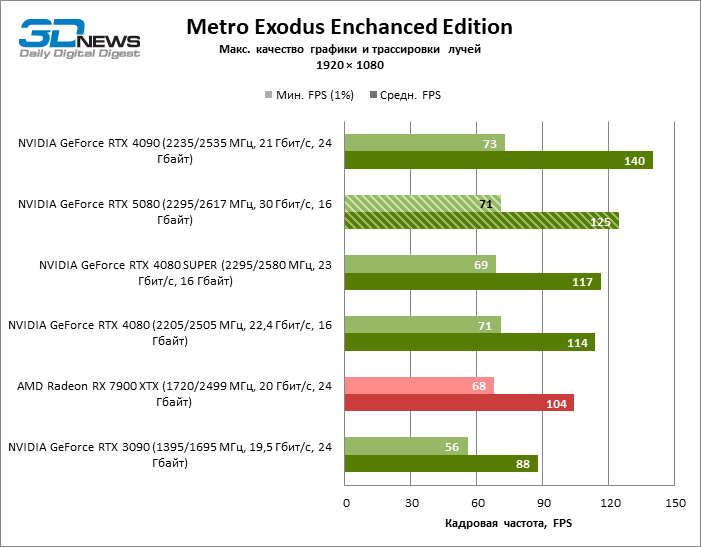
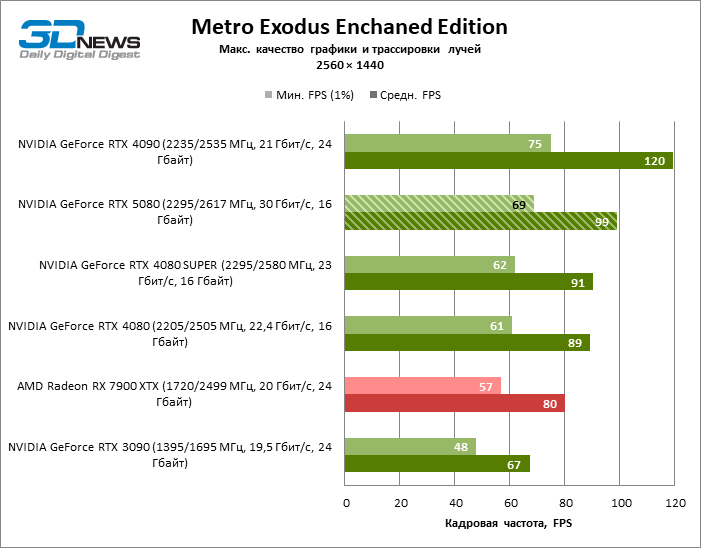
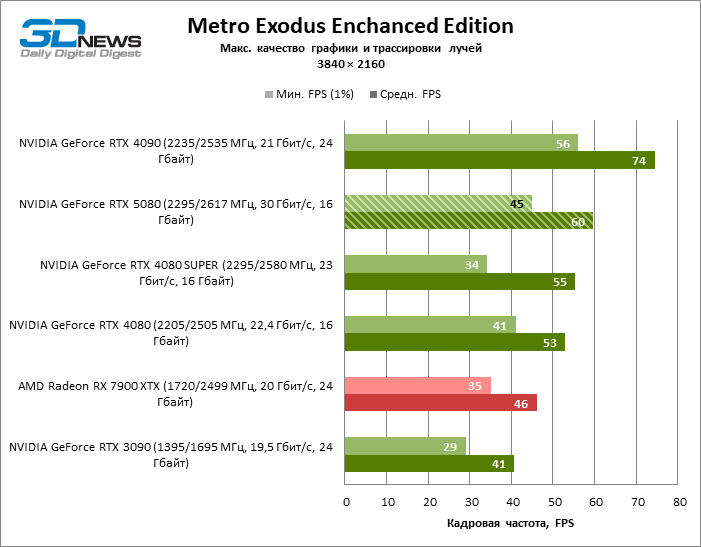
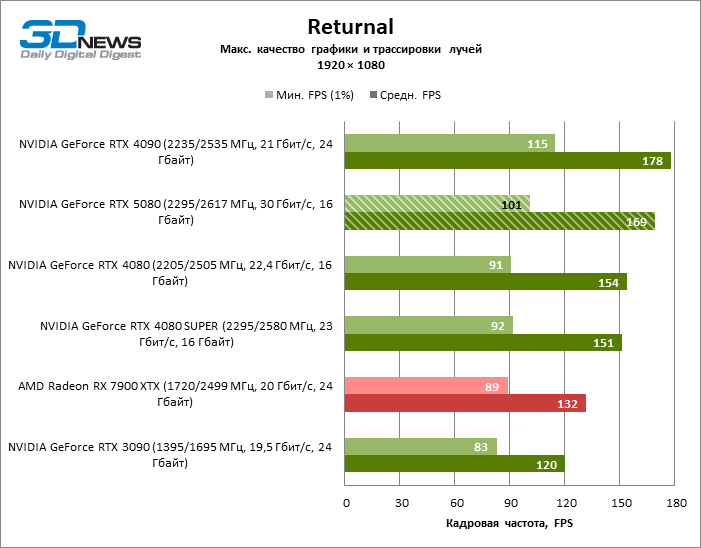
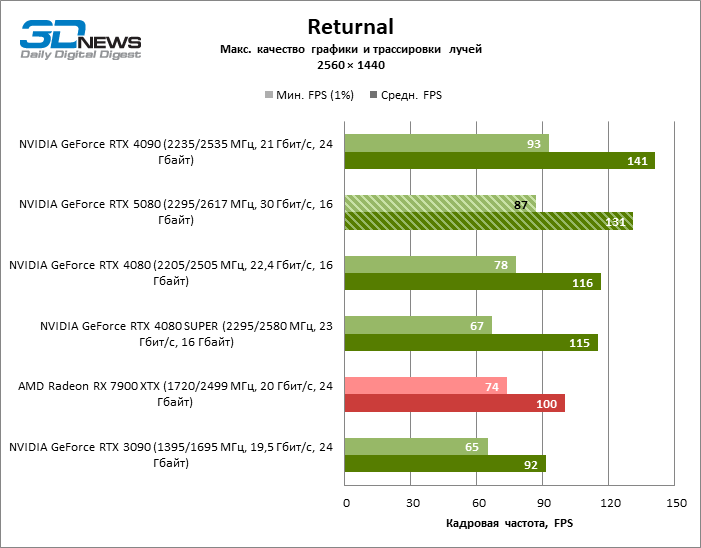
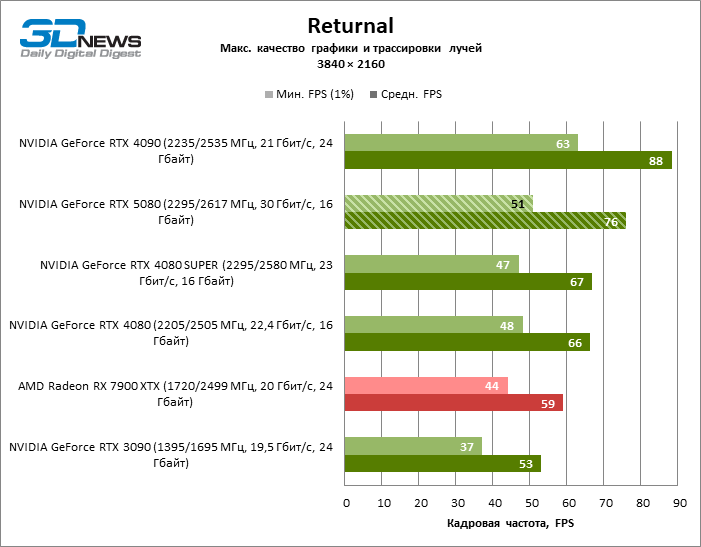
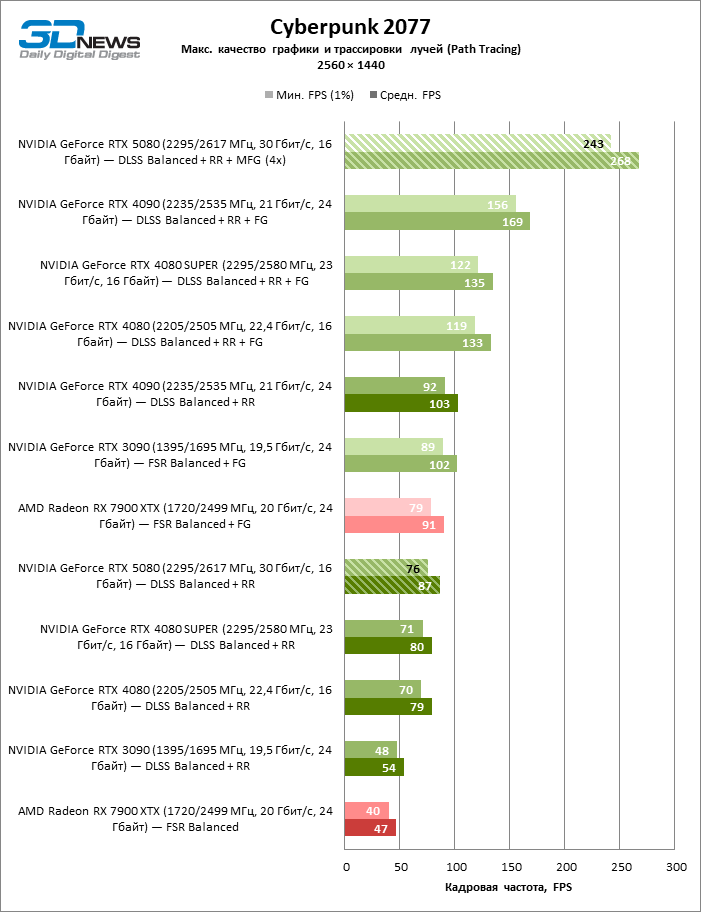
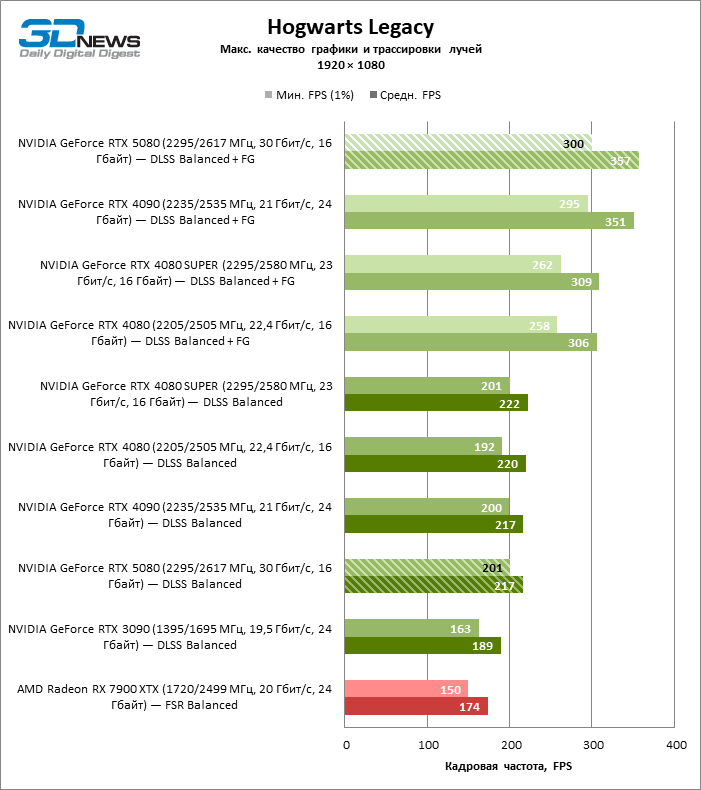
À luz da inovação de Blackwell, destinada à velocidade dos Rays Trace, é razoável esperar que o GeForce RTX 5080 se manifeste melhor nos benchmarks com a RT, e esse é em parte o caso. Jogos completamente rastreados funcionam com um quadro de pelo menos 57 qps ao resolver 1080p, e a renderização híbrida permitiu que o RTX 5080 quase 60 fps em tela em 4K sem escalar e gerar quadros.
O reitreim salvou o GeForce RTX 5080 da competição irritante do Radeon RX 7900 XTX: a vantagem média da placa de vídeo “verde” é de 64 a 75 %e em testes com traços de faixas ainda mais. A distância entre o GeForce RTX 5080 e o RTX 3090 também aumentou para 53-57 % de FPS. Infelizmente, dentro da estrutura das gerações vizinhas da GPU, a diferença entre o novo modelo 80 e duas versões do anterior aumentou, mas ainda é decepcionante 14-19 e 13-16 % da frequência do pessoal. O GeForce RTX 4090, pelo contrário, defendeu a posição de liderança com uma margem do RTX 5080 em 12-19 %.

⇡#Testes de jogos com ray tracing e frame scaling
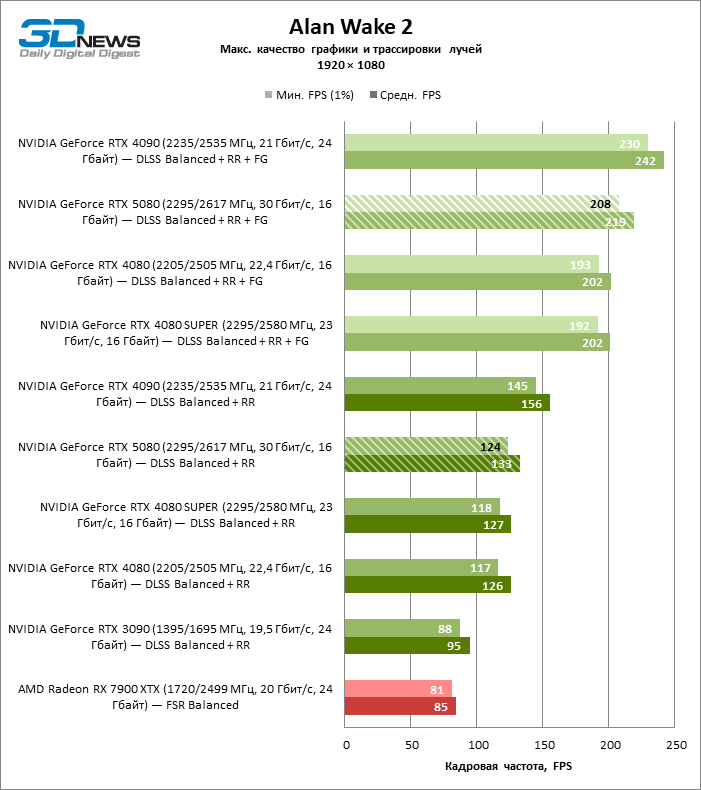
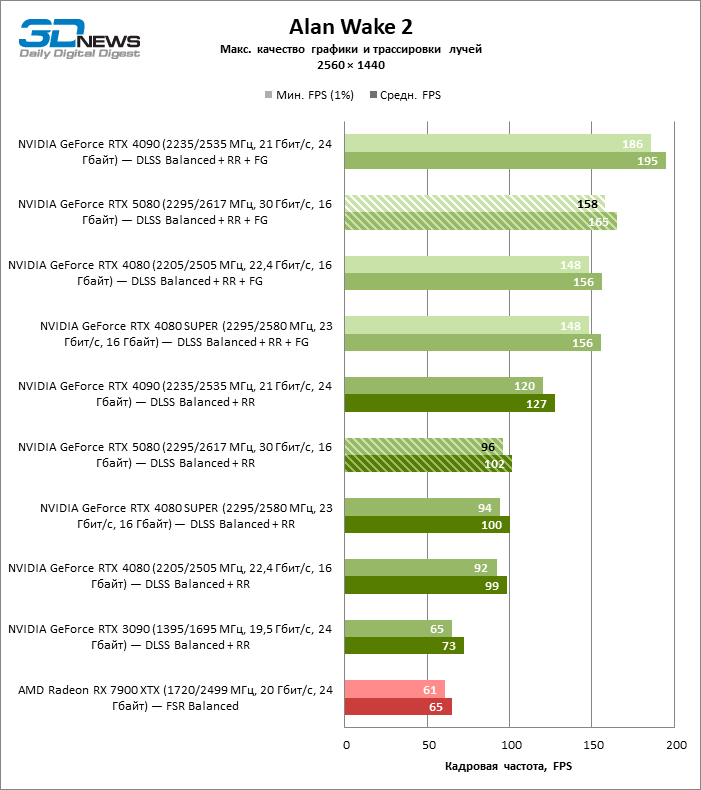
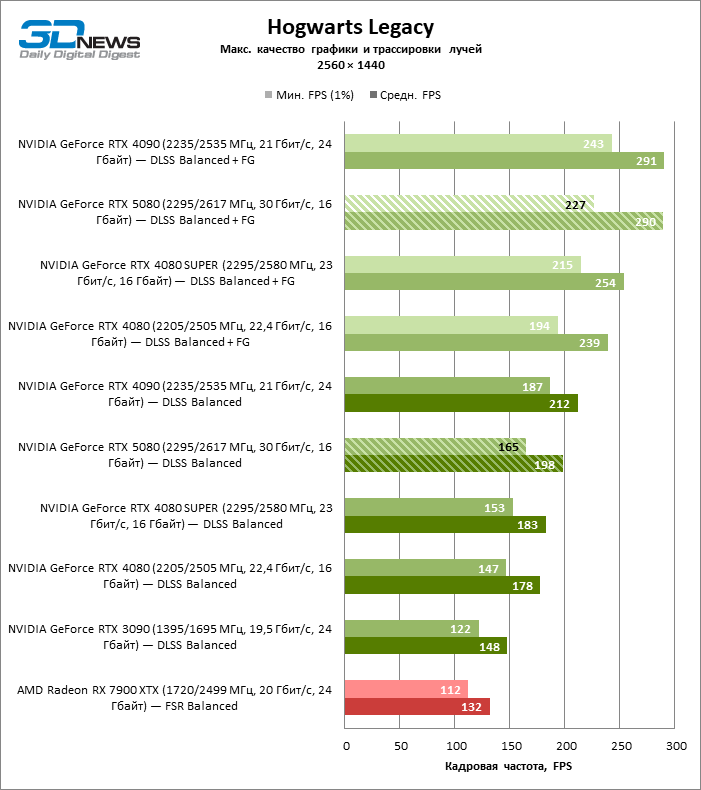
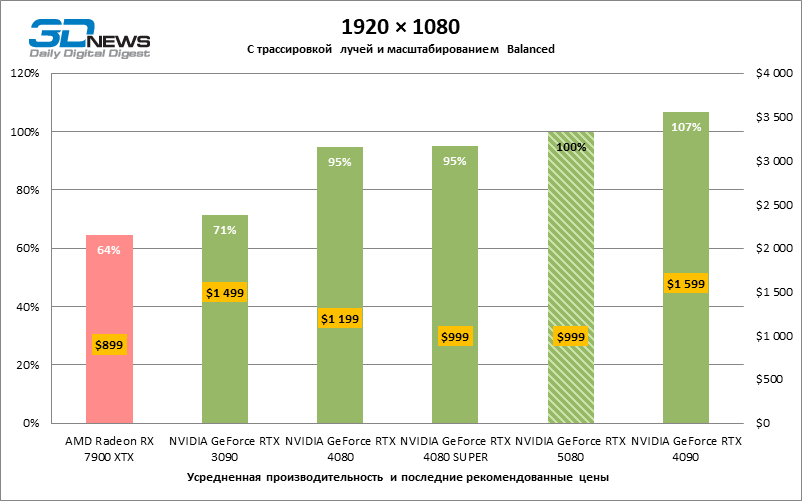
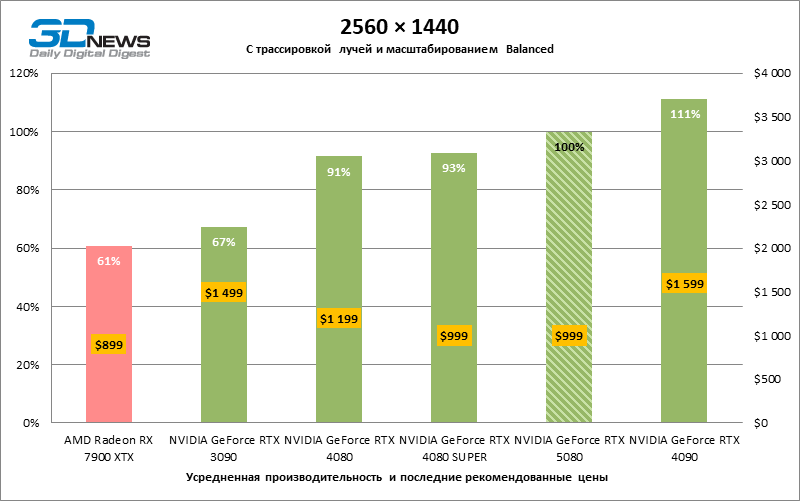
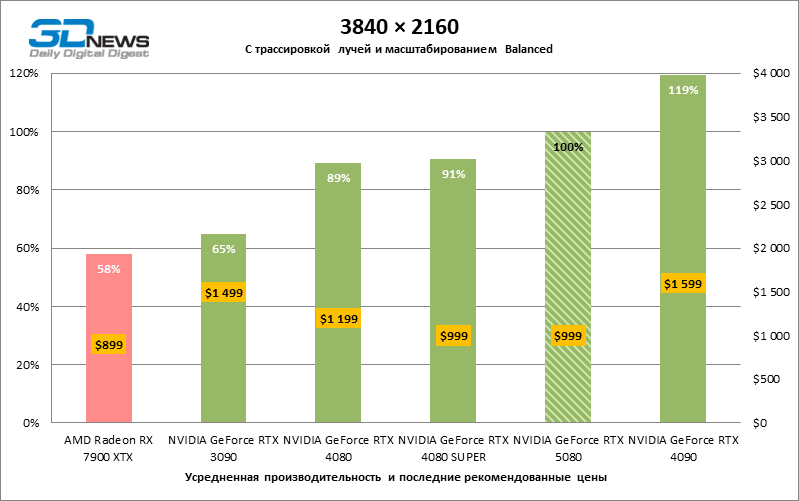
A escala de tiros com um coeficiente moderado (equilibrado) levou o GeForce RTX 5080 para um nível acima de 100 fps em jogos com renderização híbrida na tela 4K e mais de 60 fps em referência totalmente rastreada com uma resolução de 1440p. Todos os aceleradores da NVIDIA realizaram testes usando a reconstrução de raios DLSS se essa função for suportada pelo jogo.
Sob a carga atualizada, as placas de vídeo rivais novamente se tornaram próximas uma da outra. O GeForce RTX 5080 ainda está à frente do GeForce RTX 3090 e Radeon RX 7900 XTX para valores enormes de 40-54 e 55-72 % de FPS. Mas a vantagem da novidade sobre o GeForce RTX 4080 e o RTX 4080 super diminuiu para os modestos 6-12 e 5-10 % de FPS, respectivamente. No entanto, o GeForce RTX 4090 nessas condições de jogo mais realista para poderosas placas de vídeo excede o RTX 5080 em apenas 7-19 %.
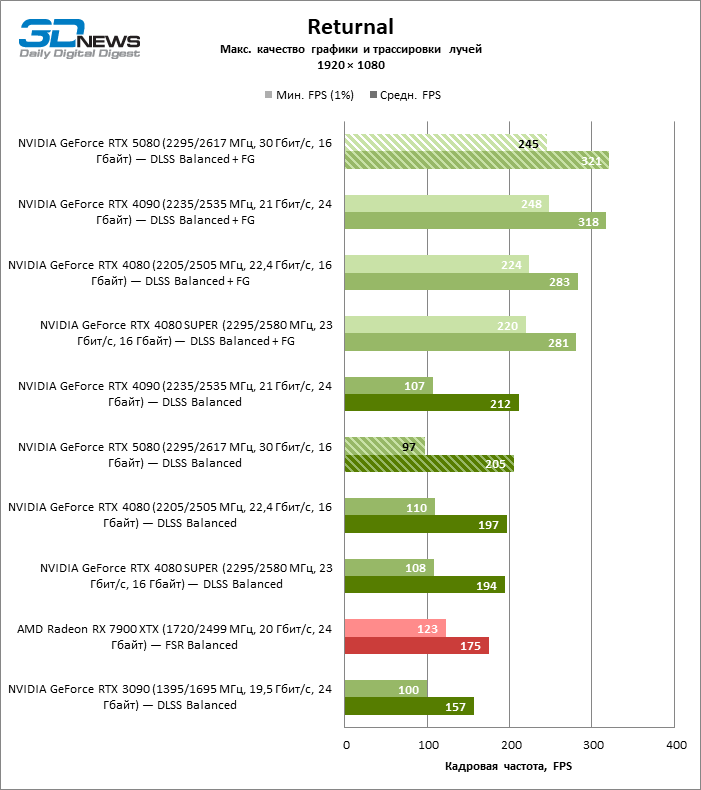
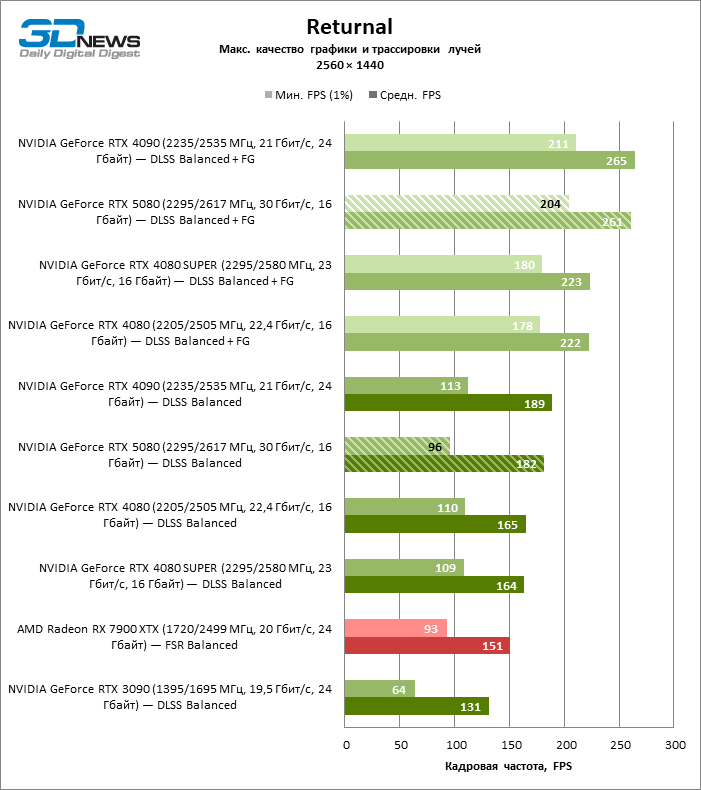
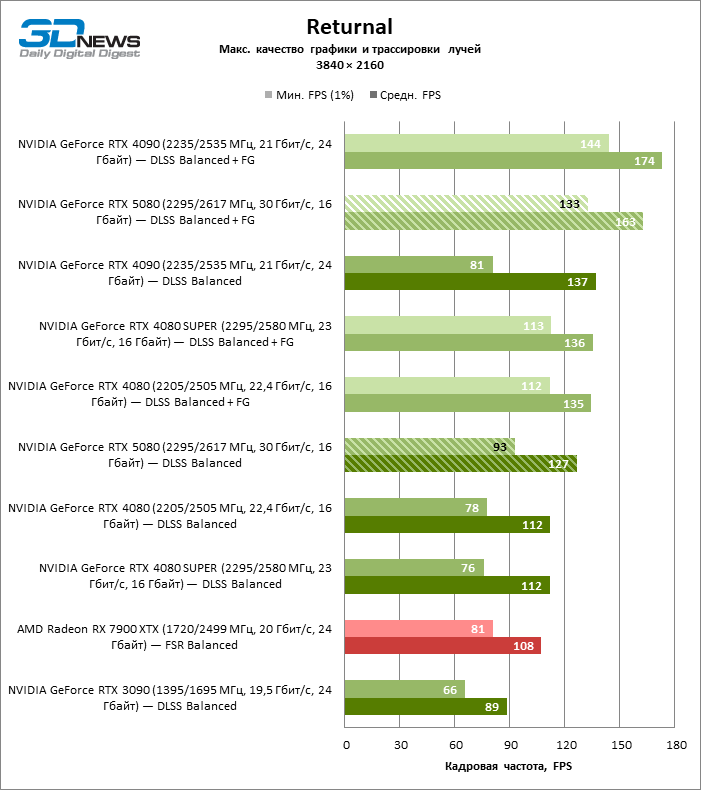
⇡#Testes de jogos com overclock
Devido à maneira como os chips Blackwell controlam a frequência do relógio, o aumento formal de 500 MHz (e 457 MHz de acordo com o monitoramento) não fala tudo sobre o trabalho da GPU “sob o capô”. Seja como for, para uma placa de vídeo, sem uma capacidade inesgotável do Palit Gamerock, acelera notavelmente: em jogos rasterizados na tela 4K, o Framretite aumentou em média 11 %, que trouxe de perto o GeForce RTX 5080 para o Versão do GeForce RTX 4090 com frequências quase repelentes.
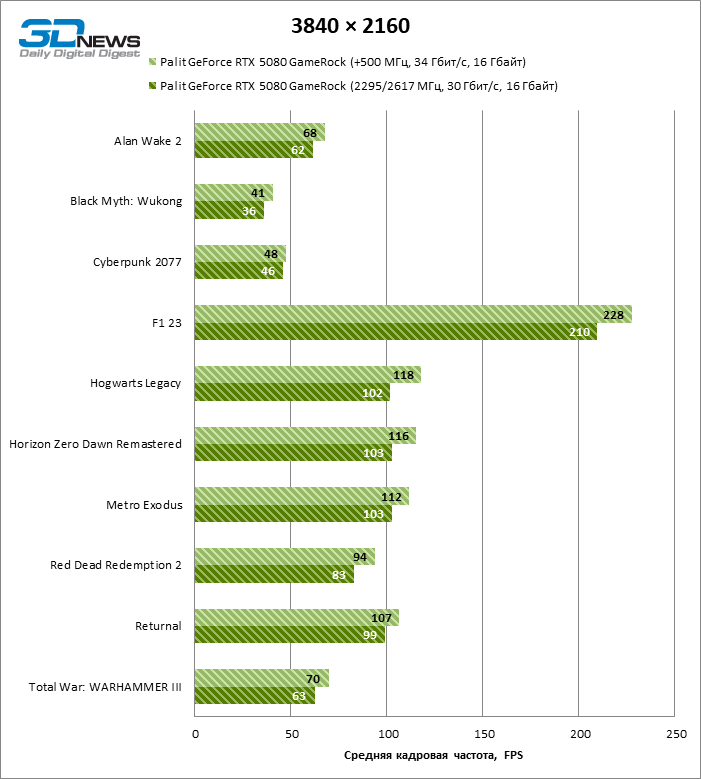
⇡#Testes em aplicativos de produção
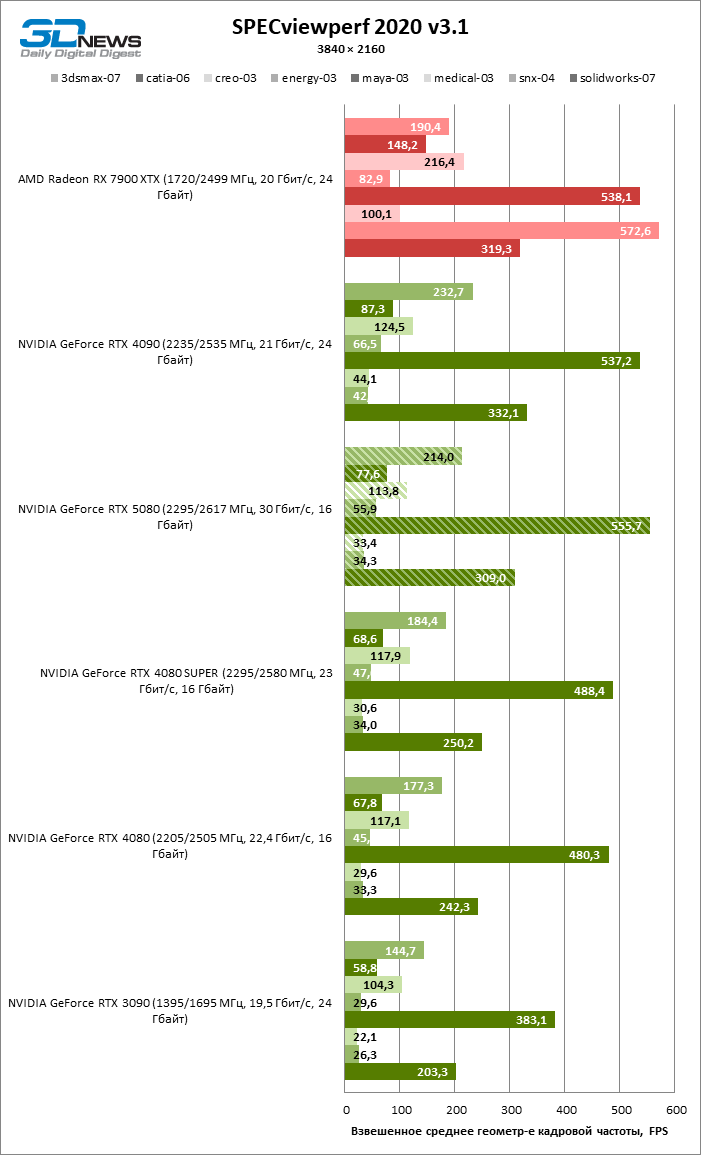
A renderização do liquidificador é uma medida da produtividade bruta da GPU em cálculos materialmente dramáticos e, nesse sentido, o GeForce RTX 5080 deu apenas um passo formal a partir do RTX 4080 Super. Como resultado, a novidade tem uma pequena vantagem sobre os antigos modelos 80 ao usar o hardware que reitere, mas em geral não há uma diferença significativa entre três aceleradores. Bem, o GeForce RTX 4090 continua sendo um líder incondicional nas tarefas desse tipo.
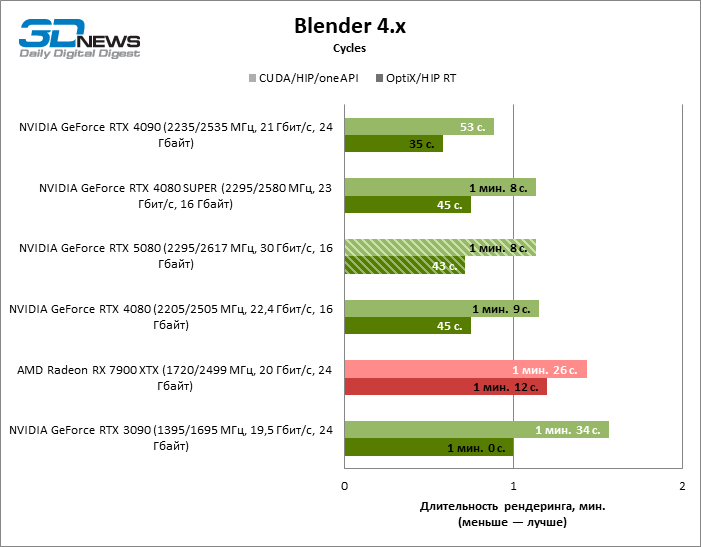
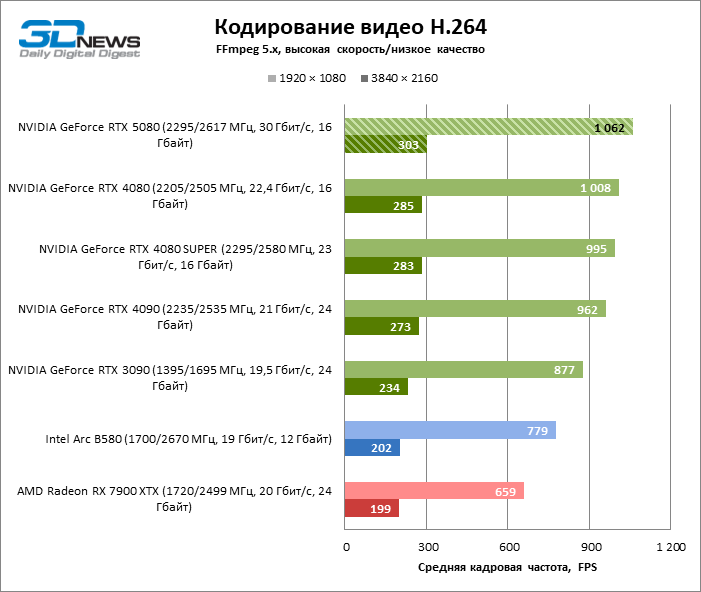
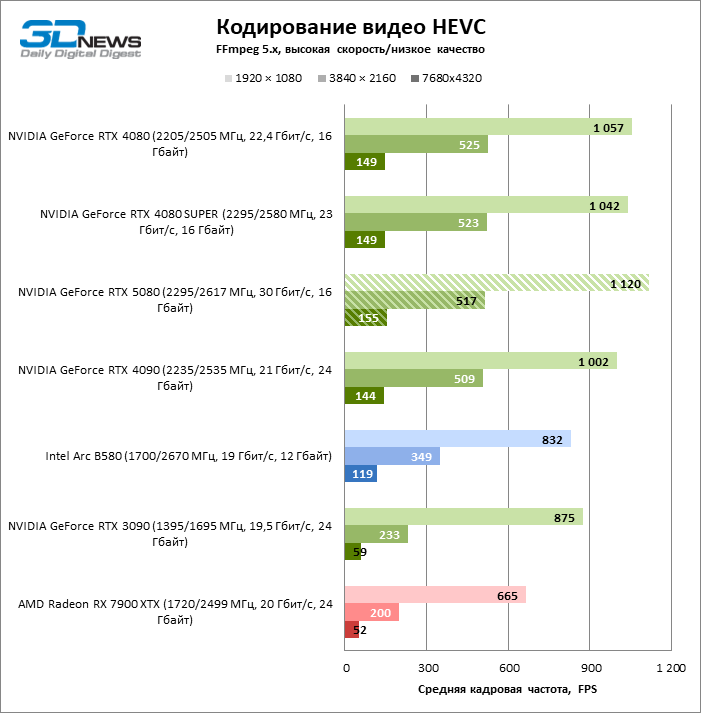
Mas a codificação/decodificação de benchmark no Premiere Pro colocou o GeForce RTX 5080 em primeiro lugar entre os participantes do teste devido à alta velocidade de trabalho com formatos H.264 e HEVC. No entanto, deve -se notar que receberia o Radeon RX 7900 XTX, se não fosse pelo resultado baixo em testes brutos.

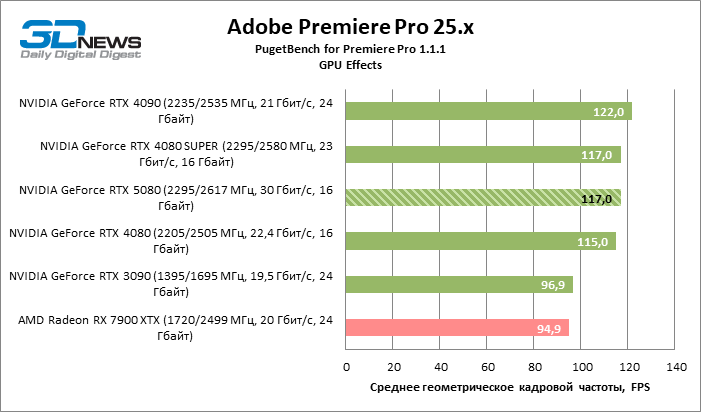
Os modelos sênior da NVIDIA formam um grupo denso no gráfico de desempenho dos efeitos da GPU no Premiere Pro, e o GeForce RTX 5080 atingiu os mesmos resultados que o RTX 4080 Super.
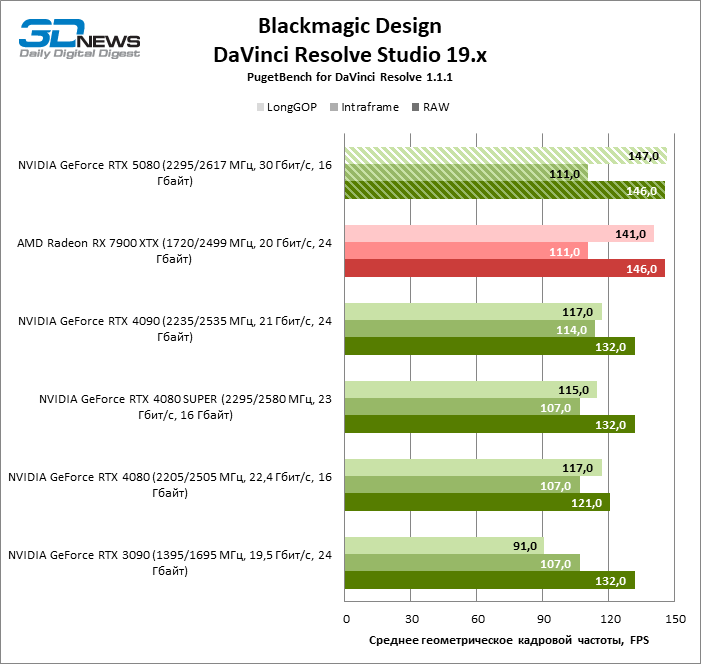
O teste usando vários formatos de vídeo em DaVinci Resolve trouxe outra vitória do GeForce RTX 5080 com uma pequena margem do campeão anterior – Radeon RX 7900 XTX.
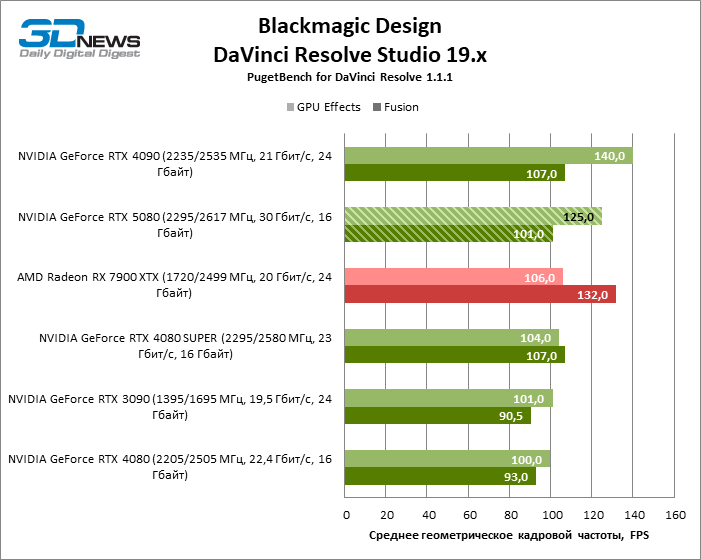
A novidade também contornou a taxa de renderização Radeon RX 7900 XTX nos efeitos da Davinci Resolve e apenas o GeForce RTX 4090 é inferior, mas o carro -chefe “vermelho” não desistiu da referência de fusão.
Finalmente, o GeForce RTX 5080 demonstrou o mesmo perfil de desempenho em aplicativos CAD das placas de vídeo da 40ª série. De acordo com a avaliação média, o RTX 5080 assume uma posição entre o RTX 4080 Super e o RTX 4090, mas todos os aceleradores “verdes” não são comparados com o Radeon RX 7900 XTX.
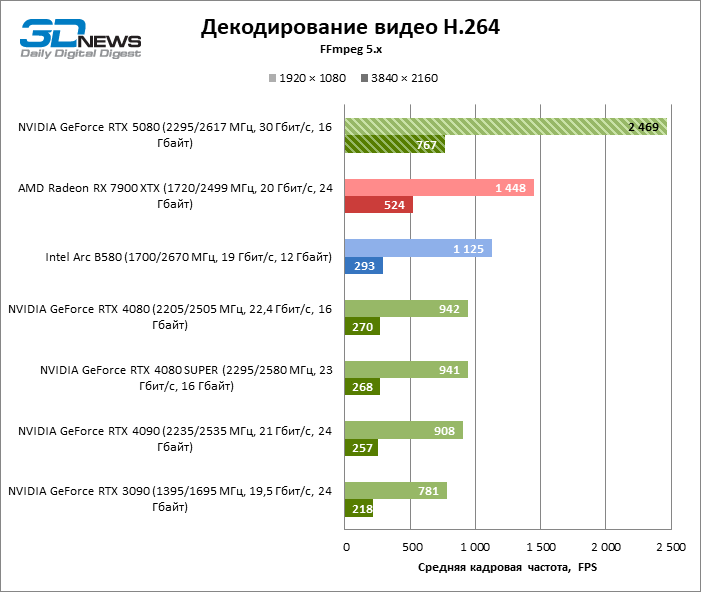
⇡#Codificação / decodificação de vídeo
O decodificador de hardware da NVDEC, que não havia reclamado do desempenho antes, recebeu um pequeno aumento na velocidade de trabalho com HEVC, VP9 e AV1. E o mais importante, a frequência do pessoal de H.264 mais que dobrou. Agora, a NVIDIA lidera todos os testes de decodificação, com exceção do AV1, com uma resolução de 1080p e VP9, onde o primeiro local é ocupado pela Intelly Quicksync na placa ARC B580.
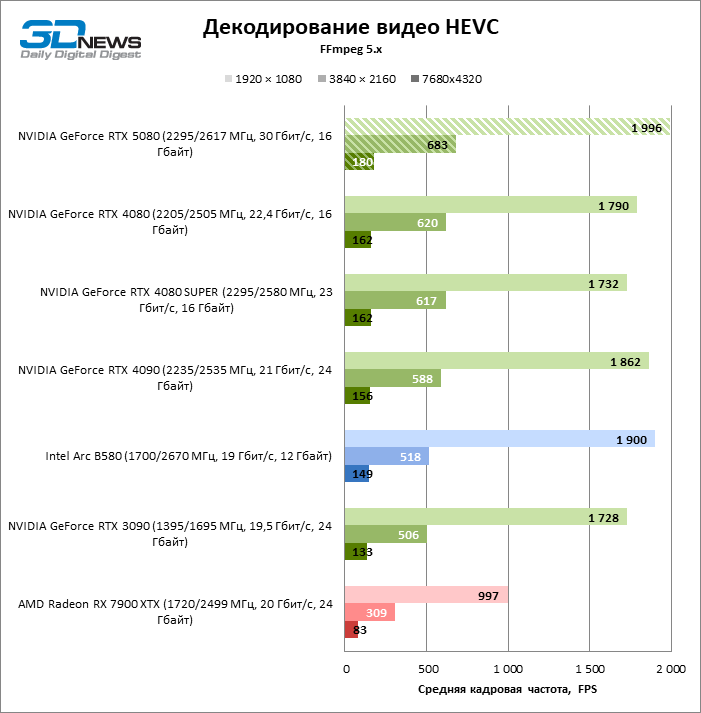
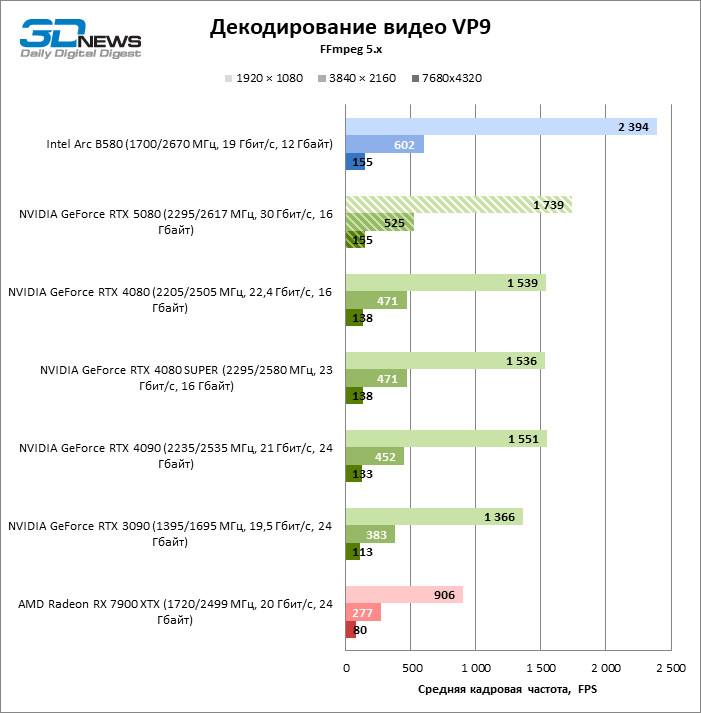
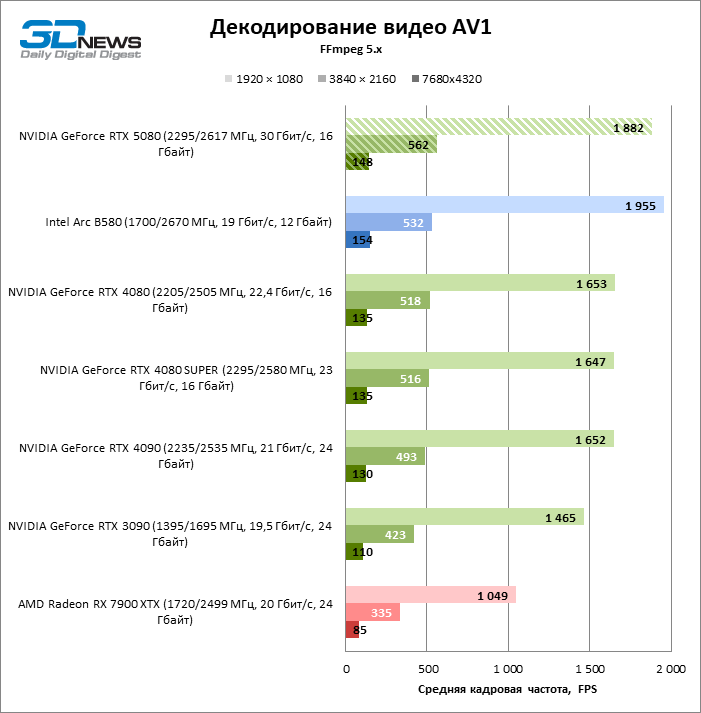
Quanto à codificação de hardware, o GeForce RTX 5080 não conseguiu demonstrar uma vantagem significativa sobre os modelos seniores da 40ª série nos benchmarks H.264 e HEVC, mas a taxa de exportação no AV1 aumentou acentuadamente (especialmente com a resolução de 8k). Nesse grupo de tarefas, o RTX 5080 incondicionalmente à frente da solução da Intel e da AMD.
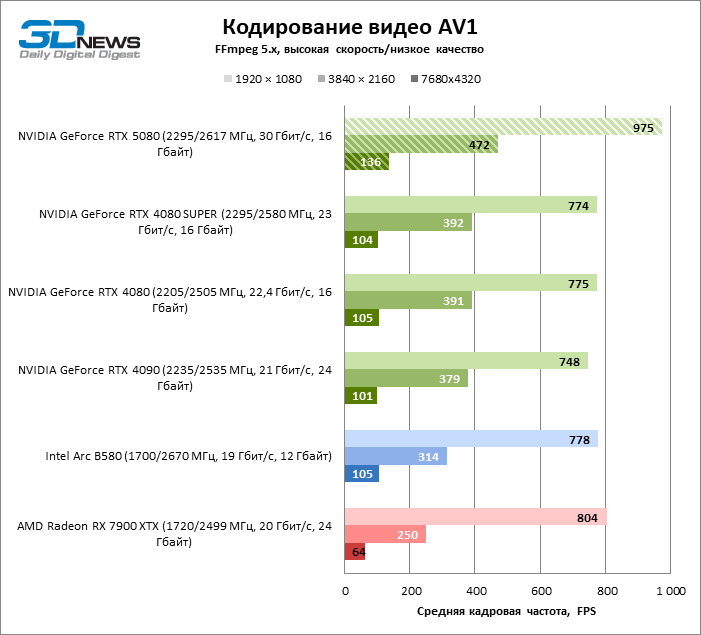
⇡#Desempenho por watt
Apesar de todas as melhorias dos chips de Blackwell, projetados para aumentar a eficiência energética nas condições da norma fotolitográfica anterior, a comparação do GeForce RTX 5080 com o super RTX 4080 na frequência de pessoal médio (tanto em rastreamento quanto rastreado -baseado Jogos) Sobre o poder do orçamento de energia não terminou em favor da novidade. E na versão básica do RTX 4080, ele ganha apenas 1-2 %. Também está curioso para saber que o Radeon RX 7900 XTX acabou sendo o equivalente completo do GeForce RTX 5080 em velocidade específica na rastrovização, embora seja previsivelmente inferior a 39 % de FPS em jogos com renderização ou rastreamento híbrido de faixas.
⇡#Resultados resumidos de testes de jogos sem ray tracing

⇡#Resultados resumidos de testes de jogos com ray tracing
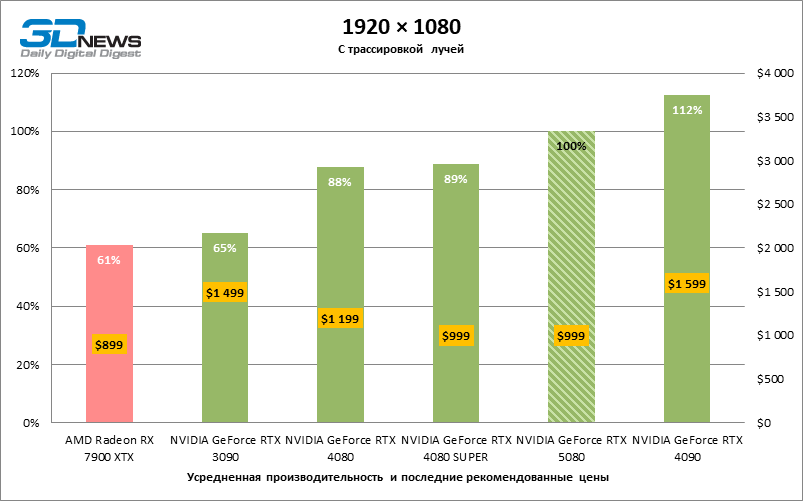
⇡#Resultados resumidos de testes de jogos com ray tracing e frame scaling
⇡#Achados
O surgimento da GPU da nova arquitetura é sempre um evento grande e emocionante, especialmente agora, quando os fabricantes de chips ainda estão dominando o traço de raios e redes neurais na renderização de jogos. No entanto, o desempenho puro das placas de vídeo não pode mais aumentar no mesmo ritmo. Os engenheiros da NVIDIA fizeram muito para extrair 5 nm da fotolitografia e as inovações funcionais da lógica de Blackwell – antes de tudo, a nova versão do DLSS e Shaders neurais – tornou -se mais um passo do paradigma renderizador da força rude. Além disso, a geração de múltiplos funcionários com a ajuda do DLSS 4 pode ser usada agora, mesmo nos jogos que não oferecem essa função do nativo.
O problema é que o MFG realmente fornece vários crescimento “livre” na frequência do pessoal, mas, na melhor das hipóteses, não ajuda a reduzir o atraso na entrada em comparação com a estrutura básica. Portanto, o desempenho puro da GPU ainda é importante, a saber, seu GeForce RTX 5080 não é suficiente para elaborar o custo recomendado de US $ 999. Removendo vários funcionários do Chip Blackwell, e receberemos a segunda edição do RTX 4080 Super. Nas condições mais favoráveis (jogos na tela 4K com reitrião), o RTX 5080 conseguiu mover a barra de velocidade para apenas 16 %. Isso não foi suficiente para atingir o nível do carro-chefe anterior-o GeForce RTX 4090-Which é uma falha sem precedentes nos anos 80 dos modelos NVIDIA. Outro na cara foi uma rivalidade estreita com o Radeon RX 7900 XTX em benchmarks rasterizados. No entanto, por que comprar placas de vídeo tão caras, se não para jogos com a RT?
Em defesa da novidade, pode -se argumentar que ela possui uma proporção deliberadamente melhor de capacidades e preços em comparação com o GeForce RTX 4090, que há muito sai de seu MSRP. No entanto, as placas gráficas da 50ª série provavelmente acontecerão na mesma escassez. O GeForce RTX 5080 é um exemplo ideal do que está acontecendo na ausência de competição, que deixou o mercado discreto de GPU e definitivamente não retornará no ciclo atual.
Mas o Palit Gamerock Accelerator, que representa o GeForce RTX 5080 na revisão, não deu a menor razão para as críticas. Apesar do consumo de energia de até 400 watts, o dispositivo funciona de forma silenciosa e surpreendentemente produtiva (o que é uma extensão considerável o mérito de Silicon Blackwell) – se apenas no caso houve espaço suficiente para uma placa de vídeo tão grande.